文章目录
灰色预测对原始数据进行生成处理来寻找系统变动的规律,并生成有较强规律性的数据序列,然后建立相应的微分方程模型,从而预测事物未来发展趋势的状况。
灰色预测是一种对含有不确定因素的系统进行预测的方法。 灰色预测通过鉴别系统因素之间发展趋势的相异程度,即进行关联分析,并对原始数据进行生成处理来寻找系统变动的规律,生成有较强规律性的数据序列,然后建立相应的微分方程模型,从而预测事物未来发展趋势的状况。 其用等时距观测到的反映预测对象特征的一系列数量值构造灰色预测模型,预测未来某一时刻的特征量,或达到某一特征量的时间
这个应该是很清晰的,数据量少,四五个,然后类指数形式增长的,什么是类指数增长:就是一组数据累加后排列是否呈类指数增长,与且预测的时间不是很长,就可以用。 分为GM (1,1),GM (1,m),GM (n,m)分别用于一个自变量一个因变量,多个自变量一个因变量,多个自变量多个因变量。 灰色预测就是尽可能使用数据中含有的信息。 假设你有十组数据,需要预测接下来的三组数据,程序跑完,一般是有求残差的过程,看一看是不是小于0.1,如果每个数据点都是小于0.1,那这次灰色预测就是很好的。
注:
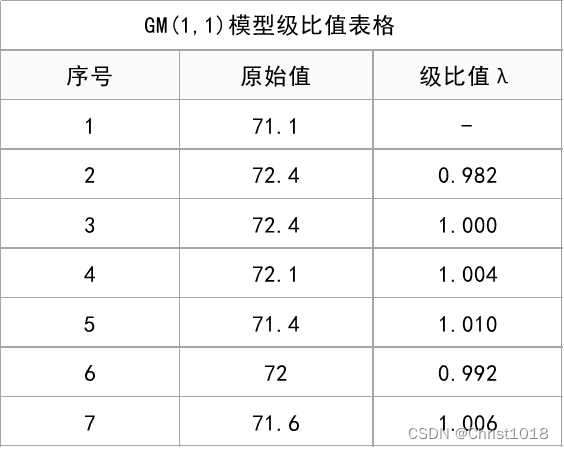
(注:级比值介于区间[0.982,1.0098]时说明数据适合模型构建。)
从上表可知,针对某数据进行GM(1,1)模型构建,结果显示:级比值的最大值为1.010,在适用范围区间[0.982,1.0098]之外,意味着本数据进行GM(1,1)可能得不到满意的模型。但从数据来看,1.01非常接近于1.0098,因此有理由接着进行建模。
如下代码所示为数据级比检验:
m = length(A);
JiBi = ones(1,m-1);
for i =2:m
JiBi(i-1) = A(i-1)/A(i);
end
max1 = max(JiBi);
min1 = min(JiBi);
FanWei = exp(2/(n+2))-exp(-2/(n+1))
if max1 - min1<FanWei
disp(['数据通过级别检验']);
else
disp(['数据不通过级比检验']);
end
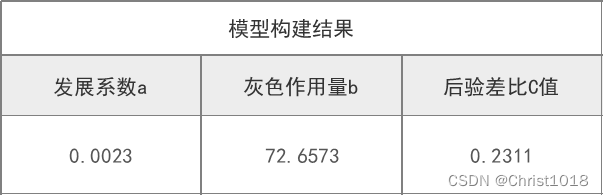
后验差比C值用于模型精度等级检验,该值越小越好,一般C值小于0.35则模型精度等级好,C值小于0.5说明模型精度合格,C值小于0.65说明模型精度基本合格,如果C值大于0.65,则说明模型精度等级不合格。
从上表可知,后验差比C值0.231 <=0.35,意味着模型精度等级非常好。
以下为发展系数、灰色作用量和C值代码:
%构造数据矩阵
B = [-C;ones(1,n-1)];
Y = A; Y(1) = []; Y = Y'; %Y进行了转置,C的公式求法与百度文库 发生了一些变化
% 使用最小二乘法计算参数 a(发展系数)和b(灰作用量)
c = inv(B*B')*B*Y; %核心公式
c = c';
a = c(1); b = c(2);
disp(['发展系数:',num2str(a)]);
disp(['灰色作用量:',num2str(b)]);
%预测后续数据
F = []; F(1) = A(1);
%法二:方差比C检验
C = std(epsilon, 1)/std(A, 1); %方差函数std 按照列分
disp(['方差比C检验:',num2str(C)]);
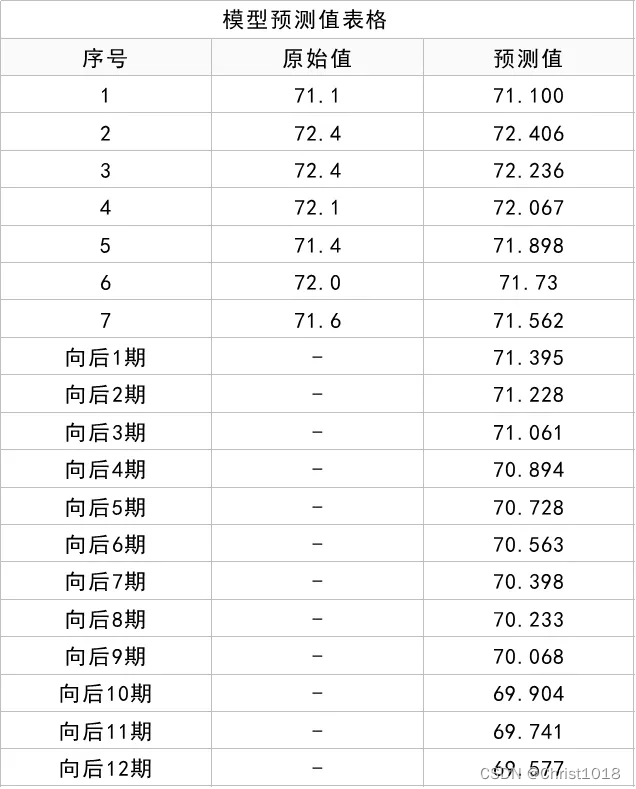
上表格展示出模型的拟合值,以及向后12期的拟合数据情况,当然也可通过图形直观查看如下图,下图明显可以看出,往后时会一直下降,这是GM(1,1)模型的特征,其仅适用于中短期预测,因此向后1期和向后2期的数据具有价值,更多的预测数据需要特别谨慎对待。
以下为模型拟合检验代码:
%模型检验
H = G(1:T1);
epsilon = A - H; %计算残差序列
disp(['残差检验:',num2str(epsilon)]);
画图展示:
%绘制曲线图
plot(t1, A,'ro'); hold on;
plot(t2, G, 'g-');
grid on;
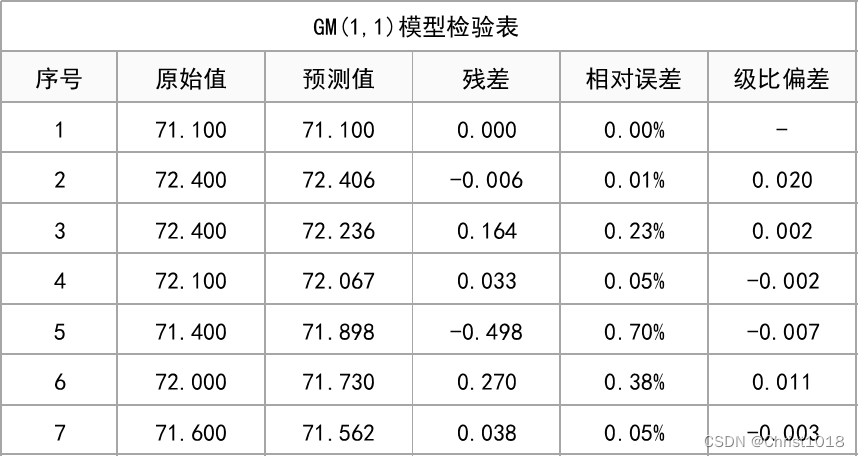
模型残差检验,主要是查看相对误差值和级比偏差值,验证模型效果情况。
从上表可知,模型构建后可对相对误差和级比偏差值进行分析,验证模型效果情况;模型相对误差值最大值0.007<0.1,意味着模型拟合效果达到较高要求。
针对级比偏差值,该值小于0.2说明达到要求,若小于0.1则说明达到较高要求;模型相对误差值最大值0.020<0.1,意味着模型拟合效果达到较高要求。
以下为残差值检验代码:
%法一:计算相对误差Q
delta = abs(epsilon./A);
Q = mean(delta);
disp(['相对残差Q检验:',num2str(Q)]);
%法二:方差比C检验
C = std(epsilon, 1)/std(A, 1); %方差函数std 按照列分
disp(['方差比C检验:',num2str(C)]);
%法三:小误差概率P检验
S1 = std(A, 1);
tmp = find(abs(epsilon - mean(epsilon))< 0.6745 * S1);
P = length(tmp)/n;
disp(['小误差概率P检验:',num2str(P)])
这是在(check.m)函数里的,需要调用
% 预测
p_d = zeros(n, 1);
for i = 1 : n - 1
p_d(i + 1) = (1-exp(a))*(d(1)-b/a)*exp(-a*i);
end
% 级比偏差
u = abs(d(2:end)-p_d(2:end))./d(2:end);
disp('均级比偏差为(通常小于0.1则说明适合灰色预测):');
disp(mean(u));
% 相对残差
disp('均级相对残差为(通常小于0.1则说明适合灰色预测):');
e = abs(1-(1-0.5*a)/(1+0.5*a)*(d(1:end-1)./d(2:end)));
disp(mean(e));
end
clc;clear; %建立符号变量a(发展系数)和b(灰作用量)
syms a b;
c = [a b]';
A = [1 4 6 9 10 12 21 34
]; %输入需要预测的数据
T1=length(A);
T2=100; %输入需要预测数据个数
t1=1:T1;
t2=1:T1+T2;
n = T1;
m = length(A);
JiBi = ones(1,m-1);
for i =2:m
JiBi(i-1) = A(i-1)/A(i);
end
max1 = max(JiBi);
min1 = min(JiBi);
FanWei = exp(2/(n+2))-exp(-2/(n+1))
if max1 - min1<FanWei
disp(['数据通过级别检验']);
else
disp(['数据不通过级比检验']);
end
%对原始数列 A 做累加得到数列 B
B = cumsum(A);
%对数列 B 做紧邻均值生成
for i = 2:n
C(i) = (B(i) + B(i - 1))/2;
end
C(1) = [];
%构造数据矩阵
B = [-C;ones(1,n-1)];
Y = A; Y(1) = []; Y = Y'; %Y进行了转置,C的公式求法与百度文库 发生了一些变化
% 使用最小二乘法计算参数 a(发展系数)和b(灰作用量)
c = inv(B*B')*B*Y; %核心公式
c = c';
a = c(1); b = c(2);
disp(['发展系数:',num2str(a)]);
disp(['灰色作用量:',num2str(b)]);
%预测后续数据
F = []; F(1) = A(1);
for i = 2:T1+T2
F(i) = (A(1)-b/a)*exp(-a*(i-1))+ b/a;
end
%对数列 F 累减还原,得到预测出的数据
G = []; G(1) = A(1);
for i = 2:T1+T2
G(i) = F(i) - F(i-1); %得到预测出来的数据
end
disp(['预测数据为:',num2str(G)]);
%模型检验
H = G(1:T1);
epsilon = A - H; %计算残差序列
disp(['残差检验:',num2str(epsilon)]);
%法一:计算相对误差Q
delta = abs(epsilon./A);
Q = mean(delta);
disp(['相对残差Q检验:',num2str(Q)]);
%法二:方差比C检验
C = std(epsilon, 1)/std(A, 1); %方差函数std 按照列分
disp(['方差比C检验:',num2str(C)]);
%法三:小误差概率P检验
S1 = std(A, 1);
tmp = find(abs(epsilon - mean(epsilon))< 0.6745 * S1);
P = length(tmp)/n;
disp(['小误差概率P检验:',num2str(P)])
%级比偏差和相对残差
check(A)
%绘制曲线图
plot(t1, A,'ro'); hold on;
plot(t2, G, 'g-');
grid on;
以上内容主要是针对如何使用灰色预测(GM(1,1))进行了一个概述,具体的公式讲解并没有列举出来,如若需要,再进行公式的细分和讲解。
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
ruby中有这样的东西吗?send(+,1,2)我想让这段代码看起来不那么冗余ifop=="+"returnarg1+arg2elsifop=="-"returnarg1-arg2elsifop=="*"returnarg1*arg2elsifop=="/"returnarg1/arg2 最佳答案 是的,只需像这样使用send(或者更好的是public_send):arg1.public_send(op,arg2)这是可行的,因为Ruby中的大多数运算符(包括+、-、*、/、andmore)只需调用方法。所以1+2与1.+(2)相同
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
情况:我正在编写一个程序来求解素数。我需要解决4x^2+y^2=n的问题,其中n是一个已知变量。是的,必须是Ruby。我愿意在这个项目上花费大量时间。我最好自己编写方程式的求解算法,并将其作为该项目的一部分。我真正喜欢的是:如果任何人都可以向我提供指南、网站的链接,或者关于与求解代数方程特别相关的形式算法的构造的歧义消除,或者向我提供似乎你是读者它会帮助我完成任务。请不要建议我使用其他语言。如果您在回答之前接受我真的非常想这样做,我将不胜感激。该项目没有范围或时间限制,也不以营利为目的。这是为了我自己的教育。注意:我并不直接反对为Ruby实现和使用现存的数学库/模块/其他东西,但我更喜
我发现许多Rails应用程序主要针对企业、社交网络类型的Web应用程序。我看到有人将Ruby与一些出色的OOPS语言(如Java和C#)进行了比较,但我确实发现很难获得一些数学密集型应用程序。非常感谢任何知识渊博的输入(指向示例程序的链接等),其中轻松显示了语言的用法,就像快速启动或显示该语言如何用于各种数学问题一样。 最佳答案 不幸的是,Ruby并没有在数学和科学计算领域涉足太多。目前,有一个名为SciRuby的pre-alpha库它试图为Ruby带来更多面向数学的功能。他们正试图构建一个NumPy/SciPy等价物。SciRub
link有两个组件:componenta_id和componentb_id。为此,在Link模型文件中我有:belongs_to:componenta,class_name:"Component"belongs_to:componentb,class_name:"Component"validates:componenta_id,presence:truevalidates:componentb_id,presence:truevalidates:componenta_id,uniqueness:{scope::componentb_id}validates:componentb_id
“架设一个亿级高并发系统,是多数程序员、架构师的工作目标。许多的技术从业人员甚至有时会降薪去寻找这样的机会。但并不是所有人都有机会主导,甚至参与这样一个系统。今天我们用12306火车票购票这样一个业务场景来做DDD领域建模。”开篇要实现软件设计、软件开发在一个统一的思想、统一的节奏下进行,就应该有一个轻量级的框架对开发过程与代码编写做一定的约束。虽然DDD是一个软件开发的方法,而不是具体的技术或框架,但拥有一个轻量级的框架仍然是必要的,为了开发一个支持DDD的框架,首先需要理解DDD的基本概念和核心的组件。一.什么是领域驱动设计(DDD)首先要知道DDD是一种开发理念,核心是维护一个反应领域概
我计划在成员之间实现一个私有(private)消息系统。我想知道对此的首选方法是什么。要求是我应该能够像这样轻松地检索它们@user.conversations#ShouldreturnUserobjectsthatIsentorreceivedmessagesfrom(butnotme)@user.conversations.messages#Messagesfromallorspecificuserobjects.@user.conversations.messages.unread#Unreadmessages调用@user.conversations时应该只检索向我发送消息的人
查看原文>>>基于”PLUS模型+“生态系统服务多情景模拟预测实践技术应用目录第一章、理论基础与软件讲解第二章、数据获取与制备第三章、土地利用格局模拟第四章、生态系统服务评估第五章、时空变化及驱动机制分析第六章、论文撰写技巧及案例分析基于ArcGISPro、Python、USLE、INVEST模型等多技术融合的生态系统服务构建生态安全格局基于生态系统服务(InVEST模型)的人类活动、重大工程生态成效评估、论文写作等具体应用基于ArcGISPro、R、INVEST等多技术融合下生态系统服务权衡与协同动态分析实践应用 本文从数据、方法、实践三方面对生态系统服务多情景预测进行讲解。内容涵盖多
论文常见数学符号及其含义(科研必备)返回论文和资料目录数学符号在数学领域是非常重要的。在论文中,使用数学符号可以使得论文更加简洁明了,同时也能够准确地描述各种概念和理论。在本篇博客中,我将介绍一些常见的数学符号及其含义(省去特别简单的符号),希望能够帮助读者更好地理解数学论文。高等数学∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi(求和符号):表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x2,…,xn中的所有数相加,例如∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x