MapReduce 是 Google 公司开源的一项重要技术,它是一个编程模型,用以进行大数据量的计算。MapReduce 是一种简化的并行计算编程模型,它使那些没有多少并行计算经验的开发人员也可以开发并行应用程序。
MapReduce运行开发人员使用自己熟悉的语言进行开发。MapReduce,应用程序可以在超过1000个节点的大型集群上运行,并且提供经过优化的错误容灾。MapReduce 采用 “分而治之”思想,把对大规模数据集的操作,分发给一个主节点管理下的各个字节点共同完成,然后整合各个字节点的中间结果,得到最终的计算结果。简而言之,MapReduce 就是“分散任务,汇总结果”。

从MapReduce 自身的命名特点可以看出,MapReduce 至少由两部分组成:Map 和 Reduce。Map理解为“分发”,Reduce理解为“聚合”。用户只需要编写 map() 和 reduce() 两个方法的逻辑,即可完成简单的分布式程序的设计。
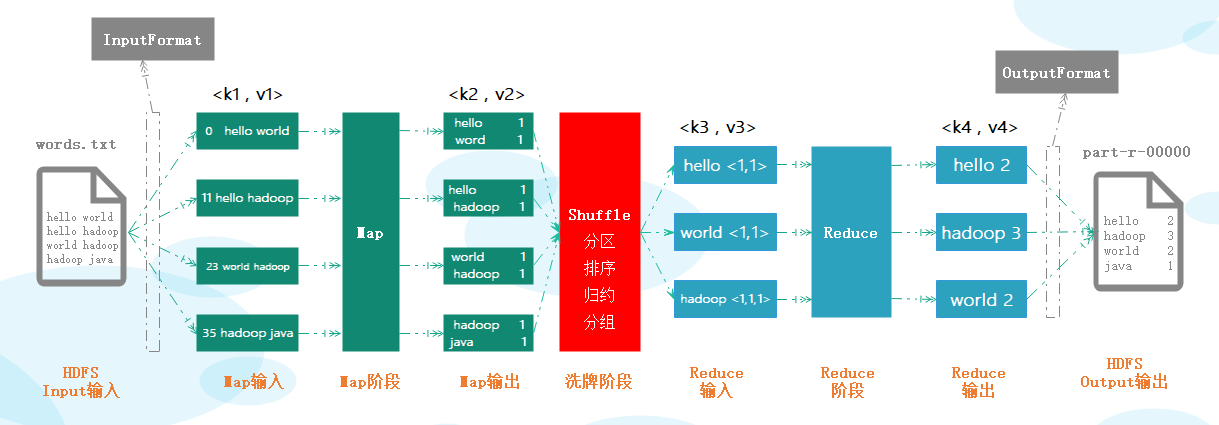
MapReduce 执行过程简要说明如下
HDFS 文件内容,把内容中的每一行解析成一个个的<key, value>键值对。key是每行行首相对于文件起始位置的字节偏移量,value 就是具体的数据,一个文件切片对应一个 map task ,每读取一行就会调用一次 map。map 方法,编写自己的业务逻辑,对输入的<key, value>处理,转换成新的<key,value>输出作为中间结果。reduce 可以并行处理 map 的结果,根据业务要求需要对 map 的输出进行一定的分区 对不同分区上的数据,按照 key 进行排序分组,相同 key的value 放到一个集合中,把分组后的数据进行归约。每个 reduce 会接收各个map中相同分区中的数据,对多个 map任务的输出,按照不同的分区通过网络 copy 到不同 reduce 节点。这个过程称为 Shuffle洗牌 ,即Shuffle就是把我们 map 中的数据分发到 reduce 中去的一个过程。reduce 函数,编写自己的业务逻辑,对输入的<key,value>键值对进行处理,转换成新的<key,value>输出。reduce 的输出保存到新的文件中。D:/devtoolswindow 上面配置配置 hadoop 的环境变量:HADOOP_HOME,并将 %HADOOP_HOME%/bin 配置到 Path 中hadoop 文件 bin 目录下的 hadoop.dll 文件放在系统盘 C:\Windows\System32 目录MapReduce 要求<key, value>的 key 和 value 都要实现 Writable 接口,从而支持Hadoop的序列化和反序列化。
| Java的类型 | Hadoop的内置类 | Java的类型 | Hadoop的内置类 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |||
|
| |||
hadoop 开发依赖 hadoop-clientMapper 类实现自己的 Mapper 类,并重写 map() 方法Reduce 类实现自己的 Reduce 类,并重写 reduce() 方法Job 和 任务入口mvn clean package 对工程进行构建jar 到 Linudx 远程服务器任意目录,并执行程序输出到 output 目录下<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>// Mapper
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
// key --> 字符偏移量 value 文本读取的一行数据 hello world context 上下文
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// map逻辑
// 获取每一行数据,转为字符串类型,通过split方法按空格进行拆分获取一个数组
String[] words = value.toString().split(" ");
// 遍历数组,获取每一个单词,通过上下文(context) 以 (单词,1) 的格式写到reduce中
for (String word : words) {
context.write(new Text(word),new IntWritable(1));
}
}
}// Reduce
public static class WordCountReduce extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// key hadoop value <1,1,1>
int count = 0;
// 遍历可迭代对象,获取数值进行统计
for (IntWritable num : values) {
count += num.get();
}
//次数计算完毕,通过上下文 context 以 (hadoop,4) 格式写到文件中
context.write(key,new IntWritable(count));
}
}// 定义MR执行任务,关联Mapper 和 Reduce 以及 输出和输出文件地址
public static void main(String[] args) throws Exception{
//1. 实例化MR环境 --> Configuration
Configuration conf = new Configuration();
//2. 通过环境实例化一个任务 Job
Job job = Job.getInstance(conf,"词频统计");
//3. 指定执行任务的类是谁--> 入口方法所在的类
job.setJarByClass(WordCountJob.class);
// 4. 指定输入文件所在的位置
// D:\WorkSpace\MapReduce\input\words.txt
FileInputFormat.setInputPaths(job,new Path("D:\\WorkSpace\\MapReduce\\input\\words.txt"));
// 5. 指定Mapper阶段所对应的类
job.setMapperClass(WordCountMapper.class);
// Text, IntWritable
// 5.1 指定Mapper的输出key和value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 6. 指定Reduce阶段所对应的类
job.setReducerClass(WordCountReduce.class);
// Text,IntWritable
// 6.1 指定Reduce的输出key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 7. 指定结果输出的地址 -->输出的地址一定不能存在
// 7.1 MR程序输出路径不能存在,通过HDFS API 进行判断删除
Path outputPath = new Path("D:\\WorkSpace\\MapReduce\\output");
// 获取HDFS 文件系统对象
FileSystem fs = FileSystem.get(conf);
// 判断指定的输出地址是否存在,如果存在,则删除
if(fs.exists(outputPath)){
fs.delete(outputPath,true);
}
// 指定处理后的数据输出地址
FileOutputFormat.setOutputPath(job,outputPath);
// 8. 执行任务,输出成功或失败
boolean flg = job.waitForCompletion(true);
System.out.println(flg?"执行成功":"执行失败");
// System.exit(flg?0:1);
}添加打JAR包插件,并指定入口类
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<!--改成自己的MR程序main方法所在的类全路径-->
<mainClass>org.example.mapreduce.WordCountJob</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>修改MapReduce程序,动态指定输入输出路径
public static void main(String[] args) throws Exception{
if(args.length<2){
System.err.println("Usage: yarn jar <jar_name> <in_path> <out_path>");
System.exit(2);
}
FileInputFormat.setInputPaths(job,args[0]);
FileOutputFormat.setOutputPath(job,args[1]);
}通过Maven插件进行打JAR包
执行 mvn clean package 对工程进行构建
注意:词频统计的输入地址和输出地址都是HDFS文件系统地址。[cdhong@centos8 hadoop]$ yarn jar mapreduce-demo-1.0-SNAPSHOT.jar /input/words.txt /outputConfiguration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://node:9000"); // 执行操作的Hadoop环境,默认是本地
System.setProperty("HADOOP_USER_NAME","root"); // 指定操作的用户在MapReduce流程中,Map的输出<key, value>经过 Shuffle 过程聚集成 <key, value-list> 后会交给Reduce。当Reduce接收到一个<key, value_list>时就直接将key复制到输出key中,并将value设置为空值。Reduce中的key表示要统计的数据,value则没有太大意义。
片名:我不是药神,主演:徐峥,上映时间:2018-07-05,9.6
片名:千与千寻,主演:周冬雨, 上映时间:2019-06-21,评分:9.3
片名:阿甘正传,主演:汤姆·汉克斯, 上映时间:1994-07-06,评分:9.4
片名:阿甘正传,主演:汤姆·汉克斯, 上映时间:1994-07-06,评分:9.4
片名:触不可及,主演:弗朗索瓦·克鲁塞, 上映时间:2011-11-02,评分:9.1
片名:楚门的世界,主演:金·凯瑞, 上映时间:1998,评分:8.9
片名:寻梦环游记,主演:安东尼·冈萨雷斯,上映时间:2017-11-24,评分:9.6
片名:我不是药神,主演:徐峥,上映时间:2018-07-05,9.6
片名:楚门的世界,主演:金·凯瑞, 上映时间:1998,评分:8.9public class RepeatHandler {
public static class RepeatHandlerMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value, NullWritable.get());
}
}
public static class RepeatHandlerReduce extends Reducer<Text, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(RepeatHandler.class);
// 设置Mapper
job.setMapperClass(RepeatHandlerMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
// 设置Reduce
job.setReducerClass(RepeatHandlerReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 设置输入和输出目录
FileInputFormat.setInputPaths(job, new Path("E:\\WorkSpace\\mapreduce\\input\\*"));
Path path = new Path("E:\\WorkSpace\\mapreduce\\output");
FileSystem fileSystem = FileSystem.get(conf);
if (fileSystem.exists(path)) {
fileSystem.delete(path, true);
}
FileOutputFormat.setOutputPath(job, path);
// 任务执行
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}7369,SMITH,CLERK,7902,1980/12/17,800,,20
7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
7521,WARD,SALESMAN,7698,1981/2/22,1250,500,30
7566,JONES,MANAGER,7839,1981/4/2,2975,,20
7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981/5/1,2850,,30
7782,CLARK,MANAGER,7839,1981/6/9,2450,,10
7788,SCOTT,ANALYST,7566,1987/4/19,3000,,20
7839,KING,PRESIDENT,,1981/11/17,5000,,10
7844,TURNER,SALESMAN,7698,1981/9/8,1500,0,30
7876,ADAMS,CLERK,7788,1987/5/23,1100,,20
7900,JAMES,CLERK,7698,1981/12/3,950,,30
7902,FORD,ANALYST,7566,1981/12/3,3000,,20
7934,MILLER,CLERK,7782,1982/1/23,1300,,10public class SalaryTotalHandler {
public static class SalaryTotalHandlerMapper extends Mapper<LongWritable, Text, IntWritable, DoubleWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(",");
int deptNo = Integer.parseInt(line[7]); // 部门编号
double salary = Double.parseDouble(line[5]); // 薪资
context.write(new IntWritable(deptNo),new DoubleWritable(salary));
}
}
public static class SalaryTotalHandlerReduce extends Reducer<IntWritable, DoubleWritable,IntWritable, DoubleWritable>{
@Override
protected void reduce(IntWritable key, Iterable<DoubleWritable> values, Context context) throws IOException, InterruptedException {
// 对总工资求和
double total = 0;
for (DoubleWritable value : values) {
total += value.get();
}
context.write(key,new DoubleWritable(total));
}
}
}统计各部门员工总数,平均薪资,总薪资???
采用 MapReduce 实现类似下面 SQL 语句的功能: select d.*,e.* from emp e join dept d on e.deptno=d.deptno;
Map 端读取所有的文件,并为输出的内容加上标识,代表文件数据来源于员工表还是部门表,获取连接字段作为key,进行分组。Reduce 端,获取每个分组中带有标识的数据与无标识的数据进行拼接即可。10,ACCOUNTING,NEW YORK
20,RESEARCH,DALLAS
30,SALES,CHICAGO
40,OPERATIONS,BOSTONpublic class EqualJoinHandler {
public static class EqualJoinHandlerMapper extends Mapper<LongWritable, Text, Text, Text> {
// 接收所有文件,对两张表打标识,根据连接列分组
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(","); //获取两个文件中的每一行数据,通过逗号分割获取数组
String deptNo = line.length == 3 ? line[0] : line[7]; // 根据数组的长度判断分别获取对应的分组字段 deptNo
context.write(new Text(deptNo), value); // 根据deptNo字段进行分组传递给Reduce
}
}
public static class EqualJoinHandlerReduce extends Reducer<Text, Text, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 数据暂存,Iterable有指针,且不方便后续处理
ArrayList<String> list = new ArrayList<>();
values.forEach(item -> list.add(item.toString()));
// 查找部门数据,用于拼接在Emp表的后面
String deptInfo = list.stream().filter(item -> item.split(",").length == 3).findFirst().orElse("");
// 查找所有员工数据,把dept表的数据拼接到每个员工表数据后面
list.stream()
.filter(item -> item.split(",").length > 3) // 过滤部门表数据
.map(item -> item.concat(deptInfo.substring(3))) // 拼接部门表数据,并去除部门编号前缀
.forEach(item -> context.write(new Text(item), NullWritable.get())); // 循环写入文件中
}
}
}通过 JSON 工具解析JSON字符串数据,获取所有数据维度,并按相应格式保存为数据文件
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>JSON数据样例
{
"success": true,
"msg": null,
"code": 0,
"content": {
"showId": "43e327f364c144be893e5adc4625c364",
"hrInfoMap": {
"7134703": {
"userId": 5930479,
"portrait": null,
"realName": "陈小姐",
"positionName": "招聘主管"
},
"8042425": {
"userId": 10905492,
"portrait": "i/image/M00/45/DA/Ciqc1F9Dj52Afz0hAACeGEp-ay0996.png",
"realName": "林小姐",
"positionName": "人事专员"
}
},
"pageNo": 1,
"positionResult": {
"resultSize": 15,
"result": [{
"positionId": 8094442,
"companyFullName": "上海致宇信息技术有限公司",
"companyShortName": "致宇信息",
"companySize": "150-500人",
"industryField": "金融,软件开发",
"financeStage": "不需要融资",
"companyLabelList": ["股票期权", "绩效奖金", "专项奖金", "年底双薪"],
"firstType": "开发|测试|运维类",
"secondType": "数据开发",
"thirdType": "BI工程师",
"skillLables": ["数据仓库", "Hadoop", "Spark", "Hive"],
"positionLables": ["数据仓库", "Hadoop", "Spark", "Hive"],
"industryLables": [],
"createTime": "2020-12-25 14:16:31",
"formatCreateTime": "2天前发布",
"city": "厦门",
"district": "思明区",
"businessZones": null,
"salary": "18k-22k",
"salaryMonth": "13",
"workYear": "1-3年",
"jobNature": "全职",
"education": "本科",
"positionAdvantage": "五险一金 年终奖 两次调薪 晋升空间",
"imState": "threeDays",
"lastLogin": "2020-12-25 18:17:20",
"publisherId": 10876210
}, {
"positionId": 8136910,
"positionName": "(大数据专场)Java开发工程师/专家-【数据架构】",
"companyId": 1880,
"companyFullName": "北京达佳互联信息技术有限公司",
"companyShortName": "快手",
"companyLogo": "i/image/M00/49/E7/Ciqc1F9QZJSAC0VBAACwLdjC9yo459.png",
"companySize": "2000人以上",
"industryField": "文娱丨内容",
"financeStage": "D轮及以上",
"companyLabelList": ["股票期权", "弹性工作", "定期体检", "岗位晋升"],
"firstType": "开发|测试|运维类",
"secondType": "后端开发",
"thirdType": "Java",
"skillLables": [],
"positionLables": [],
"industryLables": [],
"createTime": "2020-12-25 19:06:35",
"formatCreateTime": "2天前发布",
"city": "北京",
"district": "海淀区",
"businessZones": ["上地"],
"salary": "20k-40k",
"salaryMonth": "0",
"workYear": "3-5年",
"jobNature": "全职",
"education": "本科",
"positionAdvantage": "福利多,成长快",
"imState": "threeDays",
"lastLogin": "2020-12-25 18:48:45",
"publisherId": 11043272
}],
"locationInfo": {
"city": null,
"district": null,
"businessZone": null,
"isAllhotBusinessZone": false,
"locationCode": null,
"queryByGisCode": false
}
},
"pageSize": 15
},
"resubmitToken": null,
"requestId": null
}MapReduce程序代码
public class LaGouJob {
public static class LaGouMapper extends Mapper<LongWritable, Text,Text, NullWritable>{
@Override
protected void map(LongWritable key, Text line, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
// 通过阿里巴巴的 fastJSON进行JSON数据解析
JSONArray result = JSON.parseObject(line.toString())
.getJSONObject("content")
.getJSONObject("positionResult")
.getJSONArray("result");
for (Object o : result) {
JSONObject obj = (JSONObject)o; // 类型转换
// 获取所需维度
String city = obj.getString("city");
String salary = obj.getString("salary");
String workYear = obj.getString("workYear");
String education = obj.getString("education");
// 拼接数据
// 完整格式:重庆,11-22K,本科,1-3年,股票期权|绩效奖金|专项奖金|年底双薪,数据仓库|Hadoop|Spark|Hive
String info = city+","+salary+","+workYear+","+education;
// 写到文件中
context.write(new Text(info),NullWritable.get());
}
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(LaGouJob.class);
job.setMapperClass(LaGouMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//文件地址
FileInputFormat.setInputPaths(job,new Path("D:\\WorkSpace\\MapReduce\\input\\lagou\\*"));
FileOutputFormat.setOutputPath(job, HDFSUtil.delPath(conf,"D:\\WorkSpace\\MapReduce\\output"));
System.exit(job.waitForCompletion(true)?0:1);
}
}序列化时一种将内存中的Java对象转化为其他可存储文件或可跨计算机传输数据流的一种技术。
由于在运行程序的过程中,保存在内存中的Java对象会因为断电而丢失,或在分布式系统中,Java对象需要从一台计算机传递给其他计算机进行计算,所有Java对象需要通过某种技术转为为文件或实际可传输的数据流。这就是Java的序列化。
常见的 Java 序列化方式是实现 java.io.Serializable 接口。而Hadoop的序列化则是实现 org.apache.hadoop.io.Writable 接口,该接口包含 readFields()、write() 两个方法。注意:序列化和反序列化方法的字段顺序需要保持一致。
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class EmployeeWritable implements Writable {
private int empno;
private String ename;
private String job;
private int mgr;
private String hiredate;
private double sal;
private double comm;
private int deptno;
@Override // 序列化
public void write(DataOutput out) throws IOException {
out.writeInt(this.empno);
out.writeUTF(this.ename);
out.writeUTF(this.job);
out.writeInt(this.mgr);
out.writeUTF(this.hiredate);
out.writeDouble(this.sal);
out.writeDouble(this.comm);
out.writeInt(this.deptno);
}
@Override
public void readFields(DataInput in) throws IOException {
this.empno = in.readInt();
this.ename = in.readUTF();
this.job = in.readUTF();
this.mgr = in.readInt();
this.hiredate = in.readUTF();
this.sal = in.readDouble();
this.comm = in.readDouble();
this.deptno = in.readInt();
}
}
public class SalaryAvgHandler {
public static class SalaryAvgHandlerMapper extends Mapper<LongWritable, Text, IntWritable, EmployeeWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(",");
EmployeeWritable emp = EmployeeWritable.builder()
.deptno(Integer.parseInt(line[0]))
.ename(line[1]).job(line[2])
.mgr(Integer.parseInt(Objects.equals(line[3], "") ? "-1" : line[3]))
.hiredate(line[4]).sal(Double.parseDouble(line[5]))
.comm(Double.parseDouble(Objects.equals(line[6], "") ? "0" : line[6]))
.deptno(Integer.parseInt(line[7])).build();
int deptno = Integer.parseInt(line[7]);
context.write(new IntWritable(deptno), emp);
}
}
public static class SalaryAvgHandlerReduce extends Reducer<IntWritable, EmployeeWritable, IntWritable, Text> {
@Override
protected void reduce(IntWritable key, Iterable<EmployeeWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
double sumSal = 0;
double sumComm = 0;
for (EmployeeWritable emp : values) {
count++;
sumSal += emp.getSal();
sumComm += emp.getComm();
}
String info = sumSal / count + "\t" + sumComm;
context.write(key, new Text(info));
}
}
}在Hadoop中,排序是MapReduce的灵魂,MapTask和ReduceTask均会对数据按Key排序,这个操作是MR框架的默认行为,不过有的时候我们需要自己定义排序规则,具体实现有如下两种方式。
TreeMap 集合工具和 Reduce 的生命周期方法 cleanup 实现MapReduce 的高级 API 使用多个 MapReduce 任务来完成public static class WordCountHandlerMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(" ");
for (String word : line) {
context.write(new Text(word), new IntWritable(1));
}
}
}
public static class WordCountHandlerReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
TreeMap<Integer, String> words = new TreeMap<>((o1, o2) -> -o1.compareTo(o2));
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
words.put(sum,key.toString());
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
words.entrySet().stream()
.limit(3)
.forEach(item-> {
try {
context.write(new Text(item.getValue()),new IntWritable(item.getKey()));
} catch (Exception e) {
e.printStackTrace();
}
});
}
}无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
有点边缘情况,但知道为什么&&=会这样吗?我正在使用1.9.2。obj=Object.newobj.instance_eval{@bar&&=@bar}#=>nil,expectedobj.instance_variables#=>[],soobjhasno@barinstancevariableobj.instance_eval{@bar=@bar&&@bar}#ostensiblythesameas@bar&&=@barobj.instance_variables#=>[:@bar]#whywouldthisversioninitialize@bar?为了比较,||=将实例变量初始
一般来说哪个更好用?:casenwhen'foo'result='bar'when'peanutbutter'result='jelly'when'stack'result='overflow'returnresult或map={'foo'=>'bar','peanutbutter'=>'jelly','stack'=>'overflow'}returnmap[n]更具体地说,什么时候应该使用案例陈述,什么时候应该只使用散列? 最佳答案 散列是一种数据结构,而case语句是一种控制结构。当你只是检索一些数据时,你应该使用散列(就像你
有没有办法在case语句的对象上隐式调用方法?即:classFoodefbar1enddefbaz...endend我希望能够做的是这样的事情......foo=Foo.newcasefoowhen.bar==1then"something"when.bar==2then"somethingelse"when.baz==3then"anotherthing"end...其中“when”语句正在评估case对象上方法的返回。这样的结构可能吗?如果是的话,我还没有弄清楚语法...... 最佳答案 FWIW,您根本不需要将对象传递给1.8
所以我从维基百科上抓取了这段ruby代码并做了一些修改:@trie=Hash.new()defbuild(str)node=@triestr.each_char{|ch|cur=chprev_node=nodenode=node[cur]ifnode==nilprev_node[cur]=Hash.new()node=prev_node[cur]end}endbuild('dogs')puts@trie.inspect我首先在控制台irb上运行它,每次我输出node时,每次{}都会给我一个空哈希值,但当我实际调用时该函数使用参数'dogs'字符串构建,它确实有效,并输出{"d"=>
运行有问题或需要源码请点赞关注收藏后评论区留言一、利用ContentResolver读写联系人在实际开发中,普通App很少会开放数据接口给其他应用访问。内容组件能够派上用场的情况往往是App想要访问系统应用的通讯数据,比如查看联系人,短信,通话记录等等,以及对这些通讯数据及逆行增删改查。首先要给AndroidMaifest.xml中添加响应的权限配置 下面是往手机通讯录添加联系人信息的例子效果如下分成三个步骤先查出联系人的基本信息,然后查询联系人号码,再查询联系人邮箱代码 ContactAddActivity类packagecom.example.chapter07;importandroid
BigData/CloudComputing:基于阿里云技术产品的人工智能与大数据/云计算/分布式引擎的综合应用案例目录来理解技术交互流程目录一、云计算网站建设:部署与发布网站建设:简单动态网站搭建云服务器管理维护云数据库管理与数据迁移云存储:对象存储管理与安全超大流量网站的负载均衡二、大数据MOOC网站日志分析搭建企业级数据分析平台基于LBS的热点店铺搜索基于机器学习PAI实现精细化营销基于机器学习的客户流失预警分析使用DataV制作实时销售数据可视化大屏使用MaxCompute进行数据质量核查使用Quick BI制作图形化报表使用时间序列分解模型预测商品销量三、云安全云平台使用安全云上服务
各位朋友们,大家好啊,今天我要分享的是关于文件操作方面的知识。文章目录为什么会有文件操作什么是文件文件操作文件指针文件的打开与关闭fopen(打开文件)fclose(关闭文件)打开文件的方式文件的顺序读写fgets函数fputc函数fgets函数fputs函数fprintf函数fscanf函数文件的非顺序读写fseek函数ftell函数rewind函数二进制读写fwrite函数`fread函数结语为什么会有文件操作那么大家可能会问:为什么会有文件操作呢?前面我们可能都了解了通讯录,我们知道当我们使用通讯录的时候我们可以添加联系人,也可以删除联系人,但是当我们退出程序之后下次再进来的时候,我们要