在前面的几个章节中,我们介绍了几种基于不同半监督假设的模型优化方案,包括Mean Teacher等一致性正则约束,FGM等对抗训练,min Entropy等最小熵原则,以及Mixup等增强方案。虽然出发点不同但上述优化方案都从不同的方向服务于半监督的3个假设,让我们重新回顾下(哈哈自己抄袭自己):
MixMatch则是集各家所长,把上述方案中的SOTA都融合在一起实现了1+1+1>3的效果,主要包括一致性正则,最小熵,Mixup正则这三个方案。想要回顾下原始这三种方案的实现可以看这里
本章介绍几种半监督融合方案,包括MixMatch,和其他变种MixText,UDA,FixMatch
- Paper: MixMatch: A Holistic Approach to
Semi-Supervised Learning- Github: https://github.com/YU1ut/MixMatch-pytorch
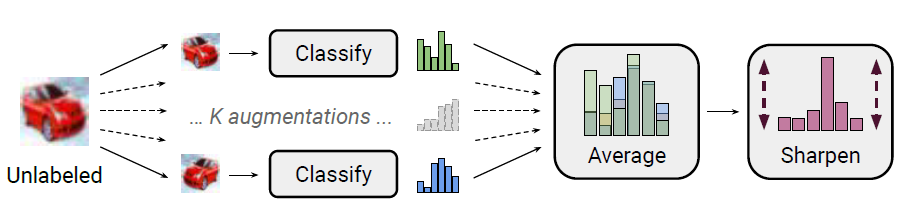
针对无标注样本,MixMatch融合了最小熵原则和一致性正则, 前者最小化模型预测在无标注样本上的熵值,使得分类边界远离样本高密度区,后者约束模型对微小的扰动给出一致的预测,约束分类边界平滑。实现如下
针对有标注样本,作者在原始Mixup的基础上加入对以上无标注样本的使用。
最终的损失函数由标注样本的交叉熵和无标注样本在预测标签上的L2正则项加权得到
Mixmath因为使用了多种方案融合因子引入了不少超参数,包括融合轮数K,温度参数T,Mixup融合参数\(\alpha\), 以及正则权重\(\lambda_u\)。不过作者指出,多数超惨不需要根据任务进行调优,可以直接固定,作者给的参数取值,T=0.5,K=2。\(\alpha=0.75,\lambda_u=100\)是推荐的尝试取值,其中正则权重作者做了线性warmup。
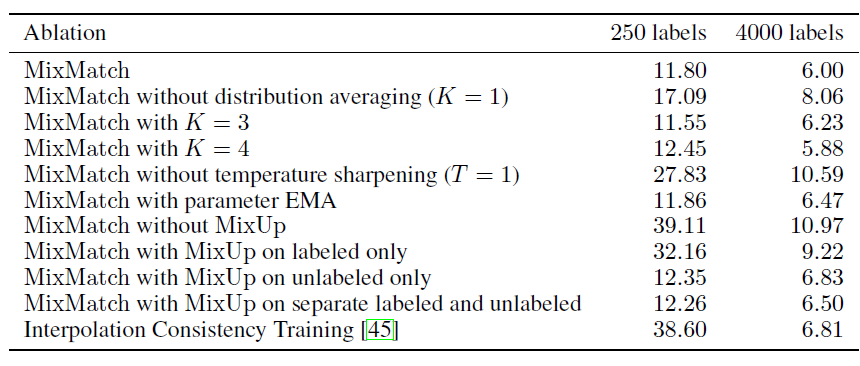
通过消融实验,作者证明了LabelGuessing,Sharpening,Mixup在当前的方案中缺一不可,且进一步使用Mean Teacher没有效果提升。

- Paper: MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification
- Github:https://github.com/SALT-NLP/MixText
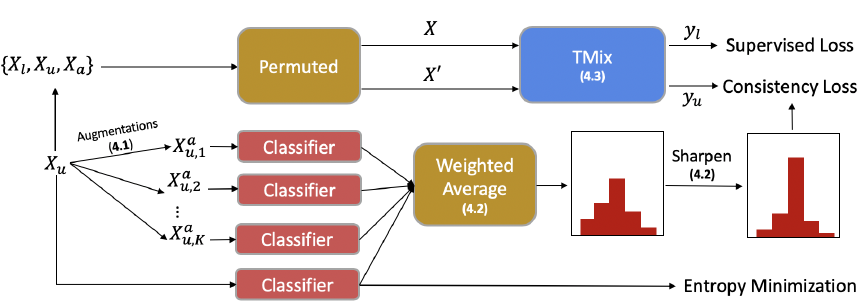
MixText是MixMatch在NLP领域的尝试,关注点在更适合NLP领域的Mixup使用方式,这里只关注和MixMatch的异同,未提到的部分基本上和MixMatch是一样的

- Paper:Unsupervised Data Augmentation for Consistency Training
- official Github: https://github.com/google-research/uda
- pytorch version: https://github.com/SanghunYun/UDA_pytorch
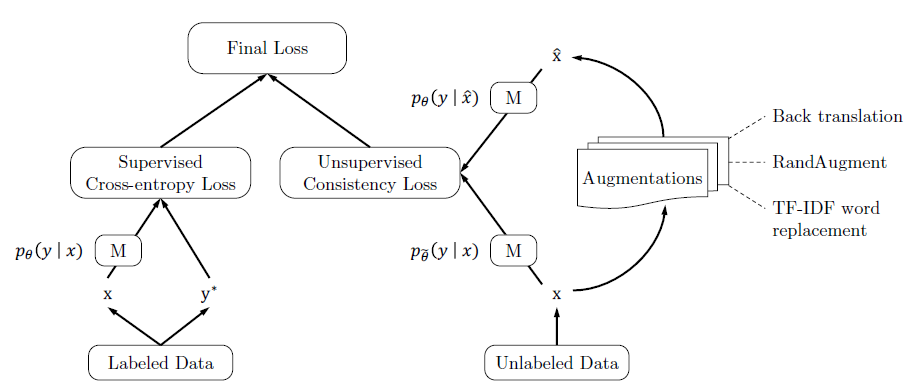
同样是MixMatch在NLP领域的尝试,不过UDA关注点在Data Augmentation的难易程度对半监督效果的影响,核心观点是难度高,多样性好,质量好的噪声注入,可以提升半监督的效果。以下只总结和MixMatch的异同点
Data Augmentation
MixMatch只针对CV任务,使用了随机水平翻转和裁剪进行增强。UDA在图片任务上使用了复杂度和多样性更高的RandAugment,在N个图片可用的变换中每次随机采样K个来对样本进行变换。原始的RandAugment是搜索得到最优的变换pipeline,这里作者把搜索改成了随机选择,可以进一步增强的多样性。
针对文本任务,UDA使用了Back-translation和基于TF-IDF的词替换作为增强方案。前者通过调整temperature可以生成多样性更好的增强样本,后者在分类问题中对核心关键词有更好的保护作用,生成的增强样本有效性更高。这也是UDA提出的一个核心观点就是数据增强其实是有效性和多样性之间的Trade-off
Pseudo Label
针对无标注样本,MixMatch是对K次弱增强样本的预测结果进行融合得到更准确的标签。UDA只对一次强增强的样本进行预测得到伪标签。
Confidence-Based Maskin & Domain-relevance Data Filtering
UDA对无标注样本的一致性正则loss进行了约束,包括两个方面
- Paper:FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
- official Github: https://github.com/google-research/fixmatch
- pytorch version: https://github.com/kekmodel/FixMatch-pytorch
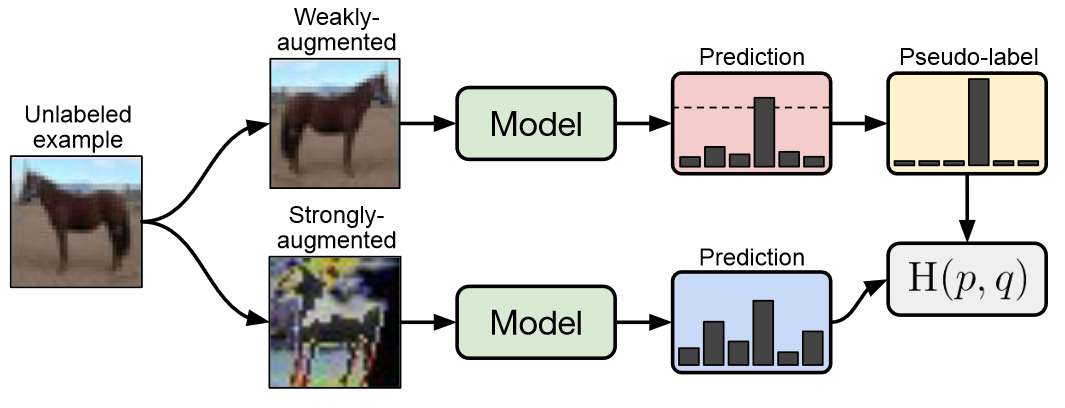
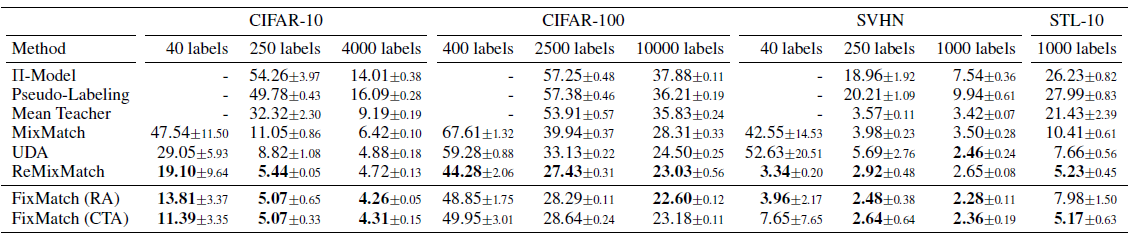
在生成无标注样本的伪标签时,FixMatch使用了UDA的一次预测,和MixMatch的弱增强Flip&Shift来生成伪标签,同时应用UDA的置信度掩码,预测置信度低的样本不参与loss计算。
一致性正则是FixMatch最大的亮点,它使用以上弱增强得到的伪标签,用强增强的样本去拟合,得到一致性正则部分的损失函数。优点是弱增强的标签准确度更高,而强增强为一致性正则提供更好的多样性,和更大的样本扰动覆盖区域,使用不同的增强方案提高了一致性正则的效果
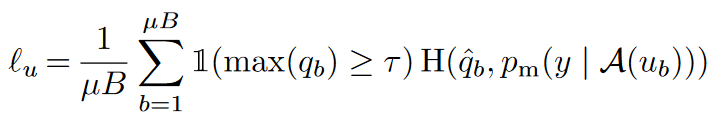
我有一个接受回调函数的函数,我在其中将数据传回。可以将其转换为延迟对象以便更好地练习吗?这是我得到的:varchapters;vargetChapters=function(fnLoad){//CACHEDATAIFAPPLICABLEif(!chapters){//CALLJSONDATAVIAAJAX$.getJSON('/chapters.txt').done(function(json){//STOREDATAINLOCALSTORAGEchapters=Lawnchair(function(){this.save(json,function(data){//CALLCALLB
我想使用网络浏览器从麦克风获取实时音频,并通过网络套接字将其发送到Node.js服务器。我正在使用BinaryJS库将二进制数据发送到服务器。我在从麦克风获取音频样本时遇到问题。这是我所拥有的:window.AudioContext=window.AudioContext||window.webkitAudioContext;varcontext=newAudioContext();varaudio=document.querySelector('audio');navigator.webkitGetUserMedia({audio:true},function(micstream){
我正在尝试用html5制作一个网页,该网页将来自wav文件的示例数据存储在一个数组中。有没有办法用javascript获取样本数据?我正在使用文件输入来选择wav文件。在我已经添加的javascript中:document.getElementById('fileinput').addEventListener('change',readFile,false);但我不知道在readFile中做什么。编辑:我试图在ArrayBuffer中获取文件,将其传递给decodeAudioData方法并从中获取typedArraybuffer。这是我的代码:varopenFile=function
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭4年前。Improvethisquestion或者我必须使用简单的方式,例如:vararr[]intfori:=0;i
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭2年前。社区在11个月前审查了是否重新打开此问题,并将其关闭:原始关闭原因未解决Improvethisquestion我正在寻找用于半自动XSLT生成的工具。给定2个XML文件,来源:XXX和目标:XXX该工具应生成XSLT文件,该文件从源生成目标。查看内容,它应该确定级别、位置、元素名称等方面的变化。对此没有通用的解决方案,但我只需要简单的转换。可能的实现:1.scanthesource,mapXMLdata"
我正在尝试使用Windows生物识别框架注册指纹。程序非常简单,但我想问一下,是否有规定数量的样本(用户滑动手指的次数)才能进行注册?如果这是基于硬件的,那么它应该根据您使用的指纹读取器而改变,但我想知道这是否是特定于实现的。我正在从MSDN复制示例//Captureenrollmentinformationbyswipingthesensorwith//thefingeridentifiedbythesubFactorargumentinthe//WinBioEnrollBeginfunction.for(intswipeCount=1;;++swipeCount){wprintf_
不确定这是否是一个骗局,但到目前为止我找到的帖子并没有解决我的问题。前一段时间,我写了一个(音乐)metronomeforUbuntu.节拍器是用python3/Gtk写的为了重复播放节拍器滴答声(录制的声音样本),我使用subprocess.Popen()播放声音,使用ogg123作为cli工具:subprocess.Popen(["ogg123",soundfile])这很好用,我可以轻松达到每分钟240次。在Windows上我决定在Windows上重写项目(python3/tkinter/ttk)。然而,我很难播放声音,以更高的速度重复节拍样本。下一个节拍根本不会开始,而前一个节
关闭。这个问题需要debuggingdetails.它目前不接受答案。编辑问题以包含desiredbehavior,aspecificproblemorerror,andtheshortestcodenecessarytoreproducetheproblem.这将有助于其他人回答问题。关闭6年前。Improvethisquestion我尝试编译和运行的所有UWP示例都不起作用。他们总是停在闪屏上并保持这种状态。关闭它们后,我无法再次运行它们,因为它说系统正在使用.exe进程。
简介相信大家能经常性的遇到项目上各类excel的导出,简单的excel格式,用简单的poi,easyExcel等工具都能导出。但是针对复杂的excel,有固定的样式、合并单元格、动态列等各类要求,导致excel导出需要花很大一部分精力去写代码。jxls在很大程度上解决了以上问题。这里简单介绍下jxls,JXLS是国外一个简单的、轻量级的excel导出库,链接:JXLS官网,这里有详细的文档说明教程(英文版),为了方便大家使用,我举例几个常见的excel模板配置,方便大家使用。引入maven依赖org.jxlsjxls2.11.0org.jxlsjxls-poi2.11.0org.jxlsjxl
在mypreviousquestion在更大的音频样本中找到引用音频样本时,有人建议我应该使用卷积。使用DSPUtil,我能够做到这一点。我试了一下它并尝试了不同的音频样本组合,看看结果如何。为了可视化数据,我只是将原始音频作为数字转储到Excel中,并使用这些数字创建了一个图表。峰是可见的,但我真的不知道这对我有什么帮助。我有这些问题:我不知道,如何从峰值位置推断出原始音频样本中匹配的起始位置。我不知道,我应该如何将它应用到连续的音频流中,以便我可以在引用音频样本出现时立即使用react。我不明白,为什么图2和图4(见下文)差异如此之大,尽管它们都代表了一个与自身卷积的音频样本...