在排队论中,我们经常见到上面三种分布,即泊松分布、指数分布和爱尔朗分布。我们详细整理一下。
在我们的日常生活中,大量的事件发生是有其固定频率的。就比如下面的例子:
我们可以预估上述事件的总数,但是没法知道具体的发生时间。就比如,我们已知平均每小时出生3个婴儿,请问下一个小时,会出生几个?
而整理的泊松分布就是表述这种概率发生时间的,简言之,泊松分布就是描述某段时间内,事件具体的发生概率。
上面的公式中,等号的左边,P 表示概率,N表示某种函数关系,t 表示时间,n 表示数量,1小时内出生3个婴儿的概率,就表示为 P(N(1) = 3) 。等号的右边,λ 表示事件的频率。

从上面的泊松分布图可以看到,在频率附近,事件的发生概率最高,然后向两边对称下降,即变得越大和越小都不太可能。



指数分布是事件的时间间隔的概率。下面这些都属于指数分布。
比如下面的例子都是需要用到指数分布的,比如婴儿出生的时间间隔 来电的时间间隔 奶粉销售的时间间隔 网站访问的时间间隔等,也就是说,指数分布和泊松分布是一种“逆向的运算”,指数分布衡量的是时间的发生间隔的概念,而泊松分布则是某段时间内,某一件事件发生的概率。
可以看到泊松分布和指数分布都是与时间相关的。我们可以借助泊松分布推导出来指数分布,比如说如果下一个婴儿要间隔时间 t ,就等同于 t 之内没有任何婴儿出生。
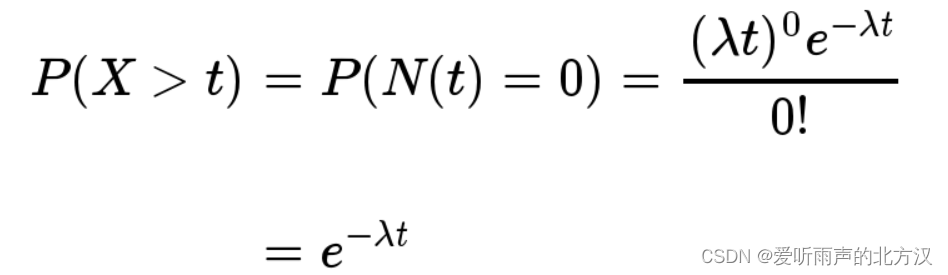
反过来,事件在时间 t 之内发生的概率,就是1减去上面的值。
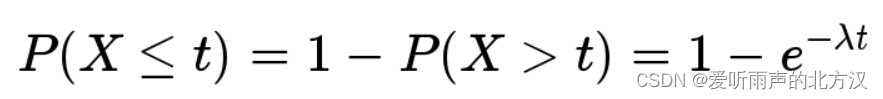

指数分布的概率密度函数定义:
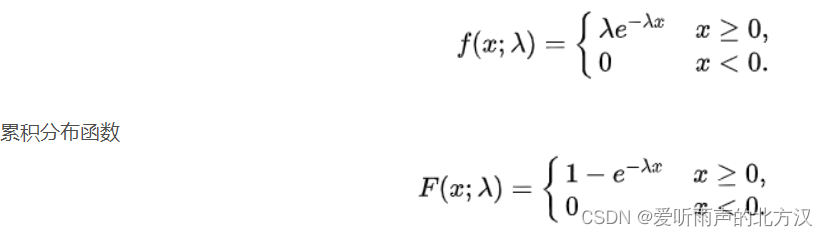
综合上面,我们可以知道:泊松分布是单位时间内独立事件发生次数的概率分布,指数分布是独立事件的时间间隔的概率分布。
具体而言,爱尔朗分布与指数分布一样多用来表示独立随机事件发生的时间间隔。相比指数分布,爱尔朗分布能更好地对现实数据进行拟合(更适用于多个串行过程,或无记忆性假设不显著的情况下)。
简言之,服从指数分布的随机变量之和服从爱尔朗分布。

我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我遇到了同样的问题here对于python,但对于ruby。我需要输出这样一个小数字:0.00001,而不是1e-5。有关我的特定问题的更多信息,我正在使用f.write("Mynumber:"+small_number.to_s+"\n")输出到一个文件对于我的问题,准确性不是什么大问题,所以只做一个if语句来检查是否small_number那么更通用的方法是什么? 最佳答案 f.printf"Mynumber:%.5f\n",small_number您可以将.5(小数点右侧5位数字)替换为您喜欢的任何特定格式大小,例如,%8
我有一个启动DRb服务的脚本,然后生成处理程序对象并通过DRb.thread.join等待。我希望脚本一直运行直到被明确杀死,所以我添加了trap"INT"doDRb.stop_serviceend在Ruby1.8下成功停止DRb服务并退出,但在1.9下似乎死锁(在OSX10.6.7上)。对该进程进行采样显示在semaphore_wait_signal_trap中有几个线程在旋转。我假设我在调用stop_service时做错了什么,但我不确定是什么。谁能给我任何关于如何正确处理它的指示? 最佳答案 好的,我想我已经找到了解决方案。如
我只是在做一些与大学相关的Diffie-Hellman练习,并尝试使用ruby。遗憾的是,ruby似乎无法处理大指数:warning:ina**b,bmaybetoobigNaN[...]有什么办法吗?(例如,特殊的数学课或类似的东西?)附注这是有问题的代码:generator=7789prime=1017473alice_secret=415492bob_secret=725193putsfrom_alice_to_bob=(generator**alice_secret)%primeputsfrom_bob_to_alice=(generator**bob_secret)%pr
我试图删除括号内的文本(连同括号本身),但遇到括号内有括号的情况时遇到问题。这是我正在使用的方法(在Ruby中):sentence.gsub(/\(.*?\)/,"")在我写出如下句子之前一切正常:"Thisis(atest(string))"然后上面就噎住了。任何人都知道如何做到这一点?我完全被难住了。 最佳答案 一种方法是从内向外替换括号组:x=string.dupwhilex.gsub!(/\([^()]*\)/,"");endx 关于ruby-删除括号内的文本(括号内的括号概率)
我有一些代码可以根据加权随机数提供内容。权重越大的东西越有可能被随机选择。现在作为一名优秀的rubyist,我当然想用测试覆盖所有这些代码。我想测试是否根据正确的概率获取了东西。那么我该如何测试呢?为应该是随机的东西创建测试使得很难比较实际与预期。我有一些想法,以及为什么它们不会很好地工作:在我的测试中stubKernel.rand以返回固定值。这很酷,但是rand()被调用了多次,我不确定我是否可以通过足够的控制来装备它来测试我需要的东西。多次获取随机项目,并将实际比率与预期比率进行比较。但除非我可以无限次地运行它,否则这永远不会完美,并且如果我在RNG中运气不佳,可能会间歇性地
BigData/CloudComputing:基于阿里云技术产品的人工智能与大数据/云计算/分布式引擎的综合应用案例目录来理解技术交互流程目录一、云计算网站建设:部署与发布网站建设:简单动态网站搭建云服务器管理维护云数据库管理与数据迁移云存储:对象存储管理与安全超大流量网站的负载均衡二、大数据MOOC网站日志分析搭建企业级数据分析平台基于LBS的热点店铺搜索基于机器学习PAI实现精细化营销基于机器学习的客户流失预警分析使用DataV制作实时销售数据可视化大屏使用MaxCompute进行数据质量核查使用Quick BI制作图形化报表使用时间序列分解模型预测商品销量三、云安全云平台使用安全云上服务
我不太确定如何表达这一点,所以我只是举个例子。如果我写:some_method(["a","b"],3)我希望它返回某种形式的[{"a"=>0,"b"=>3},{"a"=>1,"b"=>2},{"a"=>2,"b"=>1},{"a"=>3,"b"=>0}]如果我传入some_method(%w(abc),2)期望的返回值应该是[{"a"=>2,"b"=>0,"c"=>0},{"a"=>1,"b"=>1,"c"=>0},{"a"=>1,"b"=>0,"c"=>1},{"a"=>0,"b"=>2,"c"=>0},{"a"=>0,"b"=>1,"c"=>1},{"a"=>0,"b"=>0,"
文章目录概述定义使用场景特点工作流程连接器转换为何选择SeaTunnel安装下载配置文件部署模式入门示例启动脚本配置文件使用参数示例Kafka进Kafka出的ETL示例FlinkRun传递参数概述定义SeaTunnel官网http://seatunnel.incubator.apache.org/SeaTunnel最新版本官网文档http://seatunnel.incubator.apache.org/docs/2.1.3/intro/aboutSeaTunnelGitHub地址https://github.com/apache/incubator-seatunnelSeaTunnel是一个
假设给您三个“选项”,A、B和C。您的算法必须随机选择并返回一个。为此,只需将它们放在一个数组{A,B,C}中并生成一个随机数(0、1或2),这将是元素在返回数组。现在,这个算法有一个变体:假设A有40%的机会被选中,B有20%,而C40%。如果是这种情况,您可以采用类似的方法:生成一个数组{A,A,B,C,C}并生成一个随机数(0,1,2,3,4)选择要返回的元素。行得通。但是,我觉得效率很低。想象一下,将此算法用于大量选项。你会创建一个有点大的数组,可能有100个元素,每个元素代表1%。现在,这仍然不是很大,但假设您的算法每秒使用多次,这可能会很麻烦。我考虑过创建一个名为Slot的