Tensorflow.js 官方提供了很多常用模型库,涵盖了平时开发中大部分场景的模型。例如,前面提到的图片识别,除此之外还有人体姿态识别,目标物体识别,语音文字等识别。其中一些可能是 Python 转换而来,但都是开发人员用海量数据或资源训练的,个人觉得准确度能满足大部分功能开发要求。这里要介绍的是目标物体识别模型 ——CooSSD。
目标检测在机器视觉中已经很常见了,就是模型可以对图片或者视频中的物体进行识别,并预测其最大概率的名称和展示概率值。以下就先以 Github 上 Coo-SSD 图片目标检测为例,最后再弄一个视频的目标实时识别。
tensorflow.js 提供的例子是通过 yarn,由于我本地环境原因,就以 npm 和 parcel 运行其效果。先本地创建项目文件夹,然后再分别创建 index.html, script.js, package.json 和添加几张图片。
1. 依赖包安装
(1). package.json 配置,安装 tfjs-backend-cpu, tfjs-backend-webgl 和模型
{
"name": "tfjs-coco-ssd-demo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"dependencies": {
"@tensorflow-models/coco-ssd": "^2.2.2",
"@tensorflow/tfjs-backend-cpu": "^3.3.0",
"@tensorflow/tfjs-backend-webgl": "^3.3.0",
"@tensorflow/tfjs-converter": "^3.3.0",
"@tensorflow/tfjs-core": "^3.3.0",
"stats.js": "^0.17.0"
},
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"browserslist": [
"last 1 Chrome version"
]
}(2). 命令切换到项目目录,运行 npm install
2. 代码:
(1). index.html
<h1>TensorFlow.js Object Detection</h1><selectid='base_model'>
<optionvalue="lite_mobilenet_v2">SSD Lite Mobilenet V2</option>
<optionvalue="mobilenet_v1">SSD Mobilenet v1</option>
<optionvalue="mobilenet_v2">SSD Mobilenet v2</option></select><buttontype="button"id="run">Run</button><buttontype="button"id="toggle">Toggle Image</button><div><imgid="image" /><canvasid="canvas"width="600"height="399"></canvas></div><scriptsrc="script.js"></script>(2). script.js
import'@tensorflow/tfjs-backend-cpu';
import'@tensorflow/tfjs-backend-webgl';
import * as cocoSsd from'@tensorflow-models/coco-ssd';
import imageURL from'./image3.jpg';
import image2URL from'./image5.jpg';
let modelPromise;
window.onload = () => modelPromise = cocoSsd.load();
const button = document.getElementById('toggle');
button.onclick = () => {
image.src = image.src.endsWith(imageURL) ? image2URL : imageURL;
};
const select = document.getElementById('base_model');
select.onchange = async (event) => {
const model = await modelPromise;
model.dispose();
modelPromise = cocoSsd.load(
{base: event.srcElement.options[event.srcElement.selectedIndex].value});
};
const image = document.getElementById('image');
image.src = imageURL;
const runButton = document.getElementById('run');
runButton.onclick = async () => {
const model = await modelPromise;
console.log('model loaded');
console.time('predict1');
const result = await model.detect(image);
console.timeEnd('predict1');
const c = document.getElementById('canvas');
const context = c.getContext('2d');
context.drawImage(image, 0, 0);
context.font = '10px Arial';
console.log(result);
console.log('number of detections: ', result.length);
for (let i = 0; i < result.length; i++) {
context.beginPath();
context.rect(...result[i].bbox);
context.lineWidth = 1;
context.strokeStyle = 'green';
context.fillStyle = 'green';
context.stroke();
context.fillText(
result[i].score.toFixed(3) + ' ' + result[i].class, result[i].bbox[0],
result[i].bbox[1] > 10 ? result[i].bbox[1] - 5 : 10);
}
};(3). 切换到项目目录,运行 parcel index.html
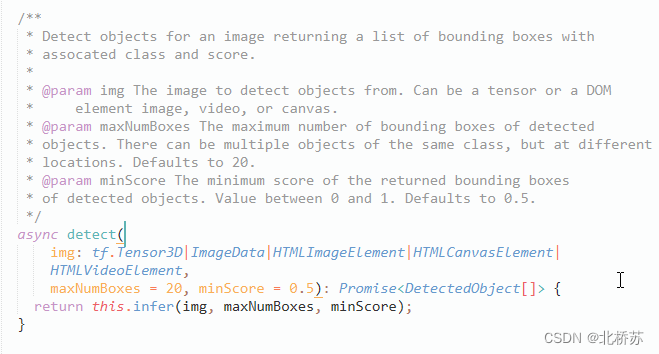
3. 运行效果
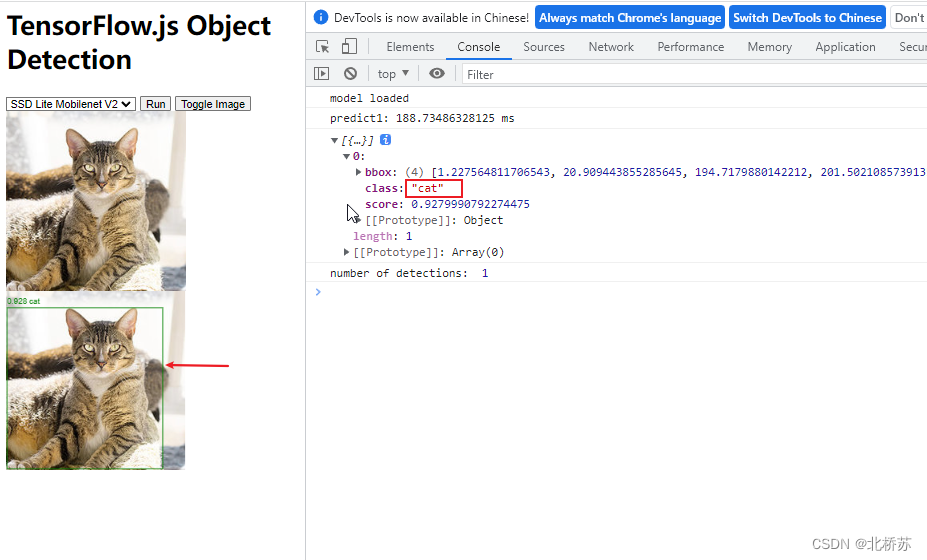
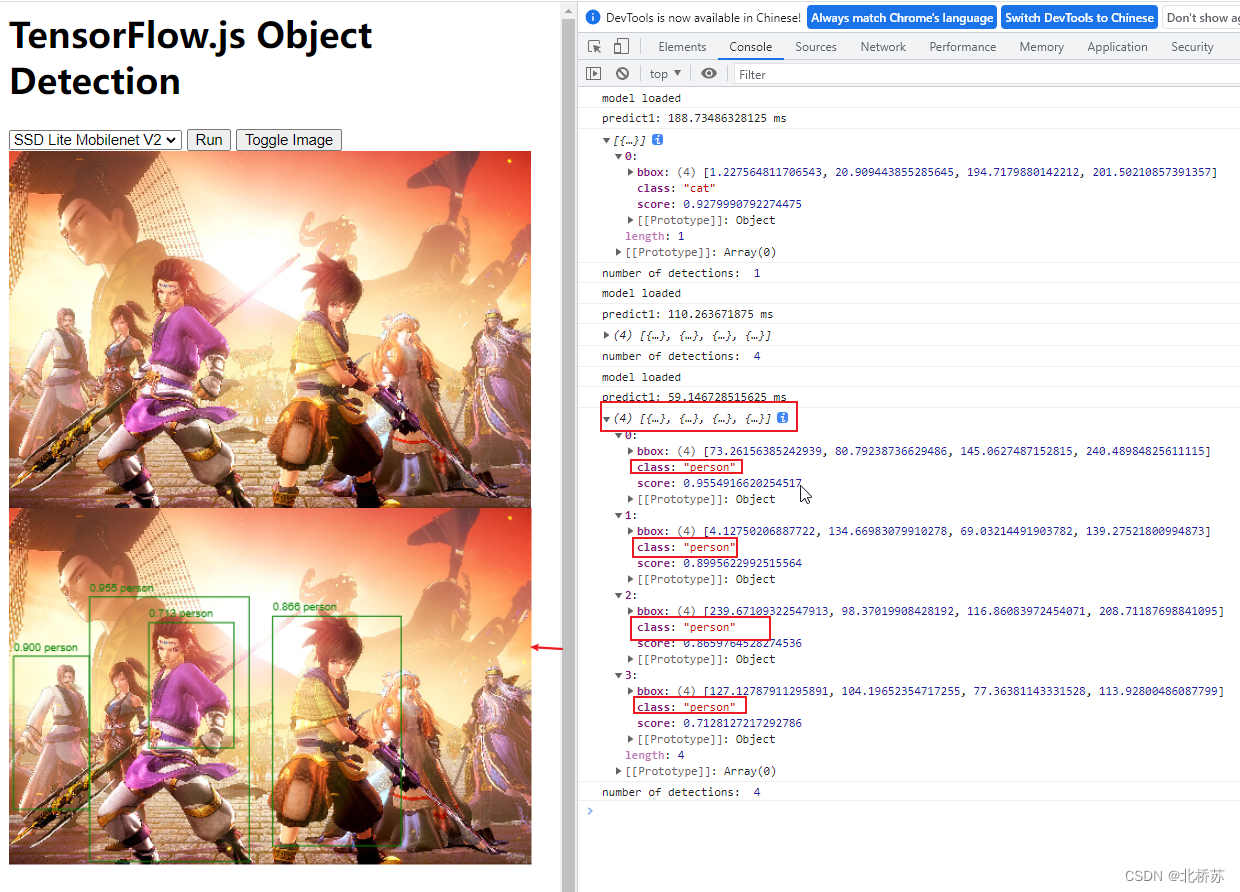
经过上面 demo 的图片检测发现,用于对某资源 (图片,视频) 进行检测的函数是 detect ()。查看该函数所处 Coco-SSD 文件发现,detect 函数接收三个参数,第一个参数可以是 tensorflow 张量,也可以分别是 DOM 里的图片,视频,画布等 HTML 元素,第二第三个参数分别用于过滤返回结果的最大识别目标数和最小概率目标,而返回自然就是一个 box, 按概率值降序排列。
1. 实现流程:
(1). 给视频标签添加播放监听
(2). 页面渲染完成加载 Coco-SSD 模型
(3). 模型加载成功轮询识别视频 (video 标签)
(4). 监听到视频播放停止关闭轮询检测
2. 编码:
(1). html 部分
<style>#big-box {
position: relative;
}
#img-box {
position: absolute;
top: 0px;
left: 0px;
}
#img-boxdiv {
position: absolute;
/*border: 2px solid #f00;*/pointer-events: none;
}
#img-boxdiv.className {
position: absolute;
top: 0;
/* background: #f00; */color: #fff;
}
#myPlayer {
max-width: 600px;
width: 100%;
}
</style><divid="showBox">等待模型加载...</div><br><divid="big-box"><videoid="myPlayer"muted="true"autoplaysrc="persons.mp4"controls=""playsinline=""webkit-playsinline=""></video><divid="img-box"></div></div><scriptsrc="persons.js"></script>(2). js 部分
import'@tensorflow/tfjs-backend-cpu';
import'@tensorflow/tfjs-backend-webgl';
import * as cocoSsd from'@tensorflow-models/coco-ssd';
var myModel = null;
var V = null;
var requestAnimationFrameIndex = null;
var myPlayer = document.getElementById("myPlayer");
var videoHeight = 0;
var videoWidth = 0;
var clientHeight = 0;
var clientWidth = 0;
var modelLoad = false;
var videoLoad = false;
window.onload = function () {
myPlayer.addEventListener("canplay", function () {
videoHeight = myPlayer.videoHeight;
videoWidth = myPlayer.videoWidth;
clientHeight = myPlayer.clientHeight;
clientWidth = myPlayer.clientWidth;
V = this;
videoLoad = true;
})
loadModel();
}
functionloadModel() {
if (modelLoad) {
return;
}
cocoSsd.load().then(model => {
var showBox = document.getElementById("showBox");
showBox.innerHTML = "载入成功";
myModel = model;
detectImage();
modelLoad = true;
});
}
functiondetectImage() {
var showBox = document.getElementById("showBox");
// 分类名var classList = [];
// 分类颜色框var classColorMap = ["red", "green", "blue", "white"];
// 颜色角标var colorCursor = 0;
showBox.innerHTML = "检测中...";
if (videoLoad) {
myModel.detect(V).then(predictions => {
showBox.innerHTML = "检测结束";
const $imgbox = document.getElementById('img-box');
$imgbox.innerHTML = ""
predictions.forEach(box => {
if (classList.indexOf(box.class) != -1) {
classList.push(box.class);
}
console.log(box);
var borderColor = classColorMap[colorCursor%4];
// console.log(colorCursor);// console.log(borderColor);const $div = document.createElement('div')
//$div.className = 'rect';
$div.style.border = "2px solid "+borderColor;
var heightScale = (clientHeight / videoHeight);
var widthScale = (clientWidth / videoWidth)
var transformTop = box.bbox[1] * heightScale;
var transformLeft = box.bbox[0] * widthScale;
var transformWidth = box.bbox[2] * widthScale;
var transformHeight = box.bbox[3] * heightScale;
var score = box.score.toFixed(3);
$div.style.top = transformTop + 'px'
$div.style.left = transformLeft + 'px'
$div.style.width = transformWidth + 'px'
$div.style.height = transformHeight + 'px'
$div.innerHTML = `<span class='className'>${box.class}${score}</span>`
$imgbox.appendChild($div)
colorCursor++;
})
setTimeout(function () {
detectImage();
}, 10);
});
}
}3. 演示效果
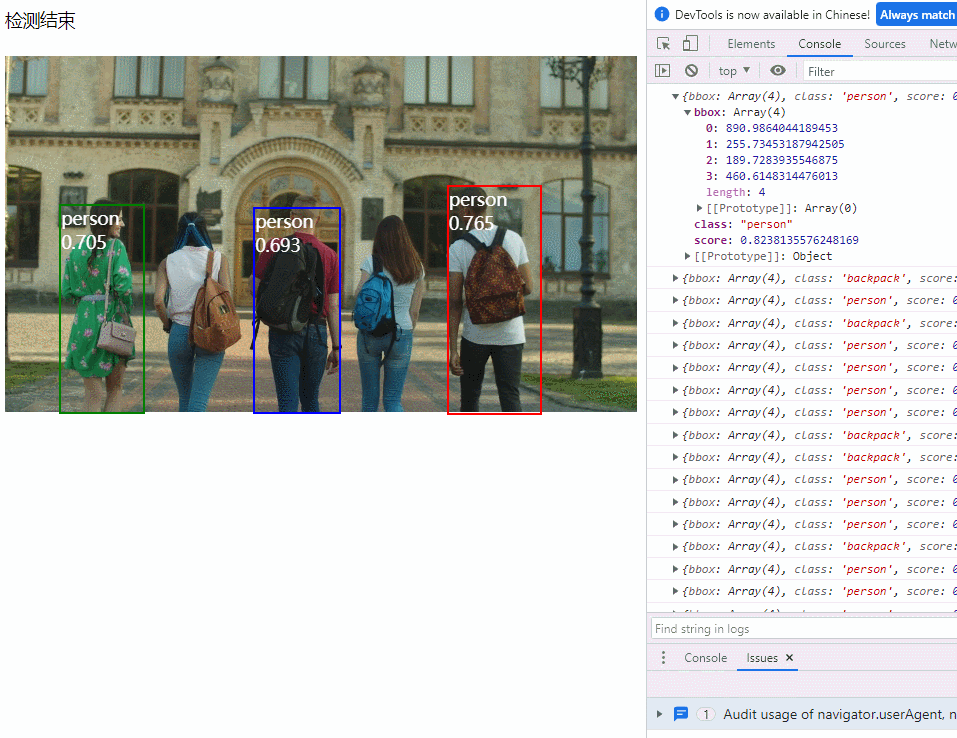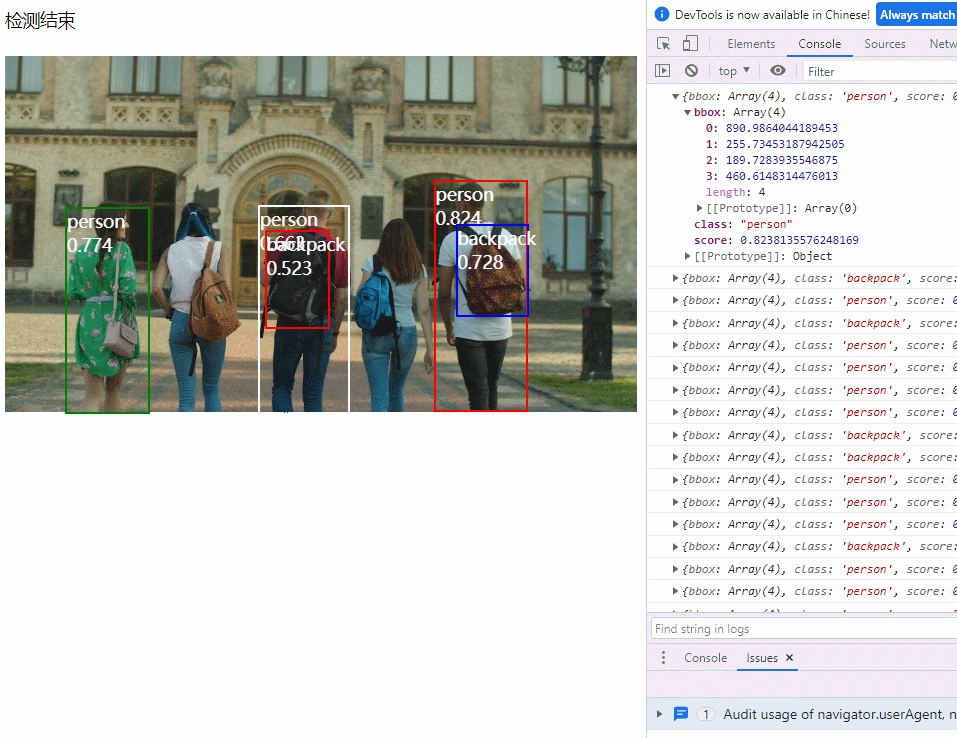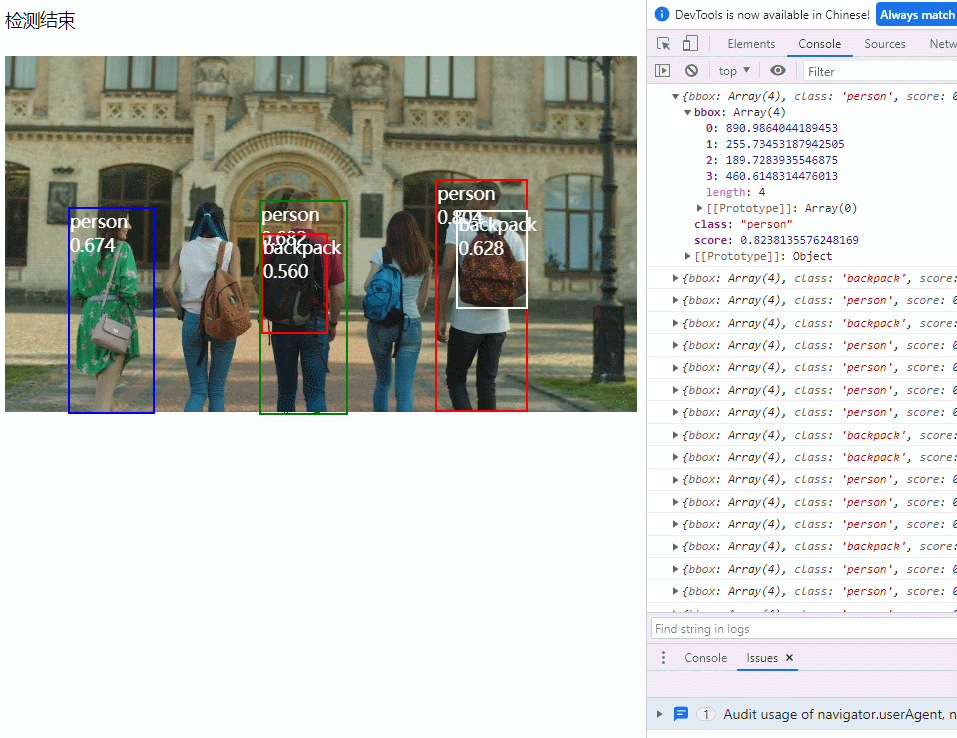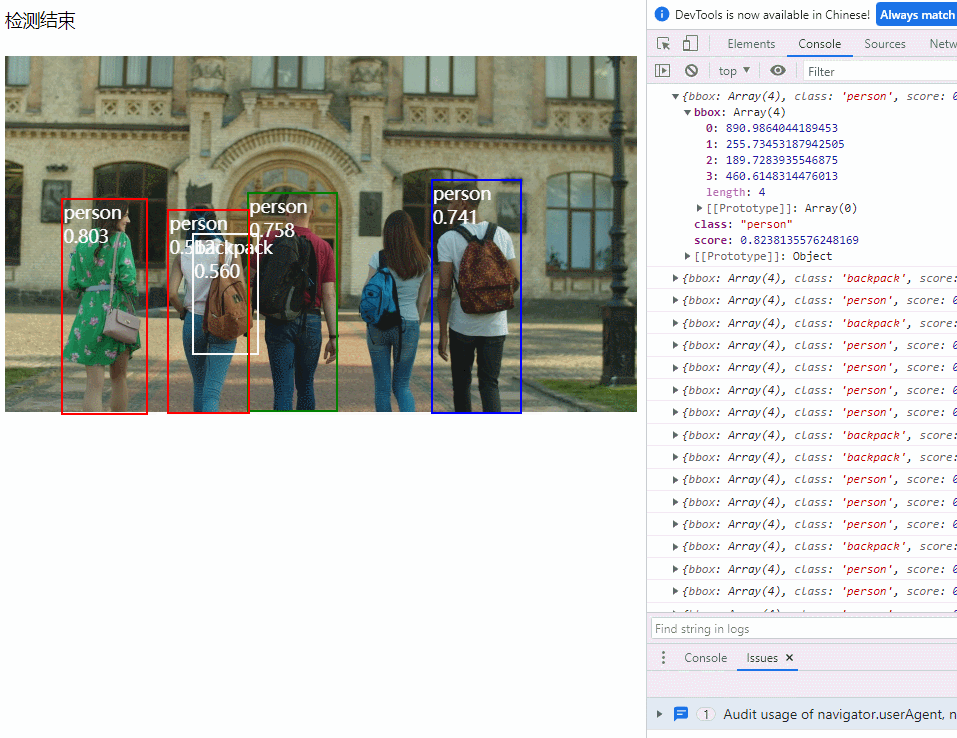
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我是Rails的新手,所以请原谅简单的问题。我正在为一家公司创建一个网站。那家公司想在网站上展示它的客户。我想让客户自己管理这个。我正在为“客户”生成一个表格,我想要的三列是:公司名称、公司描述和Logo。对于名称,我使用的是name:string但不确定如何在脚本/生成脚手架终端命令中最好地创建描述列(因为我打算将其设置为文本区域)和图片。我怀疑描述(我想成为一个文本区域)应该仍然是描述:字符串,然后以实际形式进行调整。不确定如何处理图片字段。那么……说来话长:我在脚手架命令中输入什么来生成描述和图片列? 最佳答案 对于“文本”数
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
我想知道我的代码是否在rspec下运行。这可能吗?原因是我正在加载一些错误记录器,这些记录器在测试期间会被故意错误(expect{x}.toraise_error)弄得乱七八糟。我查看了我的ENV变量,没有(明显的)测试环境变量的迹象。 最佳答案 在spec_helper.rb的开头添加:ENV['RACK_ENV']='test'现在您可以在代码中检查RACK_ENV是否经过测试。 关于ruby-检测由RSpec、Ruby运行的代码,我们在StackOverflow上找到一个类似的问题
我正在使用rubydaemongem。想知道如何向停止操作添加一些额外的步骤?希望我能检测到停止被调用,并向其添加一些额外的代码。任何人都知道我如何才能做到这一点? 最佳答案 查看守护程序gem代码,它似乎没有用于此目的的明显扩展点。但是,我想知道(在守护进程中)您是否可以捕获守护进程在发生“停止”时发送的KILL/TERM信号...?trap("TERM")do#executeyourextracodehereend或者你可以安装一个at_exit钩子(Hook):-at_exitdo#executeyourextracodehe
我正在尝试找出一种方法来显示来自不在RAILS_ROOT下(在RedHat或Ubuntu环境中)的已安装文件系统的图像。我不想使用符号链接(symboliclink),因为这个应用程序实际上是通过Tomcat部署的,而当我关闭Tomcat时,Tomcat会尝试跟随符号链接(symboliclink)并删除挂载中的所有图像。由于这些文件的数量和大小,将图像放在public/images下也不是一种选择。我查看了send_file,但它只会显示一张图片。我需要在一个格式良好的页面中显示6个请求的图像。由于膨胀,我宁愿不使用Base64编码,但我不知道如何将图像数据与呈现的页面一起传递下去。
我开始了一个新的Rails3.2.5项目,Assets管道不再工作了。CSS和Javascript文件不再编译。这是尝试生成Assets时日志的输出:StartedGET"/assets/application.css?body=1"for127.0.0.1at2012-06-1623:59:11-0700Servedasset/application.css-200OK(0ms)[2012-06-1623:59:11]ERRORNoMethodError:undefinedmethod`each'fornil:NilClass/Users/greg/.rbenv/versions/1
rails新手。只是想了解\assests目录中的这两个文件。例如,application.js文件有如下行://=requirejquery//=requirejquery_ujs//=require_tree.我理解require_tree。只是将所有JS文件添加到当前目录中。根据上下文,我可以看出requirejquery添加了jQuery库。但是它从哪里得到这些jQuery库呢?我没有在我的Assets文件夹中看到任何jquery.js文件——或者直接在我的整个应用程序中没有看到任何jquery.js文件?同样,我正在按照一些说明安装TwitterBootstrap(http: