文章目录
欢迎大家关注我的公众号:智聊对话机器人,我会定期分享技术观点、投资心得、生活随想等内容。
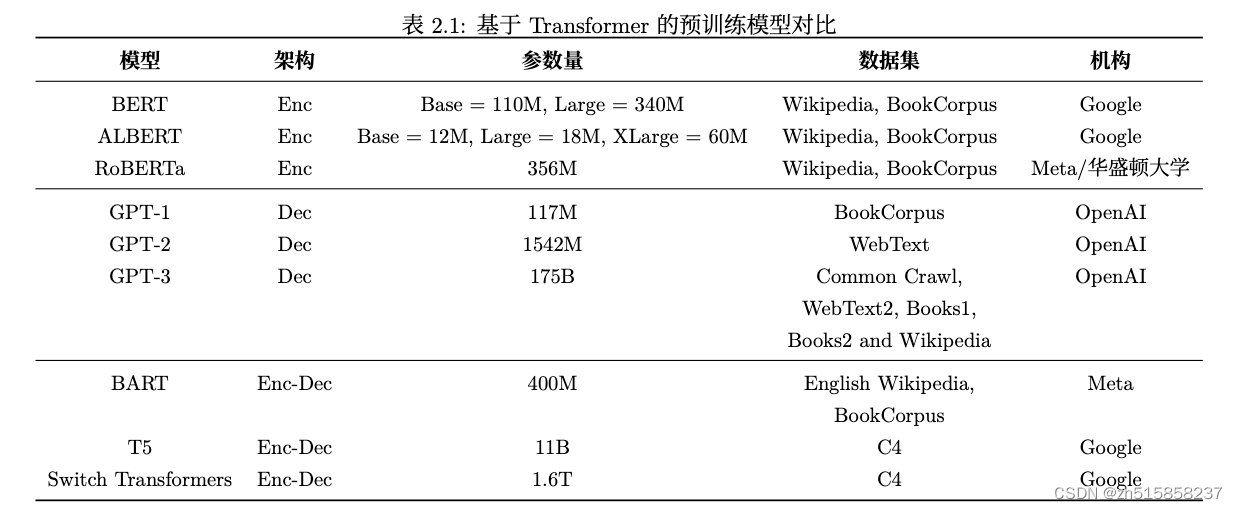
GPT从开始至今,其发展历程如下:
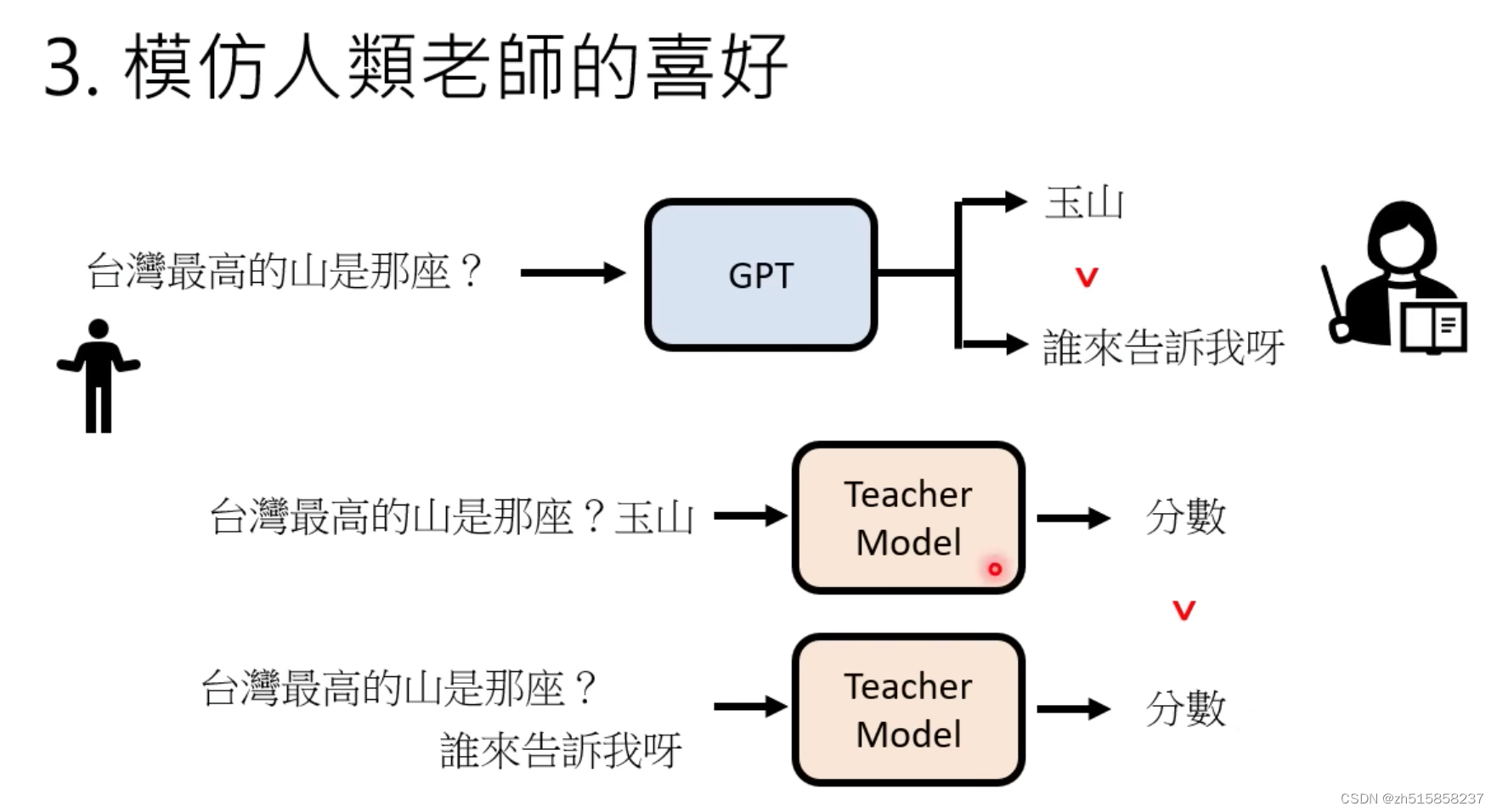
目标不一样。传统语言模型主要是预测一句话中下一个词是什么。而instructGPT的目标是:follow the user’s instructions helpfully and safely
instructGPT跟GPT-3的网络结构是一样的,区别在于训练阶段的不同,instructGPT使用了标注数据进行fine-tune
GPT 中训练的是单向语言模型,其实就是直接应用 Transformer Decoder;
Bert 中训练的是双向语言模型,应用了 Transformer Encoder 部分,不过在 Encoder 基础上还做了 Masked 操作;
BERT Transformer 使用双向 self-attention,而 GPT Transformer 使用受限制的 self-attention,其中每个 token 只能处理其左侧的上下文。

GPT-3主要聚焦于更通用的NLP模型,解决当前BERT类模型的两个缺点:
因此GPT-3的主要目标是用更少的领域数据、且不经过精调步骤去解决问题。
对于一个少样本的任务来说,模型的初始化值非常重要,从一个好的初始化值作为起点,模型能够尽快收敛,使得到的结果非常快的逼近全局最优解。元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
chatGPT有很强的归纳能力和泛化记忆能力。但是在推演和演绎方面,超大规模语言模型在符号推理、输出可控和可解释方面还较弱,并且容易犯事实性错误。
例如,你问刘德华的电影有哪些,但是chatGPT却返回一堆周星驰或者其他人的电影

import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
# ------- 文本生成 ---------
prompt = """We’re releasing an API for accessing new AI models developed by OpenAI. Unlike most AI systems which are designed for one use-case, the API today provides a general-purpose “text in, text out” interface, allowing users to try it on virtually any English language task. You can now request access in order to integrate the API into your product, develop an entirely new application, or help us explore the strengths and limits of this technology."""
response = openai.Completion.create(model="davinci", prompt=prompt, stop="\n", temperature=0.9, max_tokens=100)
# ------- 其它应用 ---------
response = openai.Completion.create(
engine="davinci",
prompt="The following is a conversation with an AI assistant. The assistant is helpful, creative, clever, and very friendly.\n\nHuman: Hello, who are you?\nAI: I am an AI created by OpenAI. How can I help you today?\nHuman: I'd like to cancel my subscription.\nAI:",
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["\n", " Human:", " AI:"]
)
print(response)
人类大脑有860亿神经元、100-1000万亿联接,能处理的任务也远远超过GPT-3。如果一个联接就相当于有一个参数,那么粗略估计人脑可能可以通过100-1000万亿的模型参数来模拟,目前的chatGPT的1750亿参数看来,参数规模还需要再扩大571倍至5710倍。
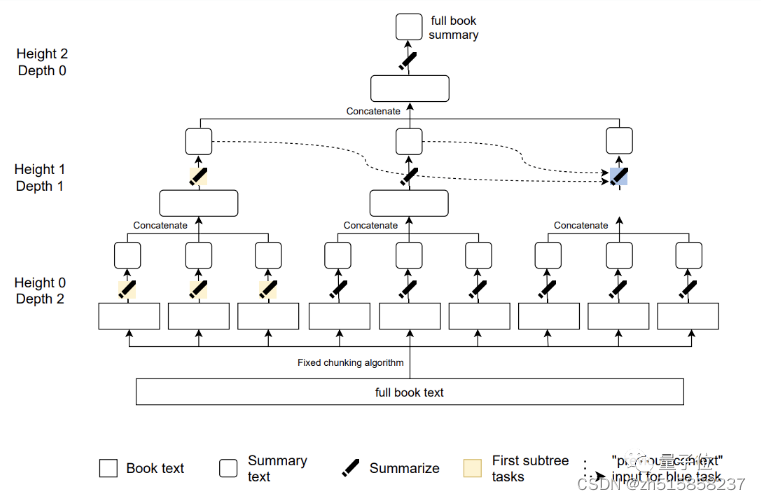
AI分四个阶段来总结:比如这样一段121567词的《傲慢与偏见》原文:
先把原文总结成276个摘要(24796词),然后进一步压缩成25个摘要(3272词),再到4个摘要(475词)。
最终得到一段175词的摘要,长度只有原片段的千分之一:
【奖励模型训练】 该阶段旨在获取拟合人类偏好的奖励模型。奖励模型以提示和回复作为输入,计算标量奖励值作为输出。奖励模型的训练过程通过拟合人类对于不同回复的倾向性实现。具体而言,首先基于在人类撰写数据上精 调的模型,针对同一提示采样多条不同回复。然后,将回复两两组合构成一 条奖励模型训练样本,由人类给出倾向性标签。最终,奖励模型通过每条样本中两个回复的奖励值之差计算倾向性概率拟合人类标签
【生成策略优化】 给定习得的奖励模型,ChatGPT/InstructGPT 的参数将被 视为一种策略,在强化学习的框架下进行训练。首先,当前策略根据输入的查询采样回复。然后,奖励模型针对回复的质量计算奖励,反馈回当前策略用以更新。值得注意的是,为防止上述过程的过度优化,损失函数同时引入了词级别的 KL 惩罚项。
LoRA: Low-Rank Adaptation of Large Language Models 是微软研究员引入的一项新技术,主要用于处理大模型微调的问题。目前超过数十亿以上参数的具有强能力的大模型 (例如 GPT-3) 通常在为了适应其下游任务的微调中会呈现出巨大开销。LoRA 建议冻结预训练模型的权重并在每个 Transformer 块中注入可训练层 (秩-分解矩阵)。因为不需要为大多数模型权重计算梯度,所以大大减少了需要训练参数的数量并且降低了 GPU 的内存要求。研究人员发现,通过聚焦大模型的 Transformer 注意力块,使用 LoRA 进行的微调质量与全模型微调相当,同时速度更快且需要更少的计算。
目前,已经公布明确已经完成 千亿参数规模大模型训练的框架主要是 NVIDIA 开发的 Megatron-LM 、经 过微软深度定制开发的DeepSpeed、国产百度飞浆 PaddlePaddle 和华为昇思 MindSpore。大多数并行框架都支持 PyTorch 分布式训练,可以完成百亿参数规模的模型训练。
https://github.com/lucidrains/PaLM-rlhf-pytorch
https://github.com/lm-sys/FastChat
Vicuna 在总分上达到了 ChatGPT 的 92%
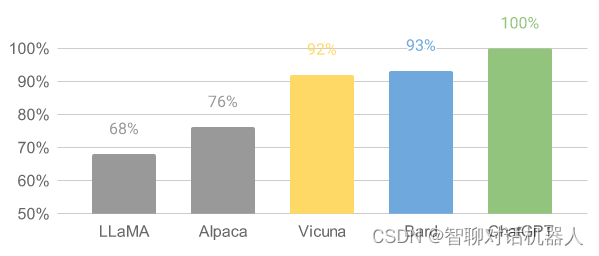
下面是LLaMA、Alpaca、Vicuna几个模型的差别

ChatGPT的核心模块包括SFT、RM、RLHF三个,当前的很多工作主要集中在复现SFT模块,只有ColossalChat 目前复现了SFT+RM+RLHF整个流程
1.1. 算法工作
| 项目 | 模块 | 备注 |
|---|---|---|
| LLaMA | 基础 | 提供了一个pre-train的backbone |
| Alpaca | SFT模块 | 基于self-instruct技术,做了指令微调 instruction fine-tune |
| Alpaca-Lora | SFT模块 | 利用LoRa技术,大大减少了需要微调的参数量 |
| Vicuna | SFT模块 | 目前最接近chatGPT的模型 |
| LMFlow | SFT模块 | 基于 70 亿参数的 LLaMA,只需 1 张 3090、耗时 5 小时,就可定制自己的GPT并完成网页端部署 |
| ColossalChat | 提供了SFT+RM+RLHF整个流程 | 无 |
1.2. 数据集
| 项目 | 备注 |
|---|---|
| AlpacaDataCleaned | 对Alpaca提供的52k数据进行了进一步清理 |
| Alpaca-CoT | 加入了思维链chain-of-thought数据 |
| InstructionWild | colossalChat开放的数据集 |
| shareGPT | 一个 ChatGPT 数据共享网站,用户会上传自己觉得有趣的 ChatGPT 回答。 |
1.3. 有限资源下的部署
llama.cpp
alpaca.cpp
欢迎大家关注我的公众号:智聊对话机器人,我会定期分享技术观点、投资心得、生活随想等内容。
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
2022年底,OpenAI的预训练模型ChatGPT给人工智能领域的爱好者和研究人员留下了深刻的印象和启发,他展现的惊人能力将人工智能的研究和应用热度推向高潮,网上也充斥着和ChatGPT的各种聊天,他可以作诗、写小说、写代码、讨论疫情问题等。下面就是一些他的神回复:人命关天的坑: 写歌,留给词作者的机会不多了。。。 回答人类怎么样面对人工智能: 什么是ChatGPT?借用网上的一段介绍,ChatGPT是由人工智能研究实验室OpenAI在2022年11月30日发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动
目录ChatGPT简介技术原理应用未来发展ChatGPT的10 种用法ChatGPT简介ChatGPT是一种基于深度学习的大型语言模型,由OpenAI公司开发。技术原理GPT是GenerativePre-trainedTransformer的缩写,意为生成式预训练变压器。它的技术原理是使用了一个基于注意力机制的变压器(Trans
♥️作者:白日参商🤵♂️个人主页:白日参商主页♥️坚持分析平时学习到的项目以及学习到的软件开发知识,和大家一起努力呀!!!🎈🎈加油!加油!加油!加油🎈欢迎评论💬点赞👍🏻收藏📂加关注+!「想体验ChatGPT中文聊天?」那快进来,你用不上算我输项目场景:项目条件一、那就开始吧1、安装ChatGPT-Desktop2、OpenAPI设置二、使用实例恭喜你!!!配置成功了!!!API和URL都是博主免费提供给大家的!!!恭喜你!!!配置成功了!!!API和URL都是博主免费提供给大家的!!!🎈🎈加油!加油!加油!加油🎈欢迎评论💬点赞👍🏻收藏📂加关注+!项目场景:近几个月可以说ChatGPT是火得一
TCP是面向连接的协议,连接的建立和释放是每一次面向连接的通信中必不可少的过程。TCP连接的管理就是使连接的建立和释放都能正常地进行。三次握手TCP连接的建立—三次握手建立TCP连接①若主机A中运行了一个客户进程,当它需要主机B的服务时,就发起TCP连接请求,并在所发送的分段中用SYN=1表示连接请求,并产生一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x。主机B收到A的连接请求报文,就完成了第一次握手。客户端发送SYN=1表示连接请求客户端发送一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x②主机B如果同意建立连接,则向主机A发送确认报
ChatGPT掀起了AI股历史上最疯狂的一轮市值狂飙。自春节后至今,ChatGPT概念股开始了暴走模式,短短半月时间,海天瑞声、开普云等ChatGPT概念股市值累计增加了近1400亿。如此的爆炸效应,得益于ChatGPT所展现出商业化落地的巨大潜力。要知道,在此之前,无论是十年AI投入超千亿的百度,还是困在硬件化里的AI四小龙,都在重复着AI商业化难落地的故事。ChatGPT的出现,让AI从生产力的赋能者直接成为一种创造生产力的工具。随着订阅模式的推出,ChatGPT已经成为第一个以AI技术为核心直接变现的消费者应用。本文持有以下核心观点:1、ChatGPT是AI技术迭代的受益者。过去受限技术
文章目录前言1.AI的发展历程2.我是如何接触到人工智能的概念和产品的3.对于ChatGPT的一点看法4.AI对大学毕业生的职业发展的利与弊5.对于AI的思考和问题前言随着ChatGPT的爆火,生成式AI,大模型的人工智能被越来越多的人注意到,同时他也带来了许多问题。本文将对几方面进行探讨。1.AI的发展历程远古时期在公元前第一个千禧年,中国,印度和希腊哲学家都提出了一些推理的研究理论,比如亚里士多德(Aristotle)进行了演绎推理三段论的完整分析,欧几里得(Euclid)所著Elements是一种形式推理的模型,MuḥammadibnMūsāal-Khwārizmī,发明了代数学,即我们