Elasticsearch(以下称之为ES)是一款基于Lucene的分布式全文搜索引擎,擅长海量数据存储、数据分析以及全文检索查询,它是一款非常优秀的数据存储与数据分析中间件,广泛应用于日志分析以及全文检索等领域,目前很多大厂都基于Elasticsearch开发了自己的存储中间件以及数据分析平台。
Lucene是Apache下的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,它是ES实现全文检索的核心基础,索引文档以及搜索索引的的核心流程都是在Lucene中完成的。
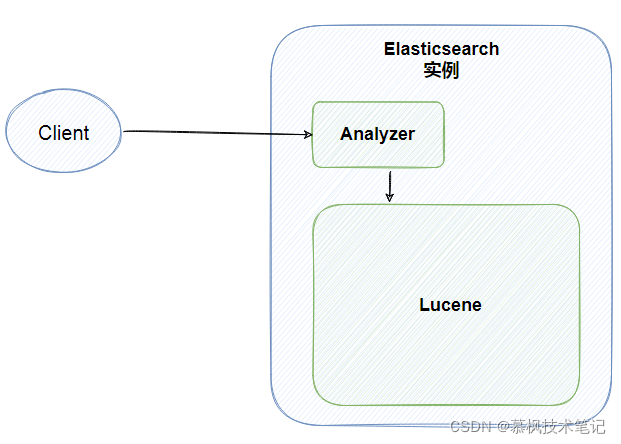
我们都说ES是面向document的,这句话什么意思呢?实际就是表示ES是基于document进行数据操作的,操作主要包括数据搜索以及索引(这里的索引时数据写入的意思)。因此可以说document是ES的基础数据结构,它会被序列化之后保存到ES中。那么这个document到底是个什么东东呢?相信大家都对Mysql还是比较熟悉的,因此我们用Mysql中的数据库与表的概念与ES的index进行对比,可能并不是十分的恰当和吻合,但是可以有助于大家对于这些概念的理解。另外type也在ES6.x版本之后逐渐取消了。
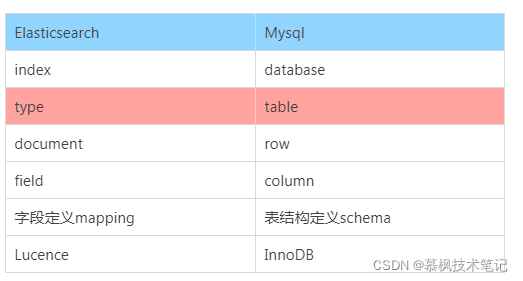
在ES之前的版本中,是有type这个概念的,类比数据库中的表,那上文中所说的document就会放在type中。但是在ES后面的版本中为了提高数据存储的效率逐渐取消了type,因此index实际上在现在的ES中既有库的概念也有表的概念。简单理解就是index就是文档的容器,它是一类文档的集合,但是这里需要注意的是index是逻辑空间的分类,实际数据是存在物理空间的分片上的。

另外需要说明的是,在ES中索引是有不同上下文含义的,它既可以是名词也可以是动词。索引为名词是就是上文中提到的它是document的集合,索引为动词的时候表示将document数据保存到ES中,也就是数据写入。

在ES中,为了屏蔽语言的交互差异,ES直接对外的交互都是通过Rest API进行的。
我们都知道索引存在的意义就是为了加速数据的查询。在关系型数据库中如果没有索引的话,为了查找数据我们需要每条数据去进行比对,运气不好的话可能需要扫描全表才能查找到想要的数据。以Mysql为例,它使用了B+树作为索引来加速数据的查询。假设有这样的一种场景,周末在路上逛的时候突然听到一首非常好听的歌曲,你记住了其中两句歌词,想着赶快拿手机到QQ音乐中查一下是什么歌。如果你是QQ音乐的程序猿,你该怎么实现根据歌词查询歌曲的功能呢?
用B+树作为索引行不行呢?全文索引就是需要支持对大文本进行索引的,从空间上来说 B+ 树不适合作为全文索引,同时 B+ 树因为每次搜索都是从根节点开始往下搜索,所以会遵循最左匹配原则,而我们使用全文搜索时,往往不会遵循最左匹配原则,所以可能会导致索引失效。这时候倒排索引就派上用场了。
所谓正排索引就像书中的目录一样,根据页码查询内容,但是倒排索引确实相反的,它是通过对内容的分词,建立内容到文档ID的关联关系。这样在进行全文检索的时候,根据词典的内容便可以精确以及模糊查询,非常符合全文检索的要求。
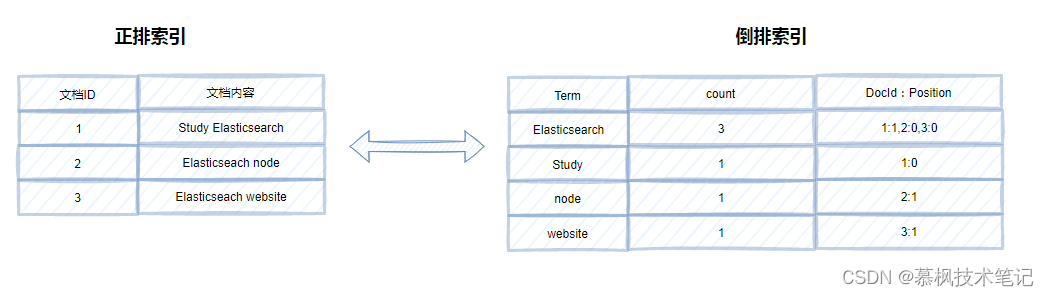
倒排索引的结构主要包括了两大部分一个是Term Dictionary(单词词典),另一个是Posting List(倒排列表)。Term Dictionary(单词词典)记录了所用文档的单词以及单词和倒排列表的关系。Posting List(倒排列表)则是记录了term在文档中的位置以及其他信息,主要包括文档ID,词频(term在文档中出现的次数,用来计算相关性评分),位置以及偏移(实现搜索高亮)。
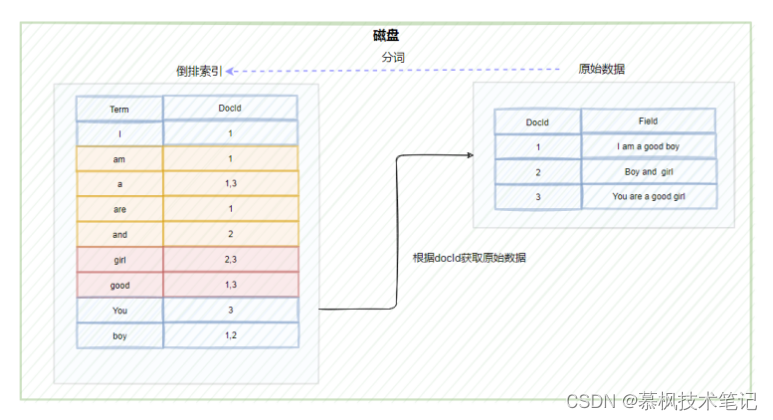
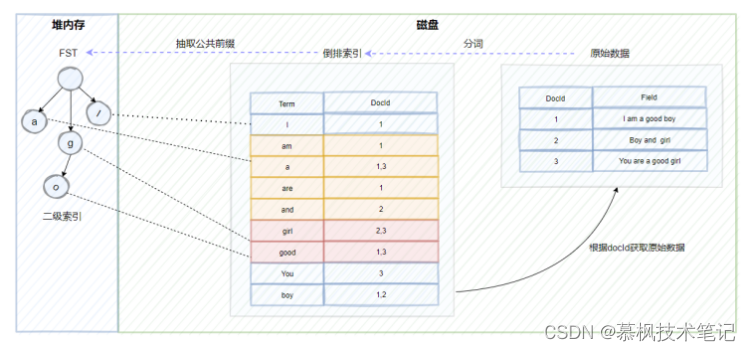
如上文所述,在进行全文检索的时候,通过倒排索引中term与docId的关联关系获取到原始数据。但是这里有一个问题,ES底层依赖Lucene实现倒排索引的,因此在进行数据写入的时候,Lucene会为原始数据中的每个term生成对应的倒排索引,因此造成的结果就是倒排索引的数据量就会很大。而倒排索引对应的倒排表文件是存储在硬盘上的。如果每次查询都直接去磁盘中读取倒排索引数据,在通过获取的docId再去查询原始数据的话,肯定会造成多次的磁盘IO,严重影响全文检索的效率。因此我们需要一种方式可以快速定位到倒排索引中的term。大家想想使用什么方式比较好呢?可以考虑HashMap, TRIE, Binary Search Tree或者Tenary Search Tree等数据结构,实际上Lucene实际是使用了FST(Finite State Transducer)有限状态传感器来实现二级索引的设计,它其实就是一种有限状态机。
我们先来看下 trie树的结构,在Lucene中是这样做的,将倒排索引中具有公共前缀的term组成一个block,如下图所示的cool以及copy,它们拥有co的公共前缀,按照类似前缀树的逻辑来构成trie树,对应节点中携带block的首地址。我们来分析下trie树相比hashmap有什么优点?hashmap实现的是精准查找,但是trie树不仅可以实现精准查找,另外由于其公共前缀的特性还可以实现模糊查找。那我们再看trie树有什么地方可以再进行优化的地方?
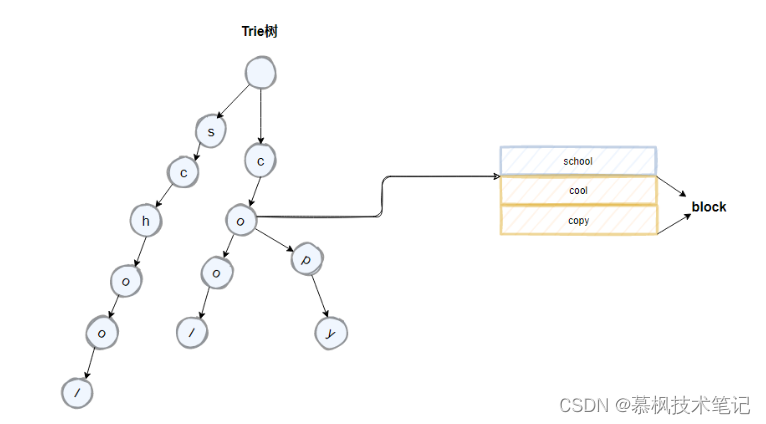
如上如所示,term中的school以及cool的后面字符是一致的,因此我们可以通过将原先的trie树中的后缀字符进行合并来进一步的压缩空间。优化后的trie树就是FST。
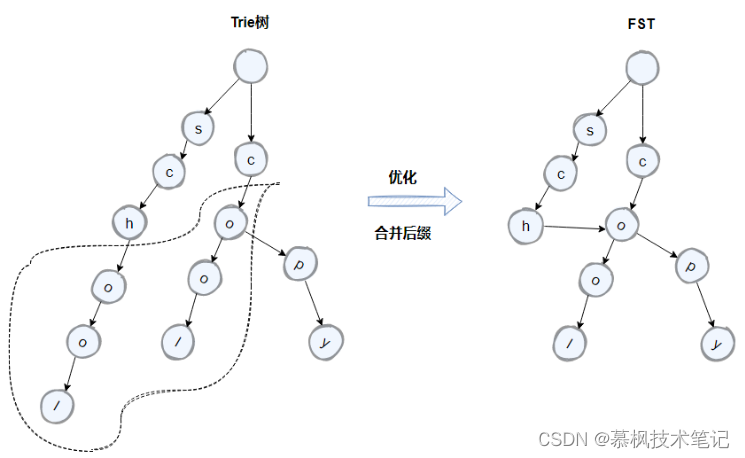
因此通过建立FST这个二级索引,可以实现倒排索引的快速定位,不需要经过多次的磁盘IO,搜索效率大大提高了。不过需要注意的是FST是存储在堆内存中的,而且是常驻内存,大概占用50%-70%的堆内存,因此这里也是我们在生产中可以进行堆内存优化的地方。
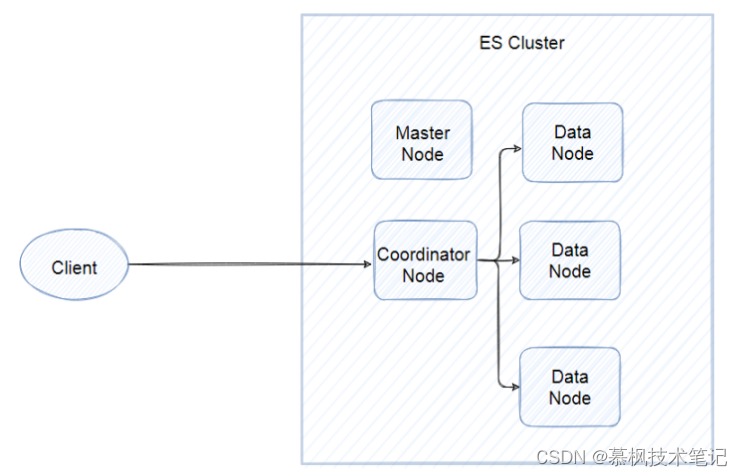
为了增强ES的数据存储可靠性以及高可用,ES支持进行集群部署,集群后的ES即便是某些节点出现故障,也不会导致真个ES集群不可用,同时通过水平扩容增强了ES的数据存储能力。
所谓的节点实际就是ES的实例,我们通常在一台服务器部署一个ES实例,其实就是一个Java进程。虽然都是ES实例,但是实际上的ES集群,不同节点承担着不同的能力角色,有的是data node,主要负责保存分片的数据的,承担着数据横向扩展的重要作用,有的是coordinating node负责将用户请求进行转发以及将查询的结果进行合并返回。当然还有master节点,负责对真个集群状态进行管理和维护。
单个ES节点的数据存储毕竟有限,没法实现海量数据的存储要求。那么怎么才能满足海量数据的存储要求呢?一个核心思想就是拆分,比如总共10亿条数据,如果都放在一个节点中不仅查询以及数据写入的速度回很慢,页存在单点问题。在传统关系型数据库中,采用分库分表的方式,用更多的数据库实例来承接大量的数据存储。那么在ES中,也是采取类似的设计思想,既然一个ES的实例存在数据存储的上线,那么就用多个实例来进行存储。在每个实例中存在的数据集合就是分片。如下图所示,index被切分成三个分片,三个分片分别存储在三个ES实例中,同时为了提升数据的高可用性,每个主分片都有两个副本分片,这些副本分片是主分片的数据拷贝。
put /article
{
"settings": {
"number_of_shards":3,
"number_of_replicas":3
}
}
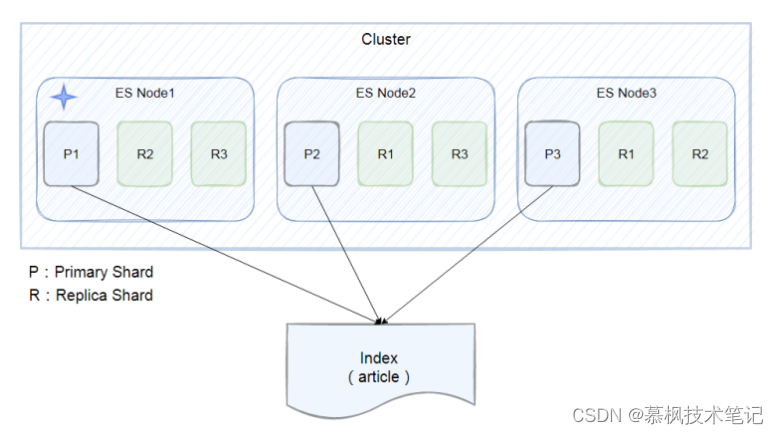
这里需要注意的是,分片不是随意进行设定的,而是需要根据实际的生产环境提前进行数据存储的容量规划,否则分片设置的过大或者过小都会影响ES集群的整体性能。如果分片设置的过小,那么单个分片的数据量可能会很大,影响数据检索效率,也会影响数据的横向扩展。如果分片设置的过大就会影响搜索结果的数据相关性评分,影响数据检索的准确性。
本文对ES的核心概念进行了全面的梳理与阐述,相信大家对于ES有了初步的了解,下篇文章中再带大家好好理解下ES的核心业务流程的原理以及优秀的设计思想,只有理解了ES的核心概念以及核心流程,那么在生产中遇到一些搜索优化、节点JVM优化等才会有对应的排查方向,另外ES中的一些优秀的设计思想,也是非常值得我们学习的,当我们在设计软件平台的时候有时可以借鉴这些优秀的设计思想。
大家好,我是慕枫,感谢各位小伙伴点赞、收藏和评论,文章持续更新,我们下期再见!
微信搜索:慕枫技术笔记,优质文章持续更新,我们有学习打卡的群可以拉你进,一起努力冲击大厂,另外有很多学习以及面试的材料提供给大家。
真正的大师永远怀着一颗学徒的心

关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭3年前。Improvethisquestion我正处于学习Ruby的阶段,我想查看一些小型库的源代码以了解它们是如何构建的。我不知道什么是小型图书馆,但希望SO能推荐一些易于理解的图书馆来学习。因此,如果有人知道一两个非常小的库,这是新手Rubyists学习的好例子,请推荐!我想使用Manveru'sInnatelib,因为它试图保持在2000LOC以下,但我还不熟悉其中经常使用的Ruby速记。也许大约100-5
由于匿名block和散列block看起来大致相同。我正在玩它。我做了一些严肃的观察,如下所示:{}.class#=>Hash好的,这很酷。空block被视为Hash。print{}.class#=>NilClassputs{}.class#=>NilClass为什么上面的代码和NilClass一样,下面的代码又显示了Hash?puts({}.class)#Hash#=>nilprint({}.class)#Hash=>nil谁能帮我理解上面发生了什么?我完全不同意@Lindydancer的观点你如何解释下面几行:print{}.class#NilClassprint[].class#A
我刚刚安装了带有RVM的Ruby2.2.0,并尝试使用它得到了这个:$rvmuse2.2.0--defaultUsing/Users/brandon/.rvm/gems/ruby-2.2.0dyld:Librarynotloaded:/usr/local/lib/libgmp.10.dylibReferencedfrom:/Users/brandon/.rvm/rubies/ruby-2.2.0/bin/rubyReason:Incompatiblelibraryversion:rubyrequiresversion13.0.0orlater,butlibgmp.10.dylibpro
我正在运行Ubuntu11.10并像这样安装Ruby1.9:$sudoapt-getinstallruby1.9rubygems一切都运行良好,但ri似乎有空文档。ri告诉我文档是空的,我必须安装它们。我执行此操作是因为我读到它会有所帮助:$rdoc--all--ri现在,当我尝试打开任何文档时:$riArrayNothingknownaboutArray我搜索的其他所有内容都是一样的。 最佳答案 这个呢?apt-getinstallri1.8编辑或者试试这个:(非rvm)geminstallrdocrdoc-datardoc-da