深度学习12. CNN经典网络 VGG16

VGG(Visual Geometry Group)是一个视觉几何组在2014年提出的深度卷积神经网络架构。
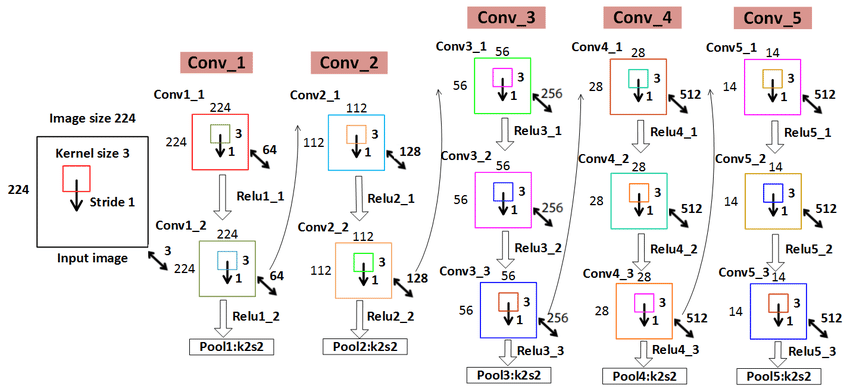
VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG19最为著名。
VGG16和VGG19网络架构非常相似,都由多个卷积层和池化层交替堆叠而成,最后使用全连接层进行分类。两者的区别在于网络的深度和参数量,VGG19相对于VGG16增加了3个卷积层和一个全连接层,参数量也更多。
VGG网络被广泛应用于图像分类、目标检测、语义分割等计算机视觉任务中,并且其网络结构的简单性和易实现性使得VGG成为了深度学习领域的经典模型之一。
本文参考内容:https://www.kaggle.com/code/blurredmachine/vggnet-16-architecture-a-complete-guide
下图中的D就是VGG16,E就是VGG19。
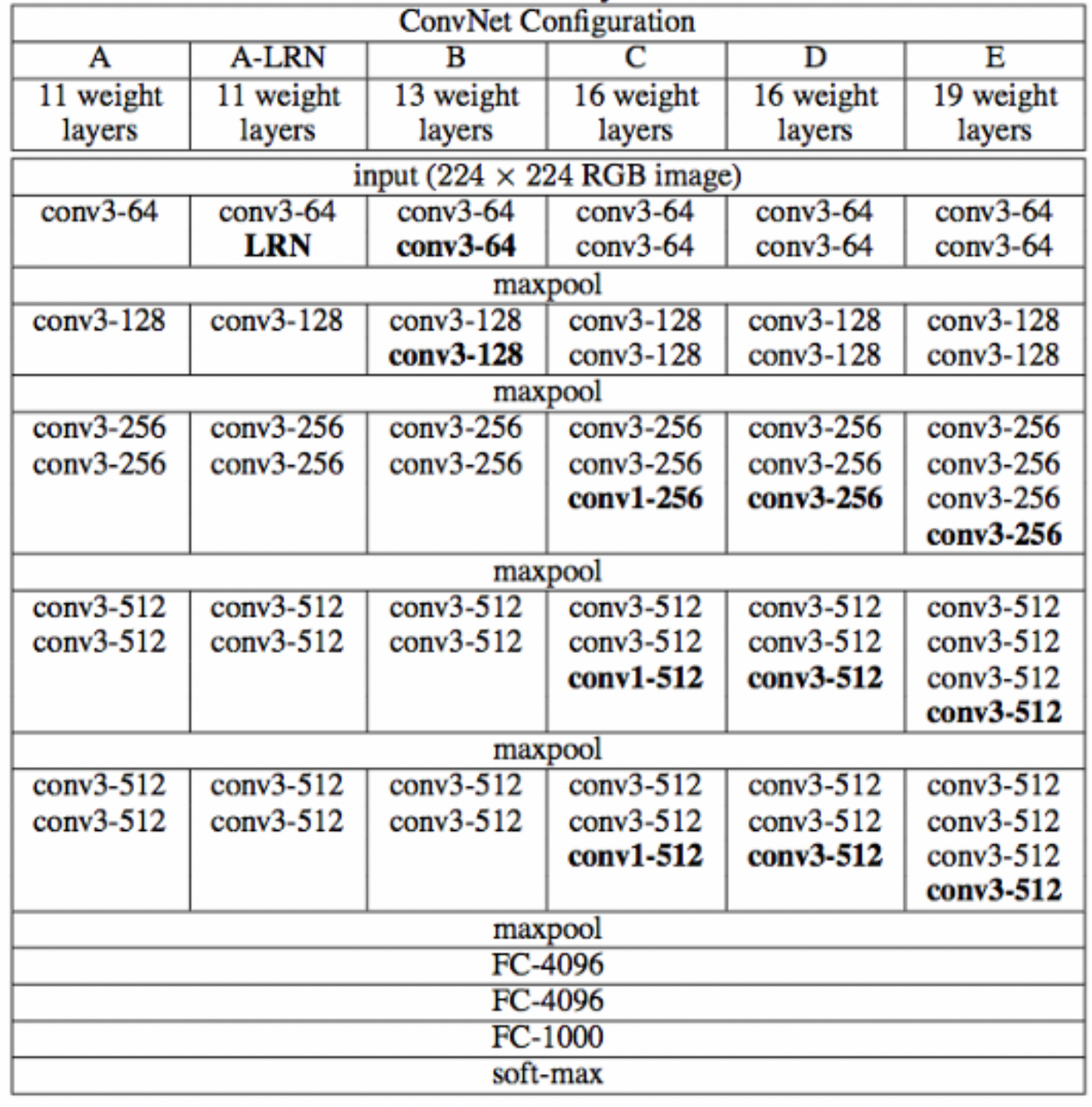
从图中看出,当层数变深时,通道数量会翻倍。
一些特点说明 :
单位:百万
| Network | A,A-LRN | B | C | D | E |
|---|---|---|---|---|---|
| 参数数量 | 133 | 133 | 134 | 138 | 144 |
VGG的参数数量非常大。
学习率调度(learning rate scheduling)是优化神经网络模型时调整学习率的技术,它会随着训练的进行动态地调整学习率的大小。通过学习率调度技术,可以更好地控制模型的收敛速度和质量,避免过拟合等问题。
常用的学习率调度包括常数衰减、指数衰减、余弦衰减和学习率分段调整等。
本文将使用StepLR学习率调度器,代码示例:
schedule = optim.lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=0.5, last_epoch=-1)
optim.lr_scheduler.StepLR 是 PyTorch中提供的一个学习率调度器。这个调度器根据训练的迭代次数来更新学习率,当训练的迭代次数达到step_size的整数倍时,学习率会乘以gamma这个因子,即新学习率 = 旧学习率 * gamma。例如,如果设置了step_size=10和gamma=0.5,那么学习率会在第10、20、30、40…次迭代时变成原来的一半。
本文使用的 optimizer是SGD优化器。
nn.BatchNorm2d(256)是一个在PyTorch中用于卷积神经网络模型中的操作,它可以对输入的二维数据(如图片)的每个通道进行归一化处理。
Batch Normalization 通过对每批数据的均值和方差进行标准化,使得每层的输出都具有相同的均值和方差,从而加快训练速度,减少过拟合现象。nn.BatchNorm2d(256)中的256表示进行标准化的通道数,通常设置为输入数据的特征数或者输出数据的通道数。
在使用nn.BatchNorm2d(256)时,需要将其作为神经网络的一部分,将其添加进网络层中,位置是在卷积后、ReLU前,经过训练之后,每个卷积层的输出在经过BatchNorm层后都经过了归一化处理,从而使得神经网络的训练效果更加稳定。
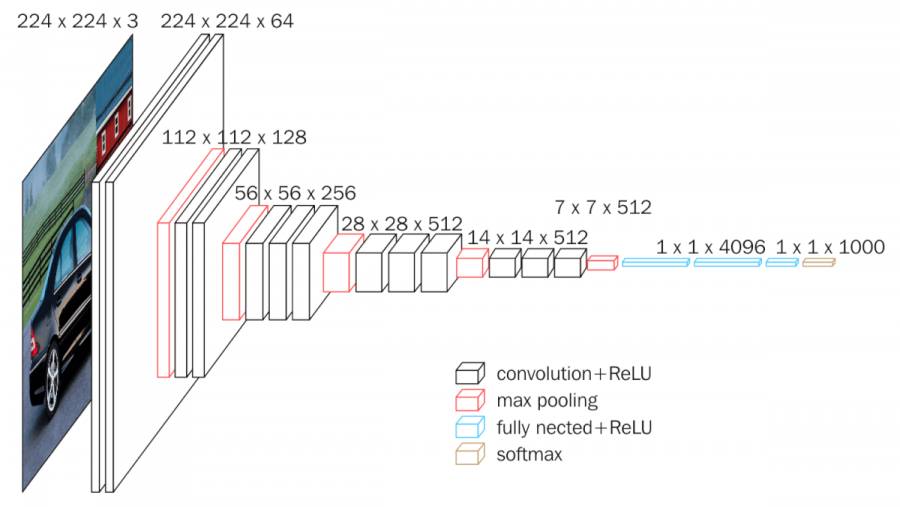
下图可以更清晰看出每个层的参数尺寸:
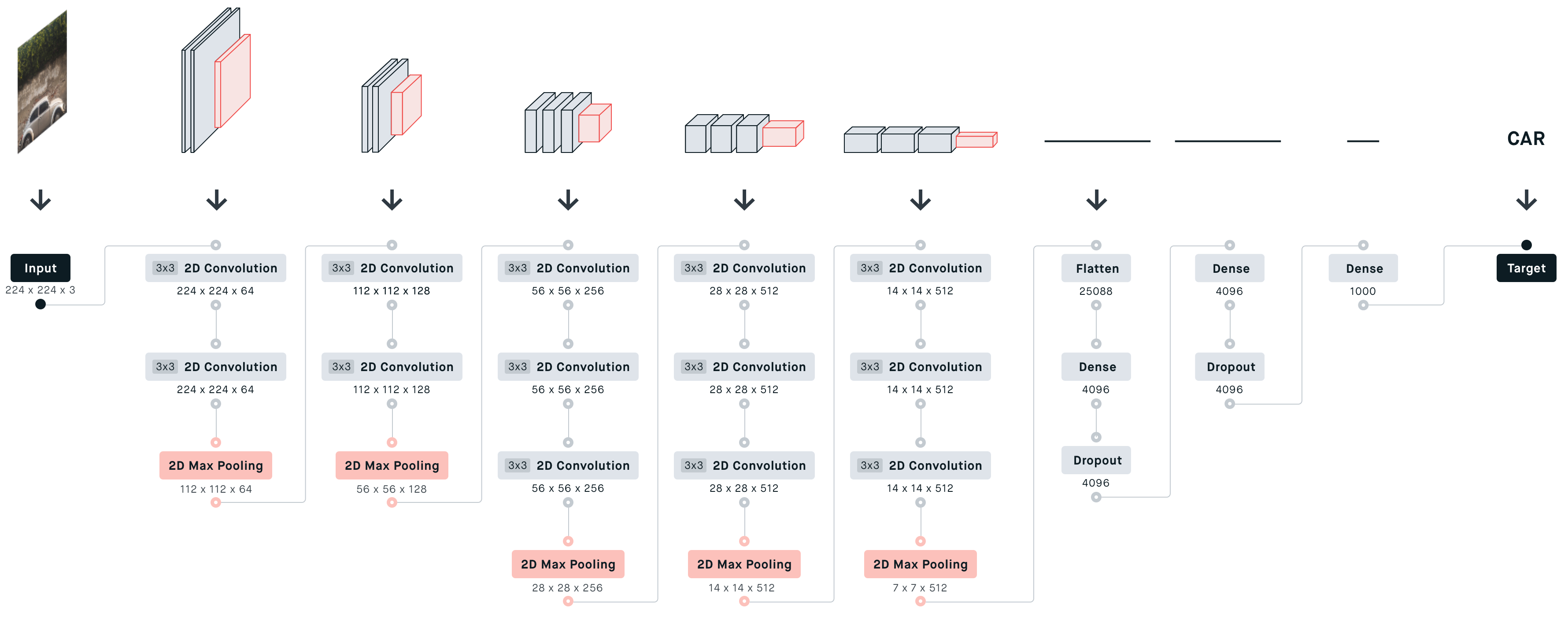
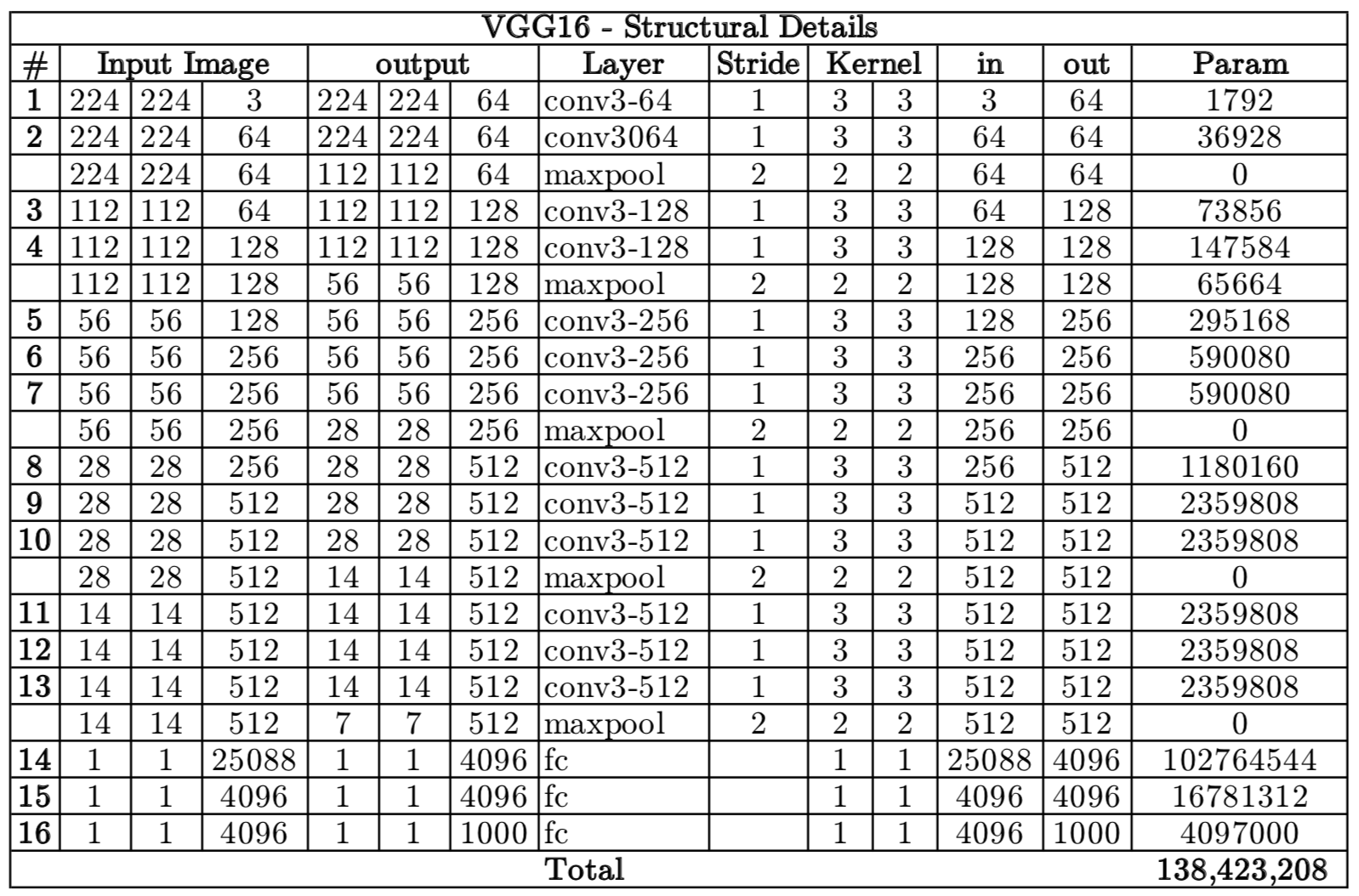
从图中可以看出,第一个全连接nfcr参数数量最多,达到了1亿多,这是因为前一个卷积层输出的向量在拉长成25088维向量,第一个全连接层4096要与25088相乘(每个神经元都要相连)。
import torch
from torch import nn, optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# VGG16网络模型
class Vgg16_net(nn.Module):
def __init__(self):
super(Vgg16_net, self).__init__()
# 第一层卷积层
self.layer1 = nn.Sequential(
# 输入3通道图像,输出64通道特征图,卷积核大小3x3,步长1,填充1
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1),
# 对64通道特征图进行Batch Normalization
nn.BatchNorm2d(64),
# 对64通道特征图进行ReLU激活函数
nn.ReLU(inplace=True),
# 输入64通道特征图,输出64通道特征图,卷积核大小3x3,步长1,填充1
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
# 对64通道特征图进行Batch Normalization
nn.BatchNorm2d(64),
# 对64通道特征图进行ReLU激活函数
nn.ReLU(inplace=True),
# 进行2x2的最大池化操作,步长为2
nn.MaxPool2d(kernel_size=2, stride=2)
)
# 第二层卷积层
self.layer2 = nn.Sequential(
# 输入64通道特征图,输出128通道特征图,卷积核大小3x3,步长1,填充1
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
# 对128通道特征图进行Batch Normalization
nn.BatchNorm2d(128),
# 对128通道特征图进行ReLU激活函数
nn.ReLU(inplace=True),
# 输入128通道特征图,输出128通道特征图,卷积核大小3x3,步长1,填充1
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
# 对128通道特征图进行Batch Normalization
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# 进行2x2的最大池化操作,步长为2
nn.MaxPool2d(2, 2)
)
# 第三层卷积层
self.layer3 = nn.Sequential(
# 输入为128通道,输出为256通道,卷积核大小为33,步长为1,填充大小为1
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
# 批归一化
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2)
)
self.layer4 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2)
)
self.layer5 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2)
)
self.conv = nn.Sequential(
self.layer1,
self.layer2,
self.layer3,
self.layer4,
self.layer5
)
self.fc = nn.Sequential(
nn.Linear(512, 512),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(512, 256),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(256, 10)
)
def forward(self, x):
x = self.conv(x)
# 对张量的拉平(flatten)操作,即将卷积层输出的张量转化为二维,全连接的输入尺寸为512
x = x.view(-1, 512)
x = self.fc(x)
return x
# 批大小
batch_size = 64
# 每n个batch打印一次损失
num_print = 100
# 总迭代次数
epoch_num = 30
# 初始学习率
lr = 0.01
# 每n次epoch更新一次学习率
step_size = 10
# 更新学习率每次减半
gamma = 0.5
def transforms_RandomHorizontalFlip():
# 训练集数据增强:随机水平翻转、转换为张量、使用均值和标准差进行归一化
transform_train = transforms.Compose([transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
# 测试集数据转换为张量、使用均值和标准差进行归一化
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.226, 0.224, 0.225))])
train_dataset = datasets.CIFAR10(root='../path/cifar10', train=True, transform=transform_train, download=True)
test_dataset = datasets.CIFAR10(root='../path/cifar10', train=False, transform=transform, download=True)
return train_dataset, test_dataset
# 随机翻转,获取训练集和测试集数据
train_dataset, test_dataset = transforms_RandomHorizontalFlip()
# 创建DataLoader用于加载训练集和测试集数据
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 创建Vgg16_net模型,并将其移动到GPU或CPU
model = Vgg16_net().to(device)
# 定义损失函数为交叉熵
criterion = nn.CrossEntropyLoss()
# 定义优化器为随机梯度下降,学习率为lr,动量为0.8,权重衰减为0.001
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.8, weight_decay=0.001)
# 定义学习率调度器,每step_size次epoch将学习率减半
schedule = optim.lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=gamma, last_epoch=-1)
# 训练
loss_list = []
# 每个epoch循环训练一遍
for epoch in range(epoch_num):
# 当前迭代次数
ww = 0
# 累计损失值
running_loss = 0.0
# 遍历数据加载器,获取每个batch
for i, (inputs, labels) in enumerate(train_loader, 0):
# 将数据和标签移动到GPU/CPU上
inputs, labels = inputs.to(device), labels.to(device)
# 梯度清零
optimizer.zero_grad()
# 输入数据进行前向传播,行到预测结果
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels).to(device)
# 反向传播,计算每个参数的梯度
loss.backward()
# 更新参数
optimizer.step()
# 累计损失值
running_loss += loss.item()
# 将损失值放到loss_list
loss_list.append(loss.item())
# 打印当前epoch的平均损失值
if (i + 1) % num_print == 0:
print('[%d epoch,%d] loss:%.6f' % (epoch + 1, i + 1, running_loss / num_print))
running_loss = 0.0
lr_1 = optimizer.param_groups[0]['lr']
# 打印学习率
print("learn_rate:%.15f" % lr_1)
schedule.step()
# 测试
model.eval()
# 记录分类正确的样本数和总样本数
correct = 0.0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
# 取预测结果中概率最大的类别为预测结果
pred = outputs.argmax(dim=1)
# 总样本数累加
total += inputs.size(0)
# 正确数量累加
correct += torch.eq(pred, labels).sum().item()
# 打印准确率
print("Accuracy of the network on the 10000 test images:%.2f %%" % (100 * correct / total))
运行示例:
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or