深度优先搜索(Depth First Search,DFS)是最常见的图搜索方法之一。
深度优先搜索沿着一条路径一直搜索下去,在无法搜索时,回退到刚刚访问过的节点。深度优先遍历是按照深度优先搜索的方式对图进行遍历的。
深度优先遍历的秘籍:后被访问的节点,其邻接点先被访问。
根据深度优先遍历的秘籍,后来者先服务,这可以借助于栈实现。递归本身就是使用栈实现的,因此使用递归的方法更方便。
【算法步骤】
① 初始化图中的所有节点均未被访问。
② 从图中的某个节点v 出发,访问v 并标记其已被访问。
③ 依次检查v 的所有邻接点w ,如果w 未被访问,则从w 出发进行深度优先遍历(递归调用,重复步骤2~3)。
【完美图解】
例如,一个无向图如下图所示,
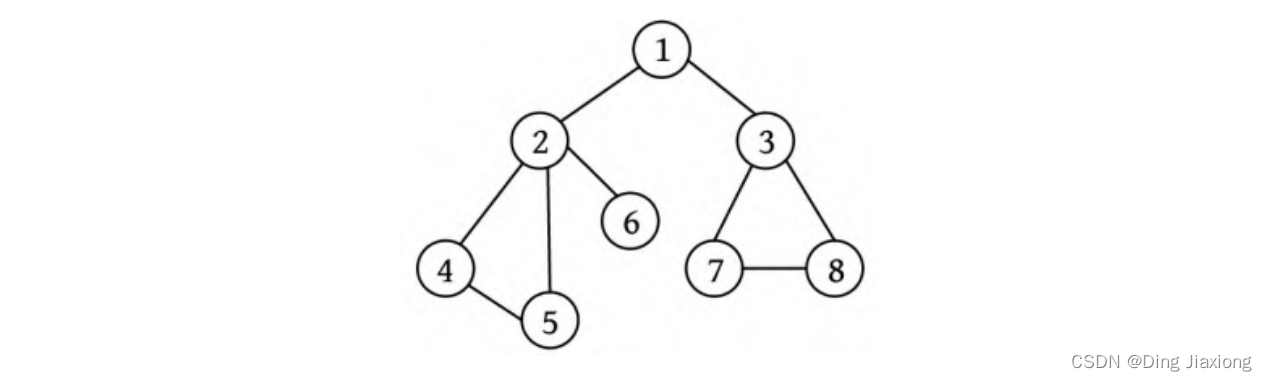
其深度优先遍历的过程如下所述。
① 初始化所有节点均未被访问,visited[i]=false,i =1,2,…,8。
② 从节点1出发,标记其已被访问,visited[1]=true。
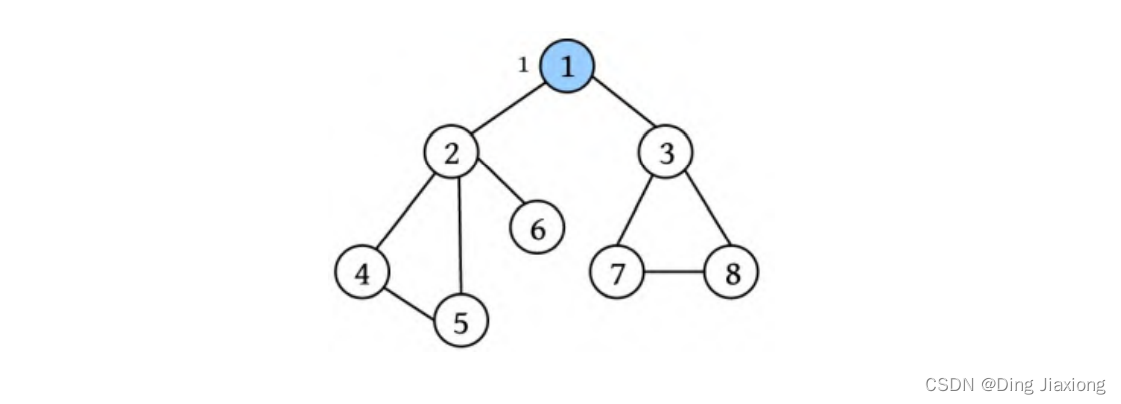
③ 从节点1出发访问邻接点2,然后从节点2出发访问节点4,从节点4出发访问节点5,从节点5出发访问未被访问的邻接点。
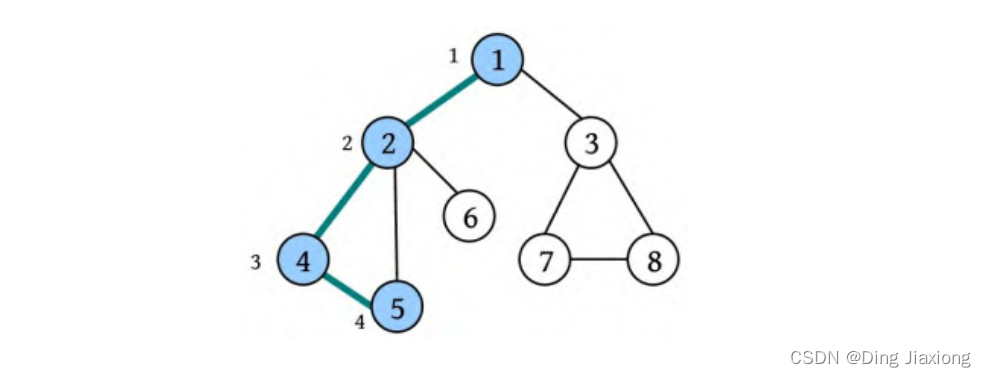
④ 回退到刚刚访问过的节点4,节点4也没有未被访问的邻接点,回退到最近访问过的节点2,从节点2出发访问下一个未被访问的邻接点6。
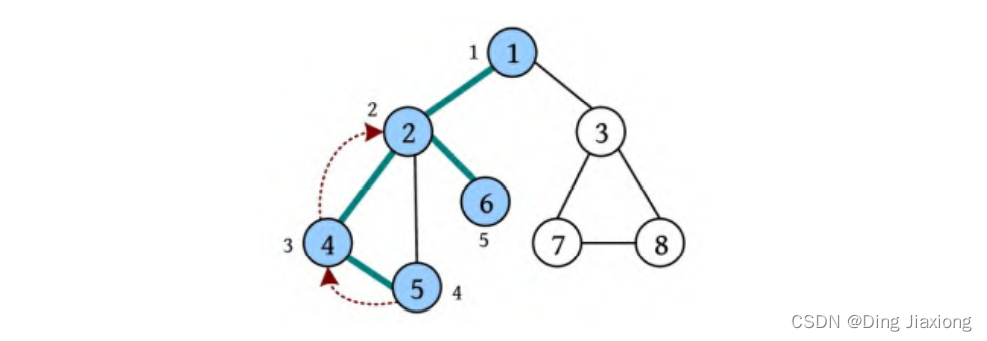
⑤ 从节点6出发访问未被访问的邻接点,回退到刚刚访问过的节点2,节点2没有未被访问的邻接点,回退到最近访问过的节点1。
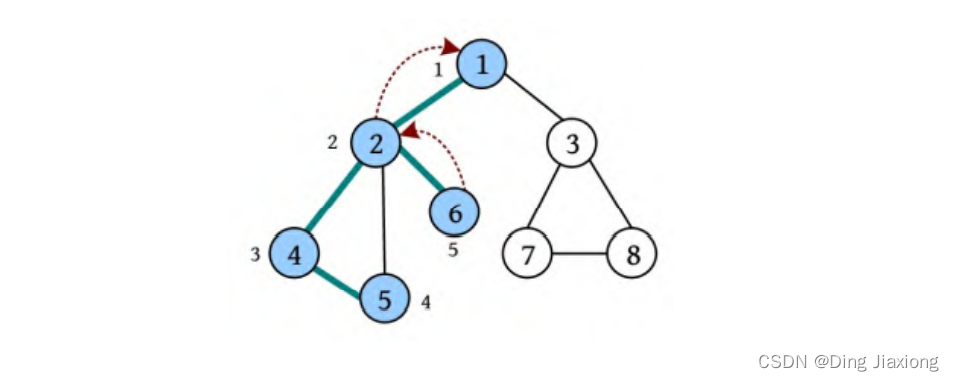
⑥ 从节点1出发访问下一个未被访问的邻接点3,从节点3出发访问节点7,从节点7出发访问节点8,从节点8出发访问未被访问的邻接点。
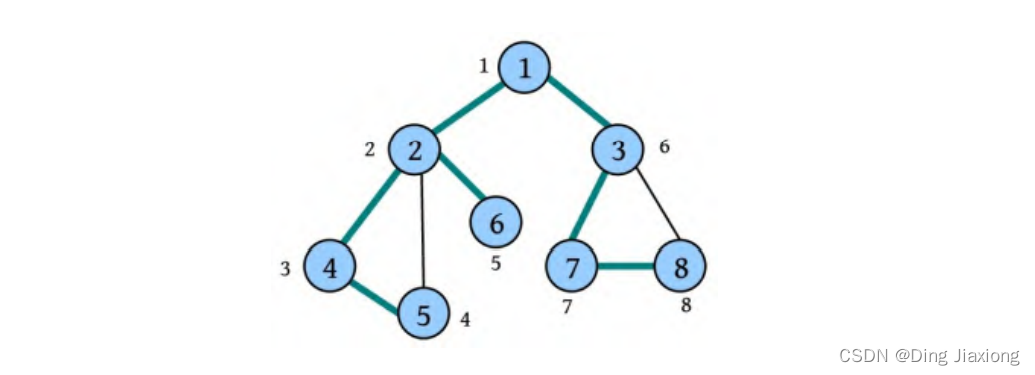
⑦ 回退到刚刚访问过的节点7,节点7也没有未被访问的邻接点,回退到最近访问过的节点3,节点3也没有未被访问的邻接点,回退到最近访问过的节点1,节点1也没有未被访问的邻接点,遍历结束。访问路径如下图所示。
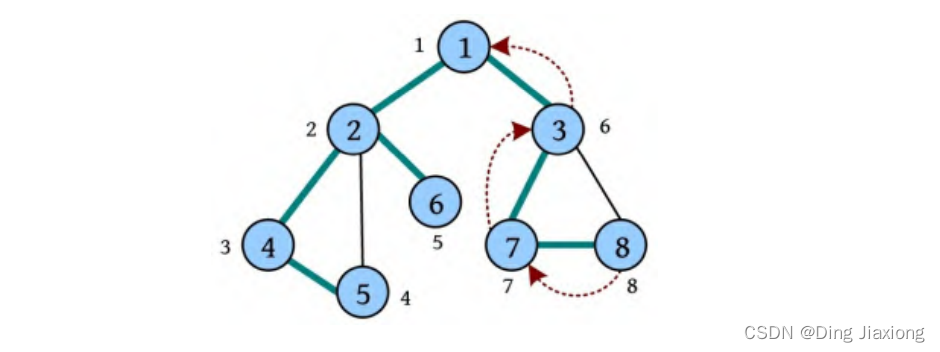
∴ 深度优先遍历序列为1 2 4 5 6 3 7 8。
深度优先遍历经过的节点及边被称为深度优先生成树,如下图所示。
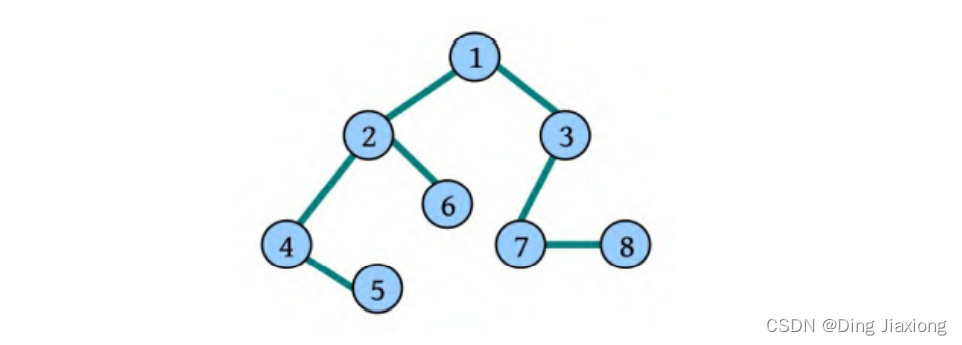
如果深度优先遍历非连通图,则每一个连通分量都会产生一棵深度优先生成树。
【算法实现】
① 基于邻接矩阵的深度优先遍历
void DFS_AM(AMGragh G , int v){ //基于邻接矩阵的深度优先遍历
cout << G.Vex[v] << "\t";
visited[v] = true;
for(int w = 0 ; w < G.vexnum ; w++){ //依次检查v 的所有邻接点
if(G.Edge[v][w] && visited[w]){ //v、w 邻接并且w 未被访问
DFS_AM(G , w); //从节点w 出发,递归深度优先遍历
}
}
}
② 基于邻接表的深度优先遍历
void DFS_AL(ALGragh G , int v){ //基于邻接表的深度优先遍历
AdjNode *p;
cout << G.Vex[v].data << "\t";
visited[v] = true;
p = G.Vex[v].first;
while(p){ //依次检查v 的所有邻接点
int w = p->v; //w 为 v 的邻接点
if(!visited[w]){ //w未被访问
DFS_AL(G , w); //从w 出发,递归深度优先遍历
}
p = p->next;
}
}
③ 基于非连通图的深度优先遍历
void DFS_AL(ALGragh G){ //非连通图,基于邻接表的深度优先遍历
for(int i = 0 ; i < G.vexnum ; i++){ //对非连通图需要查漏点,检查未被访问的节点
if(!visited[i]){ //i 未被访问,以i 为起点再次广度优先遍历
DFS_AL(G , i); //基于邻接表,也可以替换为基于邻接矩阵DFS_AM(G , i);
}
}
}
【算法分析】
深度优先遍历的过程实质上是对每个节点都搜索其邻接点的过程,图的存储方式不同,其算法复杂度也不同。
① 基于邻接矩阵的深度优先遍历算法。查找每个节点的邻接点需要O (n )时间,共n 个节点,总的时间复杂度为O (n^2 )。这里使用了一个递归工作栈,空间复杂度为O (n )
② 基于邻接表的深度优先遍历算法。查找节点vi 的邻接点需要O (d (vi ))时间,d (vi )为vi 的出度,对有向图而言,所有节点的出度之和等于边数e ;对无向图而言,所有节点的度之和等于2e ,因此查找邻接点的时间复杂度为O (e ),加上初始化时间O (n ),总的时间复杂度为O (n +e )。这里使用了一个递归工作栈,空间复杂度为O (n)。
需要注意的是,一个图的邻接矩阵是唯一的,因此基于邻接矩阵的广度优先级遍历或深度优先遍历的序列也是唯一的,而图的邻接表不是唯一的,边的输入顺序不同,正序或逆序建表都会影响邻接表中的邻接点顺序,因此基于邻接表的广度优先遍历或深度优先遍历的序列不是唯一的。
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
所以这可能有点令人困惑,但请耐心等待。简而言之,我想遍历具有特定键值的所有属性,然后如果值不为空,则将它们插入到模板中。这是我的代码:属性:#===DefaultfileConfigurations#default['elasticsearch']['default']['ES_USER']=''default['elasticsearch']['default']['ES_GROUP']=''default['elasticsearch']['default']['ES_HEAP_SIZE']=''default['elasticsearch']['default']['MAX_OP
我们有一个字符串:“”这个正则表达式://i如何从当前字符串中获取所有匹配项? 最佳答案 "".scan(//)参见scan在ruby-docs上 关于ruby-如何遍历Ruby中所有正则表达式匹配的字符串?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/6857852/
我想从0到2循环@a:0,1,2,0,1,2。defset_aif@a==2@a=0else@a=@a+1endend也许有更好的方法? 最佳答案 (0..2).cycle(3){|x|putsx}#=>0,1,2,0,1,2,0,1,2item=[0,1,2].cycle.eachitem.next#=>0item.next#=>1item.next#=>2item.next#=>0... 关于ruby-循环遍历数组的元素,我们在StackOverflow上找到一个类似的问题:
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
我在MySql中进行了查询,但在Rails和mysql2gem中工作。信息如下:http://sqlfiddle.com/#!2/9adb8/6查询工作正常,没有问题,并显示以下结果:UNITV1A1N1V2A2N2V3A3N3V4A4N4V5A5N5LIFE200120000000000ROB010012000000000-为rails2.3.8安装了mysql2gemgeminstallmysql2-v0.2.6-创建Controller:classPolicyController这是日志:SQL(0.9ms)selectdistinct@sql:=concat('SELECTpb
我一直在尝试使用简单的递归方法在Ruby中为一个更大的程序的一部分实现目录遍历。但是我发现Dir.foreach不包括其中的目录。我怎样才能列出它们?代码:defwalk(start)Dir.foreach(start)do|x|ifx=="."orx==".."nextelsifFile.directory?(x)walk(x)elseputsxendendend 最佳答案 问题是每次递归,你传递给File.directory?的路径isno只是实体(文件或目录)名称;所有上下文都丢失了。所以说你进入one/two/three/检
在以下示例中,我无法理解Ruby运算符的优先级:x=1&&y=2由于&&的优先级高于=,我的理解是类似于+和*运算符:1+2*3+4解析为1+(2*3)+4它应该等于:x=(1&&y)=2但是,所有Ruby源代码(包括内部语法解析器Ripper)都将其解析为x=(1&&(y=2))为什么?编辑[08.01.2016]让我们关注一个子表达式:1&&y=2根据优先规则,我们应该尝试将其解析为:(1&&y)=2这没有意义,因为=需要特定的LHS(变量、常量、[]数组项等)。但是既然(1&&y)是一个正确的表达式,那么解析器应该如何处理呢?我试过咨询Ruby的parse.y,但它太像意大利面条