 推荐:AI 绘画新思路:国产开源 50 亿参数新模型,合成可控性、质量实现飞跃。论文 2:Structure and Content-Guided Video Synthesis with Diffusion Models
推荐:AI 绘画新思路:国产开源 50 亿参数新模型,合成可控性、质量实现飞跃。论文 2:Structure and Content-Guided Video Synthesis with Diffusion Models 推荐:加特技只需一句话 or 一张图,Stable Diffusion 的公司把 AIGC 玩出了新花样。论文 3:The connectome of an insect brain
推荐:加特技只需一句话 or 一张图,Stable Diffusion 的公司把 AIGC 玩出了新花样。论文 3:The connectome of an insect brain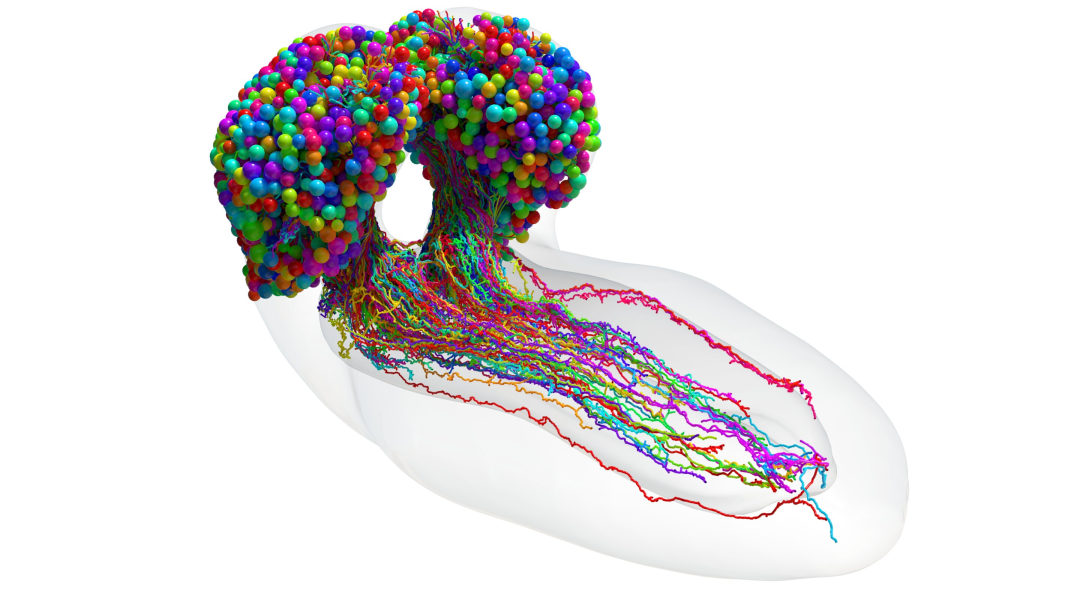 推荐:迄今为止最全昆虫大脑图谱,可能激发新的机器学习架构。论文 4:Uncertainty-driven dynamics for active learning of interatomic potentials
推荐:迄今为止最全昆虫大脑图谱,可能激发新的机器学习架构。论文 4:Uncertainty-driven dynamics for active learning of interatomic potentials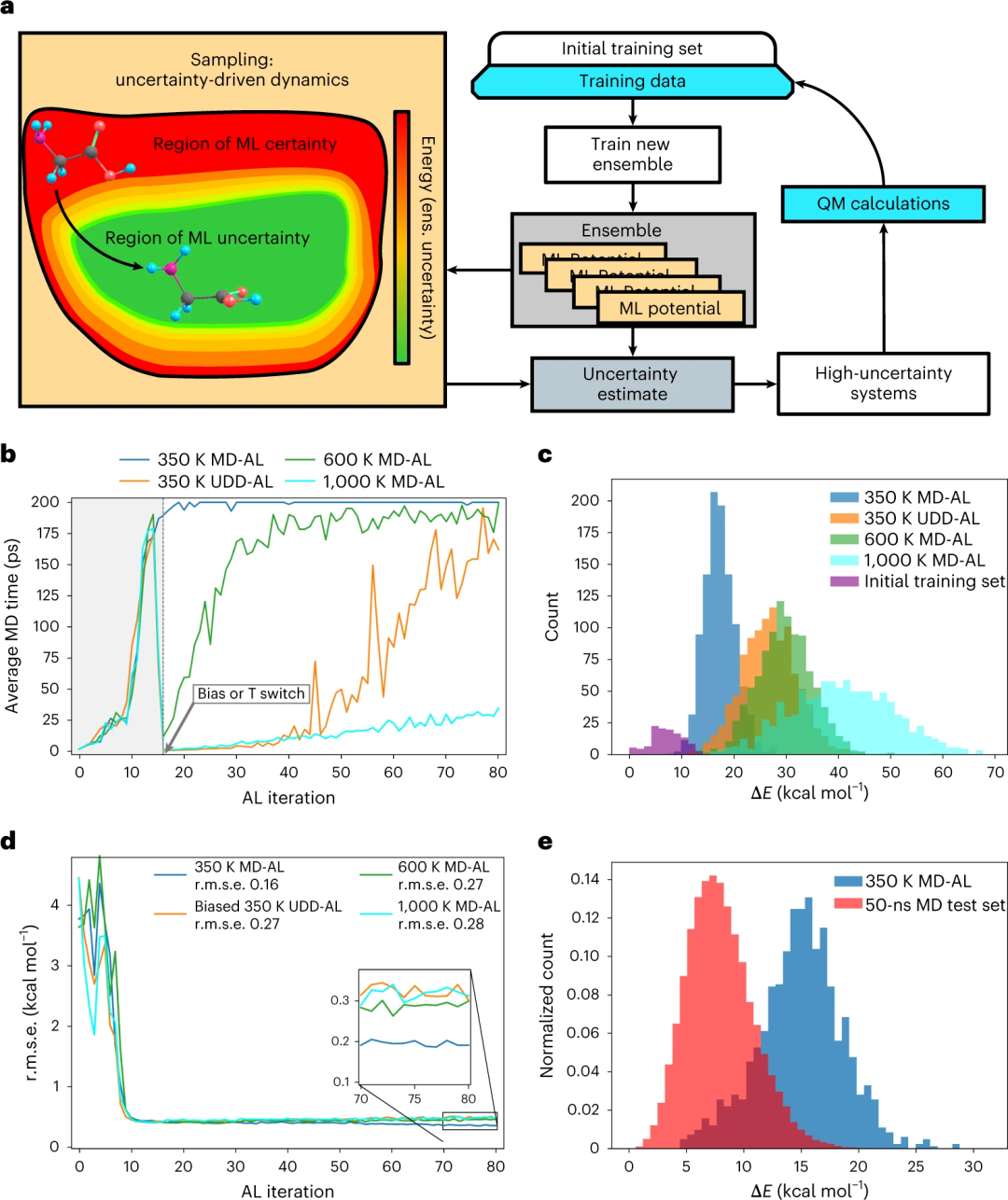 推荐:Nature 子刊 | 不确定性驱动、用于主动学习的动力学用于自动采样。论文 5:Combinatorial synthesis for AI-driven materials discovery
推荐:Nature 子刊 | 不确定性驱动、用于主动学习的动力学用于自动采样。论文 5:Combinatorial synthesis for AI-driven materials discovery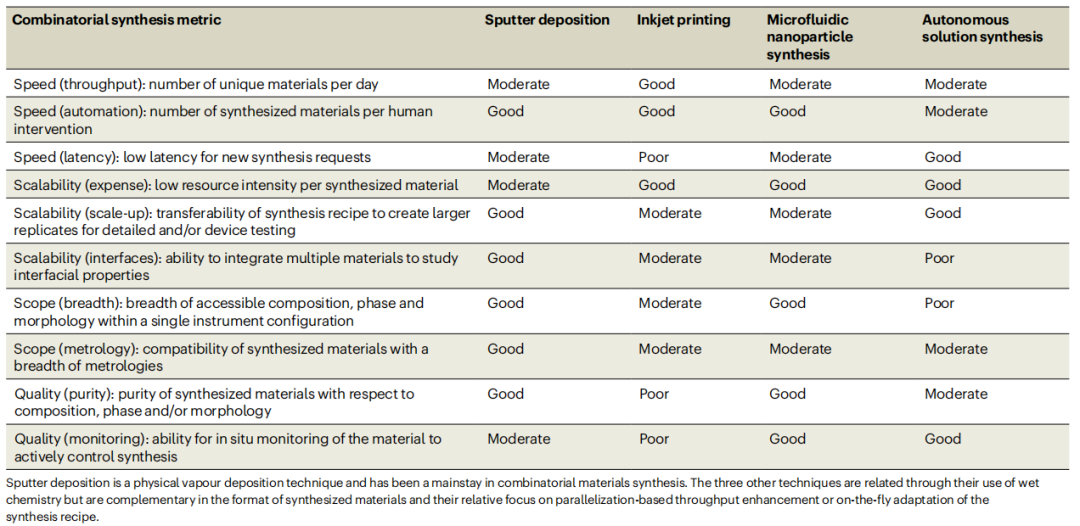 推荐:Nature Synthesis 综述:人工智能驱动材料发现的组合合成。论文 6:Masked Images Are Counterfactual Samples for Robust Fine-tuning
推荐:Nature Synthesis 综述:人工智能驱动材料发现的组合合成。论文 6:Masked Images Are Counterfactual Samples for Robust Fine-tuning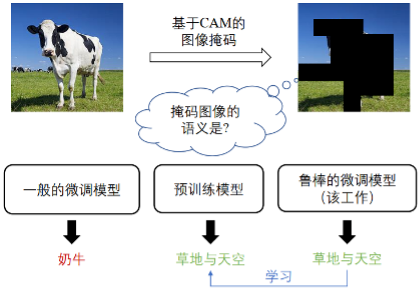 推荐:中山大学 HCP 实验室新突破:用因果范式再升级多模态大模型。论文 7:One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale
推荐:中山大学 HCP 实验室新突破:用因果范式再升级多模态大模型。论文 7:One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale 推荐:清华朱军团队开源首个基于 Transformer 的多模态扩散大模型,文图互生、改写全拿下。
推荐:清华朱军团队开源首个基于 Transformer 的多模态扩散大模型,文图互生、改写全拿下。动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
目前我正在使用这个正则表达式从YoutubeURL中提取视频ID:url.match(/v=([^&]*)/)[1]我怎样才能改变它,以便它也可以从这个没有v参数的YoutubeURL获取视频ID:http://www.youtube.com/user/SHAYTARDS#p/u/9/Xc81AajGUMU感谢阅读。编辑:我正在使用ruby1.8.7 最佳答案 对于Ruby1.8.7,这就可以了。url_1='http://www.youtube.com/watch?v=8WVTOUh53QY&feature=feedf'url
我正在使用RubyonRailsv3.0.9,我想“转换”一个句子中的字符串数组,包括标点符号。也就是说,如果我有如下数组:["element1","element2","element3"]我想得到\构建:#Note:Iadded'Elementsare:'atthebegin,','betweenelementsand'.'at#theend."Elementsare:element1,element2,element3."我该怎么做? 最佳答案 Rails有Array#to_sentence与array.join(',')相同
一、什么是web项目ui自动化测试?通过测试工具模拟人为操控浏览器,使软件按照测试人员的预定计划自动执行测试的一种方式,可以完成许多手工测试无法完成或者不易实现的繁琐工作。正确使用自动化测试,可以更全面的对软件进行测试,从而提高软件质量进而缩短迭代周期。二、构建测试用例的“九部曲”(一)创建流程包划分功能模块日常测试活动中,都会根据功能模块进行拆分,所以在设计器中我们可以通过创建流程包的方式来拆分需要测试的功能模块,如下图中操作创建一个电脑流程包并且取名为对应的功能模块名称,如果有多个功能模块就创建多个对应的流程包,实在RPA设计器有易用的图形可视化界面,方便管理较多的功能模块。(二)在流程包
目录需求基于JavaCV跨平台执行ffmpeg命令[^1]坑一内存不足坑二多个ffmpeg进程并行导致IO负载大,进而导致ioerror?坑三使用Java操作ffmpeg时,有时会卡死坑四Process的waitFor死锁问题及解决办法需求给透明背景的视频自动叠加一张背景图片基于JavaCV跨平台执行ffmpeg命令1我测试发现的本需求的最小依赖:dependency>groupId>org.bytedecogroupId>artifactId>ffmpeg-platform-gplartifactId>version>5.0-1.5.7version>dependency>核心代码:Stri
摘要本论文主要论述了如何使用Python技术开发一个短视频智能推荐,本系统将严格按照软件开发流程进行各个阶段的工作,采用B/S架构,面向对象编程思想进行项目开发。在引言中,作者将论述短视频智能推荐的当前背景以及系统开发的目的,后续章节将严格按照软件开发流程,对系统进行各个阶段分析设计。 短视频智能推荐的主要使用者分为管理员和用户,实现功能包括管理员:首页、个人中心、用户管理、热门视频管理、用户上传管理、系统管理,用户:首页、个人中心、用户上传管理、我的收藏管理,前台首页;首页、热门视频、用户上传、公告信息、个人中心、后台管理等功能。由于本网站的功能模块设计比较全面,所以使得整个短视频智能推荐信
基于ffmpeg的视频处理与MPEG的压缩试验ffmpeg介绍与基础知识对提取到的图像进行处理RGB并转化为YUV对YUV进行DCT变换对每个8*8的图像块进行进行量化操作ffmpeg介绍与基础知识ffmpeg是视频和图像处理的工具包,它的下载网址是https://ffmpeg.org/download.html。页面都是英文且下载正确的包的路径笔者找的时候还费点劲,这里记录一下也方便读者。选中这个Windows下的下午files,选择第一个这里有essential和full版本的,大家根据需要自行选择版本包下载下载好之后,在官网上下载ffmpeg的full包,一共300+MB解压,然后安装b
近年来,随着信息化时代的到来,三维全景拼接以视频监控领域为代表的智能硬件公司迅速崛起,随后全国各地在视频监控领域进行了大量的建设。但随着摄像头数量的增加,视频监控画面离散、庞杂、关联性差等诸多问题日渐凸显。如何优化现有视频技术,助力管理者或使用者有效、直观、准确地掌控现场实时动态,成为我国信息化前行路上面临的新课题。视频融合技术平台解决方案北京智汇云舟科技有限公司成立于2012年,专注于创新性的“视频孪生(实时实景数字孪生)”技术研发与应用。公司依托自研三维地理信息引擎(3DGIS),融合建筑信息模型(BIM)、视频监控(Video)、人工智能(AI)及物联网(IOT)等多种技术,并在此基础上