本文已收录于专栏
欢迎各位关注、三连博主的文章及专栏,全套Redis学习资料,大厂必备技能!
目录
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
上面这句介绍比较全面的描述了什么是布隆过滤器,如果还是不太好理解的话,就可以把布隆过滤器理解为一个set集合,我们可以通过add往里面添加元素,通过contains来判断是否包含某个元素。由于本文讲述布隆过滤器时会结合Redis来讲解,因此类比为Redis中的Set数据结构会比较好理解,而且Redis中的布隆过滤器使用的指令与Set集合非常类似(后续会讲到)。
学习布隆过滤器之前有必要先聊下它的优缺点,因为好的东西我们才想要嘛!
布隆过滤器的优点:
布隆过滤器的缺点:
布隆过滤器可以告诉我们 “某样东西一定不存在或者可能存在”,也就是说布隆过滤器说这个数不存在则一定不存,布隆过滤器说这个数存在可能不存在(误判,后续会讲),**利用这个判断是否存在的特点可以做很多有趣的事情。
布隆过滤器它实际上是一个很长的二进制向量和一系列随机映射函数。以Redis中的布隆过滤器实现为例,Redis中的布隆过滤器底层是一个大型位数组(二进制数组)+多个无偏hash函数。
一个大型位数组(二进制数组):

多个无偏hash函数:
无偏hash函数就是能把元素的hash值计算的比较均匀的hash函数,能使得计算后的元素下标比较均匀的映射到位数组中。
如下就是一个简单的布隆过滤器示意图,其中k1、k2代表增加的元素,a、b、c即为无偏hash函数,最下层则为二进制数组。
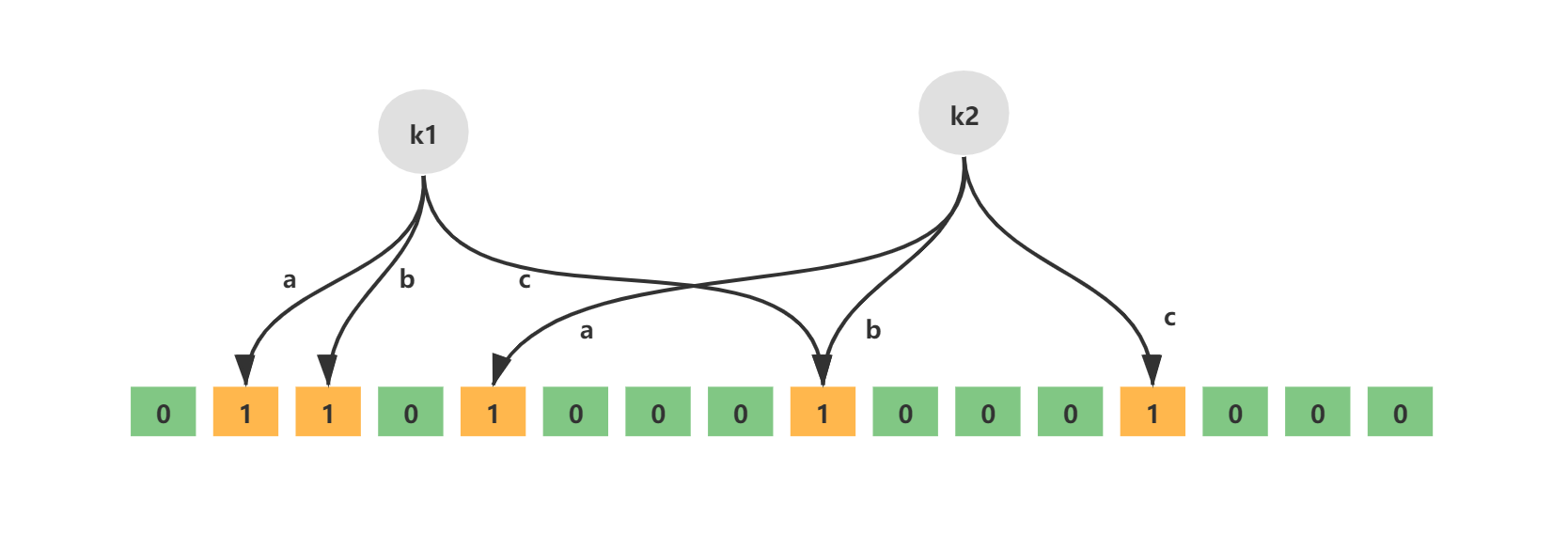
在布隆过滤器增加元素之前,首先需要初始化布隆过滤器的空间,也就是上面说的二进制数组,除此之外还需要计算无偏hash函数的个数。布隆过滤器提供了两个参数,分别是预计加入元素的大小n,运行的错误率f。布隆过滤器中有算法根据这两个参数会计算出二进制数组的大小l,以及无偏hash函数的个数k。
它们之间的关系比较简单:
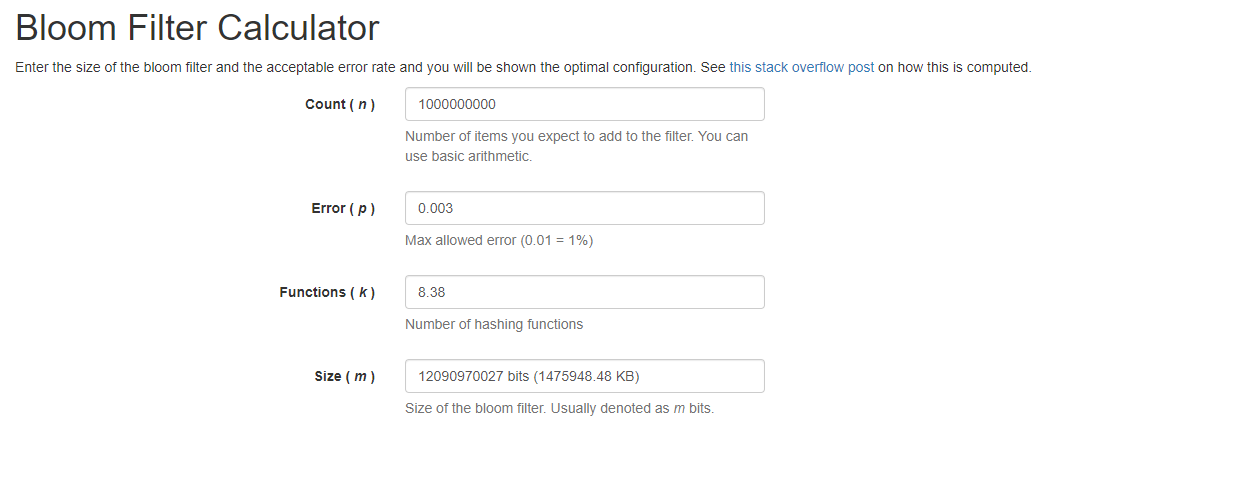
如下地址是一个免费的在线布隆过滤器在线计算的网址:
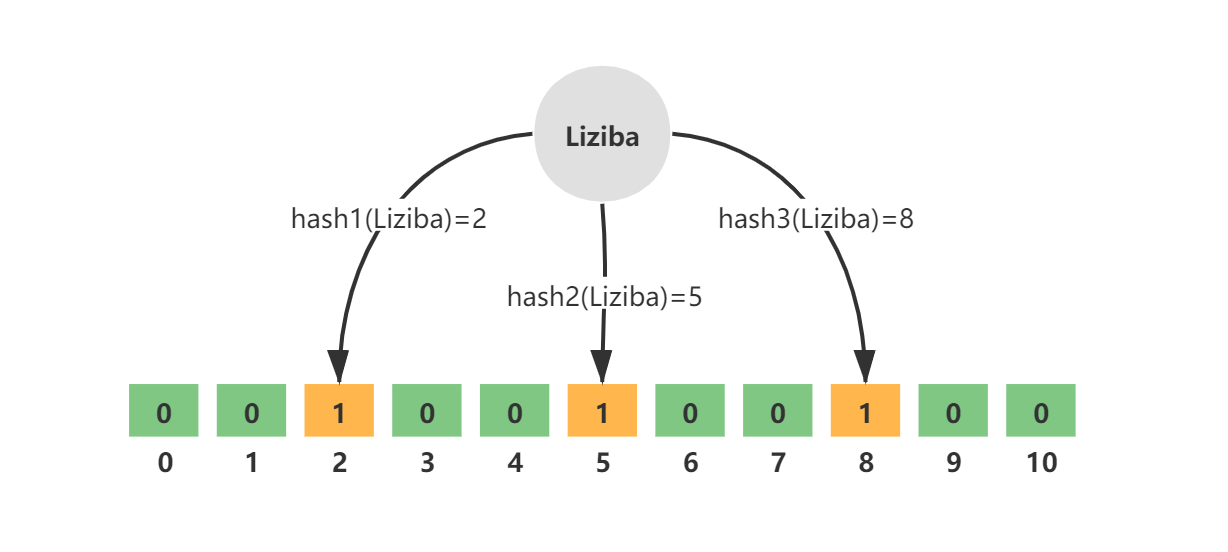
往布隆过滤器增加元素,添加的key需要根据k个无偏hash函数计算得到多个hash值,然后对数组长度进行取模得到数组下标的位置,然后将对应数组下标的位置的值置为1
例如,key = Liziba,无偏hash函数的个数k=3,分别为hash1、hash2、hash3。三个hash函数计算后得到三个数组下标值,并将其值修改为1.
如图所示:
布隆过滤器最大的用处就在于判断某样东西一定不存在或者可能存在,而这个就是查询元素的结果。其查询元素的过程如下:
关于误判,其实非常好理解,hash函数在怎么好,也无法完全避免hash冲突,也就是说可能会存在多个元素计算的hash值是相同的,那么它们取模数组长度后的到的数组索引也是相同的,这就是误判的原因。例如李子捌和李子柒的hash值取模后得到的数组索引都是1,但其实这里只有李子捌,如果此时判断李子柒在不在这里,误判就出现啦!因此布隆过滤器最大的缺点误判只要知道其判断元素是否存在的原理就很容易明白了!
无
布隆过滤器对元素的删除不太支持,目前有一些变形的特定布隆过滤器支持元素的删除!关于为什么对删除不太支持,其实也非常好理解,hash冲突必然存在,删除肯定是很苦难的!
redis-server -v

v1.1.1
https://github.com/RedisLabsModules/rebloom/archive/v1.1.1.tar.gz
v2.2.6
https://github.com/RedisLabsModules/rebloom/archive/v2.2.6.tar.gz
以下安装全部在指定目录下完成,可以选择一个合适的统一目录进行软件安装和管理。
4.2.1 下载插件压缩包
wget https://github.com/RedisLabsModules/rebloom/archive/v2.2.6.tar.gz
4.2.2 解压
tar -zxvf v2.2.6.tar.gz
4.2.3 编译插件
cd RedisBloom-2.2.6/
make
编译成功后看到redisbloom.so文件即可
4.3.1 Redis配置文件修改
loadmodule /usr/local/soft/RedisBloom-2.2.6/redisbloom.so
redis.conf配置文件中预置了loadmodule的配置项,我们可以直接在这里修改,后续修改会更加方便。

保存退出后一定要记得重启Redis!
保存退出后一定要记得重启Redis!
保存退出后一定要记得重启Redis!
4.3.2 测试是否成功
Redis集成布隆过滤器的主要指令如下:
连接客户端进行测试,如果指令有效则证明集成成功

如果出现如下情况(error) ERR unknown command ,可以通过如下方法检查:

bf.add表示添加单个元素,添加成功返回1
127.0.0.1:6379> bf.add name liziba
(integer) 1

bf.madd表示添加多个元素
127.0.0.1:6379> bf.madd name liziqi lizijiu lizishi
1) (integer) 1
2) (integer) 1
3) (integer) 1

bf.exists表示判断元素是否存在,存在则返回1,不存在返回0
127.0.0.1:6379> bf.mexists name liziba
1) (integer) 1

bf.mexists表示判断多个元素是否存在,存在的返回1,不存在的返回0
127.0.0.1:6379> bf.mexists name liziqi lizijiu liziliu
1) (integer) 1
2) (integer) 1
3) (integer) 0

使用布隆过滤器的方式有很多,还有很多大佬自己手写的,我这里使用的是谷歌guava包中实现的布隆过滤器,这种方式的布隆过滤器是在本地内存中实现。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
package com.lizba.bf;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* <p>
* 布隆过滤器测试代码
* </p>
*
* @Author: Liziba
* @Date: 2021/8/29 14:51
*/
public class BloomFilterTest {
/** 预计插入的数据 */
private static Integer expectedInsertions = 10000000;
/** 误判率 */
private static Double fpp = 0.01;
/** 布隆过滤器 */
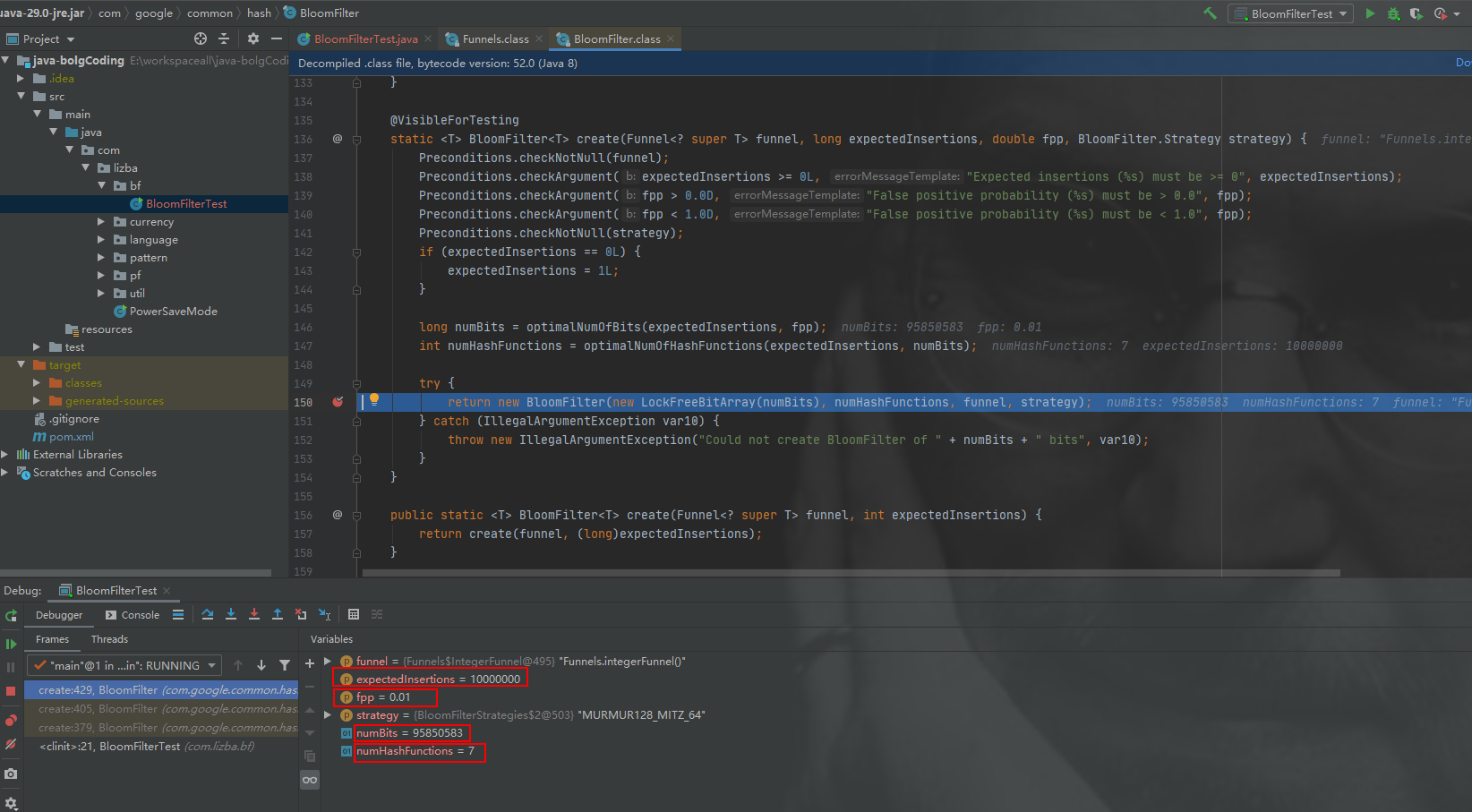
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), expectedInsertions, fpp);
public static void main(String[] args) {
// 插入 1千万数据
for (int i = 0; i < expectedInsertions; i++) {
bloomFilter.put(i);
}
// 用1千万数据测试误判率
int count = 0;
for (int i = expectedInsertions; i < expectedInsertions *2; i++) {
if (bloomFilter.mightContain(i)) {
count++;
}
}
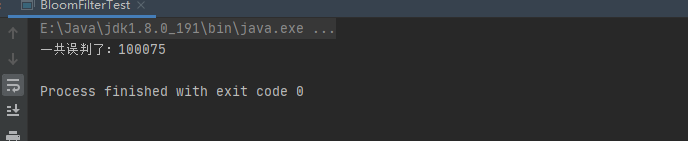
System.out.println("一共误判了:" + count);
}
}
误判了100075次,大概是expectedInsertions(1千万)的0.01,这与我们设置的 fpp = 0.01非常接近。
在guava包中的BloomFilter源码中,构造一个BloomFilter对象有四个参数:
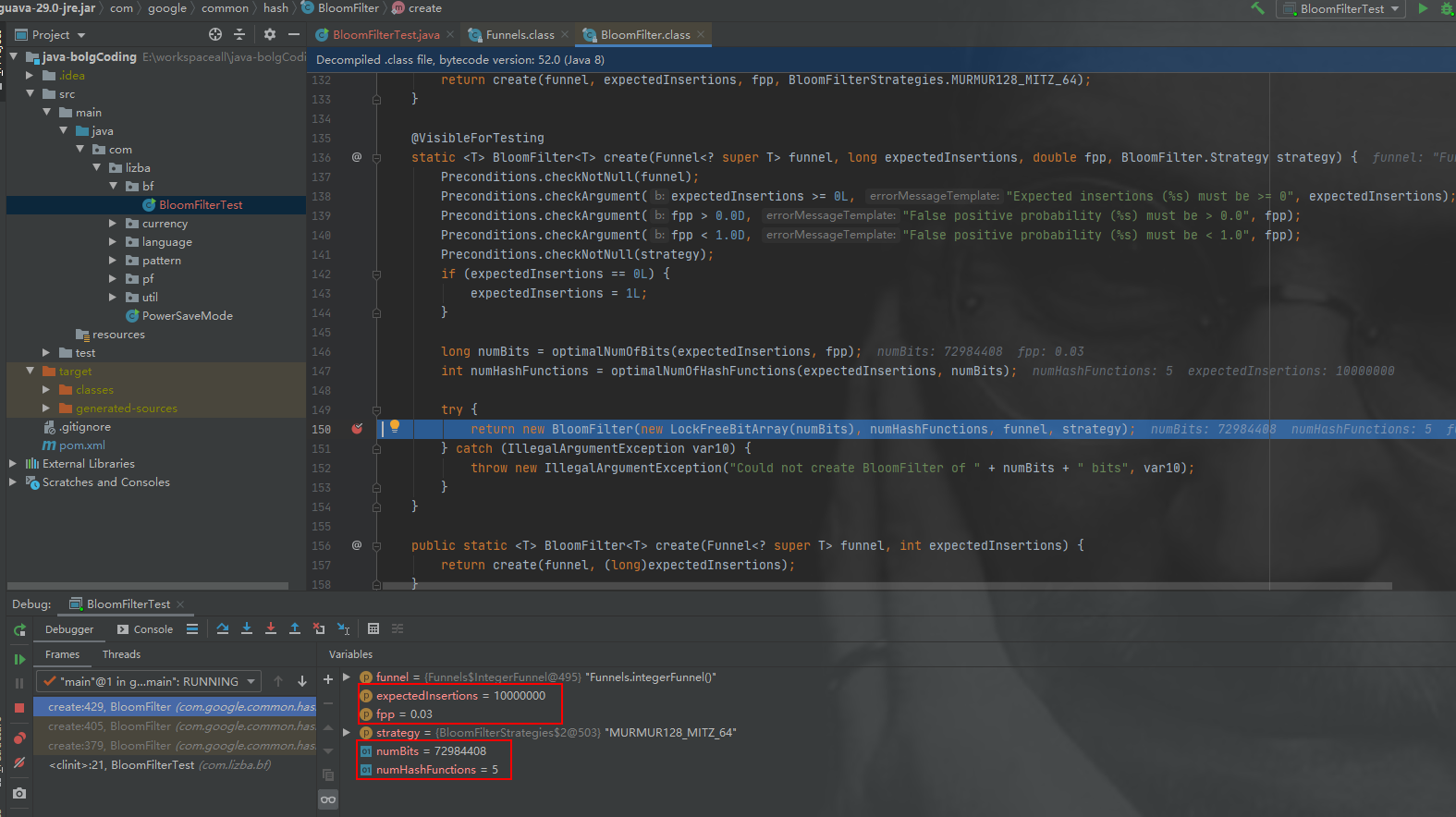
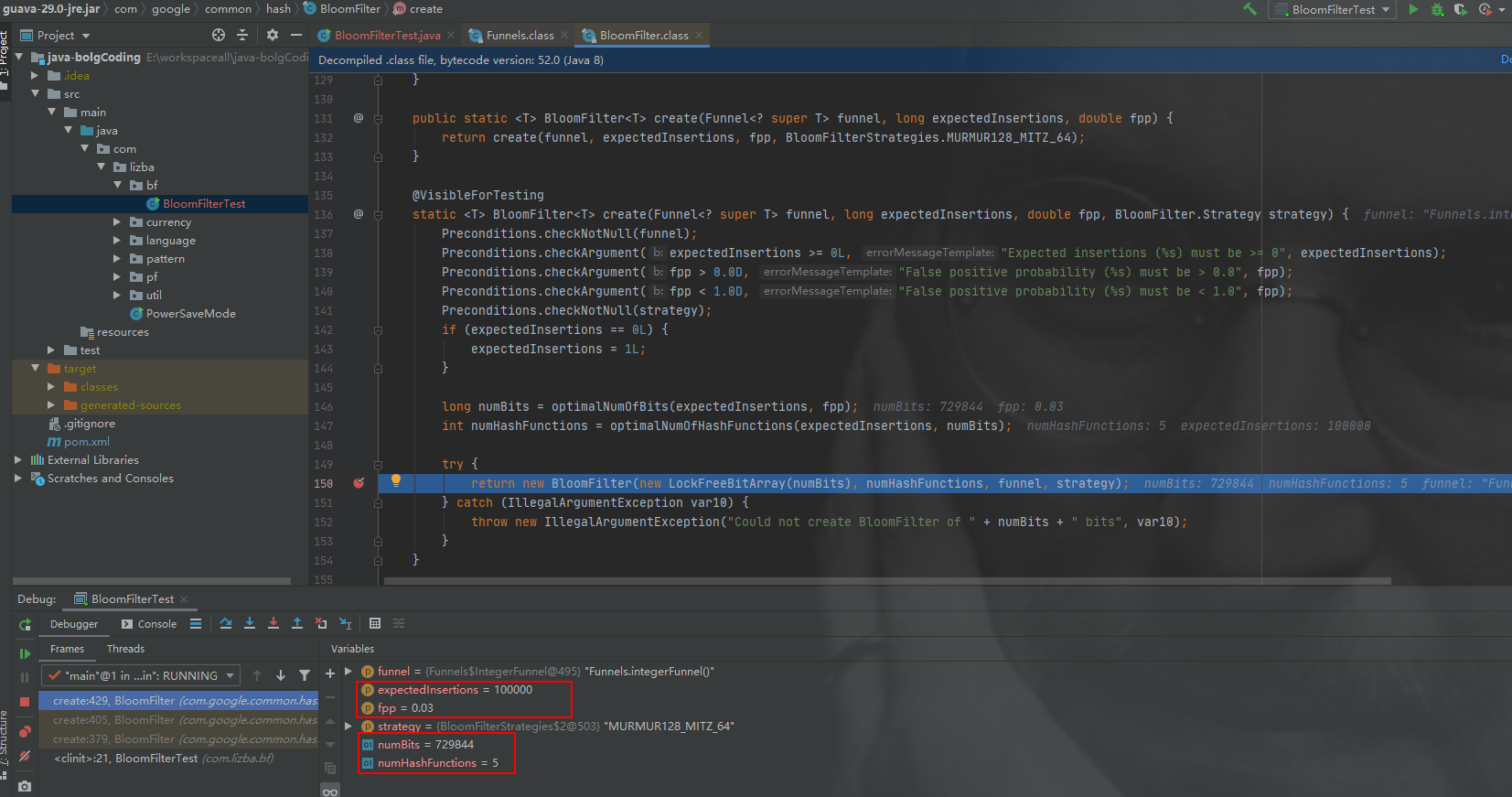
综上三次测试可以得出如下结论:
Redis经常会被问道缓存击穿问题,比较优秀的解决办法是使用布隆过滤器,也有使用空对象解决的,但是最好的办法肯定是布隆过滤器,我们可以通过布隆过滤器来判断元素是否存在,避免缓存和数据库都不存在的数据进行查询访问!在如下的代码中只要通过bloomFilter.contains(xxx)即可,我这里演示的还是误判率!
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.16.0</version>
</dependency>
package com.lizba.bf;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
/**
* <p>
* Java集成Redis使用布隆过滤器防止缓存穿透方案
* </p>
*
* @Author: Liziba
* @Date: 2021/8/29 16:13
*/
public class RedisBloomFilterTest {
/** 预计插入的数据 */
private static Integer expectedInsertions = 10000;
/** 误判率 */
private static Double fpp = 0.01;
public static void main(String[] args) {
// Redis连接配置,无密码
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.211.108:6379");
// config.useSingleServer().setPassword("123456");
// 初始化布隆过滤器
RedissonClient client = Redisson.create(config);
RBloomFilter<Object> bloomFilter = client.getBloomFilter("user");
bloomFilter.tryInit(expectedInsertions, fpp);
// 布隆过滤器增加元素
for (Integer i = 0; i < expectedInsertions; i++) {
bloomFilter.add(i);
}
// 统计元素
int count = 0;
for (int i = expectedInsertions; i < expectedInsertions*2; i++) {
if (bloomFilter.contains(i)) {
count++;
}
}
System.out.println("误判次数" + count);
}
}

我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
我有一个名为Post的类,我需要能够适应以下场景:如果用户选择了一个类别,则只显示该类别的帖子如果用户选择了一种类型,则只显示该类型的帖子如果用户选择了一个类别和类型,则只显示该类别中该类型的帖子如果用户没有选择任何内容,则显示所有帖子我想知道我的Controller是否不可避免地会因大量条件语句而显得粗糙...这是我解决此问题的错误方法-有谁知道我如何才能做到这一点?classPostsController 最佳答案 您最好遵循“胖模型,瘦Controller”的惯例,这意味着您应该将这种逻辑放在模型本身中。Post类应该能够报告
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
我仍然收到标题中的“错误”消息,但不知道如何解决。在ApplicationController中,classApplicationController在routes.rb#match'set_activity_account/:id/:value'=>'users#account_activity',:as=>:set_activity_account--thisdoesn'tworkaswell..resources:usersdomemberdoget:action_a,:action_bendcollectiondoget'account_activity'endend和User
对于用户模型,我有一个过滤器来检查用户的预订状态,该状态由整数值(0、1或2)表示。UserActiveAdmin索引页上的过滤器是通过以下代码实现的:filter:booking_status,as::select然而,这会导致下拉选项为0、1或2。当管理员用户从下拉列表中选择它们时,我更愿意自己将它们命名为“未完成”、“待定”和“已确认”之类的名称。有没有办法在不改变booking_status在模型中的表示方式的情况下做到这一点? 最佳答案 假设booking_status是模型中的枚举字段,您可以使用:过滤器:booking
我正在使用Maruku,将Markdown(超集)转换为HTML,你知道我该怎么做才能从HTML转换为Markdown吗? 最佳答案 Google发现了一个名为reverse_markdown的ruby脚本.它似乎可以满足您的需求。 关于ruby-on-rails-我需要从HTML转到markdown,有什么建议吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/175162
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva