块,页,是对同一概念的不同叫法,取决于场景不同。其表述的都是磁盘上某一柱面上的连续扇区(固定数目)。数据在磁盘和缓冲区(内存)之间传输,传输的单位就是块(页)。
内存区是以定长的页数组的形式组织的,其中每一个数组条目,被称为一个帧(frame)。当DBMS请求一个页时,被请求页的一份拷贝就被读取进其中一个帧中。
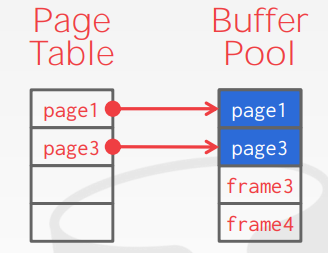
所以,page和frame实际是指的是同一个概念,buffer pool中的叫做帧,磁盘与内存之间的传输单位的叫做page或者block。
是一个Page ID到Frame ID的映射。Page ID是磁盘页的属性,不同的磁盘页的Page ID不同,当磁盘页被读取进缓冲区时,该磁盘页会在缓冲区中有一个位置,即Frame ID。缓冲区是Frame的定长数组,一共只有buffer_pool_size大小的frame,所以,当磁盘页读进写出,会存在不同的磁盘页先后出现在同一个帧位置的情况,那么这个Page Table,就是保存当前页ID到帧ID的映射。
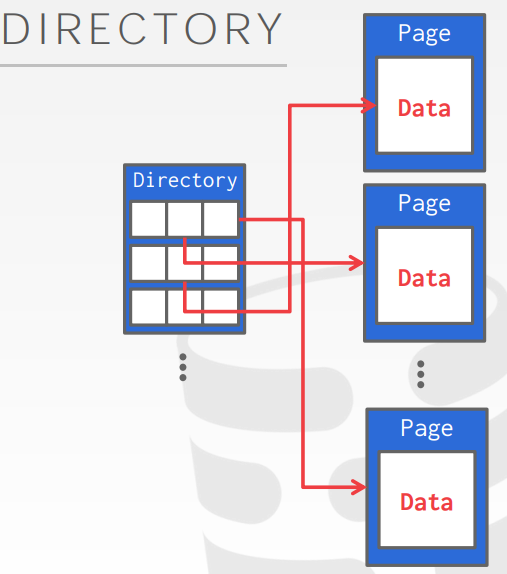
Page Directory中的每⼀个小格中包含有对应page所在位置,也包含它剩余空间信息。通过Page Directory可以将page映射到内存或者磁盘上的某个位置
总的来说,数据库内部的存储结构可以总结为,Page Directory负责映射内存或者磁盘中的page,Page Table负责将page映射到buffer pool中的frame中。
而page内部的header和slot array来组织tuple存放。以下是page中的结构
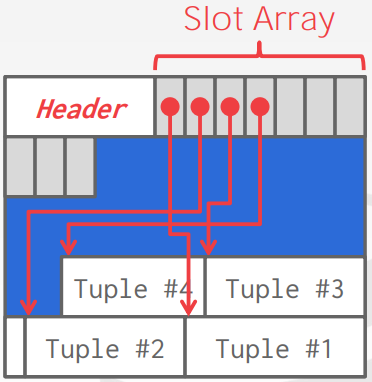
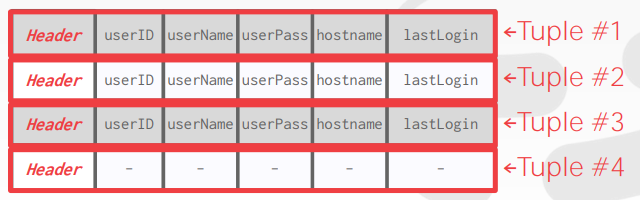
tuple内部的结构也是header+data。

replacer是一个定长数组,但是clock_size不是定长,而是可以被victim的frame的总数,所以replacer实际上存放的是可以被替换的帧。clock_size初始为0。
clock_hand是遍历replacer的指针,只有Victim()函数可以修改clock_hand指针。
pages_是buffer pool的帧数组。bool Victim(frame_id_t *frame_id)
1.进行循环遍历,扫描所有实际存在replacer中的帧,如果没有可替换帧,则返回false。
2.只查看实际在replacer中的帧,如果ref为1,则将ref修改为0,clock_hand++。如果ref为0,则将其标记为不在replacer中,clock_size--,并令*frame_id = clock_hand++,将该帧的frame_id传出去,返回true。
void Pin(frame_id_t frame_id)
将目标帧标记为不在replacer中,clock_size--。
void Unpin(frame_id_t frame_id)
将目标帧标记为在replacer中,clock_size++,同时将ref标记为true(clock_replacer中新添加帧的ref需标记为true)。
FetchPageImpl(page_id_t page_id)
0.首先用latch上锁
1.page_table_中是否存在page_id所对应的帧。如果存在,则直接返回所对应的帧,并需要进行pin操作;若没有则需要将磁盘中的page读取到buffer pool中,即读取到pages_中的一个帧的位置。
2.首先从free_list中寻找空闲帧,如果可以找到空闲帧,则go to 4;如果free_list为空,则调用replacer.Victim()获得可替换帧的victim_frame_id。若没有可替换帧,则返回nullptr。
3.检查victim_frame的脏读位,如果脏读位有效,则需要调用disk_manager_->WritePage()写回到磁盘中。
4.进行victim_frame数据的读取以及元数据的更新操作:
(1)清除victim_frame的页表中的记录。
(2)添加victim_frame的page_id到victim_frame_id的新映射。
(3)更新victim_frame(在pages_数组中)的page_id。
(4)进行victim_frame的pin操作,pin_count++,调用者加1,并调用replacer_->pin()方法。
(5)victim_frame的脏读位记为false。
(6)调用disk_manager_->ReadPage(page_id, pages_[victim_frame_id].data_),将page的数据读取到victim_frame中。
5.返回pages_中victim_frame的地址。
Page* NewPageImpl(page_id_t *page_id)
0.首先用latch上锁
1.首先从free_list中寻找空闲帧,如果可以找到空闲帧,则go to 3;如果free_list为空,则调用replacer.Victim()获得可用帧的victim_frame_id。若没有可用帧,则返回nullptr。
2.检查victim_frame的脏读位,如果脏读位有效,则需要调用disk_manager_->WritePage()写回到磁盘中。
3.调用disk_manager_->AllocatePage()分配一个新的页,记页ID为page_id,然后进行victim_frame数据的清除以及元数据的更新操作:
(1)清除victim_frame的页表中的记录。
(2)添加victim_frame的page_id到victim_frame_id的新映射。
(3)更新pages_数组中的victim_frame的page_id.
(4)记victim_frame的脏读位为false
(5)清空victim_frame中的数据
(6)设置victim_frame的pin_count=1
4.返回pages_中victim_frame的地址
bool DeletePageImpl(page_id_t page_id)
0.首先用latch上锁
1.在page_table_中查找page_id是否存在对应的frame_id,如果不存在,则直接go to 4。
2.若page_table_[frame_id].pin_count不为0,则返回false。
3.若目标帧的脏读位为true,则调用disk_manager_->WritePage()将其写回磁盘。
4.进行目标帧的重置操作:
(1)该目标帧不再进行replacer_->Victim()操作,所以调用replacer_->Pin(frame_id)。
(2)从page_table_中删除page_id的映射
(3)设置目标帧的pin_count=0,is_dirty_=false,data_清空,page_id=INVALID_PAGE_ID。
(4)加入free_list_中。
4.调用disk_manager_->DeallocatePage(page_id),返回true。
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
我的Rails应用程序中安装了carrierwave。但是,当用户上传多页pdf时,我只希望应用程序获取文档中的第一页并将其转换为jpeg。这可能吗?用什么命令?这是我的uploader。#encoding:utf-8classImageUploader[200,300]##defscale(width,height)##dosomething#end#Createdifferentversionsofyouruploadedfiles:version:thumbdoprocess:resize_to_fill=>[150,210]process:convert=>:jpgdefful
有没有办法跳过CSV文件的第一行,让第二行作为标题?我有一个CSV文件,第一行是日期,第二行是标题,所以我需要能够在遍历它时跳过第一行。我尝试使用slice但它会将CSV转换为数组,我真的很想将其读取为CSV,以便我可以利用header。 最佳答案 根据您的数据,您可以使用另一种方法和skip_lines-option此示例跳过所有以#开头的行require'csv'CSV.parse(DATA.read,:col_sep=>';',:headers=>true,:skip_lines=>/^#/#Markcomments!)do|
我的任务是从数组中选择最高和最低的数字。我想我很清楚我想做什么,但只是努力以正确的格式访问信息以满足通过标准。defhigh_and_low(numbers)array=numbers.split("").map!{|x|x.to_i}array.sort!{|a,b|ba}putsarray[0,-1]end数字可能看起来像"80917234100",要通过,我需要输出"9234"。我正在尝试putsarray.first.last,但一直无法弄明白。 最佳答案 有Array#minmax完全满足您需要的方法:array=[80,
或者好像我必须自己写方法?(保持DHA不变):ruby-1.9.2-p180:001>s='omega-3(DHA)'=>"omega-3(DHA)"ruby-1.9.2-p180:002>s.capitalize=>"Omega-3(dha)"ruby-1.9.2-p180:003>s.titleize=>"Omega3(Dha)"ruby-1.9.2-p180:005>s[0].upcase+s[1..-1]=>"Omega-3(DHA)" 最佳答案 如果我的回答只是垃圾,我深表歉意(我不做ruby)。但我相信我已经为您找到了答
我有这个字符串:auteur="comtedeFlandreetHainaut,Baudouin,Jacques,Thierry"我想删除第一个逗号之前的所有内容,即在这种情况下保留“Baudouin,Jacques,Thierry”试过这个:nom=auteur.gsub(/.*,/,'')但这会删除最后一个逗号之前的每个逗号,只保留“Thierry”。 最佳答案 auteur.partition(",").last#=>"Baudouin,Jacques,Thierry" 关于rub
我有一个以时间戳为键的哈希。hash={"2016-05-31T22:30:58+02:00"=>{"path"=>"/","method"=>"GET"},"2016-05-31T22:31:23+02:00"=>{"path"=>"/tour","method"=>"GET"},"2016-05-31T22:31:05+02:00"=>{"path"=>"/contact_us","method"=>"GET"}}我订购了这个系列并得到了第一双这样的:hash.sort_by{|k,_|k}.first.first但是我该如何删除它呢?删除方法requiresyou知道key的准确
我有一个字符串数组,我需要从中提取第一个单词,将它们转换为整数并获得它们的总和。示例:["5Apple","5Orange","15Grapes"]预期输出=>25我的尝试:["5","5","15"].map(&:to_i).sum 最佳答案 我从你的问题中找到了答案。["5Apple","5Orange","15Grapes"].map(&:to_i).sum在数组中,如果存在任何整数可转换值,那么它将自动转换为整数。 关于arrays-字符串数组中字符串第一部分的总和,我们在Sta
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>