Hbase是一种NoSql模式的数据库,采用了列式存储。而采用了列存储天然具备以下优势:
同时由于列式存储将不同列分开存储,也造成了读取多列效率不高的问题
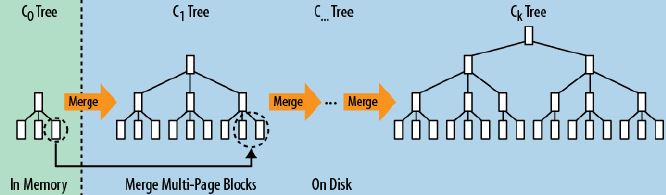
说到HBase,我们不得不说其采用的LSM Tree。我们都知道关系数据库中常用的B+Tree,叶子节点有序,但写入时可能存在大量随机写入,因此形成了其读快写慢的特点。
而HBase采用了LSM Tree,在读写之间寻找了平衡,损失了部分读取的性能,实现了快速的写入。LSM具体实现如下:
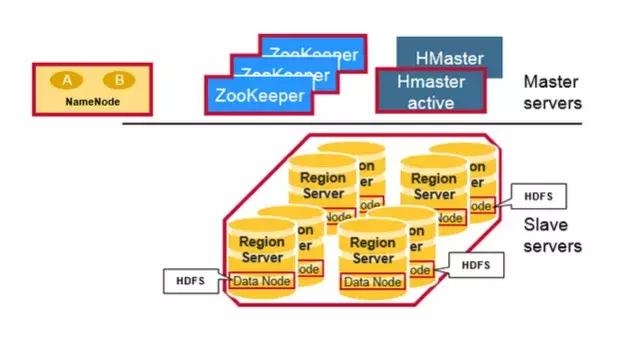
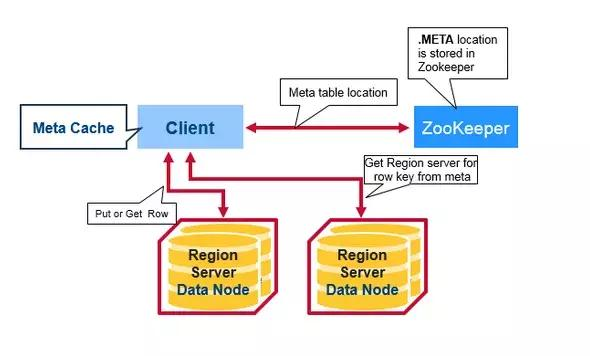
HBase中三个核心的Server形成其分布式存储架构。
1.下载Hbase2.4.11
https://hbase.apache.org/downloads.html
2.解压
tar -zxvf hbase-2.4.11-bin.tar.gz3.修改环境变量
cat conf/hbase-env.sh
export JAVA_HOME=/usr/local/java18/jdk1.8.0_331/4.修改hbase存储位置
cat conf/hbase-site.xml
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>5.启动Hbase
./bin/start-hbase.sh 6.验证Hbase
http://192.168.43.50:16010/master-status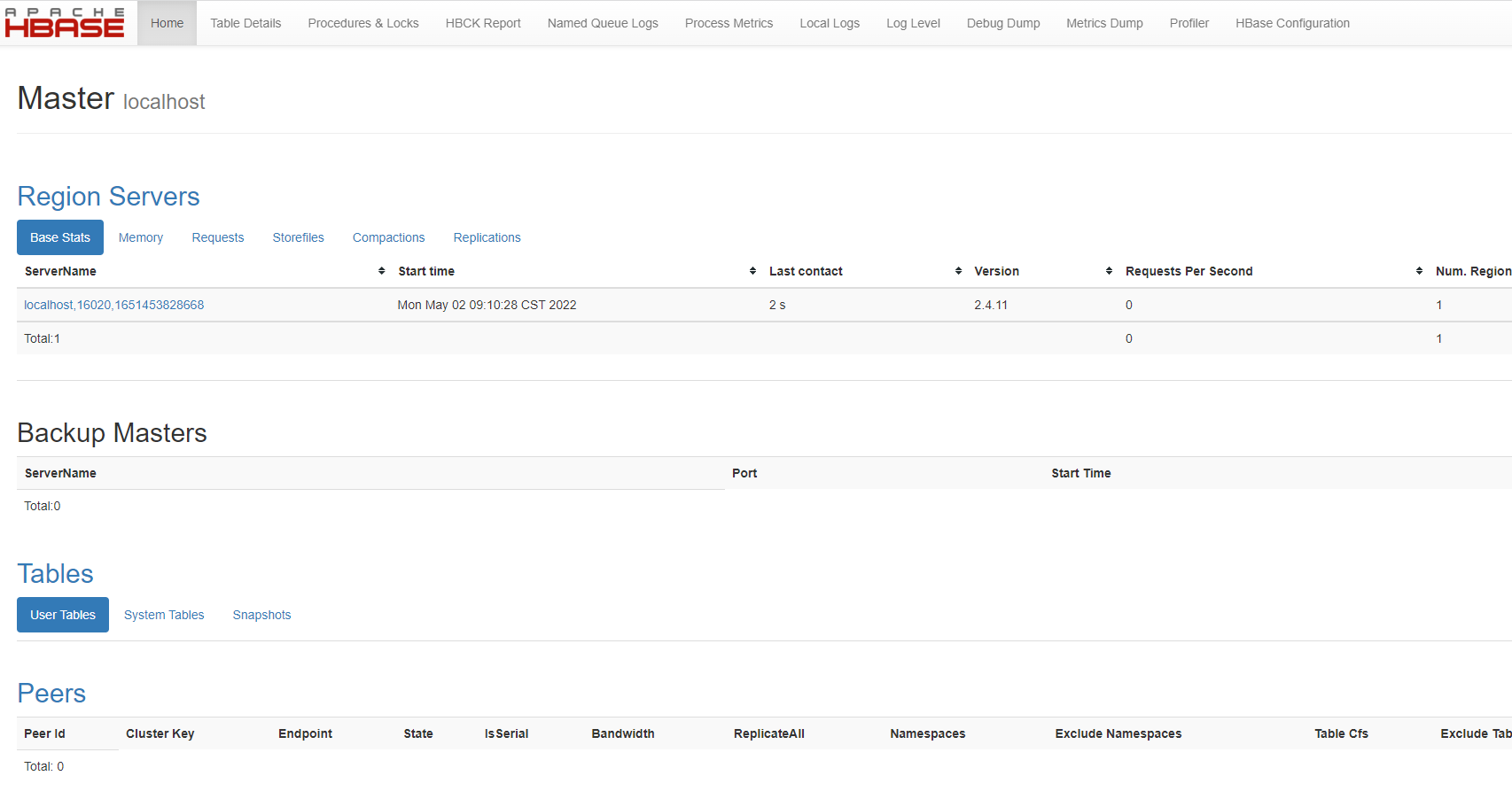
7.停止Hbase
./bin/stop-hbase.sh官方文档:https://hbase.apache.org/book.html#shell
1.进入shell
./bin/hbase shell2.查看表
hbase:001:0> list3.创建表
#create ‘<table name>’,’<column family>’
hbase:001:0> create 'emp', 'personal data', 'professional data'
Created table emp
Took 3.4810 seconds
=> Hbase::Table - emp4.创建/更新数据
#put ‘table name’,’row ’,'Column family:column name',’new value’
hbase:001:0> put 'emp','1','personal data:name','raju'
Took 1.1807 seconds5.查看数据
hbase:001:0> scan 'emp'
ROW COLUMN+CELL
1 column=personal data:name, timestamp=2022-05-02T09:55:38.861, value=raju
1 row(s)
Took 1.1758 seconds
#get ’<table name>’,’row1’
hbase:002:0> get 'emp', '1'
COLUMN CELL
personal data:name timestamp=2022-05-02T09:55:38.861, value=raju
1 row(s)
Took 1.3090 seconds6.删除数据
#delete ‘<table name>’, ‘<row>’, ‘<column name >’, ‘<time stamp>’
hbase:001:0> deleteall 'emp','1'
Took 0.9424 secondsC#访问Hbase可以根据thrift文件自己生成响应rpc client代码,通过rpc方式访问。
https://github.com/apache/hbase/tree/master/hbase-thrift/src/main/resources/org/apache/hadoop/hbase
也可以启动rest server通过微软的Microsoft.Hbase.Client访问,我们这次使用rest方式访问。
1.启动与关闭rest server
./bin/hbase-daemon.sh start rest
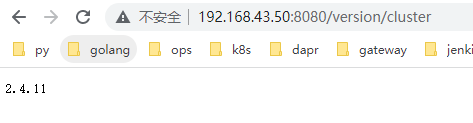
./bin/hbase-daemon.sh stop rest可通过访问http://192.168.43.50:8080/version/cluster验证rest是否启动成功
2.新增console项目,引入Microsoft.Hbase.Client包
https://github.com/hdinsight/hbase-sdk-for-net
3.编写测试demo
using Microsoft.HBase.Client;
using Microsoft.HBase.Client.LoadBalancing;
using org.apache.hadoop.hbase.rest.protobuf.generated;
var scanOptions = RequestOptions.GetDefaultOptions();
scanOptions.Port = 8080;
scanOptions.AlternativeEndpoint = "/";
var nodeIPs = new List<string>();
nodeIPs.Add("192.168.43.50");
var client = new HBaseClient(null, scanOptions, new LoadBalancerRoundRobin(nodeIPs));
var version = client.GetVersionAsync().Result;
Console.WriteLine(version);
var testTableSchema = new TableSchema();
testTableSchema.name = "mytablename";
testTableSchema.columns.Add(new ColumnSchema() { name = "d" });
testTableSchema.columns.Add(new ColumnSchema() { name = "f" });
client.CreateTableAsync(testTableSchema).Wait();通过hbase shell验证表是mytablename否创建成功
hbase:001:0> list
TABLE
emp
mytablename如何在ruby中调用C#dll? 最佳答案 我能想到几种可能性:为您的DLL编写(或找人编写)一个COM包装器,如果它还没有,则使用Ruby的WIN32OLE库来调用它;看看RubyCLR,其中一位作者是JohnLam,他继续在Microsoft从事IronRuby方面的工作。(估计不会再维护了,可能不支持.Net2.0以上的版本);正如其他地方已经提到的,看看使用IronRuby,如果这是您的技术选择。有一个主题是here.请注意,最后一篇文章实际上来自JohnLam(看起来像是2009年3月),他似乎很自在地断言RubyCL
我正在尝试在Ruby中复制Convert.ToBase64String()行为。这是我的C#代码:varsha1=newSHA1CryptoServiceProvider();varpasswordBytes=Encoding.UTF8.GetBytes("password");varpasswordHash=sha1.ComputeHash(passwordBytes);returnConvert.ToBase64String(passwordHash);//returns"W6ph5Mm5Pz8GgiULbPgzG37mj9g="当我在Ruby中尝试同样的事情时,我得到了相同sha
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
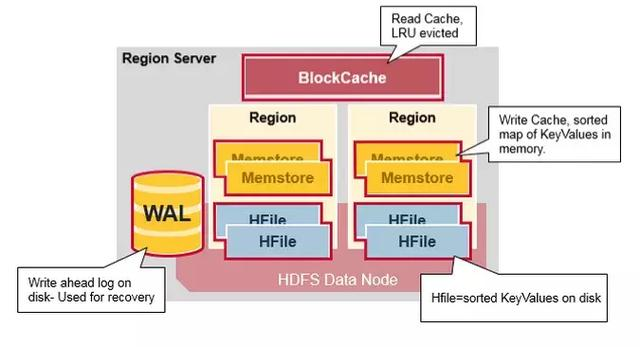
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
a=[3,4,7,8,3]b=[5,3,6,8,3]假设数组长度相同,是否有办法使用each或其他一些惯用方法从两个数组的每个元素中获取结果?不使用计数器?例如获取每个元素的乘积:[15,12,42,64,9](0..a.count-1).eachdo|i|太丑了...ruby1.9.3 最佳答案 使用Array.zip怎么样?:>>a=[3,4,7,8,3]=>[3,4,7,8,3]>>b=[5,3,6,8,3]=>[5,3,6,8,3]>>c=[]=>[]>>a.zip(b)do|i,j|c[[3,5],[4,3],[7,6],
我有一个非常简单的Controller来管理我的Rails应用程序中的静态页面:classPagesController我怎样才能让View模板返回它自己的名字,这样我就可以做这样的事情:#pricing.html.erb#-->"Pricing"感谢您的帮助。 最佳答案 4.3RoutingParametersTheparamshashwillalwayscontainthe:controllerand:actionkeys,butyoushouldusethemethodscontroller_nameandaction_nam