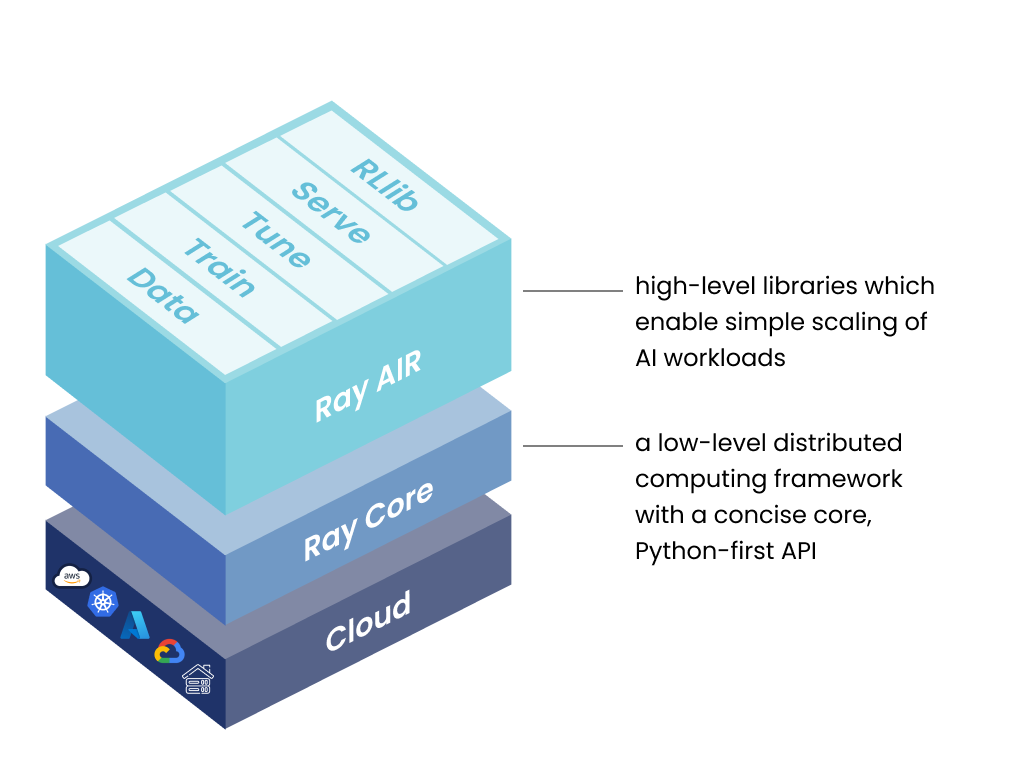
ray是开源分布式计算框架,为并行处理提供计算层,用于扩展AI与Python应用程序,是ML工作负载统一工具包
ML应用程序库集
通用分布式计算库
- Task -- Ray允许任意Python函数在单独的Python worker上运行,这些异步Python函数称为任务
- Actor -- 从函数扩展到类,是一个有状态的工作者,当一个Actor被创建,一个新的worker被创建,并且actor的方法被安排到那个特定的worker上,并且可以访问和修改那个worker的状态
- Object -- Task与Actor在对象上创建与计算,被称为远程对象,被存储在ray的分布式共享内存对象存储上,通过对象引用来引用远程对象。集群中每个节点都有一个对象存储,远程对象存储在何处(一个或多个节点上)与远程对象引用的持有者无关
- Placement Groups -- 允许用户跨多个节点原子性的保留资源组,以供后续Task与Actor使用
- Environment Dependencies -- 当Ray在远程机器上执行Task或Actor时,它们的依赖环境项(Python包、本地文件、环境变量)必须可供代码运行。解决环境依赖的方式有两种,一种是在集群启动前准备好对集群的依赖,另一种是在ray的运行时环境动态安装
一组连接到公共 Ray 头节点的工作节点,通过 kubeRay operator管理运行在k8s上的ray集群
ray版本:2.3.0
1主3从集群
# 配置文件 -- 一主两从(默认单主),文件名:k8s-3nodes.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
创建k8s集群
kind create cluster --config k8s-3nodes.yaml
# helm方式安装
# 添加Charts仓库
helm repo add kuberay https://ray-project.github.io/kuberay-helm/
# 安装default名称空间
# 安装 kubeRay operator
# 下载离线的chart包: helm pull kuberay/kuberay-operator --version 0.5.0
# 本地安装: helm install kuberay-operator
helm install kuberay-operator kuberay/kuberay-operator --version 0.5.0
# 创建ray示例集群,若通过sdk管理则跳过
# 下载离线的ray集群自定义资源:helm pull kuberay/ray-cluster --version 0.5.0
helm install raycluster kuberay/ray-cluster --version 0.5.0
# 获取ray集群对应的CR
kubectl get raycluster
# 查询pod的状态
kubectl get pods
# 转发svc 8265端口到本地8265端口
kubectl port-forward --address 0.0.0.0 svc/raycluster-kuberay-head-svc 8265:8265
# 登录ray head节点,并执行一个job
kubectl exec -it ${RAYCLUSTER_HEAD_POD} -- bash
python -c "import ray; ray.init(); print(ray.cluster_resources())" # (in Ray head Pod)
# 删除ray集群
helm uninstall raycluster
# 删除kubeRay
helm uninstall kuberay-operator
# 查询helm管理的资源
helm ls --all-namespaces
前置要求:
- 安装 KubeRay
- 安装 k8s sdk: pip install kubernetes
- 将python_client拷贝到PYTHONPATH路径下或者直接安装python_client, 该库路径为:https://github.com/ray-project/kuberay/tree/master/clients/python-client/python_client
from python_client import kuberay_cluster_api
from python_client.utils import kuberay_cluster_utils, kuberay_cluster_builder
def main():
# ray集群管理的api 获取集群列表、创建集群、更新集群、删除集群
kuberay_api = kuberay_cluster_api.RayClusterApi()
# CR 构建器,构建ray集群对应的字典格式的CR
cr_builder = kuberay_cluster_builder.ClusterBuilder()
# CR资源对象操作工具,更新cr资源
cluster_utils = kuberay_cluster_utils.ClusterUtils()
# 构建集群的CR,是一个字典对象,可以修改、删除、添加额外的属性
# 可以指定包含特定环境依赖的人ray镜像
cluster = (
cr_builder.build_meta(name="new-cluster1", labels={"demo-cluster": "yes"}) # 输入ray群名称、名称空间、资源标签、ray版本信息
.build_head(cpu_requests="0", memory_requests="0") # ray集群head信息: ray镜像名称、对应service类型、cpu memory的requests与limits、ray head启动参数
.build_worker(group_name="workers", cpu_requests="0", memory_requests="0") # ray集群worker信息: worker组名称、 ray镜像名称、ray启动命令、cpu memory的requests与limits、默认副本个数、最大与最小副本个数
.get_cluster()
)
# 检查CR是否构建成功
if not cr_builder.succeeded:
print("error building the cluster, aborting...")
return
# 创建ray集群
kuberay_api.create_ray_cluster(body=cluster)
# 更新ray集群CR中的worker副本集合
cluster_to_patch, succeeded = cluster_utils.update_worker_group_replicas(
cluster, group_name="workers", max_replicas=4, min_replicas=1, replicas=2
)
if succeeded:
# 更新ray集群
kuberay_api.patch_ray_cluster(
name=cluster_to_patch["metadata"]["name"], ray_patch=cluster_to_patch
)
# 在原来的集群的CR中的工作组添加新的工作组
cluster_to_patch, succeeded = cluster_utils.duplicate_worker_group(
cluster, group_name="workers", new_group_name="duplicate-workers"
)
if succeeded:
kuberay_api.patch_ray_cluster(
name=cluster_to_patch["metadata"]["name"], ray_patch=cluster_to_patch
)
# 列出所有创建的集群
kube_ray_list = kuberay_api.list_ray_clusters(k8s_namespace="default", label_selector='demo-cluster=yes')
if "items" in kube_ray_list:
for cluster in kube_ray_list["items"]:
print(cluster["metadata"]["name"], cluster["metadata"]["namespace"])
# 删除集群
if "items" in kube_ray_list:
for cluster in kube_ray_list["items"]:
print("deleting raycluster = {}".format(cluster["metadata"]["name"]))
# 通过指定名称删除ray集群
kuberay_api.delete_ray_cluster(
name=cluster["metadata"]["name"],
k8s_namespace=cluster["metadata"]["namespace"],
)
if __name__ == "__main__":
main()
前置: pip install -U "ray[default]"
# 文件名称: test_job.py
# python 标准库
import json
import ray
import sys
# 已经在ray节点安装的库
import redis
# 通过job提交时传递的模块依赖 runtime_env 配置 py_modules,通过 py_nodules传递过来就可以直接在job中导入
from test_module import test_1
import stk12
# 创建一个连接redeis对象,通过redis作为中转向job传递输入并获取job的输出
redis_cli = redis.Redis(host='192.168.6.205', port=6379, decode_responses=True)
# 通过redis获取传入过来的参数
input_params_value = None
if len(sys.argv) > 1:
input_params_key = sys.argv[1]
input_params_value = json.loads(redis_cli.get(input_params_key))
# 执行远程任务
@ray.remote
def hello_world(value):
return [v + 100 for v in value]
ray.init()
# 输出传递过来的参数
print("input_params_value:", input_params_value, type(input_params_key))
# 执行远程函数
result = ray.get(hello_world.remote(input_params_value))
# 获取输出key
output_key = input_params_key.split(":")[0] + ":output"
# 将输出结果放入redis
redis_cli.set(output_key, json.dumps(result))
# 测试传递过来的Python依赖库是否能正常导入
print(test_1.test_1())
print(stk12.__dir__())
# 模块路径: test_module/test_1.py
def test_1():
return "test_1"
import json
from ray.job_submission import JobSubmissionClient, JobStatus
import time
import uuid
import redis
# 上传un到ray集群供job使用的模块
import test_module
from agi import stk12
# 创建一个连接redeis对象
redis_cli = redis.Redis(host='192.168.6.205', port=6379, decode_responses=True)
# 创建一个client,指定远程ray集群的head地址
client = JobSubmissionClient("http://127.0.0.1:8265")
# 创建任务的ID
id = uuid.uuid4().hex
input_params_key = f"{id}:input"
input_params_value = [1, 2, 3, 4, 5]
# 将输入参数存入redis,供远程函数job使用
redis_cli.set(input_params_key, json.dumps(input_params_value))
# 提交一个ray job 是一个独立的ray应用程序
job_id = client.submit_job(
# 执行该job的入口脚本
entrypoint=f"python test_job.py {input_params_key}",
# 将本地文件上传到ray集群
runtime_env={
"working_dir": "./",
"py_modules": [test_module, stk12],
"env_vars": {"testenv": "test-1"}
},
# 自定义任务ID
submission_id=f"{id}"
)
# 输出job ID
print("job_id:", job_id)
def wait_until_status(job_id, status_to_wait_for, timeout_seconds=5):
"""轮询获取Job的状态,当完成时获取任务的的日志输出"""
start = time.time()
while time.time() - start <= timeout_seconds:
# 获取任务的状态
status = client.get_job_status(job_id)
print(f"status: {status}")
# 检查任务的状态
if status in status_to_wait_for:
break
time.sleep(1)
wait_until_status(job_id, {JobStatus.SUCCEEDED, JobStatus.STOPPED, JobStatus.FAILED})
# 输出job日志
logs = client.get_job_logs(job_id)
print(logs)
# 输出从job中获取的任务
output_key = job_id + ":output"
output_value = redis_cli.get(output_key)
print("output:", output_value)
from ray.job_submission import JobSubmissionClient, JobDetails, JobInfo, JobType, JobStatus
# 创建一个job提交客户端,如果管理多个ray集群的Job则切换或者创建多个连接ray head节点的客户端
job_cli = JobSubmissionClient("http://127.0.0.1:8265")
# Job信息,对应Job中submission_id属性
job_id = "b9ad6ff9ada445a29fb54307f1394594"
job_info = job_cli.get_job_info(job_id)
# 获取提交的所有job
jobs = job_cli.list_jobs()
for job in jobs:
# 获取job的状态
job_status = job_cli.get_job_status(job.submission_id)
print(f"job_id: {job.submission_id}, job_status: {job_status}")
# 输出job的json格式详情
print("job:", job.json())
# 停止Job
job_cli.stop_job(job_id)
# 删除 job
# job_cli.delete_job(job_id)
# 提交 Job
# job_cli.submit_job()
# 获取版本信息
print("version:", job_cli.get_version())
镜像文件打包下载、文件同步、运维脚本、数据导出与同步、镜像同步、服务启停、TATC卫星项目中算法任务的执行、批量同类型任务的计算(如卫星项目中卫星轨迹的计算)、备份任务
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.