存储:put 方法 put(key,value)
查询 : get 方法 get(key)
java 代码如下
import java.util.HashMap;
import java.util.Map;
public class App {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
map.put("刘一","刘一");
map.put("陈二","陈二");
map.put("张三","张三");
map.put("李四","李四");
map.put("王五","王五");
map.put("Money","我是猴哥Money老师");
System.out.println(map.get("Money"));
}
}
//输出结果:我是猴哥Money老师
程序是等于我们的数据结构和算法

HashMap 其实就是做存储的,做存储的就是数据结构
存储是按上面的规则存储的,那查询是怎么查的了
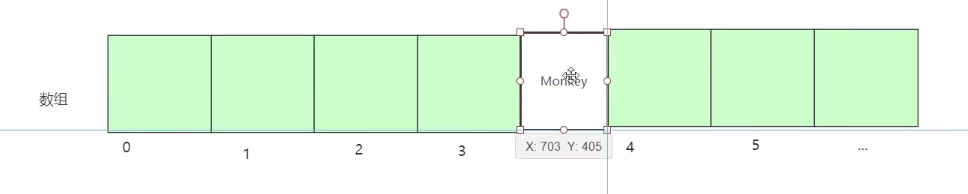
//数组:采用一段连续的存储单元来存储数据的
//数组的特点: 查询时间复杂度:0(1) ,删除,插入,时间负责度0(N),总结:查询块,插入慢
public static void main(String [] args){
//数组的定义:初始化长度为10,数据类型Integer ,
Integer integer[] = new Integer[10];
//指定下标,复制
integer[0]=0;
//指定下标,复制
integer[1]=1;
//指定下标,复制
integer[9]=2;
//指定下标,复制
integer[9]=400;
System.out.println(integer[9]);
}
// 输出结果:400
数组结构如图:

查询: 时间复杂度 0(1),查询非常快的
删除,插入 :时间复杂度0(N) 非常慢的,效率没有查询那么快
为什么查询快,插入,删除慢了?
查询快

插入,删除慢


扩充:
大家知道我们java 哪一个类,底层用的就是数组?
在我们的java.util 包下面有一个ArrayList 类,如图

怎么验证了?
我们查看它的add 方法
public boolean add(E var1) {
this.ensureCapacityInternal(this.size + 1);
this.elementData[this.size++] = var1;
return true;
}
如果面试被问到ArrayList 的特性,直接回答 查询快,插入,删除慢
谈谈什么是链表?
在java 中是这么定义的:
package node;
import com.sun.org.apache.bcel.internal.generic.IMPDEP1;
public class Node {
public Node next;
private Object data;
public Node(Object next) {
this.data = next;
}
//链表:链表是一种物理存储单元上非连续,非顺序的存储结构
//特点: 插入,删除时间复杂度0(1) 查找遍历时间复杂度0(N) 总结:插入快,查询慢
public static void main(String[] args){
Node head =new Node("monkey");
head.next =new Node("张三");
head.next.next =new Node("刘一");
System.out.println(head.data);
System.out.println(head.next.data);
System.out.println(head.next.next.data);
}
}
//输出结果:
//monkey
//张三
//刘一
链表:链表是一种物理存储单元上非连续,非顺序的存储结构,如图:
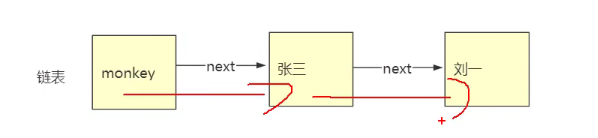
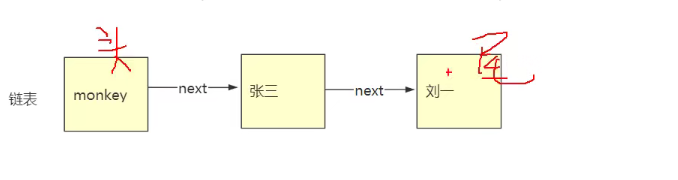
为什么它插入,删除快,查询慢了?
删除 某个节点,只需要上一个节点 head.next =null
插入 某个几点,只需要上一个节点 head.next 指向插入的节点,插入的节点指向下一个节点
查询某个节点:链表查询都要通过头节点,比如我们要查‘刘一’,我们则要先查头monkey,再查张三,再查到刘一,
虽然只有3个节点,但是我们要查到刘一要查三次,把整个链表都遍历了一次,所以查询慢!
扩充
在我们java 中,哪一个util 类采用的链表来实现的?

我们来查看它的add 方法
public boolean add(E var1) {
this.linkLast(var1);
return true;
}
//看上面有一个linkLast,如下:
void linkLast(E var1) {
LinkedList.Node var2 = this.last;
LinkedList.Node var3 = new LinkedList.Node(var2, var1, (LinkedList.Node)null);
this.last = var3;
if (var2 == null) {
this.first = var3;
} else {
var2.next = var3;
}
++this.size;
++this.modCount;
}
//看上面有一个Node,如下:
private static class Node<E> {
E item;
LinkedList.Node<E> next;
LinkedList.Node<E> prev;
Node(LinkedList.Node<E> var1, E var2, LinkedList.Node<E> var3) {
this.item = var2;
this.next = var3;
this.prev = var1;
}
}
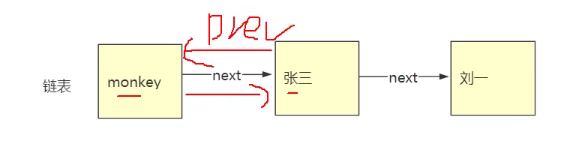
//上面有一个next,有一个prev
//这是一个双向链表
双向链表如图: 类似与分页,上一页,下一页,下面的对象也可以获取上面对象的数据(head.prev)
现在大家都已经了解JDK7 HashMap 数据结构了,开始了解下算法!
那么HashMap 是怎么去存储的了?他是如何将数据放到我们的数组和链表上的?
用的就是哈希算法,你们知道哈希算法的底层是怎么实现的?
哈希表
什么是哈希算法?
哈希算法(也叫散列),就是把任意长度值(key)通过散列算法变换成固定长度的key(地址), 通过这个地址进行访问的数据结构,
它通过把关键码值映射到表中一个位置来访问记录,以加快查找速度。

例如图中的John Smith 通过散列算法变换成固定长度的key:152 (永远是152),然后通过152 变成John Smith 是不可能的,哈希算法是不可逆的。
HashCode: 通过字符串算出它的ascii 码,进行mod(取模),算出哈希表中的下标

代码如下:
public class AsciiCode {
public static void main(String[] args) {
char c [] ="lies".toCharArray();
for (int i = 0; i < c.length; i++) {
System.out.println((c[i])+":" +(int)c[i]);
}
}
}
//输出结果:
//l:108
//i:105
//e:101
//s:115

如果我们取模会出现什么问题
会出现hash 冲突(碰撞)的一个问题,
什么是hash冲突

Hash冲突怎么解决了
我们用链表来解决这个问题, 链表是有一个指针的,我们可以让这个lies 指向这个foes,我们让foes 去匹配下标为9 的这个节点,如果匹配lies 不相等,则去匹配下一个节点foes,最终就会找到这个foes,这就是我们hash 算法底层的原理及解决冲突。
public class App {
public static void main(String[] args) {
//Map<String,String> map = new HashMap<>();
App map = new App();
map.put("刘一","刘一");
map.put("陈二","陈二");
map.put("张三","张三");
map.put("李四","李四");
map.put("王五","王五");
map.put("Money","我是猴哥Money老师");
//System.out.println(map.get("Money"));
}
public void put(String key,String value){
System.out.printf("key:%s:::::::::::::::;::hash值:%s:::::::::::::::::::存储位置:%s\r\n",key,key.hashCode(),Math.abs(key.hashCode() % 15));
}
}
//输出结果:
// key:刘一:::::::::::::::;::hash值:671464:::::::::::::::::::存储位置:4
// key:陈二:::::::::::::::;::hash值:1212740:::::::::::::::::::存储位置:5
// key:张三:::::::::::::::;::hash值:774889:::::::::::::::::::存储位置:4
// key:李四:::::::::::::::;::hash值:842061:::::::::::::::::::存储位置:6
// key:王五:::::::::::::::;::hash值:937065:::::::::::::::::::存储位置:0
// key:Monkey:::::::::::::::;::hash值:-1984628749:::::::::::::::::::存储位置:4
模拟我们是怎么存值的
我们一组数据就是 key,value , 可以用string,int 来存吗?这里显然不能,我们一般存这种值一般用对象来存值,我在这里随便命名用个Object或者叫Entry 对象,其实我们还要存另外两个值?(hash和next),当发生hash 冲突的时候(存储位置4) next 可以指向下一个节点,hash 值是用来比较的,比较hashCode 值是否相等!


上面的图形结构,我们就知道如何存数据了!
那我们该如何取数据了?
-假如我们要取‘刘一’ 的值
模拟java HashMap
定义一个Map 接口
/**
* 自己手动定义Map
* @param <K>
* @param <V>
*/
public interface Map<K,V> {
V put(K k,V v);
V get(K k);
int size();
interface Entry<K,V>{
K getKey();
V getValue();
}
}
定义一个实现Map 的HashMap
import sun.management.snmp.jvmmib.JvmRTInputArgsTableMeta;
/**
* 自己定义HashMap
* @param <K>
* @param <V>
*/
public class HashMap<K,V> implements Map<K,V>{
//存储元素对象
private Entry<K,V> table[] = null;
//扩容初始化
int size =0;
//初始化存储元素对象大小
public HashMap() {
this.table = new Entry[16];
}
/**
* 1.通过key hash 算法算出hash值,然后取模
* 2.取模后就有对应的index 数组下标,然后存储对象<Entry>
* 3.判断当前对象是否为空,如果空,直接存储,
* 4.如果不为空,我们就要用到next 链表
* 5.返回当前这个节点
* @param k
* @param v
* @return
*/
@Override
public V put(K k, V v) {
int index = hash(k);
Entry<K,V> entry = table[index];
if(null ==entry){
//刘一,陈二,李四,王五 就开始存在这个entry,每个entry 对象则存储到了对应table 中
table[index] = new Entry<>(k, v, index, null);
size++;
}else{
//冲突了,张三,Monkey
table[index] = new Entry<>(k, v, index, entry);
}
return table[index].getValue();
}
private int hash(K k) {
//HashMap 底层用到的是移位的操作,性能高很多 >>,我们这里就直接取模
int index =k.hashCode() % 16;
//Math.abs(index);
return index>0?index:-index;
}
/**
* 1.通过 key 进行hash 运算,取模,找到数组对应的下标 index
* 2.判断当前对象是否为空,如果不为空
* 3.判断是否相等,如果不相等
* 4.判断next 是否为空,如果不为空,
* 5.再判断相等,知道相等为止,或者为空为止
* 6.然后返回
*
*
*
* @param k
* @return
*/
@Override
public V get(K k) {
//如果没有存储数据那size 为0,也不用查了,直接返回null
if(size ==0){
return null;
}
int index = hash(k);
Entry<K, V> entry = findValue(table[index], k);
//通过index 找打这个对象
return entry==null?null:entry.getValue();
}
/**
*
* @param entry
* @param k 查询刘一
* @return
*/
private Entry<K,V> findValue(Entry<K,V> entry,K k) {
//存的可能是数值类型,也可能是字符串类型
if (k.equals(entry.getKey()) || k == entry.getKey()) {
return entry;
//如果不相等,估计这个节点是个链表,判断它next 数据是否匹配
} else {
if(entry.next !=null){
//用到递归,在链表里面一直查询这个k,值是否相等
return findValue(entry.next,k);
}
}
return null;
}
@Override
public int size() {
return size++;
}
class Entry<K,V> implements Map.Entry<K,V>{
//存四个值
K k;
V v;
int hash;
Entry<K,V> next;
public Entry(K k, V v, int hash, Entry<K, V> next) {
this.k = k;
this.v = v;
this.hash = hash;
this.next = next;
}
@Override
public K getKey() {
return k;
}
@Override
public V getValue() {
return v;
}
}
}
定义一个测试类
public class Test {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
map.put("Monkey","我是moneky老师");
map.put("东山再起","东山再起是位好同学");
System.out.println(map.get("Monkey"));
System.out.println(map.get("东山再起"));
}
//输出结果:
//我是moneky老师
//东山再起是位好同学
}
查看到测试结果,我们就能看到HashMap ,是怎么存储的,和获取值的!
但是JDK8 用的是红黑树,为什么了?
举个代码的例子
import com.sun.xml.internal.ws.api.model.wsdl.WSDLOutput;
public class Test {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
for (int i = 0; i < 1000; i++) {
map.put("Monkey"+i,"我是moneky老师"+i);
}
System.out.println(map);
}
}
可以看到这个map 的size 只有16,却存了很多的数据:

容量不够,我们就只能把这个数据放到链表上,链表无线延长,这种hash冲突是十分严重的,而链表的特性是查询慢,而链表又无线延长,我们查询链表末端的数据,这样性能就很低了,所以JDK8 就用红黑树了!
总结:解决链表过长查询效率过低的问题
前提条件
阈值 8
HashMap 类下面有个这个:
static final int TREEIFY_THRESHOLD = 8;
为什么要阈值 是8 了?
因为红黑叔插入慢,他要判断小中大(也就是左边的小于右边的),而链表插入快,删除快,但是为什么是 8 不是 6了?

我要去百度一下,有哪位大佬知道可以跟我讲下?
觉得文章不错,扫码有红包,支持一下创作吧

HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
西安华为OD面试体验开始投简历技术面试进展工作进展开始投简历去年一整年一直在考研和工作之间纠结,感觉自己的状态好像当时的疫情一样差劲。之前刚毕业的时候投了个大厂的简历,结果一面写算法的时候太拉跨了,虽然知道时dfs但是代码熟练度不够,放在平时给足时间自己可以调试通过,但是熟练度不够那面试当时就写不出来被刷了。说真的算法学到后期我感觉最重要的是熟练度和背板子(对于我这种普通玩家来说),面试题如果一上来短时间内想不出思路就完蛋了。然后由于当时找的工作不是很理想就又想考研了。但是考研是有风险的,我自我感觉自己可能冲不上那个学校,而找工作一个没成可以继续找嘛。本着抱着试试看的态度在boss上投了简历,
我为你们准备了一个简单的。我想要一个特色内容部分,其中排除了当前文章所以这可以通过delete_if使用MiddlemanBlog:但是我使用的是中间人代理,所以我无法访问current_article方法...我有一个YAML结构,其中包含以下模拟数据(以及其他数据),文件夹设置如下:data>site>caseStudy>RANDOM-ID423536.yaml(由CMS生成)在每个yaml文件中,您会发现如下内容::id:2k1YccJrQsKE2siSO6o6ac:title:Heyplace我的config.rb看起来像这样data.site.caseStudy.eachdo
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
点击->操作系统复习的文章集目录操作系统线程线程是什么进程与线程的关系用户态/内核态操作系统资源管理内核态用户态内核态/用户态切换程序运行类型分析计算密集型IO密集型结合进程,线程来理解程序运行类型分析协程基础上下文切换协程协程为什么叫协作式线程?协程的优缺点操作系统线程典型问题:简述进程和线程的区别以下内容带您一步步了解线程是什么比进程更小的独立运行的基本单位-线程(Threads)线程的提出主要是为了提高系统内程序并发执行的程度,从而进一步提升系统的吞吐量,充分发挥多核CPU的优越性而设计的引入进程是为了操作系统更加方便地管理程序,使得多个程序能并发管理和执行而线程则是为了减少程序在并发执
我正在为我的网站使用MiddlemanBloggem,但默认情况下,博客文章似乎需要位于/source中,这在查看vim中的树时并不是特别好并尝试在其中找到其他文件之一(例如模板)。通过查看文档,我看不出是否有任何方法可以移动博客文章,以便将它们存储在其他地方,例如blog_articles文件夹或类似文件夹。这可能吗? 最佳答案 将以下内容放入您的config.rb文件中。activate:blogdo|blog|blog.permalink=":year-:month-:day-:title.html"blog.sources=
我有一个Ruby脚本,它想要确定它的绝对路径,以便找到一些相对于脚本存储的数据文件。最简单/最好的方法是什么? 最佳答案 这可以简单地使用:File.expand_path$0 关于ruby-如何找到当前运行的Ruby脚本的绝对路径?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/7802630/
文章目录华为OD面试流程1.mysql数据库建了两个字段,且设置了联合索引,如果其中有一个字段为空会出现什么问题?2.谈谈springIOC的理解,有什么好处,解决了什么问题3.谈谈springAOP的理解,切面编程有没有实际应用,有哪些注解,作用是什么,有那些应用场景?4.Erika和zookeeper有了解过吗,作用是什么,主要解决了什么问题5.谈谈JDK、JRE、JVM的理解,区别是什么6.谈谈对泛型的理解7.JVM的组成华为OD面试流程机试:三道算法题,关于机试,橡皮擦已经准备好了各语言专栏,可以直接订阅。性格测试:机试技术一面(本专栏核心)技术二面(本专栏核心)主管面试定级定薪发of
前言 Slowloris攻击是我在李华峰老师的书——《MetasploitWeb 渗透测试实战》里面看的,感觉既简单又使用,现在这种攻击是很容易被防护的啦。不过我也不敢真刀实战的去试,只是拿个靶机玩玩罢了。 废话还是写在结语里面吧。(划掉)结语可以不看(划掉)Slowloris攻击的原理 Slowloris是一种资源消耗类DoS攻击,它利用部分HTTP请求进行操作。也叫做慢速攻击,这里的慢速并不是说发动攻击慢,而是访问一条链接的速度慢。Slowloris攻击的功能是打开与目标Web服务器的连接,然后尽可能长时间的保持这些连接打开。如果由多台电脑同时发起Slo
所以我正在关注http://guides.rubyonrails.org/getting_started.html上的官方ROR教程我被困在第5.8节,它教我如何列出所有文章下面是我的controller和index.html.erbControllerclassArticlesControllerindex.html.erbListingarticlesTitleText我收到带有错误消息的NoMethodErrorinArticles#indexundefinedmethod`each'fornil:NilClass"怎么了?我从网站上复制并粘贴了代码以查看我做错了什么,但仍然无法