Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎;本文主要介绍其基本概念。
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用 Elasticsearch 的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到 Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
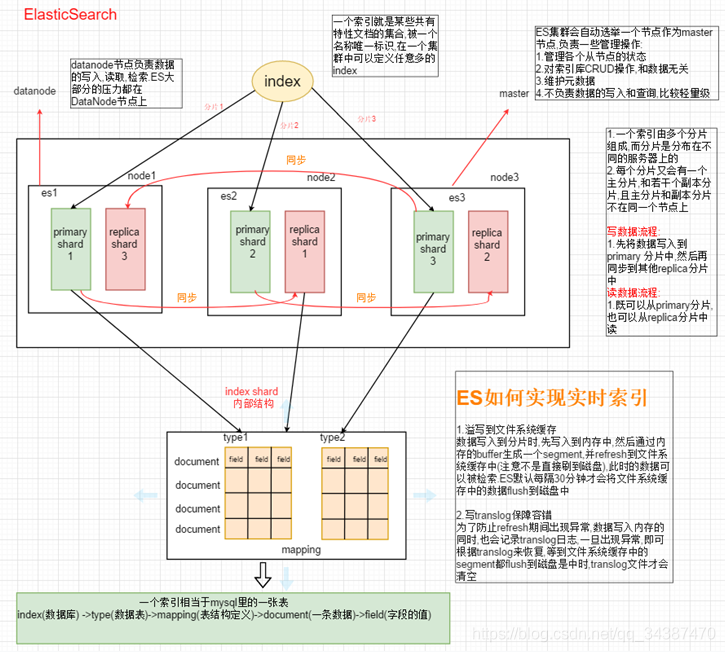
Elasticsearch 可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。Elasticsearch 是分布式的,这意味着索引可以被分成分片,每个分片可以有 0 个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch 索引指相互关联的文档集合。Elasticsearch 会以 JSON 文档的形式存储数据。每个文档都会在一组键(字段或属性的名称)和它们对应的值(字符串、数字、布尔值、日期、数值组、地理位置或其他类型的数据)之间建立联系。
Elasticsearch 使用的是一种名为倒排索引的数据结构,这一结构的设计可以允许十分快速地进行全文本搜索。倒排索引会列出在所有文档中出现的每个特有词汇,并且可以找到包含每个词汇的全部文档。
在索引过程中,Elasticsearch 会存储文档并构建倒排索引,这样用户便可以近实时地对文档数据进行搜索。索引过程是在索引 API 中启动的,通过此 API 您既可向特定索引中添加 JSON 文档,也可更改特定索引中的 JSON 文档。
Elasticsearch 在速度和可扩展性方面都表现出色,而且还能够索引多种类型的内容,这意味着其可用于多种用例:
索引是具有相似结构的文档的集合, 等同于 Solr 中的集合;每个索引有唯一的名称, 名称小写。索引类似 MySQL 中 database 概念。
文档是存储在 ES 中的 JSON 格式的字符串, 由 field(字段) 构成。
字段可以是一个简单的值(如字符串、数字、日期), 也可以是一个数组, 还可以嵌套一个对象或多个对象。字段类似于关系数据库中表数据的列, 每个字段都对应一个类型. 可以指定如何分析某一字段的值, 即对 field 指定分词器。
type 是 index 的逻辑分类, 在 ES 6.x 版本之前, 每个索引中可以定义一个或多个 type, 而在 6.X 版本之后, 一个 index 中只能定义一个 type。通常,会为具有一组共同字段的文档定义一个 type。
mapping 是对字段的定义说明,如某个字段的数据类型、默认值、分析器、是否被索引等等;类似于 Solr 中 schema.xml 约束文件的作用。
单个 node 无法存储大量的索引数据, ES 可以把一个索引分成多个分片, 分布到不同的 node 上, 从而构成分布式索引。每个分片都是一个 Lucene 实例, 也就是说每个分片底层都有一个单独的 Lucene 提供独立的索引和检索服务, 它们可以托管在集群的任一 node 上。
可以为 shard 创建副本,提高数据的安全性。建立索引时, 系统会先将索引存储在主分片(Primary Shard)中, 然后再将主分片中的索引复制到副本分片(Replica Shard)中。副本提高了系统的可用性和容错性已经查询时的吞吐量。
| Elasticsearch | RDBMS |
| Index(索引) | DataBase(数据库) |
| Type(类型) | Table(表) |
| Document(文档) | Row(行) |
| Field(字段) | Column(列) |
| Mapping(映射) | Schema(约束) |
| Query DSL(ES 的查询语言) | SQL(结构化查询语言) |
| 字段类型 | 说明 |
| text | 文本类型,会就行分词处理 |
| keyword | 关键字类型,不就行分词处理 |
| byte | -128~127 |
| short | -32768~32767 |
| integer | -2^31~2^31-1 |
| long | -2^63~2^63-1 |
| double | 64 位双精度 |
| float | 32 位单精度 |
| half_float | 16 位半精度 |
| scaled_float | 底层基于 long 存储,支持一个固定的精度因子;如果存储浮点数 0.15,设置 scaling_fac-tor=100,则该类型会以一个整数 15 进行存储,有效提高其存储性能。 |
| date |
日期类型,json 对象没有日期类型,表现形式如下: |
| boolean | 其取值为 "true"、"false"、true、false |
| binary | 二进制类型,用 base64 来表示 |
| array | 数组 |
| ip | 用于存储 IPv4 或者 IPv6 的地址 |
| range datatype |
数据范围类型,一个字段表示一个范围,具体包含如下类型: |
| 分词器 | 说明 |
| standard | 默认分词器,按词切分,小写处理 |
| simple | 按照非字母切分(符号被过滤),小写处理 |
| stop | 小写处理,停用词过滤(the ,a,is) |
| whitespace | 按照空格切分,不转小写 |
| keyword | 不分词,直接将输入当做输出 |
| pattern | 正则表达式,默认 \W+ |
| ik_smart | ik 分词器,只分一次,句子里面的每个字只会出现一次 |
| ik_max_word | ik 分词器,句子的字可以反复出现。 |

RESTful Style API:RESTful 风格接口。
Java(Netty):Java 客户端。
Transport:集群与客户端交互方式。
Disvcovery:节点发现及 master 选举。Zen 属于 ES 的特殊发现机制,也是 ES 的内置发现机制,它提供了两种发现方式:单播和多播。EC2 是另外一种插件形式的发现机制。
Scripting:脚本功能,支持 mvel、js、python等。
3rd plugins:第三方插件。
Index Moudle:索引模块。
Search Moudle:查询模块。
Mapping:映射信息。
River:用于其他数据源中获取数据,该项功能以插件的形式存在,目前支持的数据源:RabbitMQ、ActiveMQ、CSV、FileSystem、JDBC、GitHub、Kafka 等;针对关系型数据库提供了统一的 jdbc-river 来进行数据操作。
DistributedLucene Directory:Lucene 数据目录。
Gateway:ElasticSearch 索引的持久化存储方式。Gateway支持多种类型:本地文件系统(默认)、分布式文件系统 Hadoop 以及 AMZ 的 S3 云存储服务。
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
文章目录1.任务背景2.任务目标3.相关知识点4.任务实操4.1安装配置JDK4.2启动FISCOBCOS4.3下载解压WeBASE-Front4.4拷贝sdk证书文件4.5启动节点4.6访问节点4.7检查运行状态5.任务总结1.任务背景FISCOBCOS其实是有控制台管理工具,用来对区块链系统进行各种管理操作。但是对于初学者来说,还是可视化界面更友好,本节就来介绍WeBASE管理平台,这是一款微众银行开源的自研区块链中间件平台,可以降低区块链使用的门槛,大幅提高区块链应用的开发效率。微众银行是腾讯牵头设立的民营银行,在国内民营银行里还是比较出名的。微众银行参与FISCOBCOS生态建设,一定
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记