
先说重点:Azure Database for MySQL 单一服务器即将停用。Azure Database for MySQL 单一服务器计划在 2024 年 9 月 16 日之前停用。
文章目录
你在使用既有的 Azure Database for MySQL single server 服务的时候,会出现如下的提示:

Azure Database for MySQL single server is on the retirement path. Migrate your server when eligible using Azure Database Migration Service. Check migration eligibility here.
微软官方公告截图如下:原网址点击这里
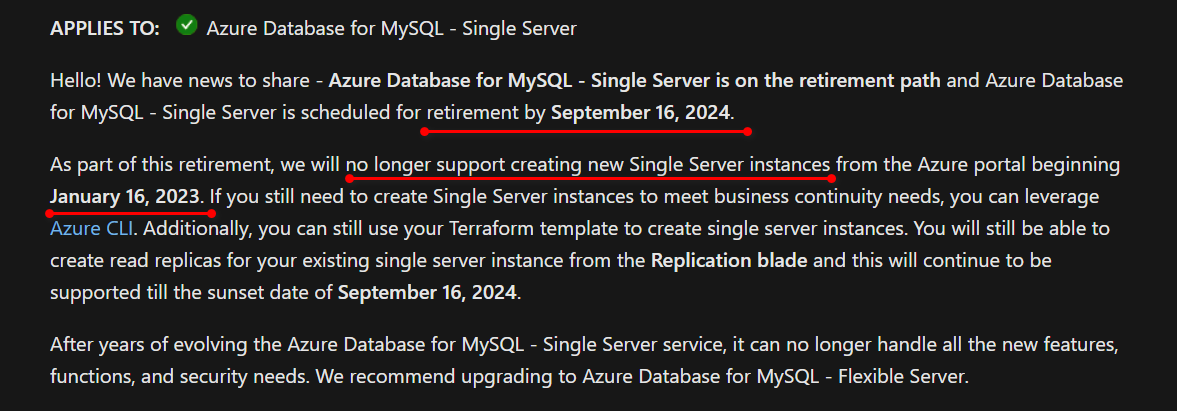
从公告连接上可以看到在 2023 年 1 月 16 日开始不再支持从 Azure 门户创建新的单一服务器实例的功能。
这也就是说在这个时间点后,你在Azure portal门户上,就不能在创建Azure Database for MySQL single server服务了,而既有的公司在使用Azure Database for MySQL single server的时候也只能使用到 2024 年 9 月 16 日,之后就不能在使用了。
总之就是微软不维护单一服务的数据库了,而给出的唯一建议就是下面所说的 从单一服务器迁移到灵活服务器。
因为是数据库迁移,在决定迁移前最好做好风险评估与数据库备份等操作。下面会列举三个主要的关心点来说从单一服务器迁移到灵活服务器比较重要的事项
如何 从单一服务器迁移到灵活服务器
迁移方法参照:https://learn.microsoft.com/zh-cn/azure/dms/tutorial-mysql-azure-single-to-flex-offline-portal


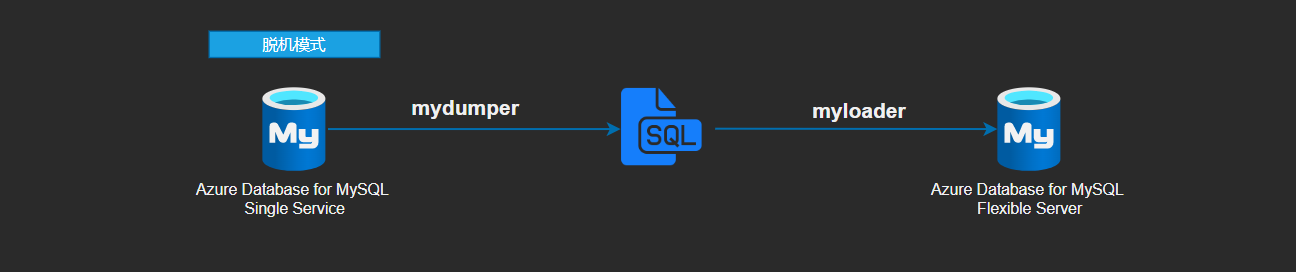
迁移方法参照:https://learn.microsoft.com/zh-cn/azure/mysql/migrate/concepts-migrate-mydumper-myloader
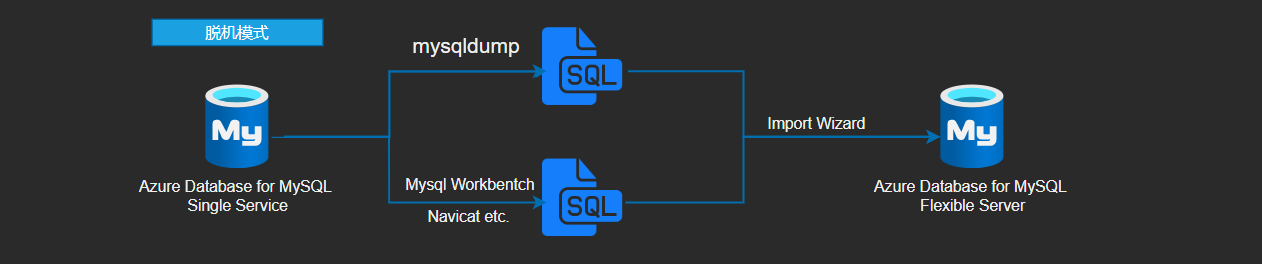
迁移方法参照:https://learn.microsoft.com/zh-cn/azure/mysql/single-server/concepts-migrate-import-export
迁移方法参照:https://learn.microsoft.com/zh-cn/azure/dms/tutorial-mysql-azure-single-to-flex-online-portal
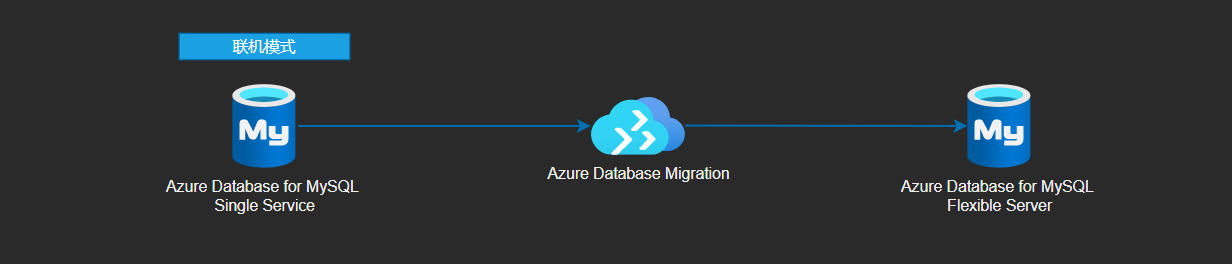
注意:要进行联机迁移,可将 DMS 支持的启用事务一致性功能与数据传入复制或复制更改结合使用。
DMS 联机迁移功能目前为预览版。 DMS 支持 MySQL 版本 5.7 和 8.0 的迁移,它还支持从较低版本的 MySQL 服务器(v5.7 和更高版本)迁移到更高版本的服务器。 此外,DMS 支持跨区域、跨资源组和跨订阅迁移,因此可以为目标服务器选择不同于为源服务器指定的区域、资源组和订阅。

Azure Database for MySQL 单一服务器在 2018 年正式发布 (GA)。 但是,鉴于客户反馈和 Azure 数据库环境中计算、可用性、可伸缩性和性能功能方面的新进展,单一服务器产品/服务需要停用,并升级为新的体系结构 - Azure Database for MySQL 灵活服务器,以充分利用 Azure 的开源数据库平台。
Azure Database for MySQL 单一服务器计划于 2024 年 9 月 16 日停用,因此强烈建议尽早将单一服务器迁移到灵活服务器,以确保有足够的时间运行迁移生命周期,应用灵活服务器提供的优势,并确保业务连续性。
现有 Azure Database for MySQL 单一服务器可以保持现有运行,并且将在停用日期之前受到正式支持。
但是,将不会为单一服务器发布任何新更新。
2024 年 9 月 16 日之后 不能在继续使用!!!迁移要尽早啊兄弟们!
如果为目标灵活服务器选择同一区域或区域冗余高可用性,则账单费用高于使用单一服务器。 同一区域或区域冗余高可用性需要启动热备用服务器以及存储冗余备份,因此会增加成本。 此体系结构可减少计划外中断和计划内维护期间的停机时间。 此外,根据工作负载,灵活服务器可以提供优于单一服务器性能,这样就可以在灵活服务器上以较低的 SKU 运行工作负载,因此总体成本可能与单一服务器类似。
单一服务器版本 8.0 的最后一个次要版本升级是 8.0.15。 这个非常重要!如果你的application运行在这个版本,那么迁移到弹性数据库的时候,一定要确认好弹性数据库的版本,并且这个弹性服务器的mysql版本是否不会对你现在的程序造成影响,是否会出现bug之类的!
注:本文原创由
bluetata发布于: https://bluetata.blog.csdn.net/ 转载请务必注明出处。
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
为了防止在迁移到生产站点期间出现数据库事务错误,我们遵循了https://github.com/LendingHome/zero_downtime_migrations中列出的建议。(具体由https://robots.thoughtbot.com/how-to-create-postgres-indexes-concurrently-in概述),但在特别大的表上创建索引期间,即使是索引创建的“并发”方法也会锁定表并导致该表上的任何ActiveRecord创建或更新导致各自的事务失败有PG::InFailedSqlTransaction异常。下面是我们运行Rails4.2(使用Acti
我正在使用最新版本的Capistrano和我的Rails4应用程序。运行capdpeloy时。我得到了很多输出,包括这次失败:DEBUG[04b6e226]Running/usr/bin/env[-f/var/www/skateboxes/releases/20131022135522/config/database.yml]on162.243.33.179DEBUG[04b6e226]Command:[-f/var/www/skateboxes/releases/20131022135522/config/database.yml]DEBUG[04b6e226]Finishedin0
我想创建一个RailsController,从网上下载一系列jpg文件,并直接将它们作为二进制文件写入数据库(我不是要上传表格)关于如何做到这一点的任何线索?谢谢编辑:这是我已经使用attachment-fugem编写的一些代码:http=Net::HTTP.new('awebsite',443)http.use_ssl=truehttp.verify_mode=OpenSSL::SSL::VERIFY_NONEhttp.start(){|http|req=Net::HTTP::Get.new("image.jpg")req.basic_authlogin,passwordrespon
我们刚刚将虚拟机升级到我认为相同的ruby配置(通过RVM...Ruby1.9.2、Rails3.0.7、DataMapper1.1.0)。最大的区别是我们从MySQL5.0升级到5.1。出于某种原因,在我们的旧VM上运行的完全相同的代码/database.yml现在在我们的新VM尝试连接到数据库时失败了。问题是这个YAML:mysql_defaults:&mysql_defaultsadapter:mysqlencoding:UTF-8username:userpassword:passhost:localhostdevelopment:正在扩展到:"mysql_defaults
我正在开发一个通过表单发送数据的Rails应用程序。我想在表单发送之后,但在它被处理之前修改表单的一些“参数”。我现在拥有的{"commit"=>"Create","authenticity_token"=>"0000000000000000000000000""page"=>{"body"=>"TEST","link_attributes"=>[{"action"=>"Foo"},{"action"=>"Bar"},{"action"=>"Test"},{"action"=>"Blah"}]}}我想要什么{"commit"=>"Create","authenticity_token"
当我尝试使用capistrano部署我的应用程序时,我会收到此错误:failed:"sh-c'cp/var/www/my_app/releases/20120313115055/config/database.staging.yml/var/www/my_app/releases/20120313115055/config/database.yml'"onIP_ADDR我的database.yml即空的,database.staging.yml:production:adapter:mysql2encoding:utf8reconnect:falsedatabase:my_dbpool
我最近一直在研究NoSql选项。我的场景如下:我们从位于世界各地偏远地区的定制硬件收集和存储数据。我们每15分钟记录一次来自每个站点的数据。我们最终希望每1分钟移动一次。每条记录有20到200个测量值。一旦设置好硬件,每次都会记录和报告相同的测量值。我们面临的最大问题是我们从每个项目中获得了一组不同的衡量标准。我们测量大约50-100种不同的测量类型,但是任何项目都可以有任意数量的每种测量类型。没有可以容纳数据的预设列集。因此,当我们在系统上设置和配置项目时,我们创建并构建了每个项目数据表,其中包含所需的确切列。我们提供工具来帮助分析数据。这通常包括更多的计算和数据聚合,其中一些我们也
我从GitHub存储库克隆了一个应用程序文件夹,在捆绑安装gems之后,我尝试使用rakedb:setup和rakedb:migrate命令,但都没有用,这是我的错误消息:**arun997@promanager:~/workspace(master)$rakedb:setuprequire'rails/all'...2.470sBundler.require...7.590srakeaborted!Cannotload`Rails.application.database_configuration`:Couldnotloaddatabaseconfiguration.Nosuchf
我有一个修改数据库中记录的后台进程。模型使用如下方式连接到数据库:dbconfig=YAML::load(File.open('database.yml'))ActiveRecord::Base.establish_connection(dbconfig["development"])classClcar所有模型类的顶部都有这些行。我同意这是一种糟糕的做法。有没有更好的方法来连接到模型类?如何将连接传递给模型?我希望能够在不同的环境(比如“生产”)中运行我的后台进程。我该如何实现? 最佳答案 我会在您的后台进程开始时设置一次连接。一