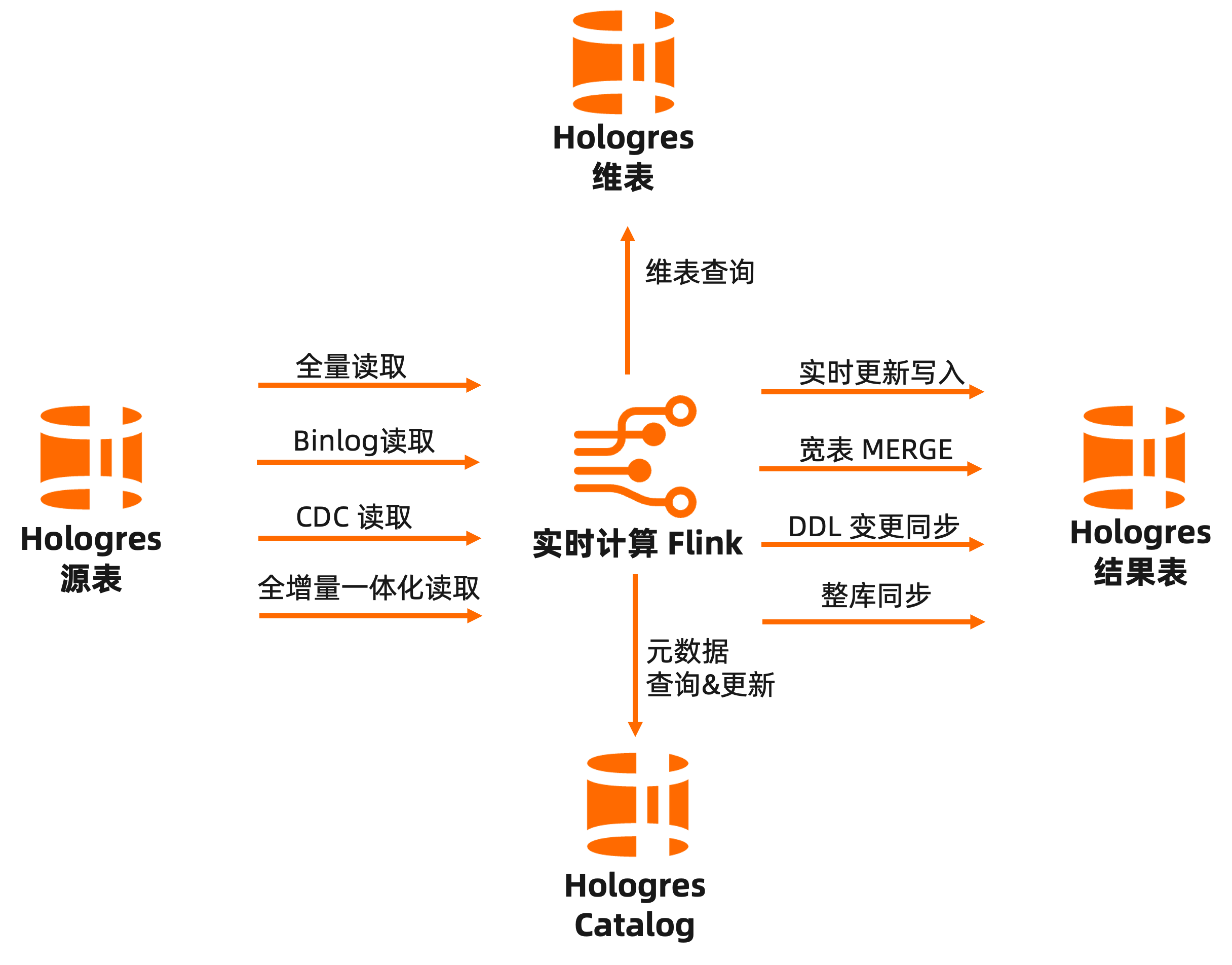
阿里云 Flink 与 Hologres 深度集成,助力企业快速构建一站式实时数仓:
可通过阿里云 Flink 实时写入 Hologres,高性能写入与更新,数据写入即可见,无延迟,满足实时数仓高性能低延迟写入需求;
可通过阿里云 Flink 的全量读取、Binlog 读取、CDC 读取、全增量一体化等多种方式,读取 Hologres 源表数据,无需额外组件,统一计算和存储,加速数据流转效率;
可通过阿里云 Flink 读取 Hologres 维表,助力高性能维表关联、数据打宽等多种应用场景;
阿里云 Flink 与 Hologres 元数据打通,通过 Hologres Catalog,实现元数据自动发现,极大提升作业开发效率和正确性。
通过阿里云 Flink 与 Hologres 的实时数仓标准解决方案,能够支撑多种实时数仓应用场景,如实时推荐、实时风控等,满足企业的实时分析需求。下面我们将会介绍阿里云 Flink + Hologres 的典型应用场景,助力业务更加高效的搭建实时数仓。
实时数仓搭建的第一步便是海量数据的实时入仓,基于阿里云 Flink CDC 可以简单高效地将海量数据同步到实时数仓中,并能将增量数据以及表结构变更实时同步到数仓中。而整个流程只需在阿里云 Flink 上定义一条 CREATE DATABASE AS DATABASE 的 SQL 即可(详细步骤可参考 实时入仓快速入门 )。经测试,对于 MySQL 中的 TPC-DS 1T 数据集,使用阿里云 Flink 64 并发,只需 5 小时便能完全同步到 Hologres,TPS 约 30 万条/秒。在增量 Binlog 同步阶段,使用阿里云 Flink 单并发,同步性能达到 10 万条/秒。

数据实时入仓形成了 ODS 层的数据后,通常需要将事实数据与维度数据利用 Flink 多流 Join 的能力实时地打平成宽表,结合 Hologres 宽表极佳的多维分析性能,助力上层业务查询提速。阿里云 Flink 支持以全增量一体化的模式读取 Hologres 表,即先读取全量数据再平滑切换到读取 CDC 数据,整个过程保证数据的不重不丢。因此基于阿里云 Flink 可以非常方便地实时加工和打宽 Hologres 的 ODS 层数据,完成 DWD 层的宽表模型构建。
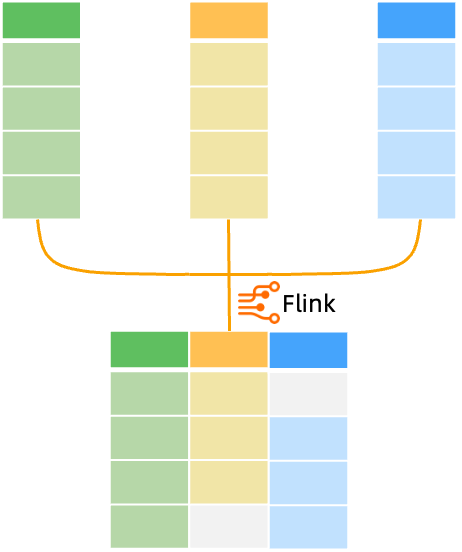
数据仓库中我们通常需要关心的就是建模,数据模型通常分为四种:宽表模型、星型模型、雪花模型、星座模型(Hologres 均支持),在这里我们重点要提到的是宽表模型的建设。宽表模型通常是指将业务主体相关的指标、维表、属性关联在一起的模型表,也可以泛指将多个事实表和多个维度表相关联到一起形成的宽表。
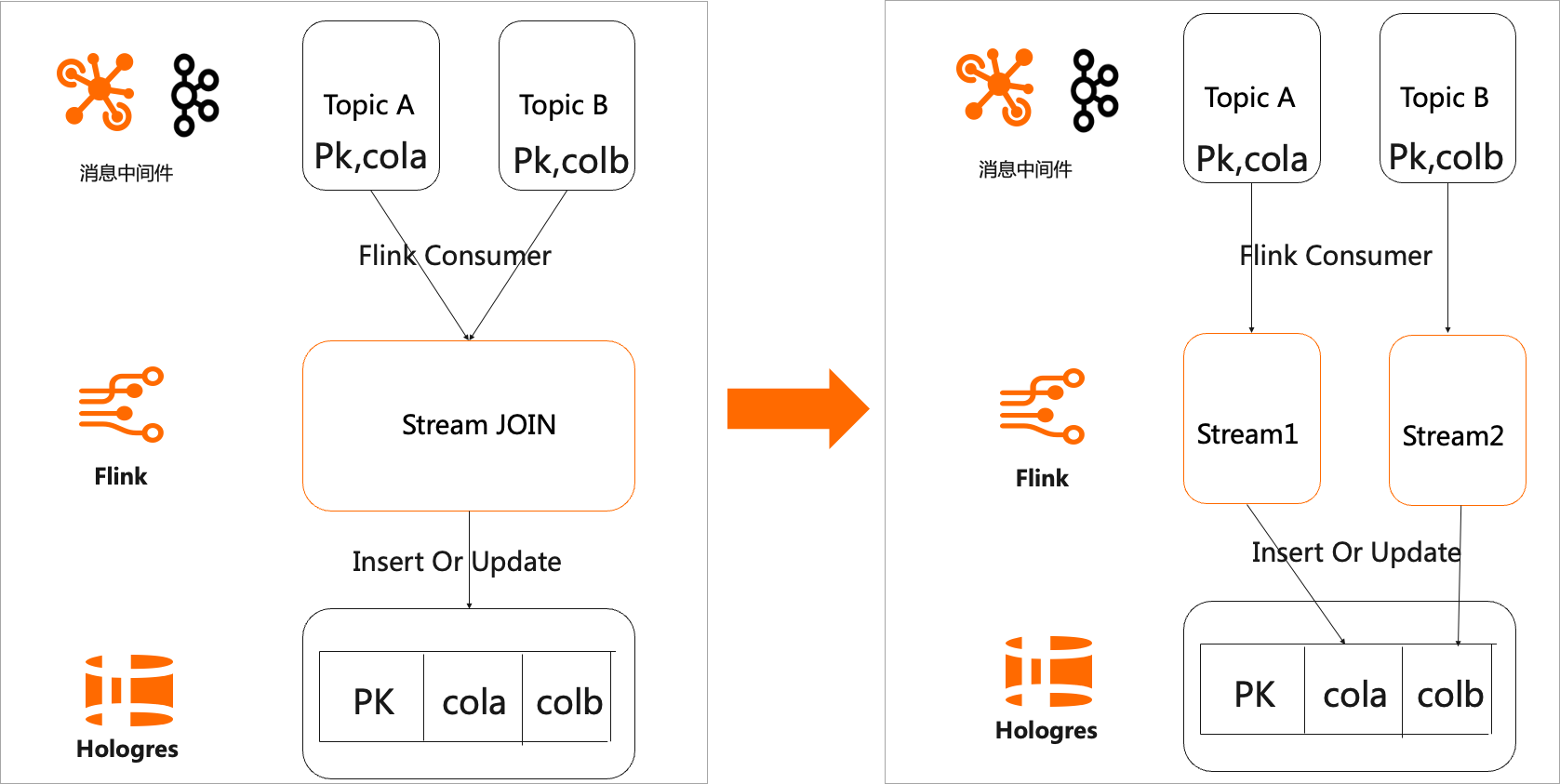
宽表建设通常的做法就是通过阿里云 Flink 的双流 Join 来实现,包括 Regular Join,Interval Join,Temporal Join。对于主键关联的场景(即 Join 条件分别是两条流的主键),我们可以将 Join 的工作下沉到 Hologres 去做,通过 Hologres 的局部更新功能来实现宽表 Merge,从而省去了 Flink Join 的状态维护成本。比如广告场景中,一个 Flink 任务处理广告曝光数据流,统计每个产品的曝光量,以产品 ID 作为主键,更新到产品指标宽表中。同时,另一个 Flink 任务处理广告点击数据流,统计每个产品的点击量,也以产品 ID 作为主键,更新到产品指标宽表中。整个过程不需要进行双流 Join,最终 Hologres 会自己完成整行数据的组装。基于得到的产品指标宽表,用户可以方便地在 Hologres 进行广告营销的分析,例如计算产品的 CTR=点击数/曝光数。下图和代码示例展示了如何从双流 Join 改为宽表 Merge。
CREATE TABLE ods_ad_click (
product_id INT,
click_id BIGINT,
click_time TIMESTAMP
) WITH ('connector'='datahub', 'topic'='..');
CREATE TABLE ods_ad_impressions (
product_id INT,
imp_id BIGINT,
imp_time TIMESTAMP
) WITH ('connector'='datahub', 'topic'='..');
CREATE TABLE dws_ad_product (
product_id INT,
click_cnt BIGINT,
imp_cnt BIGINT,
PRIMARY KEY (product_id) NOT ENFORCED
) WITH ('connector'='hologres','insertOrUpdate'='true');
INSERT INTO dws_ad_product (product_id, click_cnt)
SELECT product_id, COUNT(click_id) as click_cnt
FROM ods_ad_click
GROUP BY product_id;
INSERT INTO dws_ad_product (product_id, imp_cnt)
SELECT product_id, COUNT(imp_id) AS imp_cnt
FROM ods_ad_impressions
GROUP BY product_id;使用 Hologres 宽表的 Merge 能力,不仅可以提升流作业的开发效率,还能减少流作业所需要的资源消耗,也能够更容易的维护各个流作业,让作业之间不会相互影响。但需要注意的是,宽表 Merge 仅限于使用在主键关联的场景,并不适用于数仓中常见的星型模型和雪花模型,所以在大部分场景仍需使用 Flink 的双流 Join 来完成宽表建模。
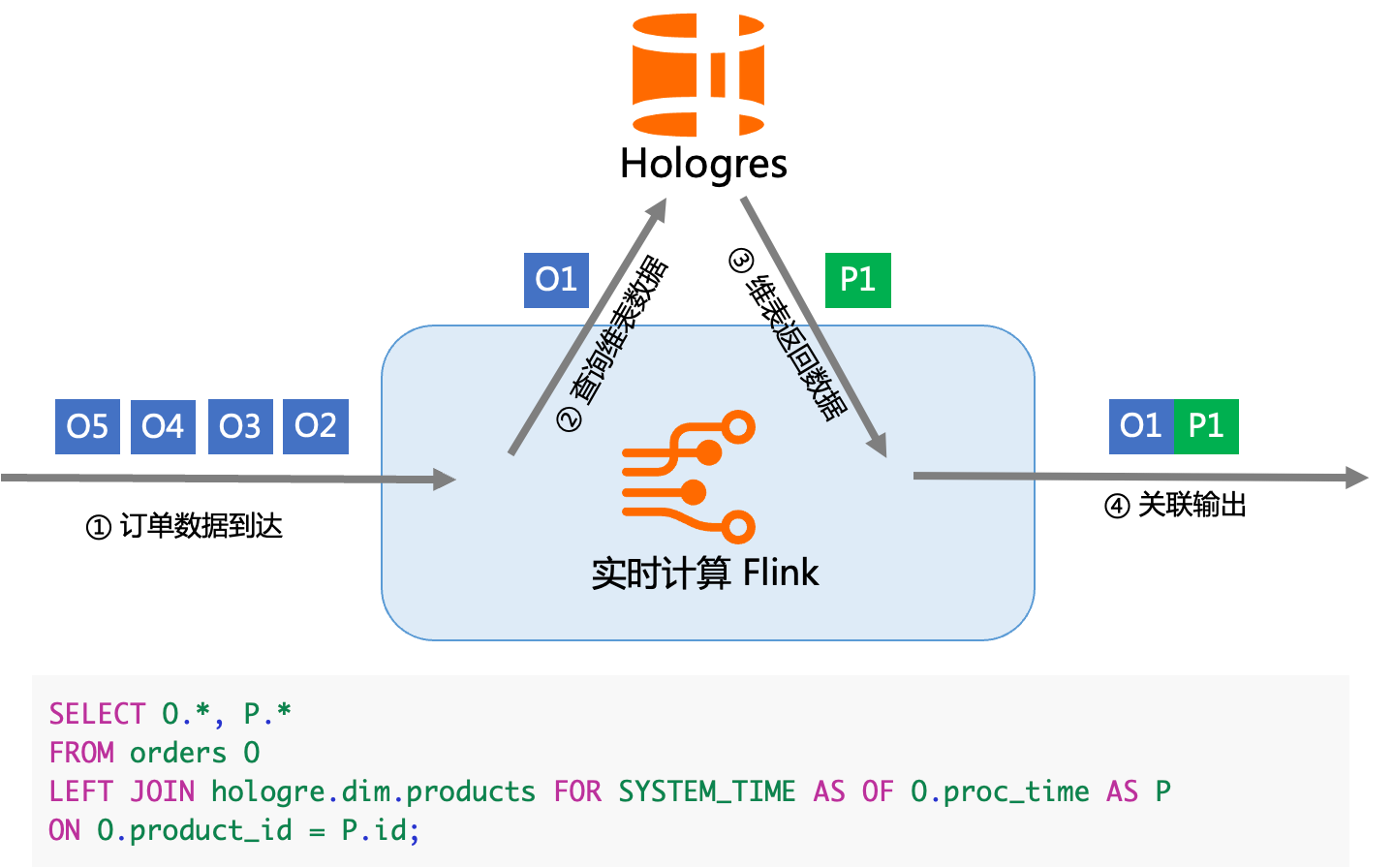
在实时数仓中,在构建 DWD 层的数据过程中,一般都是通过阿里云 Flink 来读取消息队列比如 Datahub 上的 ODS 数据,同时需要关联维表来形成 DWD 层。在阿里云 Flink 的计算过程中,需要高效的读取维表的能力,Hologres 可以通过高 QPS 低延迟的点查能力来满足实现这类场景需求。比如我们需要通过 ODS 的数据去 Join 维表形成 DWD 层的时候,就可以利用 Hologres 提供的点查能力,在该模式中,通常使用行存表的主键点查模式提高维表的 Lookup 效率。具体的实现类似如下:
依托阿里云 Flink+Hologres 解决方案,企业可以快速构建一站式实时数仓,助力实时推荐、实时风控、实时大屏等多种业务场景,实现对数据的快速处理,极速探索查询。目前该方案已在阿里巴巴内部、众多云上企业生产落地,成为实时数仓的最佳解决方案之一。
以某知名全球 TOP20 游戏公司业务为例,其通过阿里云 Flink+Hologres 实时数仓方案,替换开源 Flink+Presto+HBase+ClickHouse 架构,简化数据处理链路、统一数仓架构、统一存储、查询性能提升 100%甚至更多,完美支撑数据分析、广告投放、实时决策等多个场景,助力业务快速增长。
客户原数仓架构使用全套开源组件,架构图如下。其中开源 Flink 做 ETL 处理,处理后写入 ClickHouse、StarRocks 等 OLAP 引擎。
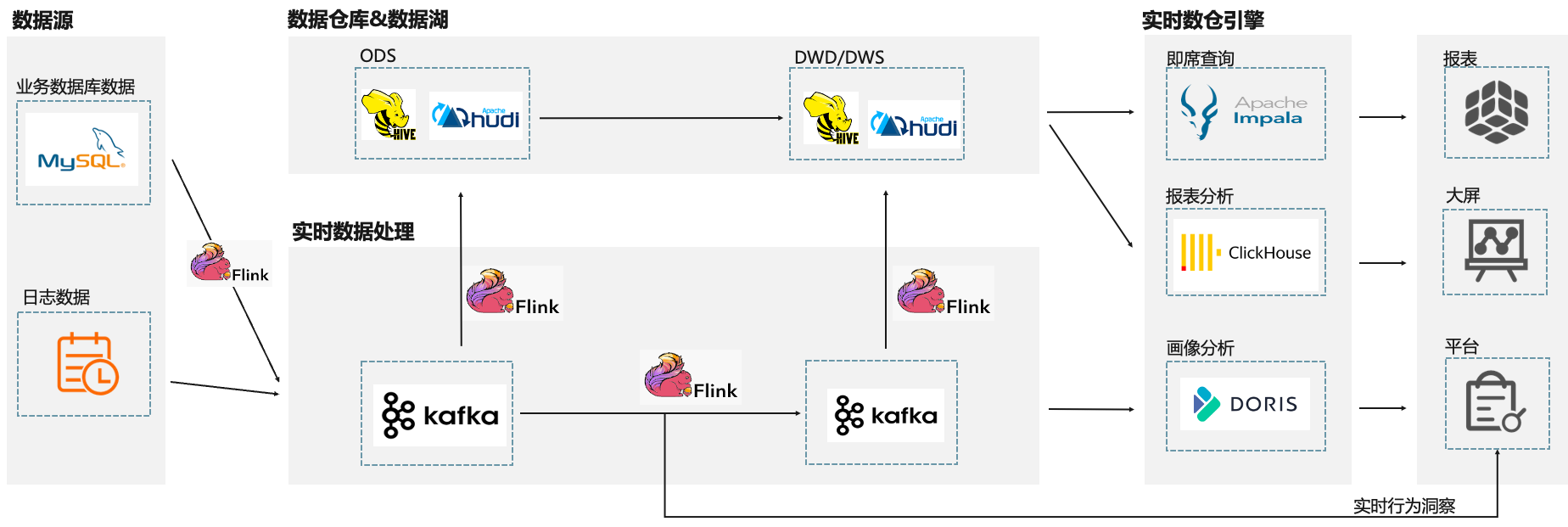
这套架构遇见的主要痛点有:
1、ETL 链路复杂
为了解决数据实时 ETL,客户通过 Flink CDC + Hudi 做流批一体。但由于上游业务数据经常变更表结构,而开源 Flink CDC 缺乏 Schema Evolution 的能力,每次表结构变更都需要任务重新启动,操作非常麻烦,浪费大量开发时间。
Hudi 的查询性能不满足业务需求,还需要再加一个 Presto 做加速查询,造成链路冗余。
2、OLAP 架构冗余,查询慢
客户主要是靠买量发行作为游戏推广的重要手段,为了解决广告归因的实时决策场景对查询加速的需要,于是部署了开源 Presto、ClickHouse、HBase 等多套集群搭建混合 OLAP 平台。带来的问题有:
平台需要维护多套集群,导致运维变得非常复杂。
开发需要在各种 SQL 中切换,为开发团队带来了许多困扰。
由于 ClickHouse 缺乏主键,在归因分析时需要使用 Last Click 模型,带来了大量的额外工作。
同时 OLAP 引擎的查询性能没有办法很好的满足业务需求,没办法根据数据实时决策。
数据需要在多个 OLAP 系统中存储,造成存储冗余,导致成本压力剧增。
基于上面的痛点,客户开始重新做技术选型,并使用阿里云 Flink+Hologres 来替换现有的开源数仓架构。
通过阿里云 Flink+Hologres 替换后的数据链路如下:
数据源数据通过 Flink CDC 能力写入 Kafka 做前置清洗,清洗后通过阿里云 Flink 进行 ETL 处理。
阿里云 Flink 经过 ETL 后的数据实时写入 Hologres,通过 Hologres 替换了 Kafka 作为实时数仓的中间数据层,统一了流批存储。
在 Hologres 中根据 ODS > DWD > DWS 层汇总加工。在 ODS 层,阿里云 Flink 订阅 Hologres Binlog,计算后写入 Hologres DWD 层,DWD 层在 Hologres 中汇总成 DWS 层,最后 DWS 对接上层报表和数据服务等业务。
为了存储的统一,也将原离线 Hive 数据替换成阿里云 MaxCompute,以 MaxCompute 为离线主要链路。因 Hologres 与 MaxCompute 的高效互通能力,Hologres 通过外表离线加速查询 MaxCompute,并将历史数据定期归档至 MaxCompute。
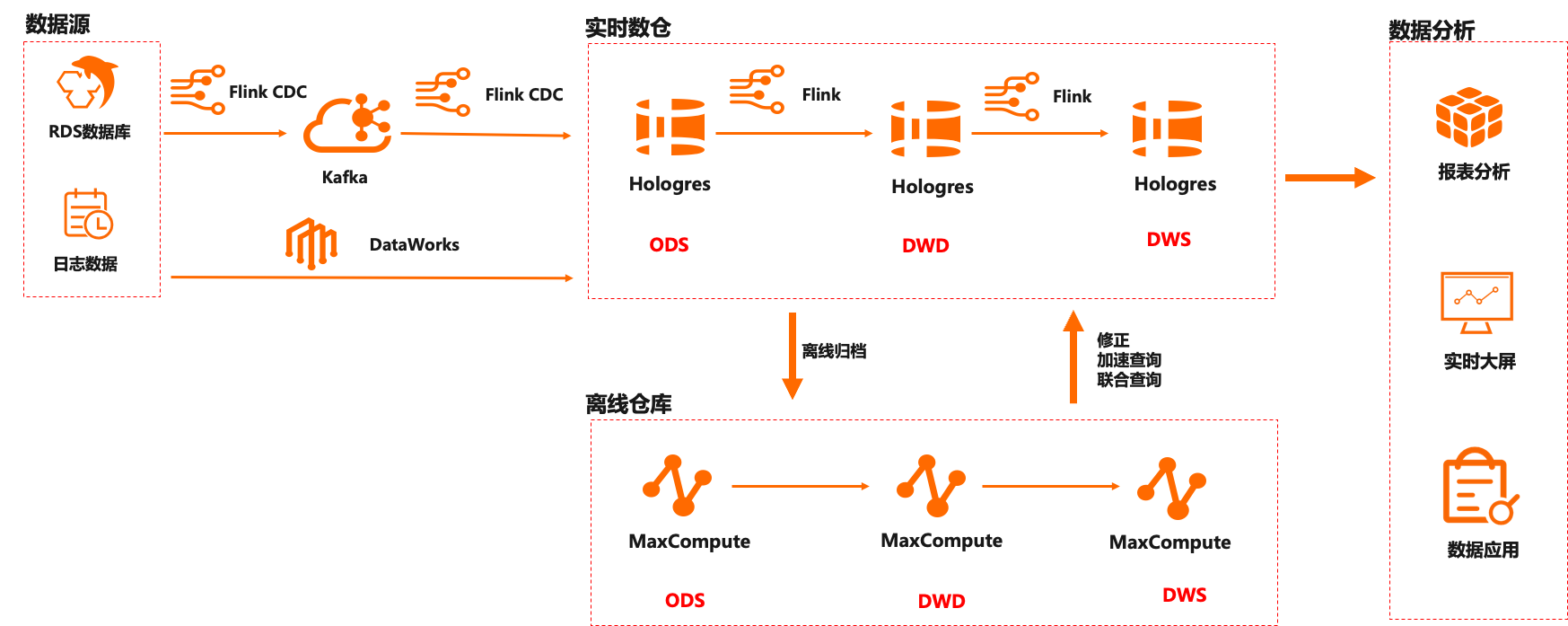
通过架构升级后,客户的显著业务收益如下:
依托阿里云 Flink+Hologres,数据可以实时写入 Hologres,写入即可见,并且 Hologres 有主键,能够支撑高性能的写入更新能力,百万级更新毫秒级延迟。
阿里云 Flink 提供 Schema Evolution 的能力,自动感知上游表结构变更并同步 Hologres,改造后的实时 ETL 链路通过订阅 Hologres Binlog 日志来完成,降低链路维护成本。
通过 Hologres 统一了数据查询出口,经过客户实测,Hologres 可以达到毫秒级延迟,相比开源 ClickHouse 性能提升 100%甚至更多,JOIN 查询性能快 10 倍。
升级后数仓架构变得更加灵活简洁,统一了存储,只需要一套系统就能满足业务需求,降低运维压力和运维成本。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
Ruby中如何“一般地”计算以下格式(有根、无根)的JSON对象的数量?一般来说,我的意思是元素可能不同(例如“标题”被称为其他东西)。没有根:{[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]}根包裹:{"posts":[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]} 最佳答案 首先,withoutroot代码不是有效的json格式。它将没有包
目标我正在尝试计算自给定日期以来周的距离,而无需跳过任何步骤。我更喜欢用普通的Ruby来做,但ActiveSupport无疑是一个可以接受的选择。我的代码我写了以下内容,这似乎可行,但对我来说似乎还有很长的路要走。require'date'DAYS_IN_WEEK=7.0defweeks_sincedate_stringdate=Date.parsedate_stringdays=Date.today-dateweeks=days/DAYS_IN_WEEKweeks.round2endweeks_since'2015-06-15'#=>32.57ActiveSupport的#weeks
参考文章搭建文章gitte源码在线体验可以注册两个号来测试演示图:一.整体介绍 介绍SignalR一种通讯模型Hub(中心模型,或者叫集线器模型),调用这个模型写好的方法,去发送消息。 内容有: ①:Hub模型的方法介绍 ②:服务器端代码介绍 ③:前端vue3安装并调用后端方法 ④:聊天室样例整体流程:1、进入网站->调用连接SignalR的方法2、与好友发送消息->调用SignalR的自定义方法 前端通过,signalR内置方法.invoke() 去请求接口3、监听接受方法(渲染消息)通过new signalR.HubConnectionBuilder().on
技术选型1,前端小程序原生MINA框架cssJavaScriptWxml2,管理后台云开发Cms内容管理系统web网页3,数据后台小程序云开发云函数云开发数据库(基于MongoDB)云存储4,人脸识别算法基于百度智能云实现人脸识别一,用户端效果图预览老规矩我们先来看效果图,如果效果图符合你的需求,就继续往下看,如果不符合你的需求,可以跳过。1-1,登录注册页可以看到登录页有注册入口,注册页如下我们的注册,需要管理员审核,审核通过后才可以正常登录使用小程序1-2,个人中心页登录成功以后,我们会进入个人中心页我们在个人中心页可以注册人脸,因为我们做人脸识别签到,需要先注册人脸才可以进行人脸比对,进
如何计算两个字符串之间的字符交集?例如(假设我们有一个名为String.intersection的方法):"abc".intersection("ab")=2"hello".intersection("hallo")=4好的,男孩女孩们,感谢你们的大量反馈。更多示例:"aaa".intersection("a")=1"foo".intersection("bar")=0"abc".intersection("bc")=2"abc".intersection("ac")=2"abba".intersection("aa")=2一些补充说明:维基百科定义intersection如下:Int