如果是用的公有云托管的 Kubernetes 集群,控制面的组件都交由云厂商托管的,那作为客户的我们就省事了,基本不用操心 APIServer 的运维。个人也推荐使用云厂商这个服务,毕竟 Kubernetes 还是有点复杂的,升级也不好搞,我们自己来维护整个集群,性价比有点低。当然,如果因为各种原因最后我们还是要维护控制面这些组件,那就要好好看看本系列接下来的几篇博客了。
APIServer 在 Kubernetes 架构中非常核心,是所有 API 的入口,APIServer 也暴露了 metrics 数据,我们尝试获取一下:
[root@tt-fc-dev01.nj etcd]# ss -tlpn|grep apiserver
LISTEN 0 128 *:6443 *:* users:(("kube-apiserver",pid=164445,fd=7))
[root@tt-fc-dev01.nj etcd]# curl -s http://localhost:6443/metrics
Client sent an HTTP request to an HTTPS server.
[root@tt-fc-dev01.nj etcd]# curl -s -k https://localhost:6443/metrics
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "forbidden: User \"system:anonymous\" cannot get path \"/metrics\"",
"reason": "Forbidden",
"details": {},
"code": 403
}
解释一下上面的命令和结果。首先我通过 ss 命令查看 apiserver 模块监听在哪些端口,发现这个进程在 6443 端口有监听。然后,使用 curl 命令请求 6443 的 metrics 接口,结果又说这是一个 HTTPS Server,不能用 HTTP 协议请求。好,那我用 HTTPS 协议请求,自签证书,加了 -k 参数,返回 Forbidden,说没权限访问 /metrics 接口。OK,那看来是需要 Token 鉴权,我们创建一下相关的 ServiceAccount。
下面的内容可以保存为 auth-server.yaml。
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: categraf
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/metrics
- nodes/stats
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
- networking.k8s.io
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics", "/metrics/cadvisor"]
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: categraf
namespace: flashcat
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: categraf
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: categraf
subjects:
- kind: ServiceAccount
name: categraf
namespace: flashcat
在上一节《Kubernetes监控手册05-监控Kubelet》中,我们为 daemonset 创建过认证信息,那个认证信息主要是用于调用 kubelet 的接口。而这次我们要调用的是 apiserver 的接口,所以增加了一些权限点,当然,上例 yaml 中给出的权限点有点多,没关系,反正都是只读的,后面再需要其他权限的时候,省的再创建新的 ServiceAccount 了。与上一讲相比,这次 ServiceAccount 名字改成了 categraf,与上一讲用到的 ServiceAccount 区分开。
通过下面的命令创建相关内容,然后查看一下是否创建成功:
[root@tt-fc-dev01.nj yamls]# kubectl apply -f auth-server.yaml -n flashcat
clusterrole.rbac.authorization.k8s.io/categraf unchanged
serviceaccount/categraf unchanged
clusterrolebinding.rbac.authorization.k8s.io/categraf unchanged
[root@tt-fc-dev01.nj yamls]# kubectl get sa categraf -n flashcat
NAME SECRETS AGE
categraf 1 7h13m
[root@tt-fc-dev01.nj yamls]# kubectl get sa categraf -n flashcat -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","kind":"ServiceAccount","metadata":{"annotations":{},"name":"categraf","namespace":"flashcat"}}
creationTimestamp: "2022-11-28T05:00:17Z"
name: categraf
namespace: flashcat
resourceVersion: "127151612"
uid: 8b473b31-ce09-4abe-ae55-ea799160a9d5
secrets:
- name: categraf-token-6whbs
[root@tt-fc-dev01.nj yamls]# kubectl get secret categraf-token-6whbs -n flashcat
NAME TYPE DATA AGE
categraf-token-6whbs kubernetes.io/service-account-token 3 7h15m
上例中,因为我之前创建过了,所以显示的是 unchanged,获取 sa 的时候,可以看到 AGE 已经七个多小时了。通过 -o yaml 可以看到 sa 对应的 secret 的名字,最下面那一行,可以看到 secret 名字是 categraf-token-6whbs。然后我们用这个 secret 中的 token 来调用一下 APIServer 试试:
[root@tt-fc-dev01.nj yamls]# token=`kubectl get secret categraf-token-6whbs -n flashcat -o jsonpath={.data.token} | base64 -d`
[root@tt-fc-dev01.nj yamls]# curl -s -k -H "Authorization: Bearer $token" https://localhost:6443/metrics > metrics
[root@tt-fc-dev01.nj yamls]# head -n 6 metrics
# HELP aggregator_openapi_v2_regeneration_count [ALPHA] Counter of OpenAPI v2 spec regeneration count broken down by causing APIService name and reason.
# TYPE aggregator_openapi_v2_regeneration_count counter
aggregator_openapi_v2_regeneration_count{apiservice="*",reason="startup"} 0
aggregator_openapi_v2_regeneration_count{apiservice="k8s_internal_local_delegation_chain_0000000002",reason="update"} 0
aggregator_openapi_v2_regeneration_count{apiservice="v1beta1.metrics.k8s.io",reason="add"} 0
aggregator_openapi_v2_regeneration_count{apiservice="v1beta1.metrics.k8s.io",reason="update"} 0
OK,这个新的 Token 是可以获取到数据的了,权限认证通过。
既然 Token 已经有了,采集器抓取 APIServer 的数据的时候,只要在 Header 里传入这个 Token 理论上就可以拿到数据了。如果 APIServer 是二进制方式部署,咱们就直接通过 Categraf 的 Prometheus 插件来抓取就可以了。如果 APIServer 是部署在 Kubernetes 的容器里,咱们最好是使用服务发现机制来做。
支持 Kubernetes 服务发现的 agent 有不少,但是要说最原汁原味的还是 Prometheus 自身,Prometheus 新版本(v2.32.0)支持了 agent mode 模式,即把 Prometheus 进程当做采集器 agent,采集了数据之后通过 remote write 方式传给中心(这里使用早就准备好的 Nightingale 作为数据接收服务端)。那这里我就使用 Prometheus 的 agent mode 方式来采集 APIServer。
首先准备一下 Prometheus agent 需要的配置文件,我们做成一个 ConfigMap:
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-agent-conf
labels:
name: prometheus-agent-conf
namespace: flashcat
data:
prometheus.yml: |-
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
remote_write:
- url: 'http://10.206.0.16:19000/prometheus/v1/write'
可以把上面的内容保存为 prometheus-agent-configmap.yaml,然后 kubectl -f prometheus-agent-configmap.yaml 创建一下即可。
有了配置了,下面我们就可以部署 Prometheus 了,要把 Prometheus 进程当做 agent 来用,需要启用这个 feature,通过命令行参数 --enable-feature=agent 即可轻松启用了,我们把 agent mode 模式的 Prometheus 部署成一个 Deployment,单副本。
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-agent
namespace: flashcat
labels:
app: prometheus-agent
spec:
replicas: 1
selector:
matchLabels:
app: prometheus-agent
template:
metadata:
labels:
app: prometheus-agent
spec:
serviceAccountName: categraf
containers:
- name: prometheus
image: prom/prometheus
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--web.enable-lifecycle"
- "--enable-feature=agent"
ports:
- containerPort: 9090
resources:
requests:
cpu: 500m
memory: 500M
limits:
cpu: 1
memory: 1Gi
volumeMounts:
- name: prometheus-config-volume
mountPath: /etc/prometheus/
- name: prometheus-storage-volume
mountPath: /prometheus/
volumes:
- name: prometheus-config-volume
configMap:
defaultMode: 420
name: prometheus-agent-conf
- name: prometheus-storage-volume
emptyDir: {}
要特别注意 serviceAccountName: categraf 这一行内容别忘记了,以上 yaml 内容保存为 prometheus-agent-deployment.yaml,然后 apply 一下:
[work@tt-fc-dev01.nj yamls]$ kubectl apply -f prometheus-agent-deployment.yaml
deployment.apps/prometheus-agent created
可以通过 kubectl logs <podname> -n flashcat 查看刚才创建的 prometheus-agent-xx 那个 Pod 的日志,如果没有报错,理论上就问题不大了。
在即时查询里查一下 apiserver_request_total 这个指标,如果可以查到,就说明数据上报是正常的。孔飞老师之前整理过夜莺的 Kubernetes / Apiserver 监控大盘,可以导入测试,地址在这里。效果如下:
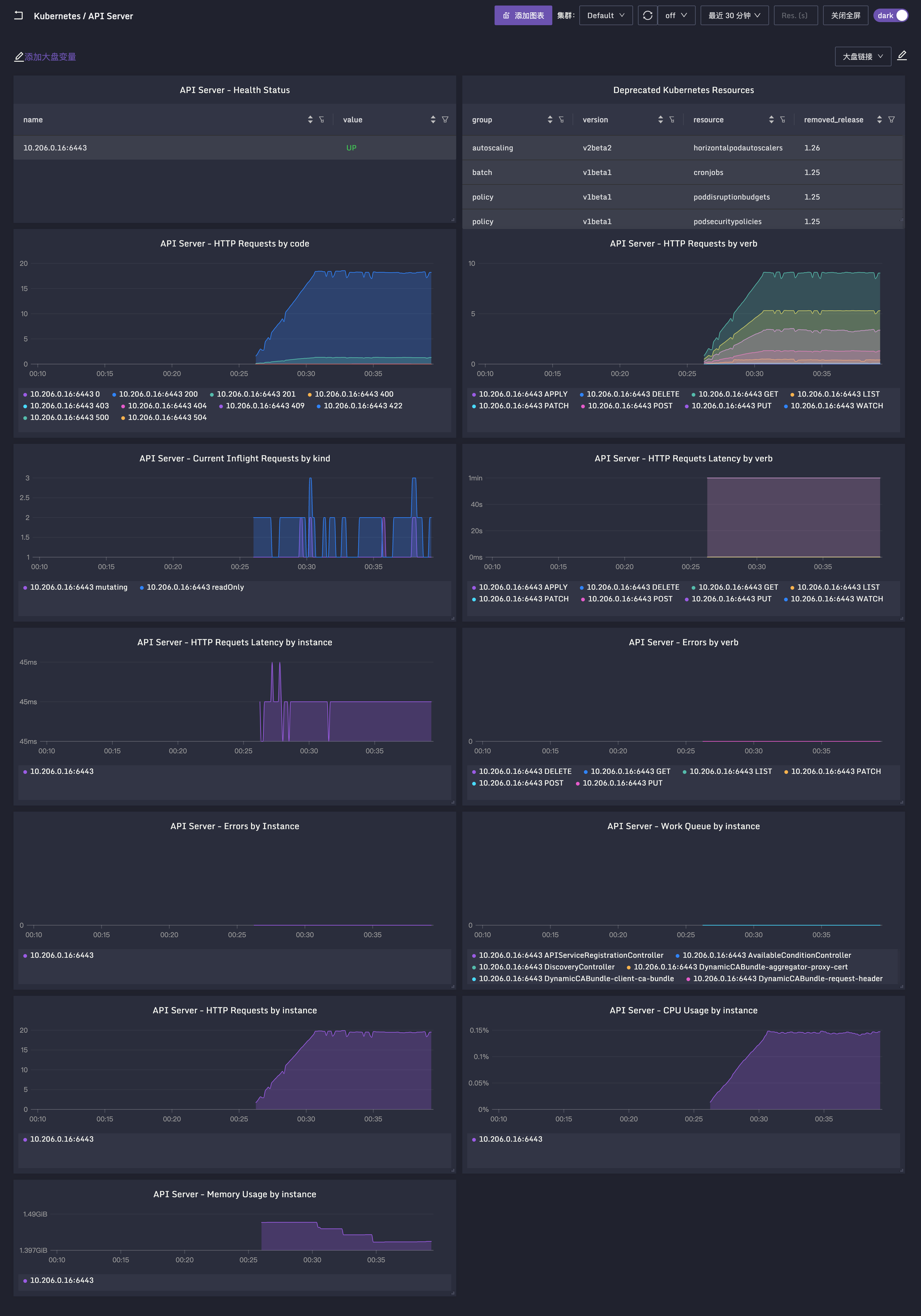
另外,Apiserver 的关键指标的含义,孔飞老师也做了整理,我也给摘过来了:
# HELP apiserver_request_duration_seconds [STABLE] Response latency distribution in seconds for each verb, dry run value, group, version, resource, subresource, scope and component.
# TYPE apiserver_request_duration_seconds histogram
apiserver响应的时间分布,按照url 和 verb 分类
一般按照instance和verb+时间 汇聚
# HELP apiserver_request_total [STABLE] Counter of apiserver requests broken out for each verb, dry run value, group, version, resource, scope, component, and HTTP response code.
# TYPE apiserver_request_total counter
apiserver的请求总数,按照verb、 version、 group、resource、scope、component、 http返回码分类统计
# HELP apiserver_current_inflight_requests [STABLE] Maximal number of currently used inflight request limit of this apiserver per request kind in last second.
# TYPE apiserver_current_inflight_requests gauge
最大并发请求数, 按mutating(非get list watch的请求)和readOnly(get list watch)分别限制
超过max-requests-inflight(默认值400)和max-mutating-requests-inflight(默认200)的请求会被限流
apiserver变更时要注意观察,也是反馈集群容量的一个重要指标
# HELP apiserver_response_sizes [STABLE] Response size distribution in bytes for each group, version, verb, resource, subresource, scope and component.
# TYPE apiserver_response_sizes histogram
apiserver 响应大小,单位byte, 按照verb、 version、 group、resource、scope、component分类统计
# HELP watch_cache_capacity [ALPHA] Total capacity of watch cache broken by resource type.
# TYPE watch_cache_capacity gauge
按照资源类型统计的watch缓存大小
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
每秒钟用户态和系统态cpu消耗时间, 计算apiserver进程的cpu的使用率
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
apiserver的内存使用量(单位:Byte)
# HELP workqueue_adds_total [ALPHA] Total number of adds handled by workqueue
# TYPE workqueue_adds_total counter
apiserver中包含的controller的工作队列,已处理的任务总数
# HELP workqueue_depth [ALPHA] Current depth of workqueue
# TYPE workqueue_depth gauge
apiserver中包含的controller的工作队列深度,表示当前队列中要处理的任务的数量,数值越小越好
例如APIServiceRegistrationController admission_quota_controller
本文作者秦晓辉,Flashcat合伙人,文章内容是Flashcat技术团队共同沉淀的结晶,作者做了编辑整理,我们会持续输出监控、稳定性保障相关的技术文章,文章可转载,转载请注明出处,尊重技术人员的成果。
如果对 Nightingale、Categraf、Prometheus 等技术感兴趣,欢迎加入我们的微信群组,联系我(picobyte)拉入部落,和社区同仁一起探讨监控技术。
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
是否可以在我的服务器上运行任何工具来监控多个Rails应用程序?我需要监控每个应用程序收到的请求数、每个应用程序使用了多少内存、使用了多少CPU以及其他类似的统计信息。我需要查看每个单独的Rails应用程序的统计信息。 最佳答案 我建议你试试NewRelicRPM.免费版:RPMLiteisthemostwidelyusedsolutionforbasicwebapplicationmonitoring.RPMLiteprovidesapplicationmonitoringforunlimitedJava,RubyorJRubya
我遇到了错误“2013-03-06”的未定义方法`strftime':String当尝试使用strftime从字符串2013-03-06正常显示日期(2013年6月3日或类似日期)时。在我的index.html.erb中执行此操作的行看起来像这样我只是在学习Rails,所以我确信这只是一个愚蠢的初学者错误,我们将不胜感激。谢谢 最佳答案 当strftime是时间/日期类的方法时,您的截止日期看起来是一个字符串。你可以试试这个:Date.parse(task.duedate).strftime("%B%e,%Y")
我正在寻找一种方法来监视流上的事件,以便我可以确定是否有任何内容通过流。如果有,我将开始使用rtmpdump进行录制。我想象这是通过运行一个每60秒检查一次流的cron任务来实现的。如果它确定流正在通过,则调用rtmpdump开始记录它。如果没有,则什么都不做,并在60秒后再次检查。由于rtmpdump只是在没有流数据时出现错误,因此尝试使用它来监视流似乎不是一个好主意,但也许我错了。如果我在逐个案例的基础上手动执行此操作会很容易,但我正在尝试自动执行自动录制流的任务(如果它们可用)。有没有人遇到过这样做的方法?也许我可以在命令行(linux)中使用其他一些工具?如果有帮助,我正在使用
Kubernetes(K8s)是一个用于管理容器化应用程序的开源平台,可以帮助开发人员更轻松地部署、管理和扩展应用程序。在Kubernetes中,集群划分是一种重要的概念,可以帮助我们更好地组织和管理集群中的节点和资源。本文将介绍如何使用Kubernetes对集群进行划分,并提供详细的操作示例,希望能够帮助读者更好地了解和使用Kubernetes平台。Node划分Node划分是将集群中的节点按照一定的规则进行划分。在Kubernetes中,可以使用NodeSelector和Affinity机制来实现Node划分。NodeSelectorNodeSelector是一种将Pod调度到符合特定节点标
文章目录Kubernetes(k8s)工作负载一、Workloads二、Pod三、Deployment四、RC、RS、DaemonSet、StatefulSet五、Job、CronJob1、Job2、CronJob六、GCKubernetes(k8s)工作负载一、Workloads什么是工作负载(Workloads)工作负载是运行在Kubernetes上的一个应用程序。一个应用很复杂,可能由单个组件或者多个组件共同完成。无论怎样我们可以用一组Pod来表示一个应用,也就是一个工作负载Pod又是一组容器(Containers)所以关系又像是这样工作负载(Workloads)控制一组PodPod控制
绝对详细的RabbitMQ实践操作手册,看完本系列就够了。一、什么是MQ?1、MQ的概念2、理解消息队列二、MQ的优势和劣势1、优势和作用2、劣势三、MQ的应用场景四、AMQP五、工作原理一、什么是MQ?1、MQ的概念MQ全称MessageQueue(消息队列),是在消息的传输过程中保存消息的容器。多用于系统之间的异步通信。下面用图来理解异步通信,并阐明与同步通信的区别。同步通信:甲乙两人面对面交流,你一句我一句必须同步进行,两人除此之外不做任何事情异步通信:异步通信相当于通过第三方转述对话,可能有消息的延迟,但不需要二人时刻保持联系,消息传给第三方后,两人可以做其他自己想做的事情,当需要获取
每5分钟(例如)ping20个网站的列表以了解该网站是否响应HTTP202的最佳方法是什么?最简单的想法是将20个URLS保存在数据库中,然后运行数据库并对每个URL执行ping操作。但是,当一个人不回答时会发生什么?之后的人会怎样?此外,是否有更好但更简单的解决方案?恐怕该列表会增长到20000个网站,然后没有足够的时间在我需要ping的5分钟内全部ping通它们。基本上,我是在描述PingDom、UptimeRobot等的工作原理。我正在使用node.js和RubyonRails构建这个系统。我也倾向于使用MongoDB来保存所有ping和监控结果的历史记录。建议?非常感谢!
我们有一个带有广泛管理部分的应用程序。我们对功能有点满意(就像您一样),并且正在寻找一些快速简便的方法来监控“谁使用什么”。理想情况下,一个简单的gem将允许我们在每个用户的基础上跟踪Controller/操作,以构建使用的功能和未使用的功能的图片。任何你会推荐的..谢谢主场 最佳答案 我不知道有什么流行的gem或插件可以解决这个问题;过去,我在ApplicationController中将这种审计实现为before_filter:从内存中:classApplicationControllercurrent_user,:contro
我有一堆长时间运行的Ruby脚本,我想确保每30秒左右运行一次。我通常通过简单地启动命令rubyscript-name.rb我如何配置monit来管理这些脚本?更新:我试着关注thismethodtocreateawrapperscript然后它会启动ruby进程,但它似乎没有创建.pid文件并且键入“./wrapper-scriptstop”什么也没做:/我应该在ruby中编写pid还是使用包装脚本来创建monit所需的pid? 最佳答案 MonitWiki有很多配置示例:http://mmonit.com/wiki/Mo