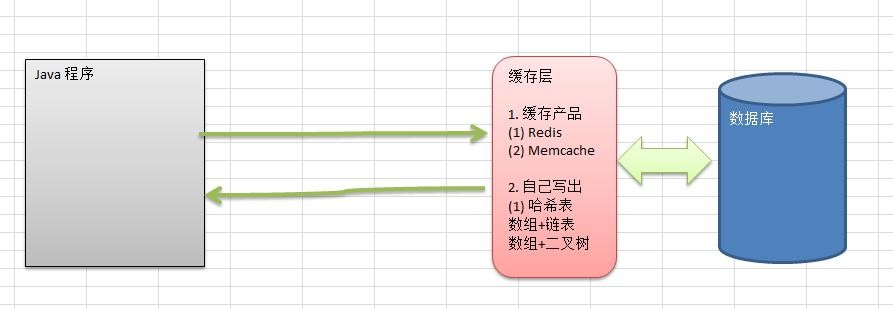
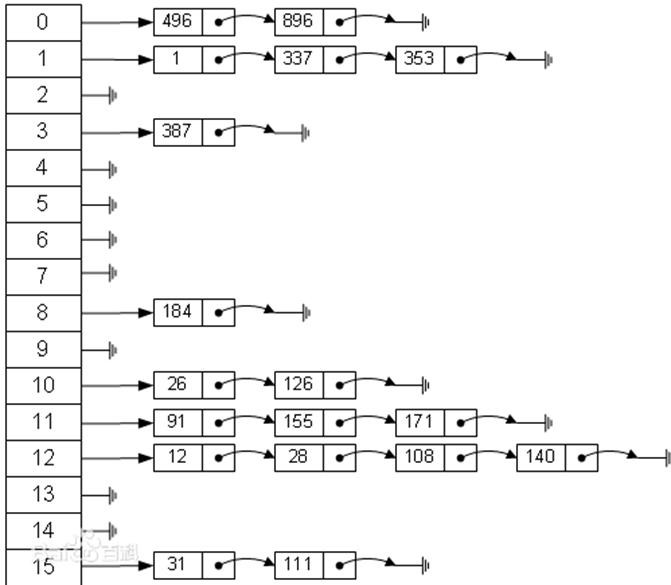
 散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
有一个公司,当有新的员工来报道时,要求将该员工的信息加入(id,性别,年龄,名字,住址..),当输入该员工的 id 时, 要求查找到该员工的 所有信息.
要求:
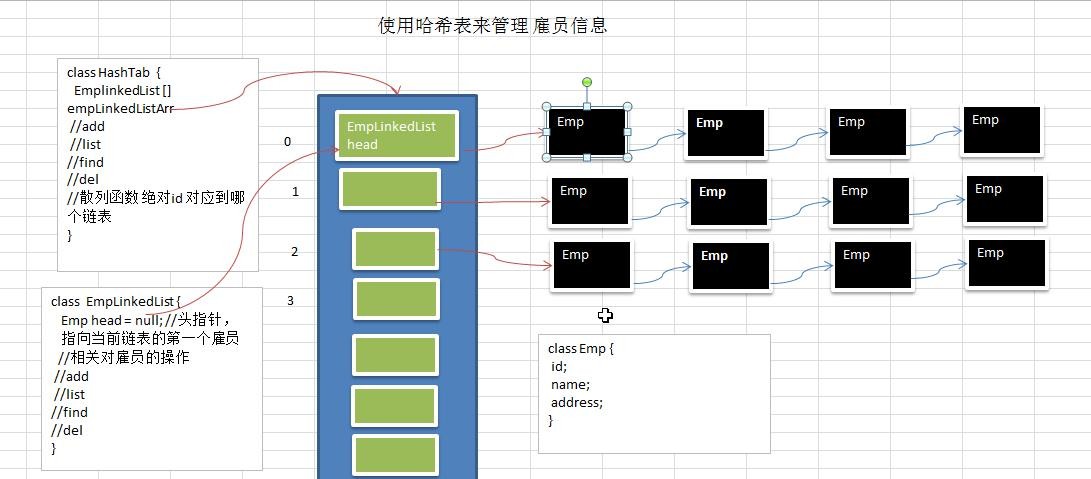 思路分析并画出示意图
思路分析并画出示意图
package com.xuge.hashTab;
import java.util.Scanner;
/**
* author: yjx
* Date :2022/5/3115:16
**/
public class HashTabDemo {
public static void main(String[] args) {
//1.创建哈希表
HashTab hashTab = new HashTab(7);
//2.写一个简单的菜单
String key="";
Scanner scanner = new Scanner(System.in);
while(true){
System.out.println("1:添加雇员");
System.out.println("2:显示雇员");
System.out.println("3:查找雇员");
System.out.println("4:退出系统");
key=scanner.next();
switch(key){
case "1":
System.out.println("请输入id:");
int id=scanner.nextInt();
System.out.println("请输入姓名:");
String name=scanner.next();
//创建
Emp emp=new Emp(id, name);
hashTab.add(emp);
break;
case"2":
hashTab.list();
break;
case"3":
System.out.println("请输入雇员号:");
id =scanner.nextInt();
hashTab.findById(id);
break;
case "4":
System.exit(0);
}
}
}
}
//hashTab,管理多条链表
class HashTab {
private int size;
private EmpLinkedList[] listArr;
//构造器
public HashTab(int size) {
this.size = size;
this.listArr = new EmpLinkedList[size];
//不要忘了,初始化,每条链表
for (int i = 0; i < size; i++) {
listArr[i]=new EmpLinkedList();
}
}
//添加雇员
public void add(Emp emp) {
//根据员工的id,确定该员工应该加入那条链表编号
int no = hashFun(emp.id);
//将emp加入到对饮链表
listArr[no].add(emp);
}
//遍历所有链表==hashTab
public void list() {
for (int i = 0; i < size; i++) {
//遍历每个链表里的雇员信息
listArr[i].list(i);
}
}
//编写一个散列函数
public int hashFun(int id) {
return id % size;
}
public void findById(int id){
int no = hashFun(id);
Emp emp = listArr[no].search(id);
if(emp!=null){
System.out.printf("编号为"+(no+1)+"=>id=%d name=%s \t", emp.id, emp.name);
}else{
System.out.println("在hashTab没有找到雇员:id"+id);
}
}
}
class EmpLinkedList {
//头指针,指向第一个节点(第一个雇员)
private Emp head;//默认为null
//1.添加雇员到链表
//添加雇员时,id时自增的,总是在链表最后
public void add(Emp emp) {
//添加第一个雇员
if (head == null) {
head = emp;
return;
}
//如果不是第一个雇员
Emp curEmp = head;
while (true) {
if (curEmp.next == null) {//说明到了链表最后
break;
}
curEmp = curEmp.next;
}
//退出循环时,将emp挂在最后
curEmp.next = emp;
}
//2.遍历链表
public void list(int no) {
if (head == null) {
System.out.println("编号为:"+(no+1)+"当前链表为空..");
return;
}
Emp curEmp = head;
while (true) {
System.out.printf("编号为"+(no+1)+"=>id=%d name=%s \t", curEmp.id, curEmp.name);
if (curEmp.next == null) {//说明遍历到了链表最后
break;
}
//后移
curEmp = curEmp.next;
}
System.out.println();
}
//根据id查找雇员
public Emp search(int id){
//判断链表是否为空
if(head==null){
System.out.println("链表为空..");
return null;
}
Emp curTmp=head;
while(true){
if(curTmp.id==id){
break;//curEmp指向雇员
}
if(curTmp.next==null){//说明当前链表没有
curTmp=null;
break;
}
curTmp=curTmp.next;
}
return curTmp;
}
}
class Emp {
public int id;
public String name;
public Emp next;
public Emp(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "Emp{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
假设我有一个在Ruby中看起来像这样的哈希:{:ie0=>"Hi",:ex0=>"Hey",:eg0=>"Howdy",:ie1=>"Hello",:ex1=>"Greetings",:eg1=>"Goodday"}有什么好的方法可以将它变成如下内容:{"0"=>{"ie"=>"Hi","ex"=>"Hey","eg"=>"Howdy"},"1"=>{"ie"=>"Hello","ex"=>"Greetings","eg"=>"Goodday"}} 最佳答案 您要求一个好的方法来做到这一点,所以答案是:一种您或同事可以在六个月后理解
我在搜索我的值是方法的散列时遇到问题。我只是不想运行plan_type与键匹配的方法。defmethod(plan_type,plan,user){foo:plan_is_foo(plan,user),bar:plan_is_bar(plan,user),waa:plan_is_waa(plan,user),har:plan_is_har(user)}[plan_type]end目前如果我传入“bar”作为plan_type,所有方法都会运行,我怎么能只运行plan_is_bar方法呢? 最佳答案 这个变体怎么样?defmethod
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
有什么区别:@attr[:field]=new_value和@attr.merge(:field=>new_value) 最佳答案 如果您使用的是merge!而不是merge,则没有区别。唯一的区别是您可以在合并参数中使用多个字段(意思是:另一个散列)。例子:h1={"a"=>100,"b"=>200}h2={"b"=>254,"c"=>300}h3=h1.merge(h2)putsh1#=>{"a"=>100,"b"=>200}putsh3#=>{"a"=>100,"b"=>254,"c"=>300}h1.merge!(h2)pu
因此,对于普通哈希,您可以使用它来获取key:hash.keys如何获取如下所示的多维哈希的第二维键:{""=>{"first_name"=>"test","last_name"=>"test_l","username"=>"test_user","title"=>"SalesManager","office"=>"test","email"=>"test@test.com"}}每个项目都是唯一的。所以我想从上面得到的键是:first_name,last_name,username,title,officeandemail 最佳答案
我正在尝试循环哈希数组。当我到达获取枚举器开始循环的位置时,出现以下错误:undefinedmethod`[]'fornil:NilClass我的代码如下所示:defextraireAttributs(attributsParam)classeTrouvee=falsescanTrouve=falseownerOSTrouve=falseownerAppTrouve=falseresultat=Hash.new(0)attributs=Array(attributsParam)attributs.eachdo|attribut|#CRASHESHERE!!!typeAttribut=a