记录几篇Transformer的超分辨率重建论文。
本文引用已经有200多了。 原文链接
文章做的是RefSR工作,主要观点是将Transformer作为一个attention,这样可以更好地将参考图像(Ref)的纹理信息转移到高质图像(HR)中。做法还是比较有意思的,如下图所示,将上采样的LR图像、依次向下/上采样的Ref图像、原始Ref图像中提取的纹理特征分别作为Q、K、V。纹理Transformer包含了4个结构:1)DNN实现的可学习的纹理提取器(learnable texture extractor)2)相关性嵌入模块( relevance embedding)3)用于纹理转换的硬注意力模块(hard-attention)4)用于纹理合成的软注意力模块(soft-attention)。此外整个纹理Transformer模块可以跨尺度的方式进一步堆叠,这使得能够从不同尺度(例如,从1x倍到4x倍放大率)恢复纹理

鉴于该论文蛮多讲解的,我简单复述一下,最后会贴其他的论文讲解。
1.2.1网络的整体架构
如下图所示,将多个纹理Transformer(即上图)堆叠、上采下采融合来实现超分。
 其中RBS为多个残差Block,CSFI为跨尺度特征集成模块(ross-scale feature integration )
其中RBS为多个残差Block,CSFI为跨尺度特征集成模块(ross-scale feature integration )
1.2.2纹理Transformer
即图1,介绍一下他的四个组件。
1)DNN实现的可学习的纹理提取器。就是将图像送入DNN,然后DNN可以训练
2)相关性嵌入模块。使用归一化内积计算Q、K之间的相关性。获得矩阵
r
i
,
j
r_{i,j}
ri,j,i,j分别为Q,K的patch数目。
3)硬注意力。通过
h
i
=
a
r
g
m
a
x
(
r
i
,
j
)
h_{i}=argmax(r_{i,j})
hi=argmax(ri,j)获得对每个LR块,最相似的Ref块的索引。然后从V中获得该特征块组成T。举个例子,比如查询第i=3 LR图像块时,发现在K中,第j=7个图像块跟它最相似,那
h
3
=
7
h_3=7
h3=7,在构建T时,T的第3个图像块就由V的第7个图像块构成。
4)软注意力。获得软注意力图
s
i
=
a
r
g
m
a
x
(
r
i
,
j
)
s_{i}=argmax(r_{i,j})
si=argmax(ri,j),然后利用下式获得输出。
再分析一下这个公式,当S大的时候,说明当前块和T的相关性大,所以用更多的T的特征,如果S小,则使用更少的参考帧特征。
L1 loss + GAN loss + Percepture Loss
其他参考讲解
1)https://cloud.tencent.com/developer/article/1646490
2)https://zhuanlan.zhihu.com/p/320236856
该文准确来说实现包括SR、denoise、JPEG compression artifact reduction等三项low level image Restoration任务。transformer在high level中效果不错,但没有使用到low level中。因此作者用Swin Transformer实现可一个baseline。
虽说很多大佬,但其实没啥要讲的,网络结构看图就好,还是常见的主体结构学习残差,然后与LR图像相加后上采。
 1)Shallow Feature Extraction 为一层3x3卷积。
1)Shallow Feature Extraction 为一层3x3卷积。
2)HQ Image Reconstruction在SR任务中采用sub-pixel Conv,就是unpixelShuffle。denoise和JPEG去伪影用一层卷积。
3)对STL,就是Transformer的Encoder结构。将输入划分为
M
∗
M
M*M
M∗M个块X,然后每个X映射为QKV,通过多头attention后将输出concat。MLP通过两层FC实现。作者还进行了划窗来避免图像块之间的信息不融合问题。步长为
M
/
2
M/2
M/2
简单的仿真图像SR只使用L1 loss
真实图像SR使用L1 + GAN loss
denoise和JPEG去伪影 使用Cb loss
论文 代码
transformer用于VSR,被引22。论文还有很多公式,代码也很标准,都可以互相参考着看看。
作者觉得transformer本来就是用于处理序列数据的,那VSR正好是视频帧的序列数据。但是传统Transformer包含FC的自注意力层和基于token的前向层(Feed Forward,FF)。这导致以下两个问题:
1)全连接的自注意层由于依赖FC来计算注意图而忽略了对局部信息的利用。
这个是Transformer用于low level经常会谈到的问题,意思是说Tranformer是全局attention的,但是low level任务一般需要局部attention。
2)由于词前馈层独立的处理每个输入,导致其缺乏特征对齐的能力。
这个是说,vsr一般需要帧间特征的对齐,但是transformer的FF层只处理一个token,因此无法做到对齐。
针对以上两个问题,作者分别提出了时空自注意力层(spatial-temporal convolutional self-attention)和基于双向光流的前馈层(bidirectional optical flow-based feed-forward)
整体架构如下:
 1)特征提取器,由一堆ResBlock构成。
1)特征提取器,由一堆ResBlock构成。
2)重建模块,文中没说,代码将残差通过两次unpixelshuffle上采4x,然后与双线性插值后的原图相加得到输出结果。
3)位置编码。空间和时序的3D信息
3.2.1 VSRT
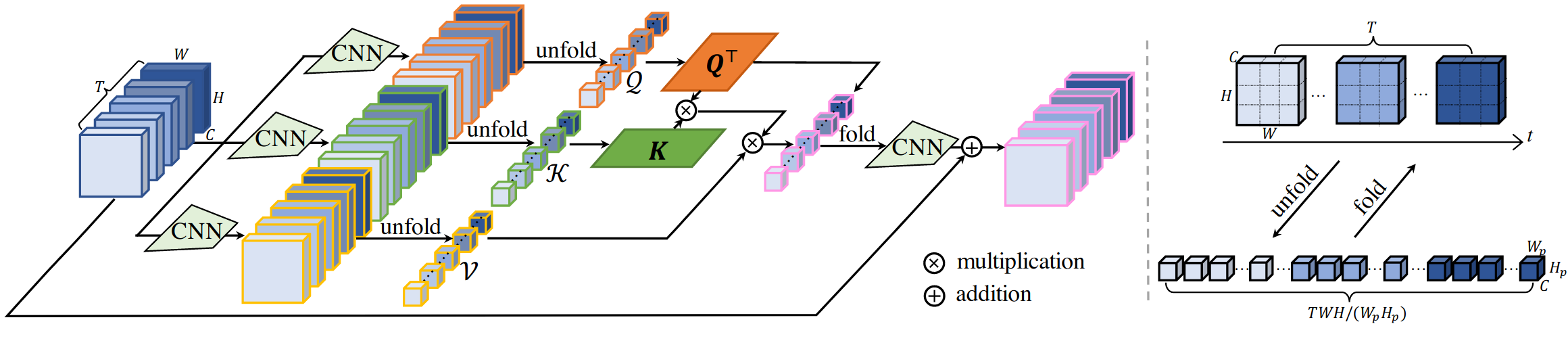
1)时空自注意力层。通过CNN提取特征,然后通过unfold和reshape操作获得 Q T Q^T QT和 K K K,将这两个向量计算attention矩阵。但有个问题是,我感觉 Q T Q^T QT连接到紫色输出的线是错的,因为公式和代码都没有这个相乘。
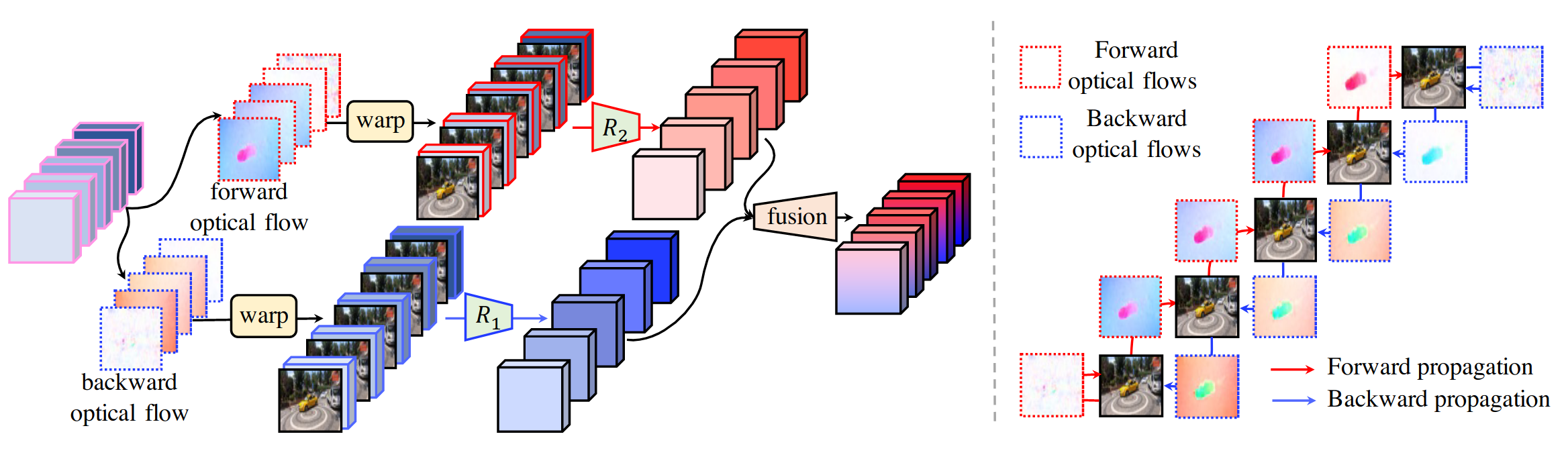
2)基于双向光流的前馈层
即通过前向和后向光流,然后融合输出。
其他参考讲解
论文挂在arxiv上,有7个索引
其实结构连得超级复杂(摘要里竟然还吐槽其他论文堆积结构参数提升性能 ),有一点是提出了Efficient Multi-Head Attention (EMHA)实现Transformer的轻量化,这点可以稍微讲讲。
 主要是在获得QKV之后,将QKV特征分为s组,每组分别进行attention获得输出O,然后将输出Concat,这样可以将大矩阵相乘拆分为多个小矩阵相乘。这也是Transformer常见的减少参数操作。
主要是在获得QKV之后,将QKV特征分为s组,每组分别进行attention获得输出O,然后将输出Concat,这样可以将大矩阵相乘拆分为多个小矩阵相乘。这也是Transformer常见的减少参数操作。
此外作者还用了一个High-frequencyFiltering Module (HFM)提取高频信息,结构如下,仅供参考。
 其他内容可以看讲解
其他内容可以看讲解
Introducing Turing Image Super Resolution: AI powered image enhancements for Microsoft Edge and Bing Maps
这篇不算论文,是微软介绍自家用于Microsoft Edge和Bing Maps上ISR的技术博客。但是效果非常Amazing啊,但缺点是有些地方没有仔细介绍。
1)人类视觉为基准(Human eyes as the north star)
广泛使用的指标如PSNR,SSIM并不总是和人眼视觉的直观感受匹配的,同时也需要GT图。我们构建了一个并行评估工具匹配人眼判断,并将这个工具作为north star metric来引导模型训练。(可是作者没介绍这个工具是啥55555)
2)噪声建模(Noise modeling)
开始作者也是将HR图像降质然后构建HR-LR图相对训练。但这样有些case效果好,但是对真实的LR图像不鲁棒。因此随机对输入图像用blurring, compression 和 gaussian noise进行破坏可以恢复细节。
3)Perceptual and GAN loss
仅pixel loss不够,要引入感知和GAN loss,并用权重结合。
4)Transformers for vision
CNN和Transformer各有优缺点,因此未利用他们各自优点,将网络分为Enhance和Zoom,前者使用Transformer,后者使用CNN。(其实这段也没详细介绍各自优缺点是什么。整体四准则很对我胃口啊,果然英雄所见略同hhhh)
在处理高度压缩和从远程卫星拍摄的航拍照片等very noise图像时,Transformer清理噪声做的很好。如人脸的噪声和处理包含很多纹理的森林的特征就很不同。这是因为大数据集和Transformer卓越的远程记忆能力。我们先使用了一个稀疏Transformer,将其放大以支持非常大的序列长度来“Enhance”图像,产生干净的,crisper(脆?)和更具吸引力,尺寸相同的图像。有些场景不需要放大图像,那到这里就可以停止了。
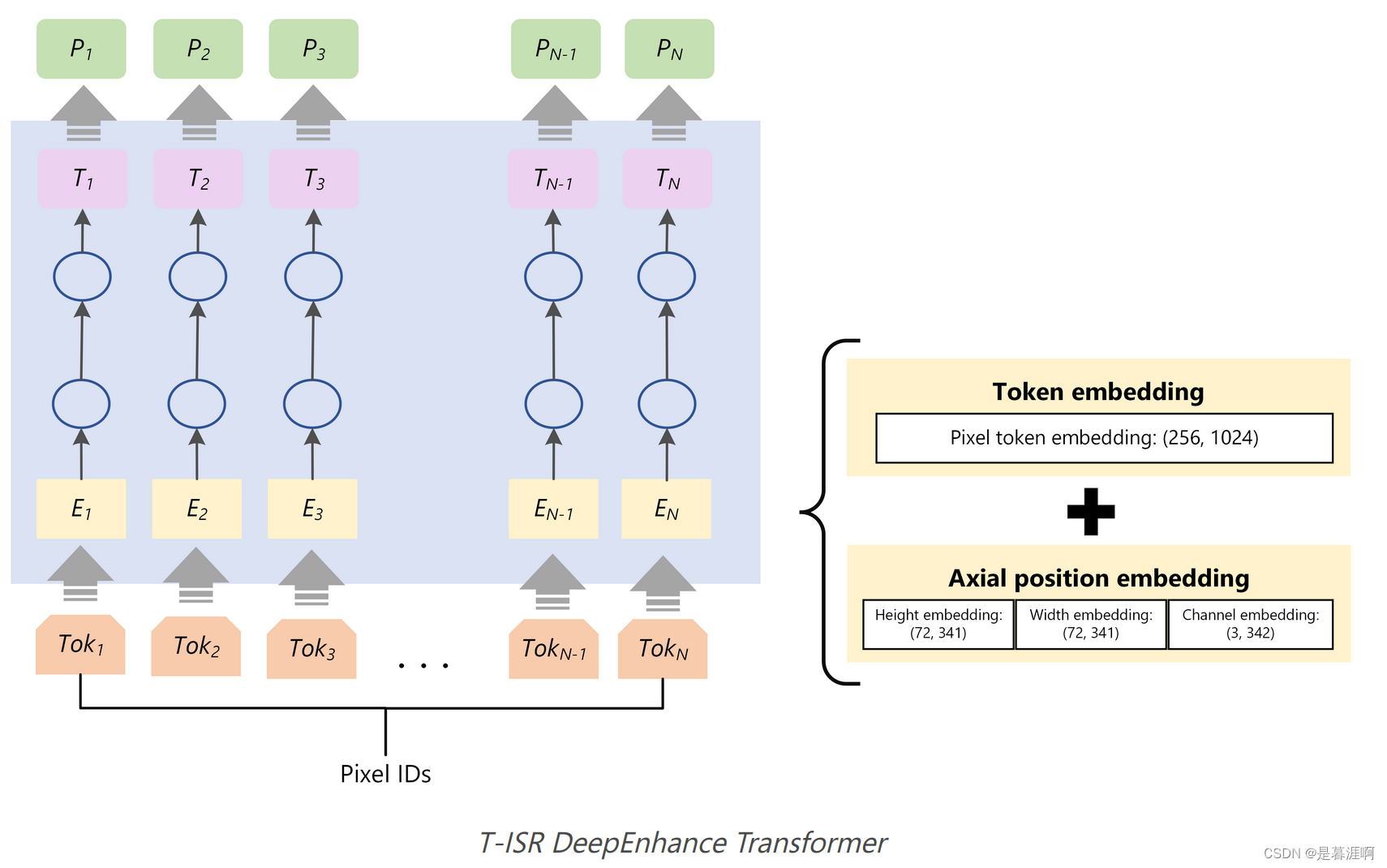 非常难受的是这个结构作者没有详细介绍。
非常难受的是这个结构作者没有详细介绍。
作者认为双线性和双立方插值都会导致图像信息丢失,因此采用200层的CNN恢复pixel细节
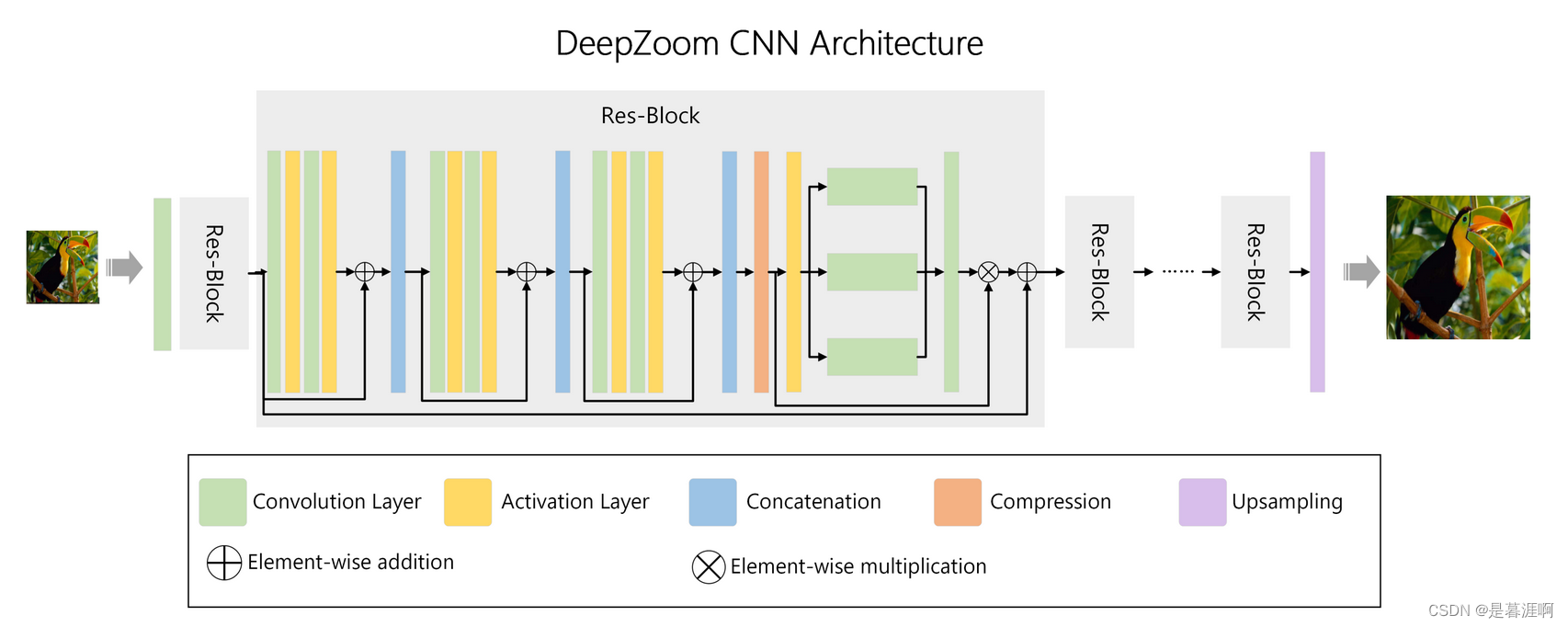
T-ISR在几个不同任务的海量多样的数据上进行训练。所以相同的模型可以应用到Bing Maps, Microsoft Edge和其他可能的场景。域的多样性提升了网络的性能。如为处理卫星图中森林做的训练recipe同样提升了自然图像(如人,动物,建筑)的效果。
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
📢博客主页:https://blog.csdn.net/weixin_43197380📢欢迎点赞👍收藏⭐留言📝如有错误敬请指正!📢本文由Loewen丶原创,首发于CSDN,转载注明出处🙉📢现在的付出,都会是一种沉淀,只为让你成为更好的人✨文章预览:一.分辨率(Resolution)1、工业相机的分辨率是如何定义的?2、工业相机的分辨率是如何选择的?二.精度(Accuracy)1、像素精度(PixelAccuracy)2、定位精度和重复定位精度(RepeatPrecision)三.公差(Tolerance)四.课后作业(Post-ClassExercises)视觉行业的初学者,甚至是做了1~2年
我正在尝试构建一个脚本来浏览我的原始高分辨率照片,并替换我在拥有专业帐户之前上传到Flickr的低分辨率旧照片。对于他们中的许多人,我可以只使用Exif信息(例如拍摄日期)来确定匹配。但有些真的很旧,要么原始文件没有Exif信息,要么被我当时使用的任何愚蠢的大小调整软件破坏了。因此,由于无法依赖元数据,我不得不求助于内容本身。问题是原件的分辨率与Flickr上的分辨率不同(这就是这项工作的重点)。那么有没有一种方法可以让我将它们与某种模糊相似性度量进行比较,从而允许我设置是否需要人工输入的阈值?我想知道一张图片是另一张图片的调整大小版本比一般相似性产生更好的结果。任何语言的解决方案都可
这篇文章网络结构ESRT(EfficientSuper-ResolutionTransformer)还是蛮复杂的,是一个CNN和Transformer结合的结构。文章提出了一个高效SRTransformer结构,是一个轻量级的Transformer。作者考虑到图像超分中一张图像内相似的细节部分可以作为参考补充,(类似于基于参考图像Ref的超分),于是引入了Transformer,可以在图像中建模一种长期依赖关系。而ViT这些方法计算量太大,太占内存,于是提出了这个轻量版的Transformer结构(ET)ET只使用了transformer中的encoder,并且作者还使用了featurespi
我在多个位置安装了多个gem。生成/重新生成的困难/简单方法是什么:所有这些已安装的gem的rdoc,一次全部?所有这些已安装的gem的yardoc,一次全部? 最佳答案 你试过其中之一吗?gemrdoc--allgemrdoc--all--overwrite 关于ruby-如何为所有已安装的gem重建rdoc?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/3152857/
用vit的时候读了一下transformer的思想,前几天面试结束之后发现对QKV又有点忘记了,写一篇文章来记录一下参考链接:哔哩哔哩:在线激情讲解transformer&Attention注意力机制(上)在线激情讲解transformer&Attention注意力机制(上)_哔哩哔哩_bilibiliAttentionisallyouneed介绍更具体的介绍可以去阅读论文在Attentionisallyouneed这篇文章中提出了著名的Transformer模型Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transform
我有一个类似2012-01-01T01:02:03.456的字符串,我使用ActiveRecord将其存储在Postgres数据库TIMESTAMP中。不幸的是,Ruby似乎切断了毫秒数:ruby-1.9.3-rc1:078>'2012-12-31T01:01:01.232323+3'.to_datetime=>Mon,31Dec201201:01:01+0300Postgrs支持微秒分辨率。如何相应地保存我的时间戳?我至少需要毫秒分辨率。(PS是的,我可以破解postgres中的毫秒整数列;这违背了ActiveRecord的全部目的。)更新:非常有帮助的回复表明Ruby的DateTi
我正在创建一个基于Fabric.js的图像编辑器,但我在最终图像分辨率方面遇到了问题。我需要生成高分辨率的图像,但我的编辑器的尺寸在低分辨率下以像素为单位。例如:Canvas有800像素x600像素,我需要一张100厘米x400厘米的最终图像,换句话说,实际尺寸。 最佳答案 让我根据我的经验在这里提出一些想法-如果最终分辨率很大,但不是特别大,您可以在生成图像数据(例如toDataURL)之前将Canvas缩放到它的大小如果最终分辨率特别大,建议直接用PHP处理对于第一个-varoriginWidth=canvas.getWidth
我需要获取浏览器的客户端统计信息(不是完整的长描述而是简称,通常是firefox、ie6、ie7、ie8、safari、chrome、opera和mozilla)。客户端分辨率和操作系统即。WindowsVista、Ubuntu....谢谢 最佳答案 您可以使用Request.Browser.Browser获取浏览器名称。Request.Browser类中还有更多可能感兴趣的内容:varbrowserName=Request.Browser.Browser;//WouldreturnIE,etcvarbrowserType=Requ
这听起来好得令人难以置信,所以如果是这样请告诉我。如果我只有一个单一版本的移动网站(没有变体不同的设备,所有手机只有一个网站),它的可靠性如何通过屏幕分辨率检测移动设备?如果屏幕分辨率小于400像素,则只需提供移动版本。注意:我的问题假定启用了javascript。另外,我知道有用户代理检测,但我不想使用它。 最佳答案 Javascript移动设备屏幕高度检测根本不可靠。问题是不同的浏览器使用不同数量的“chrome”,不同的操作系统版本对系统栏使用不同的高度。所有检测机制报告的高度都不可靠(screen.height、window