来源丨网络
作者丨Alan D. Thompson
半个月以来,ChatGPT这把火越烧越旺。国内很多大厂相继声称要做中文版ChatGPT,还公布了上线时间表,不少科技圈已功成名就的大佬也按捺不住,携巨资下场,要创建“中国版OpenAI“。
不过,看看过去半个月在群众眼里稍显窘迫的Meta的Galactica,以及Google紧急发布的Bard,就知道在短期内打造一个比肩甚至超越ChatGPT效果的模型没那么简单。
让很多人不免感到诧异的是,ChatGPT的核心算法Transformer最初是由Google提出的,并且在大模型技术上的积累可以说不弱于OpenAI,当然他们也不缺算力和数据,但为什么依然会被ChatGPT打的措手不及?
Meta首席AI科学家Yann LeCun最近抨击ChatGPT的名言实际上解释了背后的门道。他说,ChatGPT“只是巧妙的组合而已”,这句话恰恰道出了一种无形的技术壁垒。
简单来说,即使其他团队的算法、数据、算力都准备的与OpenAI相差无几,但就是没想到以一种精巧的方式把这些元素组装起来,没有OpenAI,全行业不知道还需要去趟多少坑。
即使OpenAI给出了算法上的一条路径,后来者想复现ChatGPT,算力、工程、数据,每一个要素都需要非常深的积累。七龙珠之中,算力是自由流通的商品,花钱可以买到,工程上有OneFlow这样的开源项目和团队,因此,对互联网大厂之外的团队来说,剩下最大的挑战在于高质量训练数据集。
至今,OpenAI并没有公开训练ChatGPT的相关数据集来源和具体细节,一定程度上也暂时卡了追赶者的脖子,更何况,业界公认中文互联网数据质量堪忧。
好在,互联网上总有热心的牛人分析技术的细枝末节,从杂乱的资料中串联起蛛丝马迹,从而归纳出非常有价值的信息。
此前,OneFlow发布了《ChatGPT背后的经济账》,其作者从经济学视角推导了训练大型语言模型的成本。本文作者则整理分析了2018年到2022年初从GPT-1到Gopher的相关大型语言模型的所有数据集相关信息,希望帮助有志于开发“类ChatGPT”模型的团队少走一步弯路。
一些研究人员的报告称,通用人工智能(AGI)可能是从我们当前的语言模型技术进行演进[1],预训练Transformer语言模型为AGI的发展铺平了道路。虽然模型训练数据集日渐增大,但缺乏基本指标文档,包括数据集大小、数据集token数量和具体的内容细节。
尽管业内提出了数据集组成和整理文档的标准[2],但几乎所有重点研究实验室在揭示模型训练数据集细节这方面都做得不够。这里整合的研究涵盖了2018年到2022年初从GPT-1到Gopher的精选语言模型的所有数据集(包括主要数据集:Wikipedia和Common Crawl)的综合视图。
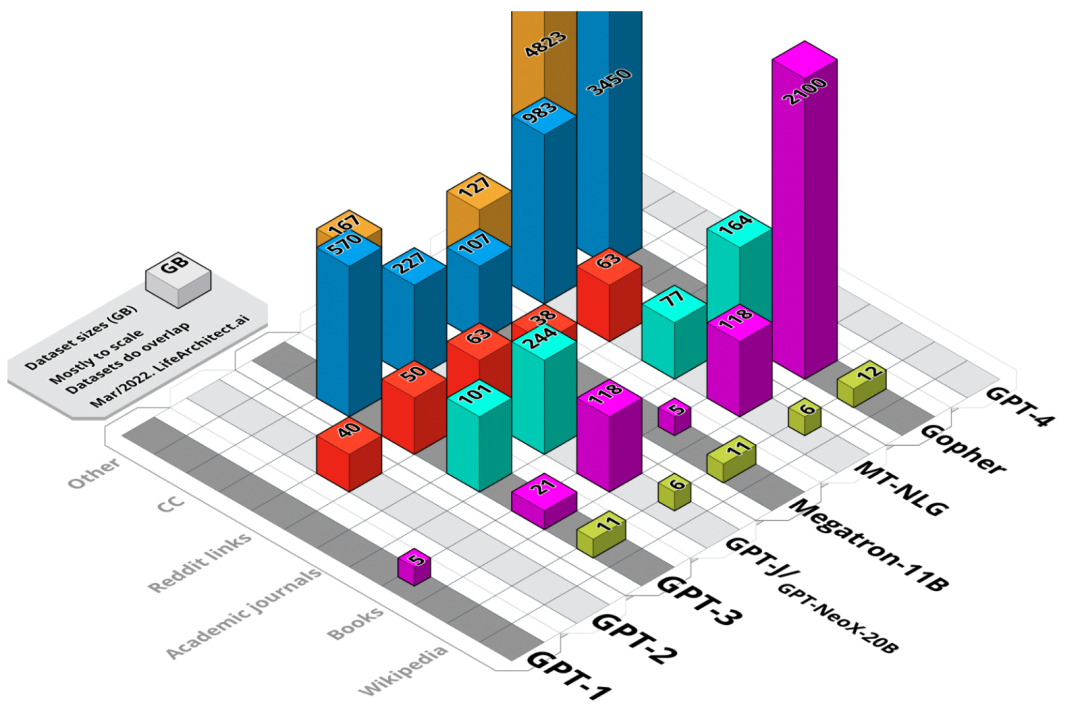
图 1. 主要数据集大小的可视化汇总。未加权大小,以GB为单位。
2018年以来,大语言模型的开发和生产使用呈现出爆炸式增长。一些重点研究实验室报告称,公众对大语言模型的使用率达到了惊人高度。2021年3月,OpenAI宣布[3]其GPT-3语言模型被“超过300个应用程序使用,平均每天能够生成45亿个词”,也就是说仅单个模型每分钟就能生成310万词的新内容。
值得注意的是,这些语言模型甚至还没有被完全理解,斯坦福大学的研究人员[4]最近坦言,“目前我们对这些模型还缺乏认知,还不太了解这些模型的运转模式、不知道模型何时会失效,更不知道这些模型的突现性(emergent properties)能产生什么效果”。
随着新型AI技术的快速发展,模型训练数据集的相关文档质量有所下降。模型内部到底有什么秘密?它们又是如何组建的?本文综合整理并分析了现代大型语言模型的训练数据集。
因为这方面的原始文献并不对外公开,所以本文搜集整合了二、三级研究资料,在必要的时候本文会采用假设的方式来推算最终结果。
在本文中,我们会将原始论文中已经明确的特定细节(例如token数量或数据集大小)归类为“公开的(disclosed)”数据,并作加粗处理。
多数情况下,适当地参考二、三级文献,并采用假设的方式来确定最终结果是很有必要的。在这些情况下,token数量和数据集大小等细节是“确定的(determined)”,并以斜体标记。
模型数据集可分为六类,分别是:维基百科、书籍、期刊、Reddit链接、Common Crawl和其他数据集。
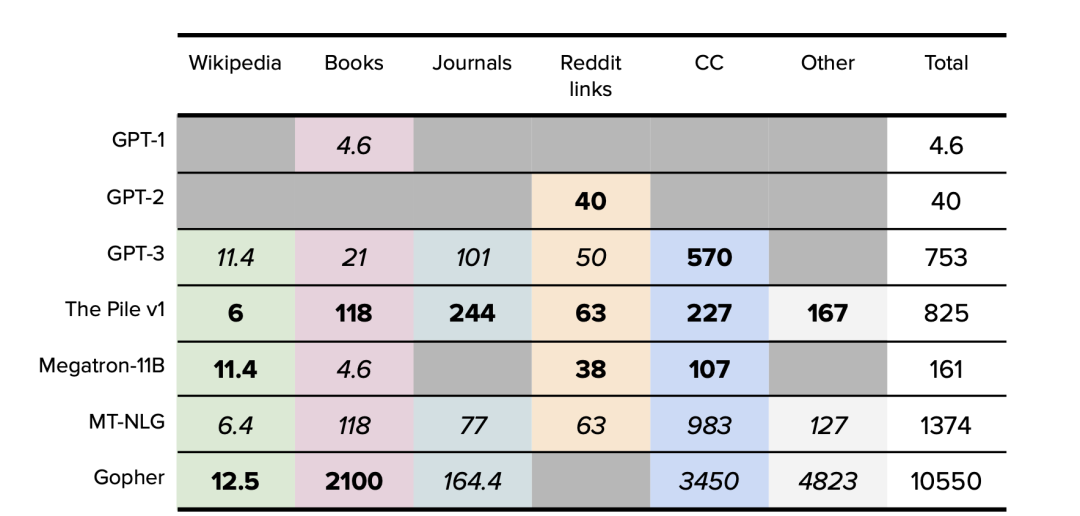
表1. 主要数据集大小汇总。以GB为单位。公开的数据以粗体表示。确定的数据以斜体表示。仅原始训练数据集大小。
1.1. 维基百科
维基百科是一个免费的多语言协作在线百科全书,由超过300,000名志愿者组成的社区编写和维护。截至2022年4月,英文版维基百科中有超过640万篇文章,包含超40亿个词[5]。维基百科中的文本很有价值,因为它被严格引用,以说明性文字形式写成,并且跨越多种语言和领域。一般来说,重点研究实验室会首先选取它的纯英文过滤版作为数据集。
1.2. 书籍
故事型书籍由小说和非小说两大类组成,主要用于训练模型的故事讲述能力和反应能力,数据集包括Project Gutenberg和Smashwords (Toronto BookCorpus/BookCorpus)等。
1.3. 杂志期刊
预印本和已发表期刊中的论文为数据集提供了坚实而严谨的基础,因为学术写作通常来说更有条理、理性和细致。这类数据集包括ArXiv和美国国家卫生研究院等。
1.4. Reddit链接
WebText是一个大型数据集,它的数据是从社交媒体平台Reddit所有出站链接网络中爬取的,每个链接至少有三个赞,代表了流行内容的风向标,对输出优质链接和后续文本数据具有指导作用。
1.5. Common Crawl
Common Crawl是2008年至今的一个网站抓取的大型数据集,数据包含原始网页、元数据和文本提取,它的文本来自不同语言、不同领域。重点研究实验室一般会首先选取它的纯英文过滤版(C4)作为数据集。
1.6. 其他数据集
不同于上述类别,这类数据集由GitHub等代码数据集、StackExchange 等对话论坛和视频字幕数据集组成。
2019年以来,大多数基于Transformer的大型语言模型 (LLM) 都依赖于英文维基百科和Common Crawl的大型数据集。在本节中,我们参考了Jesse Dodge和AllenAI(AI2)[8]团队的综合分析,按类别对英文维基百科作了高级概述,并在Common Crawl数据集[7]的基础上,用谷歌C4[6] (Colossal Clean Crawled Corpus)在Common Crawl中提供了顶级域(domains)。
2.1. 维基百科(英文版)分析
下面按类别[9]列出了维基百科的详细信息,涵盖了2015年抽样的1001篇随机文章,研究人员注意到随时间推移文章传播的稳定性。假设一个11.4GB、经过清理和过滤的维基百科英文版有30亿token,我们就可以确定类别大小和token。
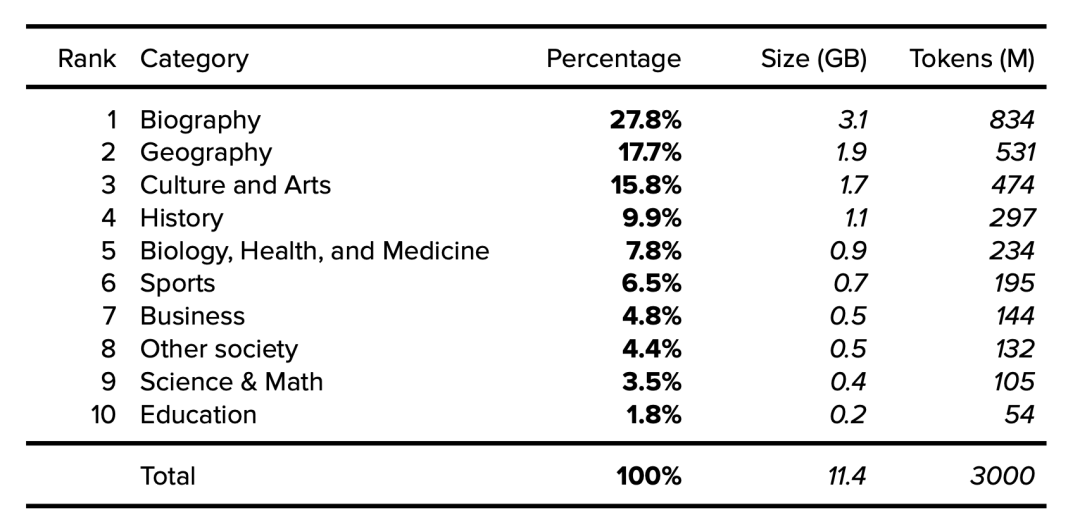
表2. 英文维基百科数据集类别。公开的数据以粗体表示。确定的数据以斜体表示。
2.2 Common Crawl分析
基于AllenAI (AI2)的C4论文,我们可以确定,过滤后的英文C4数据集的每个域的token数和总体百分比,该数据集为305GB,其中token数为1560亿。
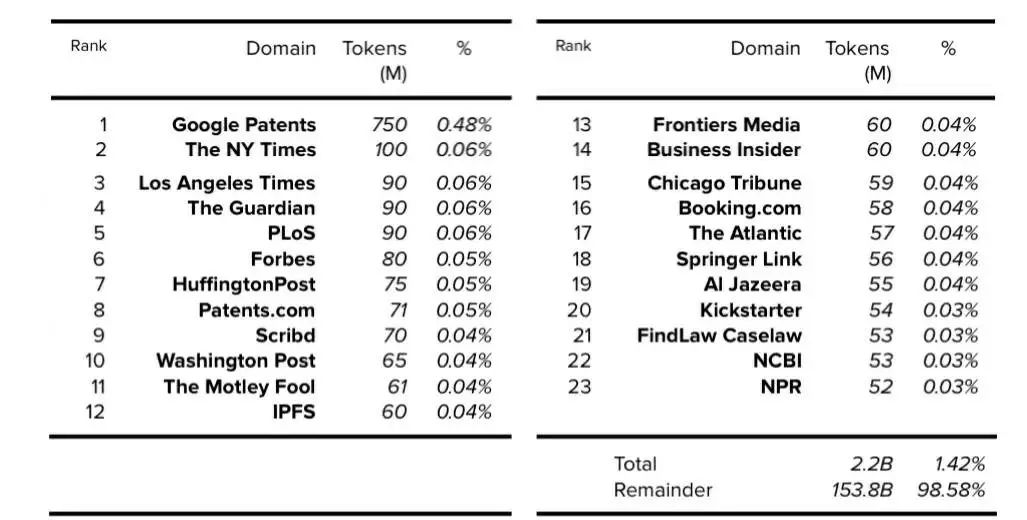
表3. C4:前23个域(不包括维基百科)。公开的数据以粗体表示,确定的数据以斜体表示。
2018年,OpenAI发布了1.17亿参数的GPT-1。在论文中,OpenAI并没有公布模型训练数据集的来源和内容[10],另外,论文误将‘BookCorpus’拼写成了‘BooksCorpus’。BookCorpus以作家未出版的免费书籍为基础,这些书籍来自于Smashwords,这是一个自称为“世界上最大的独立电子书分销商” 的电子书网站。这个数据集也被称为Toronto BookCorpus。经过几次重构之后,BookCorpus数据集的最终大小确定为4.6GB[11]。
2021年,经过全面的回顾性分析,BookCorpus数据集对按流派分组的书籍数量和各类书籍百分比进行了更正[12]。数据集中有关书籍类型的更多详细信息如下:

表4. BookCorpus书籍类型。公开的数据以粗体表示,确定的数据以斜体表示。
在随后的数据集重构中,BookCorpus数据集进一步过滤掉了书籍中的“吸血鬼”类别、降低了言情类书籍的百分比、增加了“历史”类书籍,增加了收集的书籍数量。
3.1. GPT-1数据集总结
GPT-1最终的数据集总结分析如下:

表5.GPT-1数据集总结。以GB为单位。公开的数据以粗体表示,确定的数据以斜体表示。
2019年,OpenAI发布了拥有15亿参数的语言模型GPT-2。GPT-2论文阐明了所用训练数据集的大小[13],不过并未说明其内容。而GPT-2模型卡(model card)(在GPT-2 GitHub仓库中)说明了模型内容[14]。
我们可以从GPT-3论文中得到token数量,该论文使用了WebText扩展版本来表示190亿token。据推测,2020年推出的WebText扩展版本拥有12个月的额外数据(additional data),因此它可能比2019年推出的GPT-2版本大25%左右[15]。GPT-2最终的token数量确定为150亿左右。
如GPT-2论文所述,假设模型卡显示链接数时,每个链接都可以被4500万链接总数所除,那WebText的内容在数据集中所占的百分比的详细信息就可以确定。
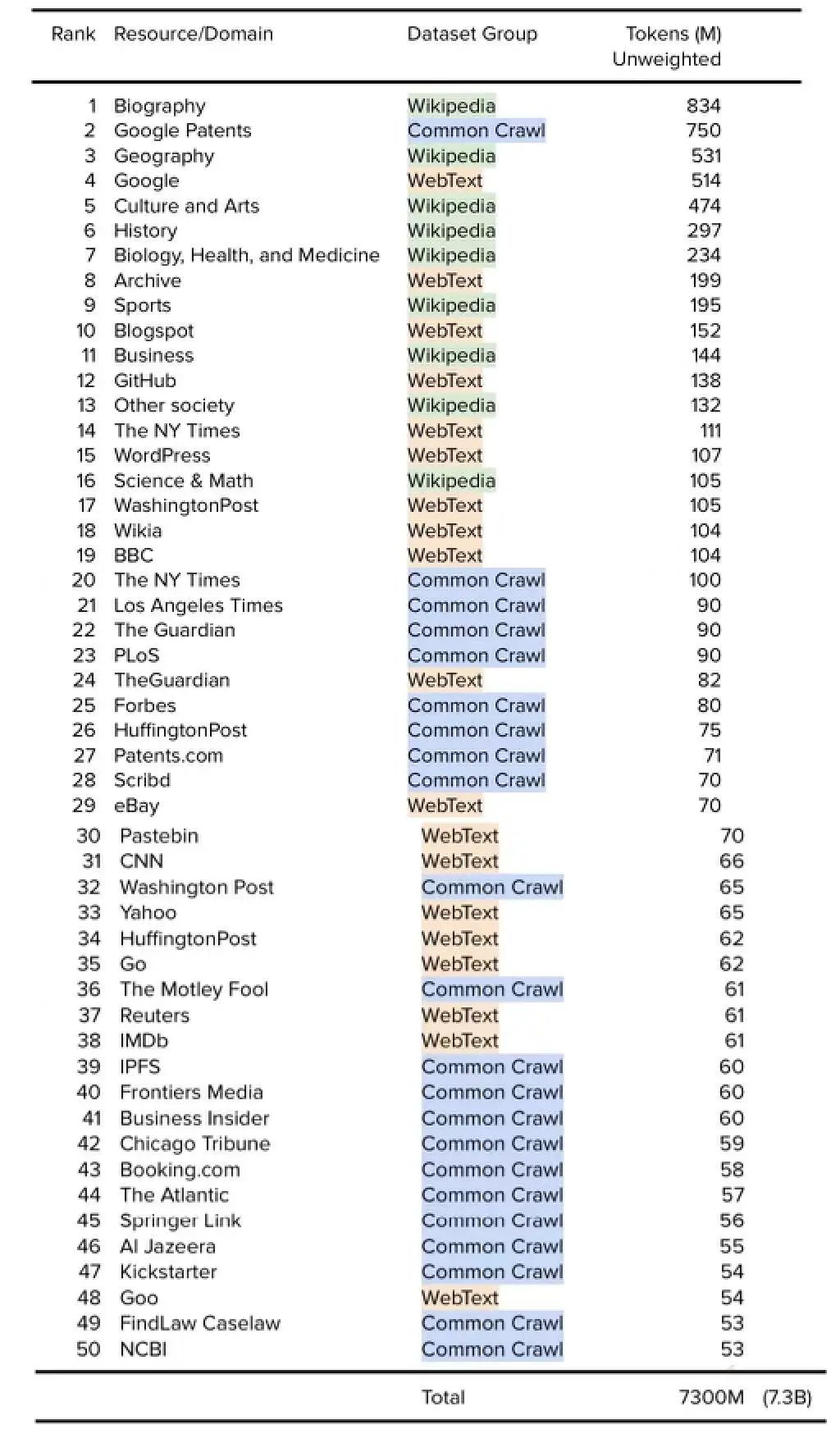
然后可以使用确定的150亿token数量来查找每个域的token数量。请注意,在可用的前1,000个域中,此处仅显示前50个域。
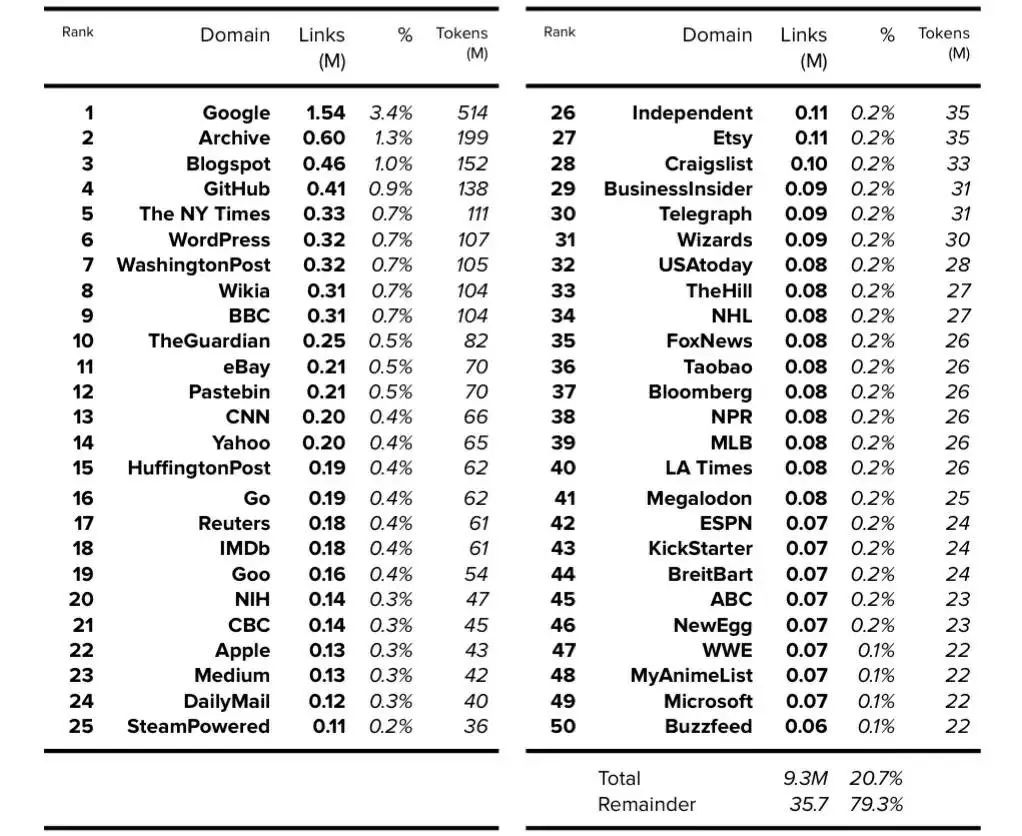
表6. WebText: 前50个域。 公开的数据以粗体表示,确定的数据以斜体表示。
4.1. GPT-2数据集总结
GPT-2模型最终的数据集总结分析如下:

表7. GPT-2数据集总结。 公开的数据以粗体表示,确定的数据以斜体表示。
GPT-3模型由OpenAI于2020年发布。论文阐明了所用训练数据集的token数量[16],但训练数据集的内容和大小尚不清楚(Common Crawl的数据集大小除外[17])
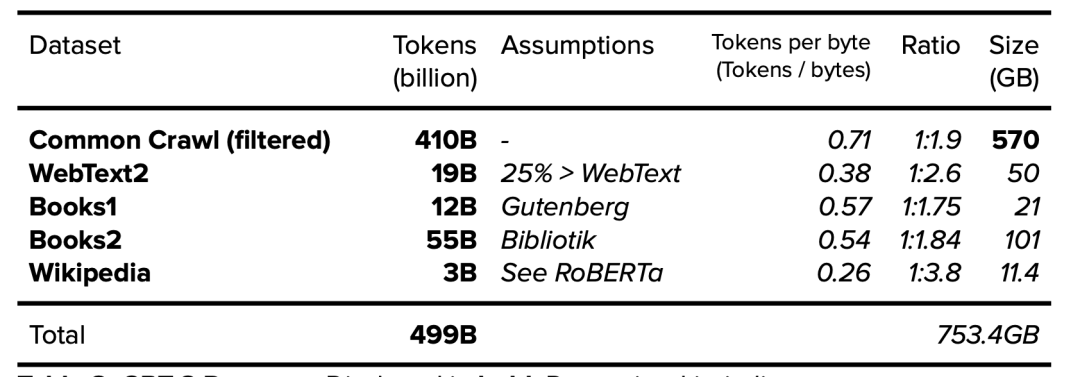
表8. GPT-3数据集。 公开的数据以粗体表示,确定的数据以斜体表示。
5.1. GPT-3:关于Books1和Books2数据集的分析
特别值得关注的是,在OpenAI的GPT-3论文中,并未公开Books1数据集(120亿token)和Books2数据集(550亿token)的大小和来源。关于这两个数据集的来源人们提出了几个假设,包括来自LibGen18和Sci-Hub的类似数据集,不过这两个数据集常以TB为计,大到无法匹配。
5.2. GPT-3:Books1
GPT-3使用的Books1数据集不可能与GPT-1使用的BookCorpus数据集相同,原因在于Books1的数据集更大,达120亿token。在一篇引用的论文[19]中就提及GPT-1使用的BookCorpus数据集拥有9.848亿个词,但这可能只相当于13亿token(984.8字x 1.3字的token乘数)。
通过标准化项目古腾堡语料库(SPGC),Books1有可能与古腾堡项目保持一致性。SPGC是一种开放式科学方法,被用于古腾堡项目完整的PG数据的精选(curated)版本。SPGC包含120亿个token[20],大约为21GB[21]。
5.3. GPT-3:Books2
Books2(550亿token)可能与Bibliotik保持一致,并由EleutherA收集该来源的数据,组成数据集,使其成为The Pile v1的一部分。Bibliotik版本为100.96GB[22],其确定的token数仅为250亿,低于Books2公开的550亿。然而,使用SPGC的‘每字节token数’比率(大约为1:1.75),Bibliotik的token数和大小将更接近于Books2。
5.4. GPT-3数据集总结
附录A概述了使用Wikipedia + CommonCrawl + WebText数据集的顶级资源列表。GPT-3模型的最终数据集总结分析如下:

表9.GPT-3数据集总结。公开的数据以粗体表示,确定的数据以斜体表示。
The Pile v1数据集由EleutherAI于2021年发布,该数据集已被用于训练包括GPT-J、GPT-NeoX-20B在内的多种模型,并作为包括MT-NLG在内的其他模型的部分数据集。The Pile v1论文阐明了所用训练数据集的来源和大小。随着token数量的增加,The Pile v1论文应被用作未来数据集文档的黄金标准。
有关token数量的更多详情,可以使用本文提供的信息来确定,参见表1(大小以GB为单位)和表7(token/每字节)[23]。
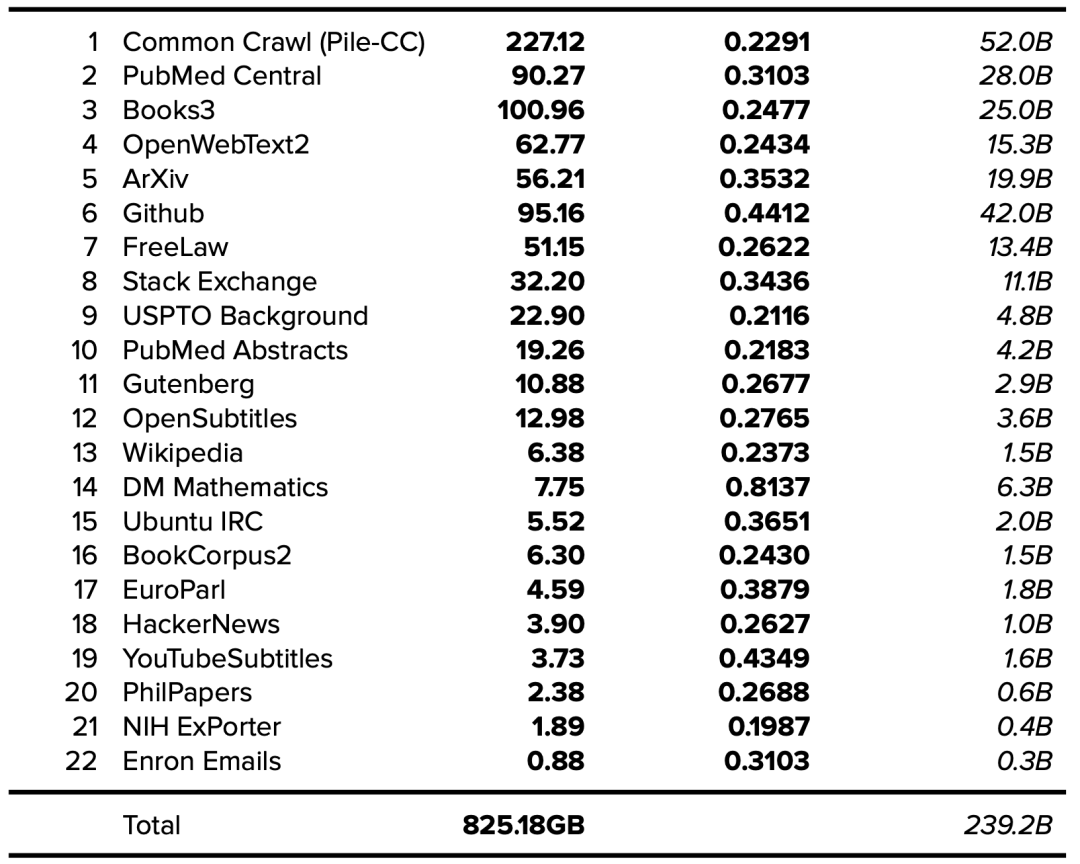
表10. The Pile v1数据集。公开的数据以粗体表示,确定的数据以斜体表示。
6.1. The Pile v1分组数据集(Grouped Datasets)
为了确定如‘Books’、‘Journals’和‘CC’这类数据集的大小,笔者对数据集进行了分组,如下表所示。
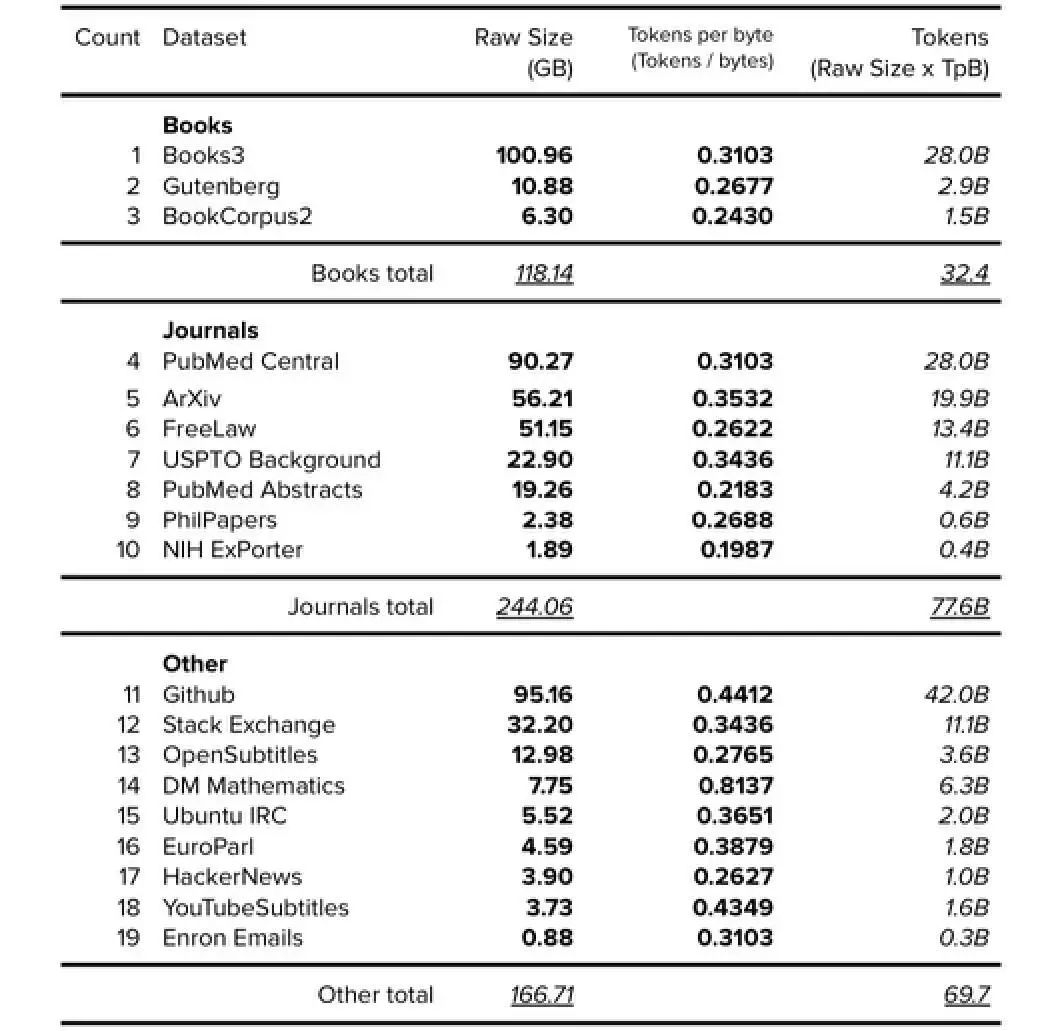
表11. The Pile v1分组数据集(不包括Wikipedia、CC 和 WebText)。公开的数据以粗体表示,确定的以斜体表示。
6.2. The Pile v1数据集总结
The Pile v1数据集与GPT-J和GPT-NeoX-20B模型的最终数据集总结分析如下:

表 12. Pile v1 数据集总结。 公开的数据以粗体表示,确定的数据以斜体表示。
2019年,Meta AI(当时称之为Facebook AI)和华盛顿大学联合发布了拥有1.25亿参数的RoBERTa模型。次年,Meta AI发布了拥有110亿参数的Megatron-11B模型。Megatron-11B使用的训练数据集与RoBERTa相同。RoBERTa[24]论文阐明了所用训练数据集的内容,不过必须参考引用的论文(BERT[25]和toryes[26])来确定最终的数据集大小。
BookCorpus: 确定的数据集为4.6GB,如上面的GPT-1部分所示。
维基百科:公开的数据集为“16GB(BookCorpus加上英文维基百科)”。在减去BookCorpus数据集(4.6GB,如上面的GPT-1部分所述)后,维基百科数据集确定为11.4GB。
CC-News:(经过滤后)公开的数据集为76GB。
OpenWebText: 公开的数据集为38GB。
Stories: 公开的数据集为31GB。请注意,此数据集是“基于常识推理任务问题”的Common Crawl内容,不属于本文的‘Books’类别。相反,将Stories与CC-News数据集(76GB)相结合,Common Crawl的总数据集则为107GB。
7.1. Megatron-11B和RoBERTa的数据集总结
Megatron-11B和RoBERTa最终的数据集总结分析如下:

表13. Megatron-11B和RoBERTa的数据集总结。 公示的数据以粗体表示,确定的数据以斜体表示。
2021年,英伟达和微软发布了拥有5300亿参数的语言模型MT-NLG。MT-NLG是微软Turing NLG(拥有170亿参数)和英伟达Megatron-LM(拥有83亿参数)的“继任者”。MT-NLG论文阐明了所用训练数据集的来源和token数量,不过没有明确指出数据集的大小。
如前所述,有关数据集大小的更多详情,可以使用The Pile v1论文中提供的信息来确定。虽然使用的组件相同,但注意的是,MT-NLG和The Pile v1中报告的组件大小却各不相同,这是由于来自Eleuther AI (The Pile v1数据集)和Microsoft/NVIDIA (MT-NLG模型)的研究人员采用了不同的数据过滤和去重方法。
8.1. MT-NLG中的Common Crawl数据集
Pile-CC:公开的数据集为498亿token,确定的数据为227.12GB左右,参见上述Pile v1部分。
CC-2020-50: 公开的数据集为687亿token,假设token的每字节率(per byte rate)为0.25 TpB=274.8GB。
CC-2021-04:公开的数据集为826亿token,假设token的每字节率为0.25 TpB=330.4GB。
RealNews(来自RoBERTa/Megatron-11B):显示为219亿token。根据RealNews论文[27],数据集确定为120GB。
CC-Stories(来自RoBERTa/Megatron-11B):公开的数据集为53亿token,如上述RoBERTa部分所示,数据集确定为31GB。
根据以上来源,可确认Common Crawl的总数据量为983.32GB,共计2283亿token。
8.2. MT-NLG分组数据集(Grouped Datasets)
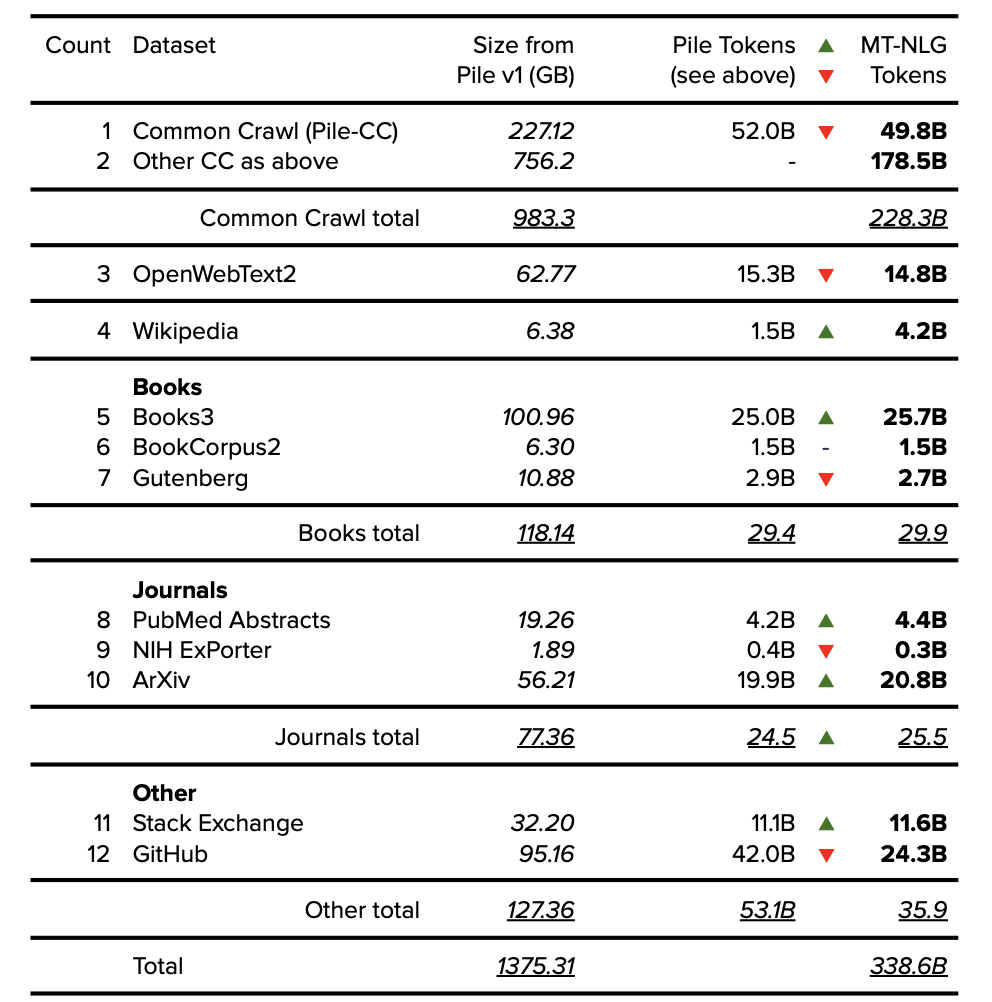
表14. MT-NLG 分组数据集。公开的数据以粗体表示,确定的数据以斜体表示。
8.3. MT-NLG数据集总结
MT-NLG模型最终的数据集总结分析如下:

表15. MT-NLG数据集总结。 公示的数据以粗体表示,确定的数据以斜体表示。
Gopher模型由DeepMind于2021年发布,有2800亿参数。该论文清楚地说明了所使用训练数据集所包含的高级token数量和大小[28],但没有说明详细内容。
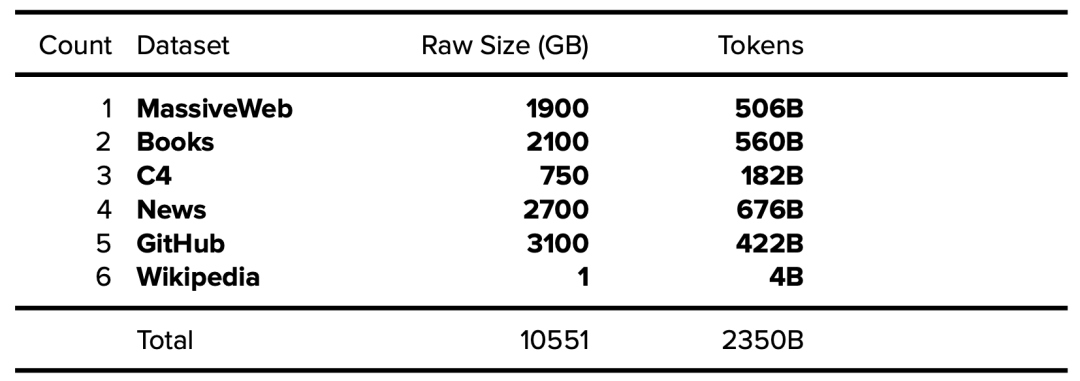
表16. 公开的Gopher数据集 (MassiveText)。公开的数据以粗体表述,确定的数据以斜体表示。
有趣的是,据Gopher论文披露:其Books数据集中包含一些超过500年历史(1500-2008)的书籍。
9.1. MassiveWeb数据集分析
DeepMind于2014年被谷歌收购,并在创建MassiveText时获得了海量数据。虽然Gopher论文中没有进一步详细描述MassiveWeb,但第44页附录中的表A3b注明了MassiveWeb中出现的前20个域[29]。根据披露的每个域所占的百分比,我们可以使用MassiveWeb的总token数(5060亿token)和总原始大小(1900GB)来确定每个域的token数量和大小。

表17. MassiveWeb:前20个域。公开的数据以粗体表示,确定的数据以斜体表示。
9.2. Gopher:关于维基百科数据集的分析
维基百科数据集的总规模很难确定。在Gopher论文中,研究人员指出维基百科没有进行数据去重[30]。然而,论文中列出的不同大小数据集(12.5GB MassiveWeb Wikipedia与1GB MassiveText Wikipedia)可能是由于失误而造成的,误将“10GB”写成了“1GB”。无论如何,本文仅使用MassiveWeb数据集版本 (12.5GB)。
9.3. Gopher: 不包括WebText
Gopher数据集的组成部分不包括Reddit外链的WebText数据集。为了清楚起见,尽管Reddit是MassiveWeb中的顶级域,但该数据集仅抓取Reddit域内的Reddit链接。根据定义,WebText[31]由“所有Reddit的外链”组成(即指向Reddit域外的链接)。
9.4. Gopher分组数据集
MassiveWeb被认为是MassiveText的子组件,并被集成到Gopher的数据集汇总中,其分组基于以下列出的可用信息:
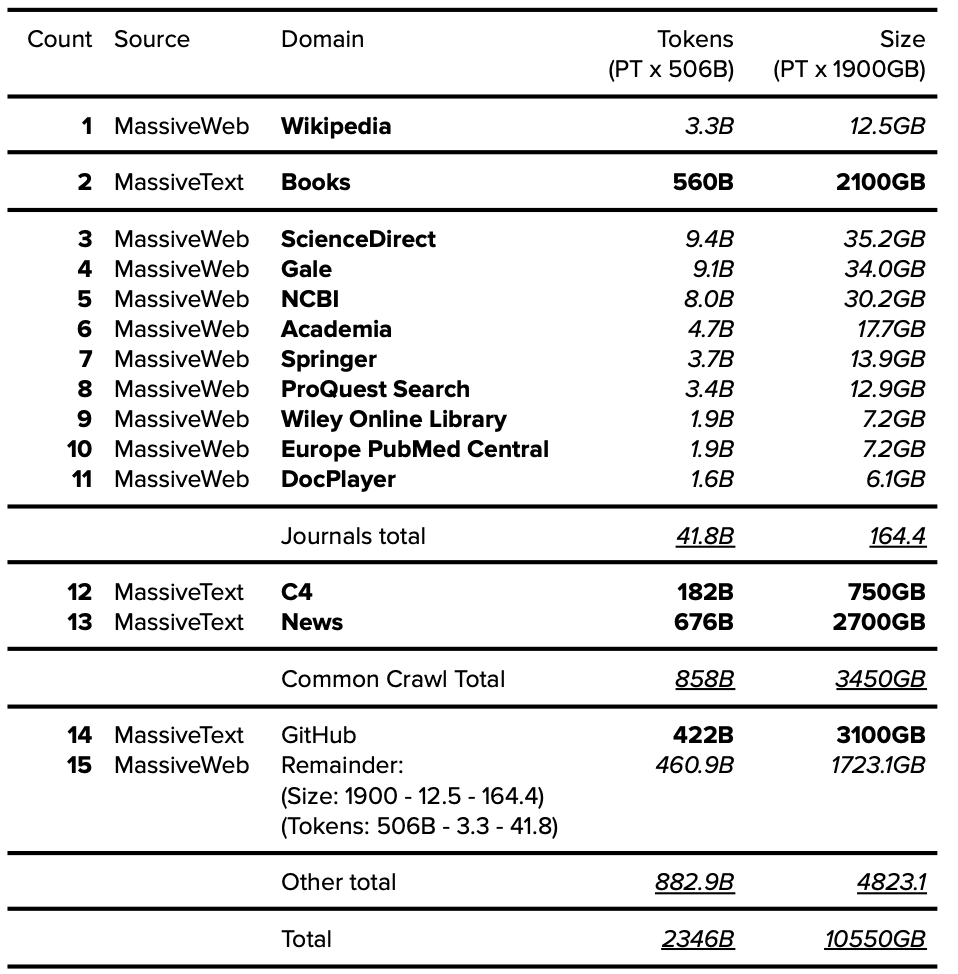
表18. Gopher分组数据集。公开的数据以粗体表示,确定的数据以斜体表示。
9.5. Gopher数据集总结
Gopher是本文中最大的数据集,大小为10.5TB。Gopher模型的最终数据集总结分析为:

表19. Gopher数据集总结。公开的数据以粗体表示,确定的数据以斜体表示。
对于训练当代Transformer大型语言模型的数据集而言,这可能是最全面的整合分析内容(截止2022年初)。在主要数据源不透明的情况下,本次研究主要从二级和三级来源收集数据,并经常需要假定来确定最终估计值。随着研究人员要处理千万亿个token(1,000万亿)和数千TB的数据(1,000TB),确保详细披露数据集组成的文档变得越来越重要。
特别值得关注的是,基于大型语言模型的强大AI系统产生的冗长而匿名的输出正在迅速发展,其中许多数据集的细节内容几乎没有文档说明。
强烈建议研究人员使用突出显示的“数据集的数据表(Datasheet for Datasets)”论文中提供的模板,并在记录数据集时使用最佳实践论文(即Pile v1论文,包括token数量)。数据集大小(GB)、token数量(B)、来源、分组和其他详细信息指标均应完整记录和发布。
随着语言模型不断发展并更广泛地渗透到人们的生活中,确保数据集的详细信息公开透明、所有人都可访问且易于理解是有用、紧迫和必要的。
Alan D. Thompson博士是人工智能专家、顾问。在2021年8月的世界人才大会(World Gifted Conference)上,Alan与Leta(由GPT-3提供支持的AI)共同举办了一场名为“The new irrelevance of intelligence”的研讨会。他的应用型人工智能研究和可视化成果受到了国际主要媒体的报道,同时还在2021年12月牛津大学有关AI伦理的辩论中被引用。他曾担任门萨国际(Mensa International)主席、通用电气(GE)和华纳兄弟(Warner Bros)顾问,也曾是电气与电子工程师协会(IEEE)和英国工程技术学会(IET)会员。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf
文章目录1.开发板选择*用到的资源2.串口通信(个人理解)3.代码分析(注释比较详细)1.主函数2.串口1配置3.串口2配置以及中断函数4.注意问题5.源码链接1.开发板选择我用的是STM32F103RCT6的板子,不过代码大概在F103系列的板子上都可以运行,我试过在野火103的霸道板上也可以,主要看一下串口对应的引脚一不一样就行了,不一样的就更改一下。*用到的资源keil5软件这里用到了两个串口资源,采集数据一个,串口通信一个,板子对应引脚如下:串口1,TX:PA9,RX:PA10串口2,TX:PA2,RX:PA32.串口通信(个人理解)我就从串口采集传感器数据这个过程说一下我自己的理解,
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手