这篇文章主要是关于php://filter伪协议中的知识点总结,分析了常见的用法
php://filter是php中独有的一种协议,它是一种过滤器,可以作为一个中间流来过滤其他的数据流。通常使用该协议来读取或者写入部分数据,且在读取和写入之前对数据进行一些过滤,例如base64编码处理,rot13处理等。官方解释为:
php://filter 是一种元封装器,设计用于数据流打开时的筛选过滤应用。这对于一体式(all-in-one)的文件函数非常有用,类似 readfile()、 file() 和 file_get_contents(),在数据流内容读取之前没有机会应用其他过滤器。
php://filter伪协议可以用于如下函数:
include()
file()
file_get_contents()
readfile()
file_put_contents()
可以用于读取、写入文件等函数,
php://filter伪协议的一般使用方法为:
php://filter/过滤器|过滤器/resource=要过滤的数据流
过滤器可以设置多个,使用管道符 |分隔,按照从左到右的方式依次使用相应的过滤器进行过滤处理,例如:
echo file_get_contents("php://filter/read=convert.base64-encode|convert.base64-encode/resource=data://text/plain,<?php phpinfo();?>");
上述代码对 <?php phpinfo();?> 进行了两次base64编码处理。
read可以省略,会自动根据函数作用来决定read还是write。
我们使用了 data伪协议 将 file_get_contents() 想要读取的内容变成了data伪协议输入的内容。
根据 php://filter官方说明 ,php://filter协议的过滤器 大致分为以下四类:
1、字符串过滤器
2、转换过滤器
3、压缩过滤器
4、加密过滤器
每个过滤器都正如其名字暗示的那样工作并与内置的 PHP 字符串函数的行为相对应。
字符串过滤器以 string 开头,常见的过滤器有 rot13、toupper、tolower、strip_tags等
使用该过滤器也就是用 str_rot13() 函数处理所有的流数据。
echo file_get_contents("php://filter/read=string.rot13/resource=data://text/plain,abcdefg");
//输出: nopqrst
该过滤器就是将字符串进行大小写转换.
等同于strtolower()、strtoupper() 函数
echo file_get_contents("php://filter/read=string.toupper/resource=data://text/plain,abcdefg");
//输出 ABCDEFG
echo file_get_contents("php://filter/read=string.tolower/resource=data://text/plain,ABCDEFG");
//输出 abcdefg
本特性已自 PHP 7.3.0 起废弃。强烈建议不要使用本特性。
使用此过滤器等同于用 strip_tags() 函数处理所有的流数据。可以用两种格式接收参数:一种是和 strip_tags() 函数第二个参数相似的一个包含有标记列表的字符串,一种是一个包含有标记名的数组。
strip_tags() — 从字符串中去除 HTML 和 PHP 标签
strip_tags对数据流进行strip_tags函数的处理,该函数功能为剥去字符串中的 HTML、XML 以及 PHP 的标签,简单理解就是包含有尖括号中的东西。
echo file_get_contents("php://filter/string.strip_tags/resource=flag.php");
//flag.php
<b>flag{abc}</b>
//输出:flag{abc}
主要含有三类,分别是base64的编码转换、quoted-printable的编码转换以及iconv字符编码的转换。该类过滤器以convert(转换)开头。
将数据进行base64编码、解码
使用这两个过滤器等同于分别用 base64_encode() 和 base64_decode() 函数处理所有的流数据。
echo file_get_contents("php://filter/read=convert.base64-encode/resource=data://text/plain,abc");
//输出:YWJj abc的base64编码
echo file_get_contents("php://filter/read=convert.base64-decode/resource=data://text/plain,YWJj");
//输出:abc
使用此过滤器的 decode 版本等同于用 quoted_printable_decode() 函数处理所有的流数据。没有和
convert.quoted-printable-encode相对应的函数。
quoted-printable-encode可译为可打印字符引用编码,可以理解为将一些不可打印的ASCII字符进行一个编码转换,转换成:=后面跟两个十六进制数,例如:
echo file_get_contents("php://filter/convert.quoted-printable-encode/resource=data://text/plain,666".chr(12));
//输出:666=0C
//将ascii码为12的字符编码为:=0C
quoted-printable-decode 与上述操作相反,将 =后面跟上两个16进制数 转换为不可打印的ascii字符
echo file_get_contents("php://filter/convert.quoted-printable-decode/resource=data://text/plain,666=0A888");
输出:666 // =0A 是 \n 的编码
888
在激活 iconv 的前提下可以使用
convert.iconv.*压缩过滤器, 等同于用 iconv() 处理所有的流数据。
iconv过滤器 就是对输入输出的数据进行编码转换,即将输入的字符串编码转换成输出指定的编码
写法:
该过滤器不支持参数,但可使用输入/输出的编码名称,组成过滤器名称,比如 :
convert.iconv.<input-encoding>.<output-encoding>
或
convert.iconv.<input-encoding>/<output-encoding> (两种写法的语义都相同)。
<input-encoding>和<output-encoding> 就是编码方式,有如下几种;
UCS-4*
UCS-4BE
UCS-4LE*
UCS-2
UCS-2BE
UCS-2LE
UTF-32*
UTF-32BE*
UTF-32LE*
UTF-16*
UTF-16BE*
UTF-16LE*
UTF-7
UTF7-IMAP
UTF-8*
ASCII*
例如:
将 abcdefg 从编码 UCS-2LE 转换为 UCS-2BE :
echo file_get_contents("php://filter/convert.iconv.UCS-2LE.UCS-2BE/resource=data://text/plain,abcdefg");
//输出: badcfe
就是两两字符顺序互换一下(两个两个一组)如果不是字符串2的倍数,最后1个字符不会被输出
将 abcdefgh1234 从编码 UCS-4LE 转换为 UCS-4BE :
echo file_get_contents("php://filter/convert.iconv.UCS-4LE.UCS-4BE/resource=data://text/plain,abcdefgh1234");
//输出:dcbahgfe4321
(四个一组)将每一组内的成员倒序排列,如果不是字符串4的倍数,最后几个字符不会被输出
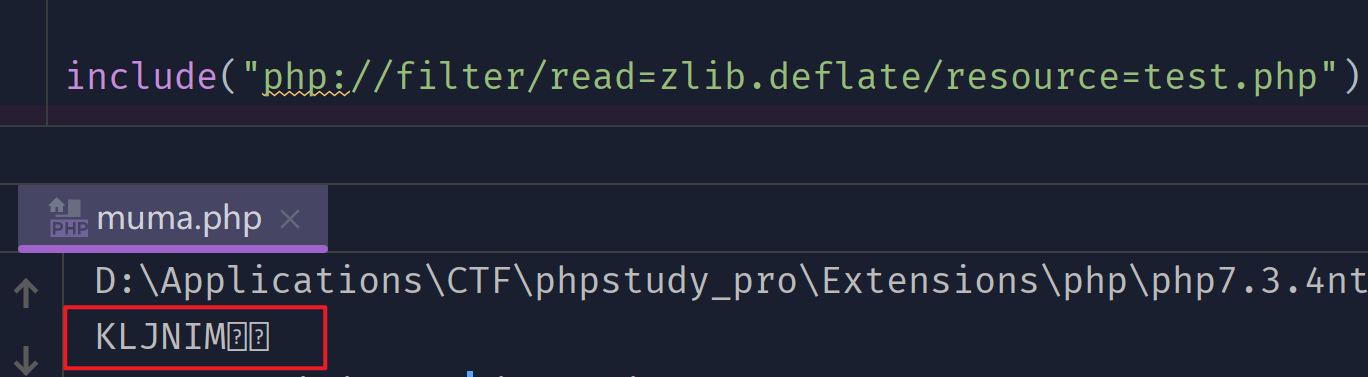
虽然 压缩封装协议 提供了在本地文件系统中 创建 gzip 和 bz2 兼容文件的方法,但不代表可以在网络的流中提供通用压缩的意思, 也不代表可以将一个非压缩的流转换成一个压缩流。对此,压缩过滤器可以在任何时候应用于任何流资源。
include("php://filter/read=zlib.deflate/resource=test.php");
//test.php
abcdef
输出:
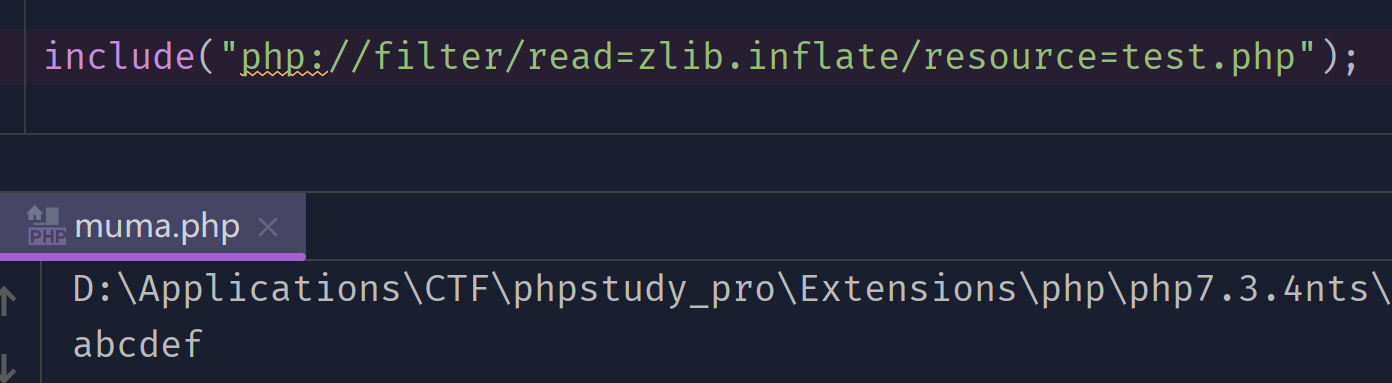
include("php://filter/read=zlib.inflate/resource=test.php");
//test.php内容为上面压缩后的内容
bzip2.compress和bzip2.decompress工作的方式与上面讲的zlib过滤器相同
加密过滤器特别适用于文件/数据流的加密。
本特性已自 PHP 7.1.0 起废弃。强烈建议不要使用本特性。
mcrypt.* 和 mdecrypt.* 使用 libmcrypt 提供了对称的加密和解密。这两组过滤器都支持 mcrypt 扩展库中相同的算法,格式为 mcrypt.ciphername,其中 ciphername 是密码的名字,将被传递给 mcrypt_module_open()。有以下五个过滤器参数可用:
mcrypt 过滤器参数
| 参数 | 是否必须 | 默认值 | 取值举例 |
|---|---|---|---|
| mode | 可选 | cbc | cbc, cfb, ecb, nofb, ofb, stream |
| algorithms_dir | 可选 | ini_get(‘mcrypt.algorithms_dir’) | algorithms 模块的目录 |
| modes_dir | 可选 | ini_get(‘mcrypt.modes_dir’) | modes 模块的目录 |
| iv | 必须 | N/A | 典型为 8,16 或 32 字节的二进制数据。根据密码而定 |
| key | 必须 | N/A | 典型为 8,16 或 32 字节的二进制数据。根据密码而定 |
如果您觉得这篇文章不错的话,请多多点赞支持一下,您的支持是我最大的动力!
是否有可能:before_filter:authenticate_user!||:authenticate_admin! 最佳答案 before_filter:do_authenticationdefdo_authenticationauthenticate_user!||authenticate_admin!end 关于ruby-on-rails-before_filter运行多个方法,我们在StackOverflow上找到一个类似的问题: https://
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
尝试通过SSL连接到ImgurAPI时出现错误。这是代码和错误:API_URI=URI.parse('https://api.imgur.com')API_PUBLIC_KEY='Client-ID--'ENDPOINTS={:image=>'/3/image',:gallery=>'/3/gallery'}#Public:Uploadanimage##args-Theimagepathfortheimagetoupload#defupload(image_path)http=Net::HTTP.new(API_URI.host)http.use_ssl=truehttp.verify
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我来自C、php和bash背景,很容易学习,因为它们都有相同的C结构,我可以将其与我已经知道的联系起来。然后2年前我学了Python并且学得很好,Python对我来说比Ruby更容易学。然后从去年开始,我一直在尝试学习Ruby,然后是Rails,我承认,直到现在我还是学不会,讽刺的是那些打着简单易学的烙印,但是对于我这样一个老练的程序员来说,我只是无法将它
我正在寻找一个清晰的Rails4示例,说明如何根据通过另一个表关联的数据过滤记录。假设我有一个用户模型和一个评论模型。一个用户has_many评论,一个Commentbelongs_to一个用户。评论在其表中也有一个score列。classUserUsers|id|name|email||-----|---------|---------------------||1|"Alice"|"alice@example.com"||2|"Bob"|"bob@example.com"||...|classComment我如何获得所有对内容“k”发表评论且分数>0的用户?请注意,我要返回的是用户
一、RIPV2协议简介 RIP(RoutingInformationProtocol)路由协议是一种相对古老,在小型以及同介质网络中得到了广泛应用的一种路由协议。RIP采用距离向量算法,是一种距离向量协议。RIP-1是有类别路由协议(ClassfulRoutingProtocol),它只支持以广播方式发布协议报文。RIP-1的协议报文无法携带掩码信息,它只能识别A、B、C类这样的自然网段的路由,因此RIP-1不支持非连续子网(DiscontiguousSubnet)。RIP-2是一种无类别路由协议(ClasslessRoutingProtocol),支持路由标记,在路由策略中可根据路由标记对
【动态规划】一、背包问题1.背包问题总结1)动规四部曲:2)递推公式总结:3)遍历顺序总结:2.01背包1)二维dp数组代码实现2)一维dp数组代码实现3.完全背包代码实现4.多重背包代码实现一、背包问题1.背包问题总结暴力的解法是指数级别的时间复杂度。进而才需要动态规划的解法来进行优化!背包问题是动态规划(DynamicPlanning)里的非常重要的一部分,关于几种常见的背包,其关系如下:在解决背包问题的时候,我们通常都是按照如下五部来逐步分析,把这五部都搞透了,算是对动规来理解深入了。1)动规四部曲:(1)确定dp数组及其下标的含义(2)确定递推公式(3)dp数组的初始化(4)确定遍历顺