Nacos 0.8.0版本完善了监控系统,支持通过暴露metrics数据接入第三方监控系统监控Nacos运行状态,目前支持prometheus、elastic search和influxdb,下面结合prometheus和grafana如何监控Nacos,官网grafana监控页面。
按照部署文档搭建好Nacos集群(具体可参考之前的博客)
配置application.properties文件,暴露metrics数据
management.endpoints.web.exposure.include=*
访问{ip}:8848/nacos/actuator/prometheus,看是否能访问到metrics数据
下载你想安装的prometheus版本,地址为download prometheus
解压prometheus压缩包
tar xvfz prometheus-*.tar.gz
cd prometheus-*
修改配置文件prometheus.yml采集Nacos metrics数据
metrics_path: '/nacos/actuator/prometheus'
static_configs:
- targets: ['{ip1}:8848','{ip2}:8848','{ip3}:8848']
启动prometheus服务
./prometheus --config.file="prometheus.yml"
下载对应的windows版本并解压
修改配置文件prometheus.yml采集Nacos metrics数据
metrics_path: '/nacos/actuator/prometheus'
static_configs:
- targets: ['{ip1}:8848','{ip2}:8848','{ip3}:8848']
启动prometheus服务
prometheus.exe --config.file=prometheus.yml
通过访问http://{ip}:9090/graph可以看到prometheus的采集数据,在搜索栏搜索nacos_monitor可以搜索到Nacos数据说明采集数据成功

和prometheus在同一台机器上安装grafana,使用 yum 安装grafana
brew install grafana
brew services start grafana
sudo yum install https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-5.2.4-1.x86_64.rpm
sudo service grafana-server start
参考文档:Install on Windows | Grafana documentation
访问grafana: http://{ip}:3000
配置prometheus数据源
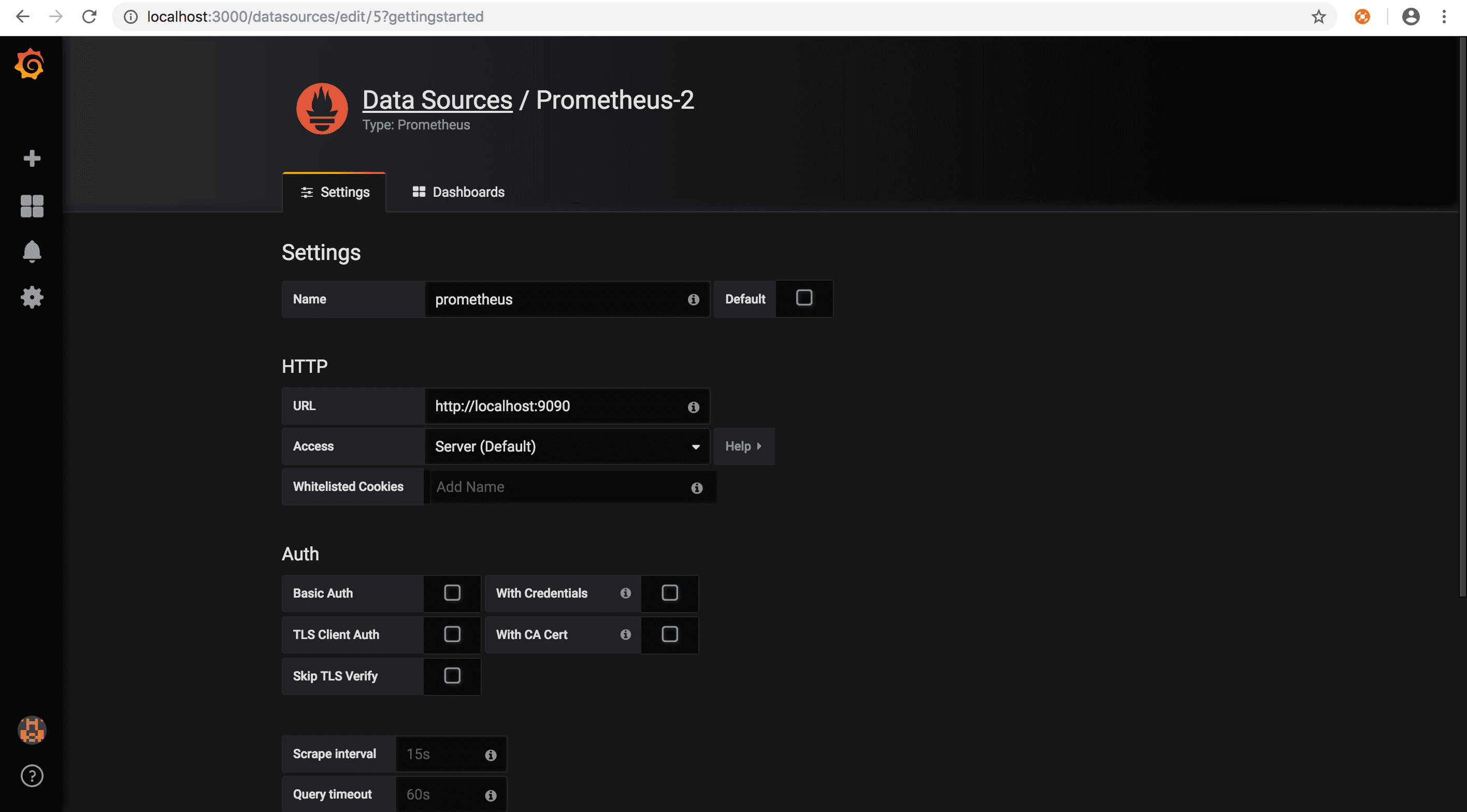
导入Nacos grafana监控模版

Nacos监控分为三个模块:



当Nacos运行出现问题时,需要grafana告警通知相关负责人。grafana支持多种告警方式,常用的有邮件,钉钉和webhook方式
钉钉可以通过配置钉钉机器人
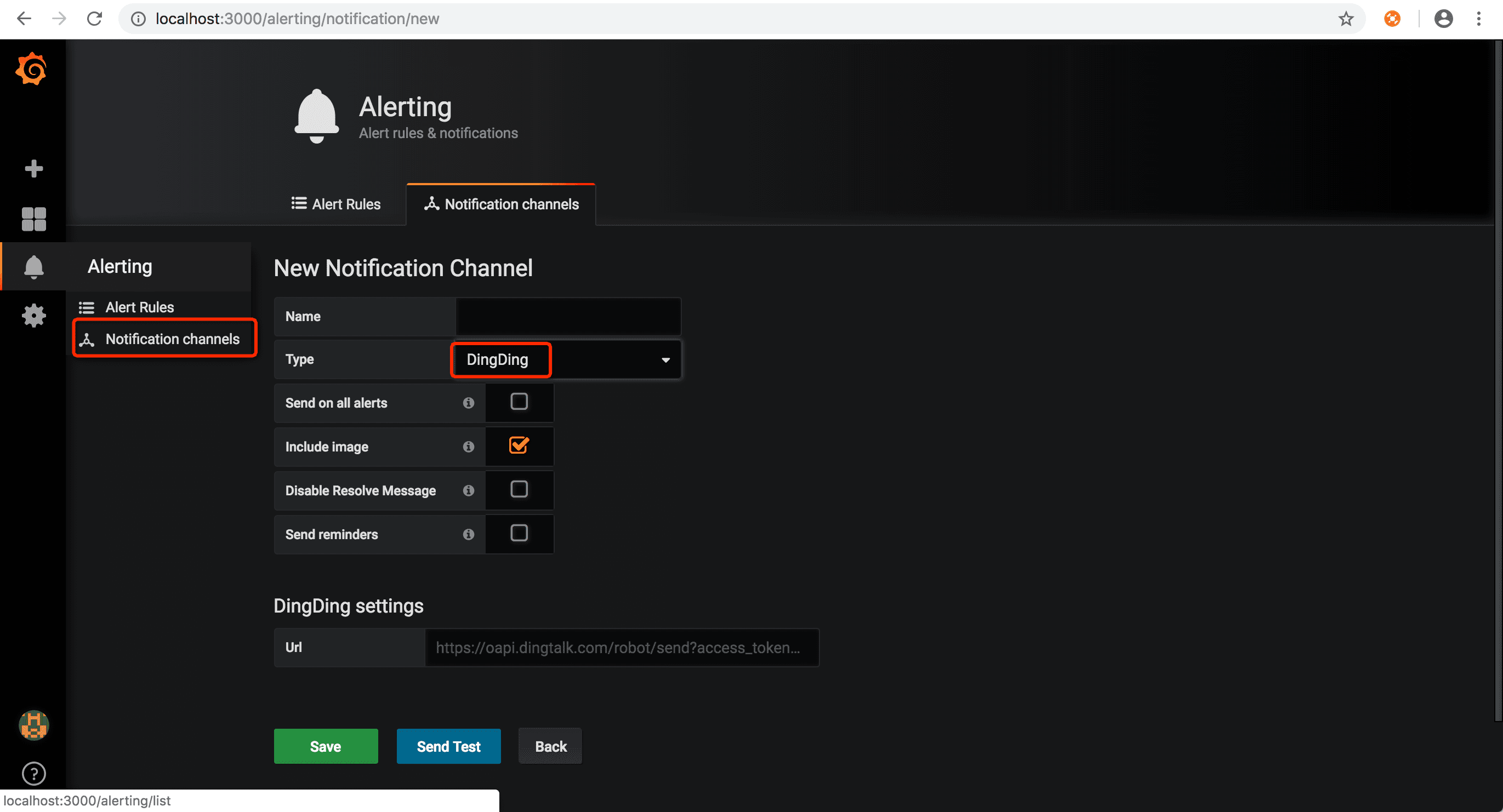
配置钉钉通知url
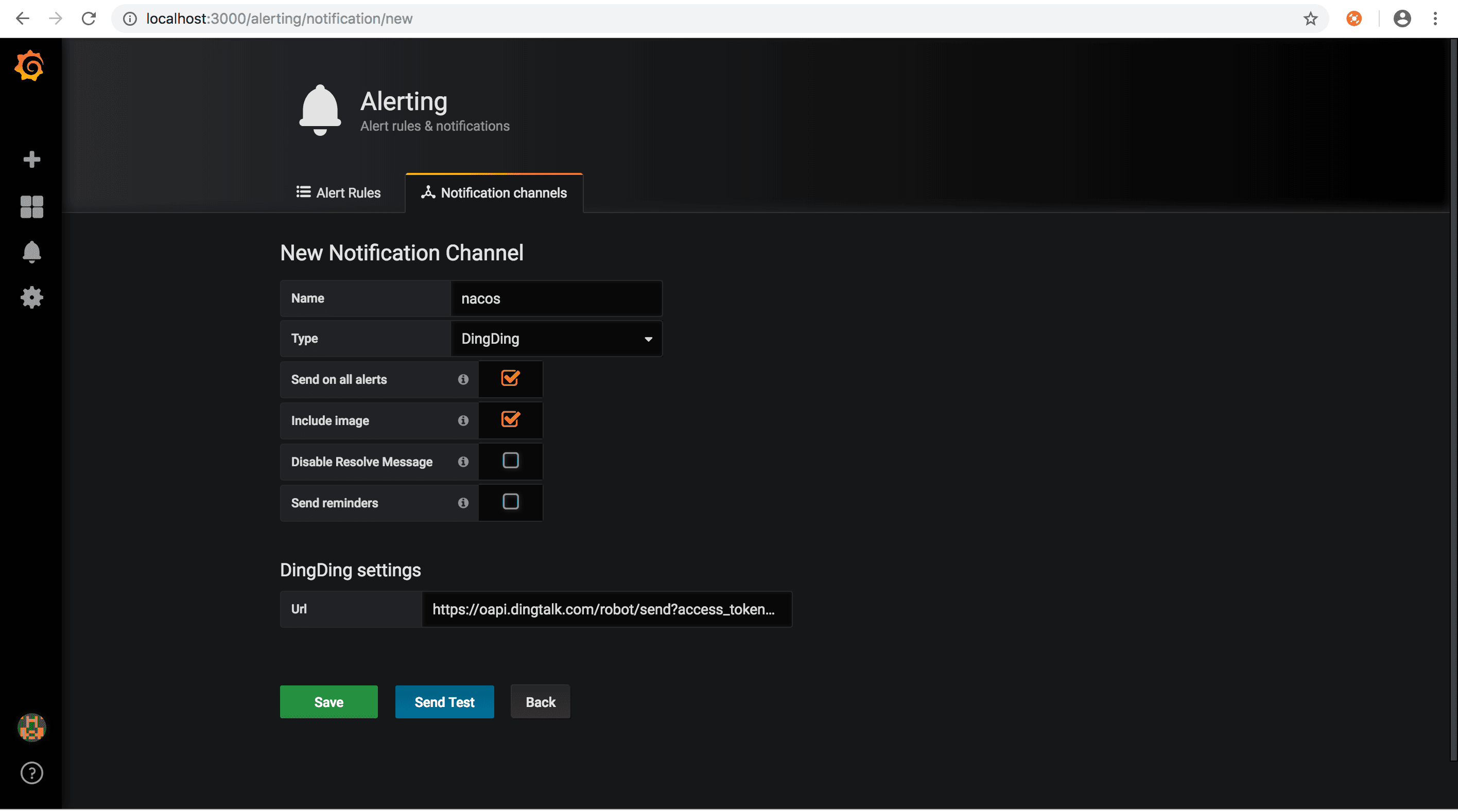
测试告警项

修改defaults.ini配置文件,增加邮件告警
#################################### SMTP / Emailing ##########################
[smtp]
enabled = true
host = smtp.126.com:25
user = xxxxxx
password = xxxxx
;cert_file =
;key_file =
skip_verify = true
from_address = xxxxxx@126.com
[emails]
;welcome_email_on_sign_up = false
配置通知邮箱

| 指标 | 含义 |
|---|---|
| system_cpu_usage | CPU使用率 |
| system_load_average_1m | load |
| jvm_memory_used_bytes | 内存使用字节,包含各种内存区 |
| jvm_memory_max_bytes | 内存最大字节,包含各种内存区 |
| jvm_gc_pause_seconds_count | gc次数,包含各种gc |
| jvm_gc_pause_seconds_sum | gc耗时,包含各种gc |
| jvm_threads_daemon | 线程数 |
| 指标 | 含义 |
|---|---|
| http_server_requests_seconds_count | http请求次数,包括多种(url,方法,code) |
| http_server_requests_seconds_sum | http请求总耗时,包括多种(url,方法,code) |
| nacos_timer_seconds_sum | Nacos config水平通知耗时 |
| nacos_timer_seconds_count | Nacos config水平通知次数 |
| nacos_monitor{name='longPolling'} | Nacos config长连接数 |
| nacos_monitor{name='configCount'} | Nacos config配置个数 |
| nacos_monitor{name='dumpTask'} | Nacos config配置落盘任务堆积数 |
| nacos_monitor{name='notifyTask'} | Nacos config配置水平通知任务堆积数 |
| nacos_monitor{name='getConfig'} | Nacos config读配置统计数 |
| nacos_monitor{name='publish'} | Nacos config写配置统计数 |
| nacos_monitor{name='ipCount'} | Nacos naming ip个数 |
| nacos_monitor{name='domCount'} | Nacos naming域名个数(1.x 版本) |
| nacos_monitor{name='serviceCount'} | Nacos naming域名个数(2.x 版本) |
| nacos_monitor{name='failedPush'} | Nacos naming推送失败数 |
| nacos_monitor{name='avgPushCost'} | Nacos naming平均推送耗时 |
| nacos_monitor{name='leaderStatus'} | Nacos naming角色状态 |
| nacos_monitor{name='maxPushCost'} | Nacos naming最大推送耗时 |
| nacos_monitor{name='mysqlhealthCheck'} | Nacos naming mysql健康检查次数 |
| nacos_monitor{name='httpHealthCheck'} | Nacos naming http健康检查次数 |
| nacos_monitor{name='tcpHealthCheck'} | Nacos naming tcp健康检查次数 |
| 指标 | 含义 |
|---|---|
| nacos_exception_total{name='db'} | 数据库异常 |
| nacos_exception_total{name='configNotify'} | Nacos config水平通知失败 |
| nacos_exception_total{name='unhealth'} | Nacos config server之间健康检查异常 |
| nacos_exception_total{name='disk'} | Nacos naming写磁盘异常 |
| nacos_exception_total{name='leaderSendBeatFailed'} | Nacos naming leader发送心跳异常 |
| nacos_exception_total{name='illegalArgument'} | 请求参数不合法 |
| nacos_exception_total{name='nacos'} | Nacos请求响应内部错误异常(读写失败,没权限,参数错误) |
| 指标 | 含义 |
|---|---|
| nacos_monitor{name='subServiceCount'} | 订阅的服务数 |
| nacos_monitor{name='pubServiceCount'} | 发布的服务数 |
| nacos_monitor{name='configListenSize'} | 监听的配置数 |
| nacos_client_request_seconds_count | 请求的次数,包括多种(url,方法,code) |
| nacos_client_request_seconds_sum | 请求的总耗时,包括多种(url,方法,code) |
随着Nacos 0.9版本发布,Nacos-Sync 0.3版本支持了metrics监控,能通过metrics数据观察Nacos-Sync服务的运行状态,提升了Nacos-Sync的在生产环境的监控能力。 整体的监控体系的搭建参考Nacos监控手册
和Nacos监控一样,Nacos-Sync也提供了监控模版,导入监控模版
Nacos-Sync监控同样也分为三个模块:


Nacos-Sync的metrics分为jvm层和应用层
| 指标 | 含义 |
|---|---|
| system_cpu_usage | CPU使用率 |
| system_load_average_1m | load |
| jvm_memory_used_bytes | 内存使用字节,包含各种内存区 |
| jvm_memory_max_bytes | 内存最大字节,包含各种内存区 |
| jvm_gc_pause_seconds_count | gc次数,包含各种gc |
| jvm_gc_pause_seconds_sum | gc耗时,包含各种gc |
| jvm_threads_daemon | 线程数 |
| 指标 | 含义 |
|---|---|
| nacosSync_task_size | 同步任务数 |
| nacosSync_cluster_size | 集群数 |
| nacosSync_add_task_rt | 同步任务执行耗时 |
| nacosSync_delete_task_rt | 删除任务耗时 |
| nacosSync_dispatcher_task | 从数据库中分发任务 |
| nacosSync_sync_task_error | 所有同步执行时的异常 |
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
目录SpringBootStarter是什么?以前传统的做法使用SpringBootStarter之后starter的理念:starter的实现: 创建SpringBootStarter步骤在idea新建一个starter项目、直接执行下一步即可生成项目。 在xml中加入如下配置文件:创建proterties类来保存配置信息创建业务类:创建AutoConfiguration测试如下:SpringBootStarter是什么? SpringBootStarter是在SpringBoot组件中被提出来的一种概念、简化了很多烦琐的配置、通过引入各种SpringBootStarter包可以快速搭建出一
是否可以在我的服务器上运行任何工具来监控多个Rails应用程序?我需要监控每个应用程序收到的请求数、每个应用程序使用了多少内存、使用了多少CPU以及其他类似的统计信息。我需要查看每个单独的Rails应用程序的统计信息。 最佳答案 我建议你试试NewRelicRPM.免费版:RPMLiteisthemostwidelyusedsolutionforbasicwebapplicationmonitoring.RPMLiteprovidesapplicationmonitoringforunlimitedJava,RubyorJRubya
我在/usr/local/lib中安装了一些本地库。我现在正在尝试安装一个需要这些的gem,以便正确构建,但是gem构建失败,因为它找不到图书馆。gem的extconf.rb文件试图确认它可以找到库have_library()但由于某种原因失败了。我尝试设置一堆环境变量,但似乎没有任何效果:irb(main):003:0>require'mkmf'=>trueirb(main):004:0>have_library('gecodesearch')checkingformain()in-lgecodesearch...no=>falseirb(main):005:0>ENV['LD_LI
我正在寻找一种方法来监视流上的事件,以便我可以确定是否有任何内容通过流。如果有,我将开始使用rtmpdump进行录制。我想象这是通过运行一个每60秒检查一次流的cron任务来实现的。如果它确定流正在通过,则调用rtmpdump开始记录它。如果没有,则什么都不做,并在60秒后再次检查。由于rtmpdump只是在没有流数据时出现错误,因此尝试使用它来监视流似乎不是一个好主意,但也许我错了。如果我在逐个案例的基础上手动执行此操作会很容易,但我正在尝试自动执行自动录制流的任务(如果它们可用)。有没有人遇到过这样做的方法?也许我可以在命令行(linux)中使用其他一些工具?如果有帮助,我正在使用
文章目录Kubernetes(k8s)工作负载一、Workloads二、Pod三、Deployment四、RC、RS、DaemonSet、StatefulSet五、Job、CronJob1、Job2、CronJob六、GCKubernetes(k8s)工作负载一、Workloads什么是工作负载(Workloads)工作负载是运行在Kubernetes上的一个应用程序。一个应用很复杂,可能由单个组件或者多个组件共同完成。无论怎样我们可以用一组Pod来表示一个应用,也就是一个工作负载Pod又是一组容器(Containers)所以关系又像是这样工作负载(Workloads)控制一组PodPod控制
绝对详细的RabbitMQ实践操作手册,看完本系列就够了。一、什么是MQ?1、MQ的概念2、理解消息队列二、MQ的优势和劣势1、优势和作用2、劣势三、MQ的应用场景四、AMQP五、工作原理一、什么是MQ?1、MQ的概念MQ全称MessageQueue(消息队列),是在消息的传输过程中保存消息的容器。多用于系统之间的异步通信。下面用图来理解异步通信,并阐明与同步通信的区别。同步通信:甲乙两人面对面交流,你一句我一句必须同步进行,两人除此之外不做任何事情异步通信:异步通信相当于通过第三方转述对话,可能有消息的延迟,但不需要二人时刻保持联系,消息传给第三方后,两人可以做其他自己想做的事情,当需要获取
每5分钟(例如)ping20个网站的列表以了解该网站是否响应HTTP202的最佳方法是什么?最简单的想法是将20个URLS保存在数据库中,然后运行数据库并对每个URL执行ping操作。但是,当一个人不回答时会发生什么?之后的人会怎样?此外,是否有更好但更简单的解决方案?恐怕该列表会增长到20000个网站,然后没有足够的时间在我需要ping的5分钟内全部ping通它们。基本上,我是在描述PingDom、UptimeRobot等的工作原理。我正在使用node.js和RubyonRails构建这个系统。我也倾向于使用MongoDB来保存所有ping和监控结果的历史记录。建议?非常感谢!
我们有一个带有广泛管理部分的应用程序。我们对功能有点满意(就像您一样),并且正在寻找一些快速简便的方法来监控“谁使用什么”。理想情况下,一个简单的gem将允许我们在每个用户的基础上跟踪Controller/操作,以构建使用的功能和未使用的功能的图片。任何你会推荐的..谢谢主场 最佳答案 我不知道有什么流行的gem或插件可以解决这个问题;过去,我在ApplicationController中将这种审计实现为before_filter:从内存中:classApplicationControllercurrent_user,:contro
我有一堆长时间运行的Ruby脚本,我想确保每30秒左右运行一次。我通常通过简单地启动命令rubyscript-name.rb我如何配置monit来管理这些脚本?更新:我试着关注thismethodtocreateawrapperscript然后它会启动ruby进程,但它似乎没有创建.pid文件并且键入“./wrapper-scriptstop”什么也没做:/我应该在ruby中编写pid还是使用包装脚本来创建monit所需的pid? 最佳答案 MonitWiki有很多配置示例:http://mmonit.com/wiki/Mo