\(EX\)和\(DX\)存在,对于任意的\(\epsilon>0\),有
这里证明\(X\)是连续型的情况。
因此,\(P\{|X-EX|\ge\epsilon\}\le \frac{DX}{\epsilon^2}\).
证明过程补充说明:
第一个不等号是因为\(|X-EX|\ge\epsilon\),两边平方,就有\((X-EX)^2\ge\epsilon^2\),于是\(\frac{(X-EX)^2}{\epsilon^2}\ge1\),因此乘上这个系数就会大于等于原来的积分。
第二个不等号是因为积分区域扩大了,并且被积函数是密度函数是非负的,所以有大于等于的不等关系。
最后的定积分化为方差,其实就是连续型随机变量的方差计算公式。?随机变量的方差-计算-连续型
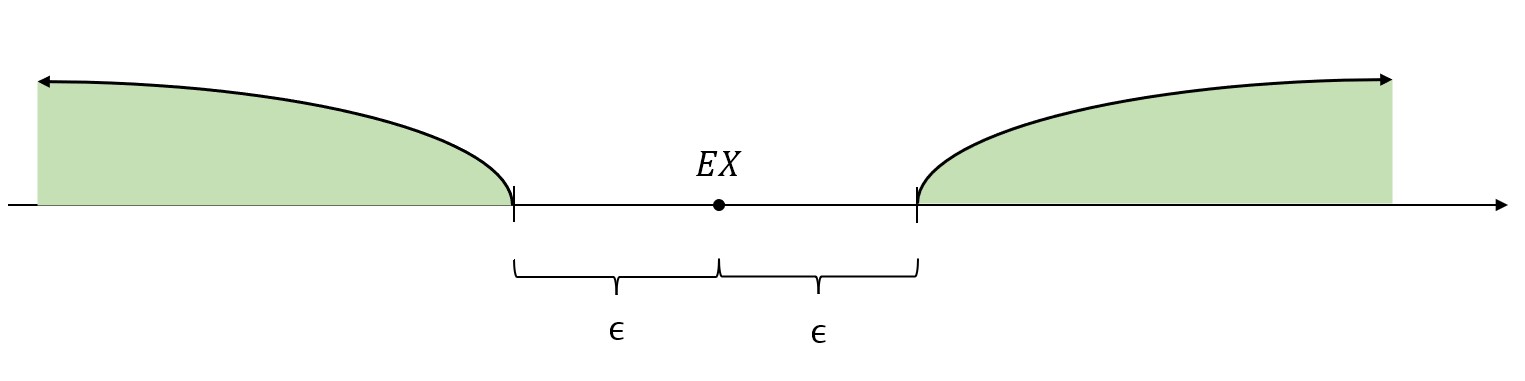
\(|X-EX|\)可以理解为随机取一个点,这个点到\(EX\)的距离。
那么\(P\{|X-EX|\ge \epsilon\}\),就表示随机取一个点,这个点到\(EX\)的距离大于指定的\(\epsilon\)的概率。也就是上图中随机取的点落在绿色区域的概率。
\(EX\)是\(X\)的“中心点”,\(X\)的取值大多数都围绕在\(EX\)不远处。因此,落在“外面”的点是比较少的,落在“外面”的概率是比较小的,并且通过上面的放缩证明,这个概率是小于\(\frac{DX}{\epsilon^2}\)的。
可以看出,概率大小与\(DX\)的正相关关系以及和\(\epsilon\)的负相关关系是和切比雪夫不等式吻合的。
切比雪夫不等式为
将切比雪夫不等式的范围取反,则可以得到
如果\(a_n\to a\),要求\(\forall \epsilon>0,\exists N>0,n>N时,|a_n-a|<\epsilon\).
理解:对于任意\(\epsilon>0\)在于划定一个非常小的区域,\(\exists N>0\)在于存在某一项,\(n>N\)也就是说这一项后面的所有项\(a_n\),与一个数\(a\)的距离都要小于先前划定的非常小的\(\epsilon\),也就是说\(a_n\to a\).
对于任意\(\epsilon>0\),有
则称\(\{X_n\}\)依概率收敛到\(X\),记作\(X_n\stackrel{P}{\longrightarrow}X\)或\(P-\lim\limits_{n\to\infty}X_n=X\).
理解:依概率收敛没有上面的收敛那么严格,它并不要求当\(n>N\)时,\(|X_n-X|<\epsilon\)恒成立。只是要求当\(n\)足够大时,\(|X_n-X|<\epsilon\)的概率为1。从数轴上理解就是:前者要求\(n>N\)的所有数都落在狭小的范围内,而依概率收敛只要求最终的概率为1,可以偶尔有几个点是落在狭小区域外面。
在\(n\)次试验中事件\(A\)发生的次数记为\(\mu_n\),发生的频率为\(\frac{\mu_n}{n}\)。\(\mu_n\)和\(\frac{\mu_n}{n}\)都是随机变量。
\(n\)重伯努利试验中,事件\(A\)发生了\(\mu_n\)次,频率为\(\frac{\mu_n}{n}\),频率依概率收敛于事件\(A\)发生的概率\(p\).
因为\(\mu_n\sim B(n,p)\),
所以
\(n\)为常数,结合数学期望和方差的相关性质,有
根据切比雪夫不等式(对应的随机变量\(X\)是\(\frac{\mu_n}{n}\)),对于任意\(\epsilon>0\),有
不等式右边
当\(n\to\infty\)时,\(上式\to1\).
又根据概率的基本性质,\(P\{|\frac{\mu_n}{n}-p|<\epsilon\}\le1\).
所以,\((*)\)式可延伸为
根据夹逼定理,
所以
当\(n\to\infty\)时,\(\frac{\mu_n}{n}\stackrel{P}{\longrightarrow}p\).
也就是说当试验次数很多时,事件发生的频率会依概率收敛于事件发生的概率。
\(X_1,X_2,\cdots,X_n,\cdots\)是一系列不相关的随机变量,\(EX_i\)和\(DX_i\)均存在,方差有界,即\(DX_i\le M\).
对于任意\(\epsilon>0\),有
\(X_1,\cdots,X_n,\cdots\)不相关,所以\(cov(X_i,X_j)=0\).
根据切比雪夫不等式(对应的随机变量\(X\)是\(\frac{1}{n}\sum\limits_{i=1}^nX_i\)),有
这里的\(D(\frac{1}{n}\sum\limits_{i=1}^nX_i)\)前面有负号,所以上式中的\(D(\frac{1}{n}\sum\limits_{i=1}^nX_i)\le\frac{M}{n}\)中的不等符号在这里要转换:
当\(n\to\infty\)时,有
根据夹逼定理,
如果\(X_1,\cdots,X_n,\cdots\)独立同分布,其数学期望和方差都存在,这些随机变量的期望都是\(EX_i=\mu\).
对于任意的\(\epsilon>0\),有
如果\(X_1,\cdots,X_n,\cdots\)独立同分布,随机变量的期望都是\(EX_i=\mu\),方差无要求。
对于任意的\(\epsilon>0\),有
这个定理说明了当试验次数很大时,可以用数据的平均值来估计期望值。
测桌子长度:在测量的过程中误差是无法避免的,那么可以多次测量求平均值,并且用该平均值来估计期望值(桌子的实际长度)。
大量独立同分布的变量之和的极限分布是正态分布。
\(X_1,\cdots,X_n,\cdots\)独立同分布(不管什么分布都行),\(EX_i=\mu,DX_i=\sigma^2\),\(0<\sigma^2<+\infty\)。
大量独立同分布的变量之和标准化之后的极限分布就是标准正态分布。
补充说明
设变量之和为\(Y=\sum\limits_{i=1}^nX_i\),则\(EY=E\sum\limits_{i=1}^nX_i=n\mu,DY=D(\sum\limits_{i=1}^nX_i)=\sum\limits_{i=1}^nDX_i=n\sigma^2\).
变量之和标准化之后:
\(Y_n\sim B(n,p)\)
其中
\(EX_i=p,\ DX_i=p(1-p)\)
也就是说只要把林德伯格-列维中心极限定理中的数学期望和方差进行替换,就可以得到棣莫弗-拉普拉斯中心极限定理.
结论:二项分布可以用正态分布去近似。
当\(n\)较大时,二项分布的计算量是非常大的。
而正态分布的计算可以查表。
参考值:
使用教材:
《概率论与数理统计》第四版 中国人民大学 龙永红 主编 高等教育出版社
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
如果使用Marshal.dump写入文件,我有一个Ruby散列达到大约10兆字节。gzip压缩后约为500KB。在ruby中迭代和改变这个散列是非常快的(几分之一毫秒)。即使复制它也非常快。问题是我需要在RubyonRails进程之间共享此散列中的数据。为了使用Rails缓存(file_store或memcached)执行此操作,我需要先Marshal.dump文件,但这会在序列化文件时产生1000毫秒的延迟,在序列化文件时产生400毫秒的延迟。理想情况下,我希望能够在100毫秒内从每个进程保存和加载此哈希。一个想法是生成一个新的Ruby进程来保存这个散列,该散列为其他进程提供AP
文章目录概述背景为何要存算分离优势**应用场景**存算分离产品技术流派华为JuiceFSHashDataXSKY概述背景Hadoop一出生就是奔存算一体设计,当时设计思想就是存储不动而计算(code也即是代码程序)动,负责调度Yarn会把计算任务尽量发到要处理数据所在的实例上,这也是与传统集中式存储最大的不同。为何当时Hadoop设计存算一体的耦合?要知道2006年服务器带宽只有100Mb/s~1Gb/s,但是HDD也即是磁盘吞吐量有50MB/s,这样带宽远远不够传输数据,网络瓶颈尤为明显,无奈之举只好把计算任务发到数据所在的位置。众观历史常言道天下分久必合合久必分,随着云计算技术的发展,数据
目录:一、简介二、HQL的执行流程三、索引四、索引案例五、Hive常用DDL操作六、Hive常用DML操作七、查询结果插入到表八、更新和删除操作九、查询结果写出到文件系统十、HiveCLI和Beeline命令行的基本使用十一、Hive配置一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。特点:简单、容易上手(提供了类似sql的查询语言hql),使得精通sql但是不了解Java编程的人也能很好地进行大数据分析;灵活性高,可以自定义用户函数(UDF)和
TCP是面向连接的协议,连接的建立和释放是每一次面向连接的通信中必不可少的过程。TCP连接的管理就是使连接的建立和释放都能正常地进行。三次握手TCP连接的建立—三次握手建立TCP连接①若主机A中运行了一个客户进程,当它需要主机B的服务时,就发起TCP连接请求,并在所发送的分段中用SYN=1表示连接请求,并产生一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x。主机B收到A的连接请求报文,就完成了第一次握手。客户端发送SYN=1表示连接请求客户端发送一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x②主机B如果同意建立连接,则向主机A发送确认报
VXLAN简介定义RFC定义了VLAN扩展方案VXLAN(VirtualeXtensibleLocalAreaNetwork,虚拟扩展局域网)。VXLAN采用MACinUDP(UserDatagramProtocol)封装方式,是NVO3(NetworkVirtualizationoverLayer3)中的一种网络虚拟化技术。目的随着网络技术的发展,云计算凭借其在系统利用率高、人力/管理成本低、灵活性/可扩展性强等方面表现出的优势,已经成为目前企业IT建设的新趋势。而服务器虚拟化作为云计算的核心技术之一,得到了越来越多的应用。服务器虚拟化技术的广泛部署,极大地增加了数据中心的计算密度;同时,为
我试图删除括号内的文本(连同括号本身),但遇到括号内有括号的情况时遇到问题。这是我正在使用的方法(在Ruby中):sentence.gsub(/\(.*?\)/,"")在我写出如下句子之前一切正常:"Thisis(atest(string))"然后上面就噎住了。任何人都知道如何做到这一点?我完全被难住了。 最佳答案 一种方法是从内向外替换括号组:x=string.dupwhilex.gsub!(/\([^()]*\)/,"");endx 关于ruby-删除括号内的文本(括号内的括号概率)
我有一些代码可以根据加权随机数提供内容。权重越大的东西越有可能被随机选择。现在作为一名优秀的rubyist,我当然想用测试覆盖所有这些代码。我想测试是否根据正确的概率获取了东西。那么我该如何测试呢?为应该是随机的东西创建测试使得很难比较实际与预期。我有一些想法,以及为什么它们不会很好地工作:在我的测试中stubKernel.rand以返回固定值。这很酷,但是rand()被调用了多次,我不确定我是否可以通过足够的控制来装备它来测试我需要的东西。多次获取随机项目,并将实际比率与预期比率进行比较。但除非我可以无限次地运行它,否则这永远不会完美,并且如果我在RNG中运气不佳,可能会间歇性地