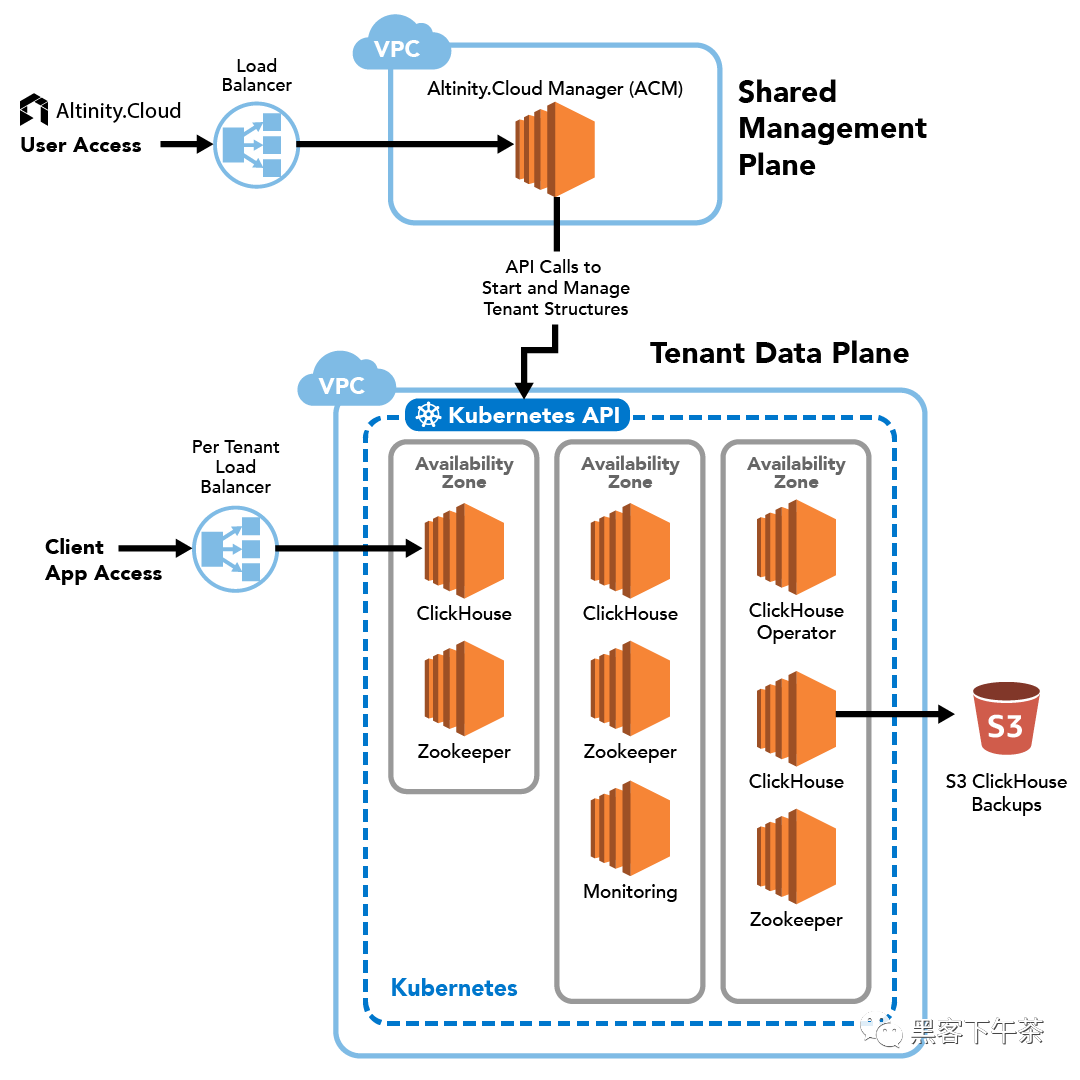
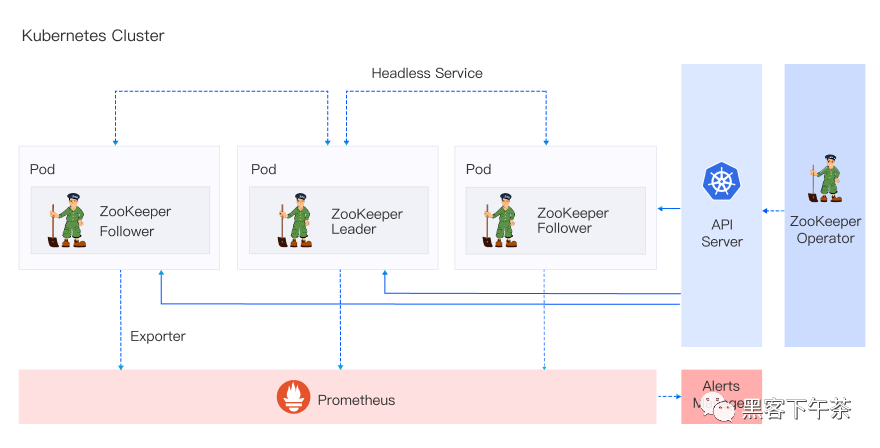
 SaaS 模式交付给用户
SaaS 模式交付给用户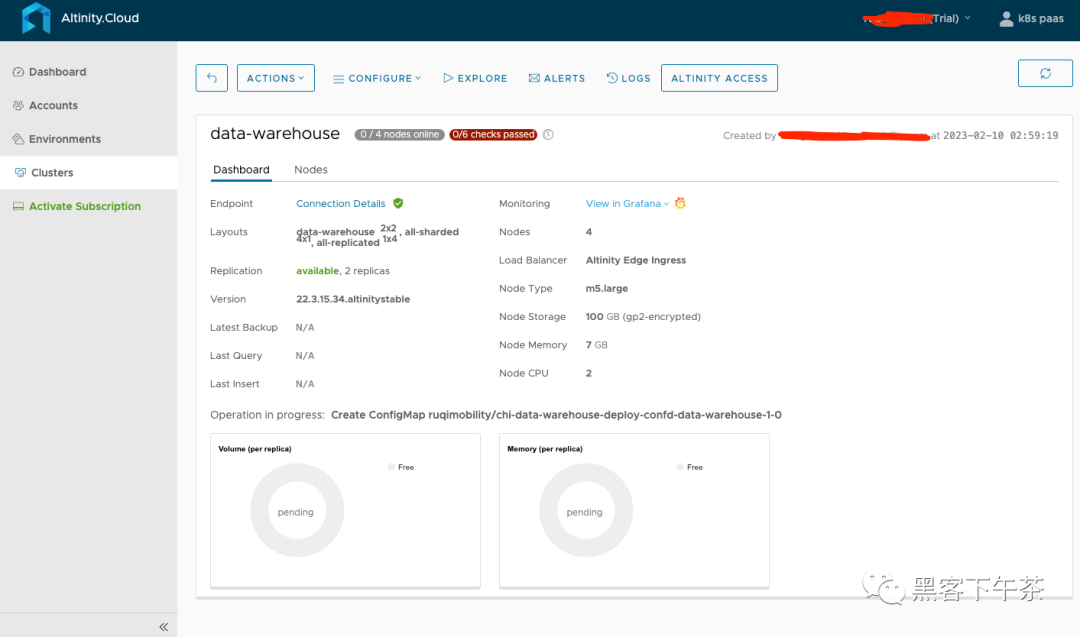 Sentry Snuba 事件大数据分析引擎架构概览Snuba 是一个在 Clickhouse 基础上提供丰富数据模型、快速摄取消费者和查询优化器的服务。以搜索和提供关于 Sentry 事件数据的聚合引擎。数据完全存储在 Clickhouse 表和物化视图中,它通过输入流(目前只有 Kafka 主题)摄入,可以通过时间点查询或流查询(订阅)进行查询。
Sentry Snuba 事件大数据分析引擎架构概览Snuba 是一个在 Clickhouse 基础上提供丰富数据模型、快速摄取消费者和查询优化器的服务。以搜索和提供关于 Sentry 事件数据的聚合引擎。数据完全存储在 Clickhouse 表和物化视图中,它通过输入流(目前只有 Kafka 主题)摄入,可以通过时间点查询或流查询(订阅)进行查询。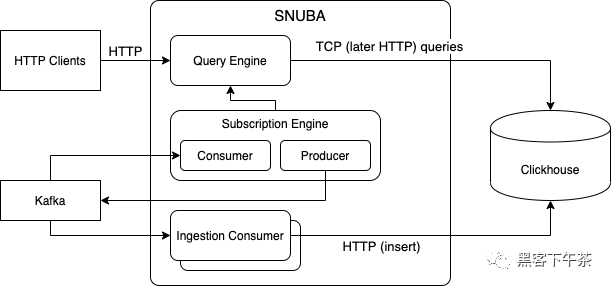 文档:https://getsentry.github.io/snuba/architecture/overview.html
文档:https://getsentry.github.io/snuba/architecture/overview.html# operator 监控集群所有 namespace 的 clickhouse 部署
watchAllNamespaces: true
# 启用 operator 指标监控
enablePrometheusMonitor: truecd vip-k8s-paas/10-cloud-native-clickhouse
# 部署在 kube-system
helm install clickhouse-operator ./clickhouse-operator -f values.operator.yaml -n kube-system
kubectl -n kube-system get po | grep clickhouse-operator
# clickhouse-operator-6457c6dcdd-szgpd 1/1 Running 0 3m33s
kubectl -n kube-system get svc | grep clickhouse-operator
# clickhouse-operator-metrics ClusterIP 10.110.129.244 <none> 8888/TCP 4m18s
kubectl api-resources | grep clickhouse
# clickhouseinstallations chi clickhouse.radondb.com/v1 true ClickHouseInstallation
# clickhouseinstallationtemplates chit clickhouse.radondb.com/v1 true ClickHouseInstallationTemplate
# clickhouseoperatorconfigurations chopconf clickhouse.radondb.com/v1 true ClickHouseOperatorConfigurationclickhouse:
clusterName: snuba-clickhouse-nodes
shardscount: 2
replicascount: 2
...
zookeeper:
install: true
replicas: 3kubectl create ns cloud-clickhouse
helm install clickhouse ./clickhouse-cluster -f values.cluster.yaml -n cloud-clickhouse
kubectl get po -n cloud-clickhouse
# chi-clickhouse-snuba-ck-nodes-0-0-0 3/3 Running 5 (6m13s ago) 16m
# chi-clickhouse-snuba-ck-nodes-0-1-0 3/3 Running 1 (5m33s ago) 6m23s
# chi-clickhouse-snuba-ck-nodes-1-0-0 3/3 Running 1 (4m58s ago) 5m44s
# chi-clickhouse-snuba-ck-nodes-1-1-0 3/3 Running 1 (4m28s ago) 5m10s
# zk-clickhouse-0 1/1 Running 0 17m
# zk-clickhouse-1 1/1 Running 0 17m
# zk-clickhouse-2 1/1 Running 0 17mkubectl edit chi/clickhouse -n cloud-clickhousekubectl get po -n cloud-clickhouse
# NAME READY STATUS RESTARTS AGE
# chi-clickhouse-snuba-ck-nodes-0-0-0 3/3 Running 5 (24m ago) 34m
# chi-clickhouse-snuba-ck-nodes-0-1-0 3/3 Running 1 (23m ago) 24m
# chi-clickhouse-snuba-ck-nodes-1-0-0 3/3 Running 1 (22m ago) 23m
# chi-clickhouse-snuba-ck-nodes-1-1-0 3/3 Running 1 (22m ago) 23m
# chi-clickhouse-snuba-ck-nodes-2-0-0 3/3 Running 1 (108s ago) 2m33s
# chi-clickhouse-snuba-ck-nodes-2-1-0 3/3 Running 1 (72s ago) 119s
# zk-clickhouse-0 1/1 Running 0 35m
# zk-clickhouse-1 1/1 Running 0 35m
# zk-clickhouse-2 1/1 Running 0 35mkubectl exec -it chi-clickhouse-snuba-ck-nodes-0-0-0 -n cloud-clickhouse -- bash
kubectl exec -it chi-clickhouse-snuba-ck-nodes-0-1-0 -n cloud-clickhouse -- bash
kubectl exec -it chi-clickhouse-snuba-ck-nodes-1-0-0 -n cloud-clickhouse -- bash
kubectl exec -it chi-clickhouse-snuba-ck-nodes-1-1-0 -n cloud-clickhouse -- bash
kubectl exec -it chi-clickhouse-snuba-ck-nodes-2-0-0 -n cloud-clickhouse -- bash
kubectl exec -it chi-clickhouse-snuba-ck-nodes-2-1-0 -n cloud-clickhouse -- bashclickhouse-client --multiline -u username -h ip --password passowrd
# clickhouse-client -mselect * from system.clusters;create database test on cluster 'snuba-ck-nodes';
# 删除:drop database test on cluster 'snuba-ck-nodes';show databases;CREATE TABLE test.t_local on cluster 'snuba-ck-nodes'
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test/t_local', '{replica}')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID);kubectl get configmap -n cloud-clickhouse | grep clickhouse
NAME DATA AGE
chi-clickhouse-common-configd 6 20h
chi-clickhouse-common-usersd 6 20h
chi-clickhouse-deploy-confd-snuba-ck-nodes-0-0 2 20h
chi-clickhouse-deploy-confd-snuba-ck-nodes-0-1 2 20h
chi-clickhouse-deploy-confd-snuba-ck-nodes-1-0 2 20h
chi-clickhouse-deploy-confd-snuba-ck-nodes-1-1 2 20h
chi-clickhouse-deploy-confd-snuba-ck-nodes-2-0 2 19h
chi-clickhouse-deploy-confd-snuba-ck-nodes-2-1 2 19hkubectl describe configmap chi-clickhouse-deploy-confd-snuba-ck-nodes-0-0 -n cloud-clickhouseCREATE TABLE test.t_dist on cluster 'snuba-ck-nodes'
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
)
ENGINE = Distributed('snuba-ck-nodes', test, t_local, rand());
# drop table test.t_dist on cluster 'snuba-ck-nodes';use test;
show tables;
# t_dist
# t_local# 插入
INSERT INTO test.t_dist VALUES ('2022-12-16 00:00:00', 1, 1),('2023-01-01 00:00:00',2, 2),('2023-02-01 00:00:00',3, 3);select * from test.t_dist;apiVersion: v2
appVersion: 22.11.0
dependencies:
- condition: sourcemaps.enabled
name: memcached
repository: https://charts.bitnami.com/bitnami
version: 6.1.5
- condition: redis.enabled
name: redis
repository: https://charts.bitnami.com/bitnami
version: 16.12.1
- condition: kafka.enabled
name: kafka
repository: https://charts.bitnami.com/bitnami
version: 16.3.2
- condition: clickhouse.enabled
name: clickhouse
repository: https://sentry-kubernetes.github.io/charts
version: 3.2.0
- condition: zookeeper.enabled
name: zookeeper
repository: https://charts.bitnami.com/bitnami
version: 9.0.0
- alias: rabbitmq
condition: rabbitmq.enabled
name: rabbitmq
repository: https://charts.bitnami.com/bitnami
version: 8.32.2
- condition: postgresql.enabled
name: postgresql
repository: https://charts.bitnami.com/bitnami
version: 10.16.2
- condition: nginx.enabled
name: nginx
repository: https://charts.bitnami.com/bitnami
version: 12.0.4
description: A Helm chart for Kubernetes
maintainers:
- name: sentry-kubernetes
name: sentry
type: application
version: 17.9.0kubectl create ns cloud-zookeeper-paas# 暴露下 prometheus 监控所需的服务
metrics:
containerPort: 9141
enabled: true
....
....
service:
annotations: {}
clusterIP: ""
disableBaseClientPort: false
externalTrafficPolicy: Cluster
extraPorts: []
headless:
annotations: {}
publishNotReadyAddresses: true
loadBalancerIP: ""
loadBalancerSourceRanges: []
nodePorts:
client: ""
tls: ""
ports:
client: 2181
election: 3888
follower: 2888
tls: 3181
sessionAffinity: None
type: ClusterIPhelm install zookeeper ./zookeeper -f values.yaml -n cloud-zookeeper-paasexport POD_NAME=$(kubectl get pods --namespace cloud-zookeeper-paas -l "app.kubernetes.io/name=zookeeper,app.kubernetes.io/instance=zookeeper,app.kubernetes.io/compnotallow=zookeeper" -o jsnotallow="{.items[0].metadata.name}")
kubectl -n cloud-zookeeper-paas exec -it $POD_NAME -- zkCli.sh
# test
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /zookeeper
[config, quota]
[zk: localhost:2181(CONNECTED) 2] quit
# 外部访问
# kubectl port-forward --namespace cloud-zookeeper-paas svc/zookeeper 2181: & zkCli.sh 127.0.0.1:2181kubectl -n cloud-zookeeper-paas exec -it $POD_NAME -- cat /opt/bitnami/zookeeper/conf/zoo.cfg# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/bitnami/zookeeper/data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# https://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
autopurge.purgeInterval=0
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpHost=0.0.0.0
metricsProvider.httpPort=9141
metricsProvider.exportJvmInfo=true
preAllocSize=65536
snapCount=100000
maxCnxns=0
recnotallow=false
quorumListenOnAllIPs=false
4lw.commands.whitelist=srvr, mntr, ruok
maxSessinotallow=40000
admin.serverPort=8080
admin.enableServer=true
server.1=zookeeper-0.zookeeper-headless.cloud-zookeeper-paas.svc.cluster.local:2888:3888;2181
server.2=zookeeper-1.zookeeper-headless.cloud-zookeeper-paas.svc.cluster.local:2888:3888;2181
server.3=zookeeper-2.zookeeper-headless.cloud-zookeeper-paas.svc.cluster.local:2888:3888;2181kubectl create ns cloud-clickhouse-paasserver.1=zookeeper-0.zookeeper-headless.cloud-zookeeper-paas.svc.cluster.local:2888:3888;2181
server.2=zookeeper-1.zookeeper-headless.cloud-zookeeper-paas.svc.cluster.local:2888:3888;2181
server.3=zookeeper-2.zookeeper-headless.cloud-zookeeper-paas.svc.cluster.local:2888:3888;2181# 修改 zookeeper_servers
clickhouse:
configmap:
zookeeper_servers:
config:
- hostTemplate: 'zookeeper-0.zookeeper-headless.cloud-zookeeper-paas.svc.cluster.local'
index: clickhouse
port: "2181"
- hostTemplate: 'zookeeper-1.zookeeper-headless.cloud-zookeeper-paas.svc.cluster.local'
index: clickhouse
port: "2181"
- hostTemplate: 'zookeeper-2.zookeeper-headless.cloud-zookeeper-paas.svc.cluster.local'
index: clickhouse
port: "2181"
enabled: true
operation_timeout_ms: "10000"
session_timeout_ms: "30000"
# 暴露下 prometheus 监控所需的服务
metrics:
enabled: true# 修改 zookeeper_servers
clickhouse:
configmap:
zookeeper_servers:
config:
- hostTemplate: 'zookeeper.cloud-zookeeper-paas.svc.cluster.local'
index: clickhouse
port: "2181"
enabled: true
operation_timeout_ms: "10000"
session_timeout_ms: "30000"
# 暴露下 prometheus 监控所需的服务
metrics:
enabled: truehelm install clickhouse ./clickhouse -f values.yaml -n cloud-clickhouse-paaskubectl -n cloud-clickhouse-paas exec -it clickhouse-0 -- clickhouse-client --multiline --host="clickhouse-1.clickhouse-headless.cloud-clickhouse-paas"show databases;
select * from system.clusters;
select * from system.zookeeper where path = '/clickhouse';clickhouse-config 1 28h
clickhouse-metrica 1 28h
clickhouse-users 1 28h<yandex>
<path>/var/lib/clickhouse/</path>
<tmp_path>/var/lib/clickhouse/tmp/</tmp_path>
<user_files_path>/var/lib/clickhouse/user_files/</user_files_path>
<format_schema_path>/var/lib/clickhouse/format_schemas/</format_schema_path>
<include_from>/etc/clickhouse-server/metrica.d/metrica.xml</include_from>
<users_config>users.xml</users_config>
<display_name>clickhouse</display_name>
<listen_host>0.0.0.0</listen_host>
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<interserver_http_port>9009</interserver_http_port>
<max_connections>4096</max_connections>
<keep_alive_timeout>3</keep_alive_timeout>
<max_concurrent_queries>100</max_concurrent_queries>
<uncompressed_cache_size>8589934592</uncompressed_cache_size>
<mark_cache_size>5368709120</mark_cache_size>
<timezone>UTC</timezone>
<umask>022</umask>
<mlock_executable>false</mlock_executable>
<remote_servers incl="clickhouse_remote_servers" optinotallow="true" />
<zookeeper incl="zookeeper-servers" optinotallow="true" />
<macros incl="macros" optinotallow="true" />
<builtin_dictionaries_reload_interval>3600</builtin_dictionaries_reload_interval>
<max_session_timeout>3600</max_session_timeout>
<default_session_timeout>60</default_session_timeout>
<disable_internal_dns_cache>1</disable_internal_dns_cache>
<query_log>
<database>system</database>
<table>query_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>
<query_thread_log>
<database>system</database>
<table>query_thread_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_thread_log>
<distributed_ddl>
<path>/clickhouse/task_queue/ddl</path>
</distributed_ddl>
<logger>
<level>trace</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>10</count>
</logger>
</yandex><yandex>
<zookeeper-servers>
<node index="clickhouse">
<host>zookeeper-0.zookeeper-headless.cloud-zookeeper-paas.svc.cluster.local</host>
<port>2181</port>
</node>
<node index="clickhouse">
<host>zookeeper-1.zookeeper-headless.cloud-zookeeper-paas.svc.cluster.local</host>
<port>2181</port>
</node>
<node index="clickhouse">
<host>zookeeper-2.zookeeper-headless.cloud-zookeeper-paas.svc.cluster.local</host>
<port>2181</port>
</node>
<session_timeout_ms>30000</session_timeout_ms>
<operation_timeout_ms>10000</operation_timeout_ms>
<root></root>
<identity></identity>
</zookeeper-servers>
<clickhouse_remote_servers>
<clickhouse>
<shard>
<replica>
<internal_replication>true</internal_replication>
<host>clickhouse-0.clickhouse-headless.cloud-clickhouse-paas.svc.cluster.local</host>
<port>9000</port>
<user>default</user>
<compression>true</compression>
</replica>
</shard>
<shard>
<replica>
<internal_replication>true</internal_replication>
<host>clickhouse-1.clickhouse-headless.cloud-clickhouse-paas.svc.cluster.local</host>
<port>9000</port>
<user>default</user>
<compression>true</compression>
</replica>
</shard>
<shard>
<replica>
<internal_replication>true</internal_replication>
<host>clickhouse-2.clickhouse-headless.cloud-clickhouse-paas.svc.cluster.local</host>
<port>9000</port>
<user>default</user>
<compression>true</compression>
</replica>
</shard>
</clickhouse>
</clickhouse_remote_servers>
<macros>
<replica from_env="HOSTNAME"></replica>
<shard from_env="SHARD"></shard>
</macros>
</yandex><yandex>
</yandex>clickhouse:
enabled: false
zookeeper:
enabled: falseexternalClickhouse:
database: default
host: "clickhouse.cloud-clickhouse-paas.svc.cluster.local"
httpPort: 8123
password: ""
singleNode: false
clusterName: "clickhouse"
tcpPort: 9000
username: defaulthelm install sentry ./sentry -f values.yaml -n sentrykubectl -n cloud-clickhouse-paas exec -it clickhouse-0 -- clickhouse-client --multiline --host="clickhouse-1.clickhouse-headless.cloud-clickhouse-paas"
show databases;
show tables;
select * from system.zookeeper where path = '/clickhouse';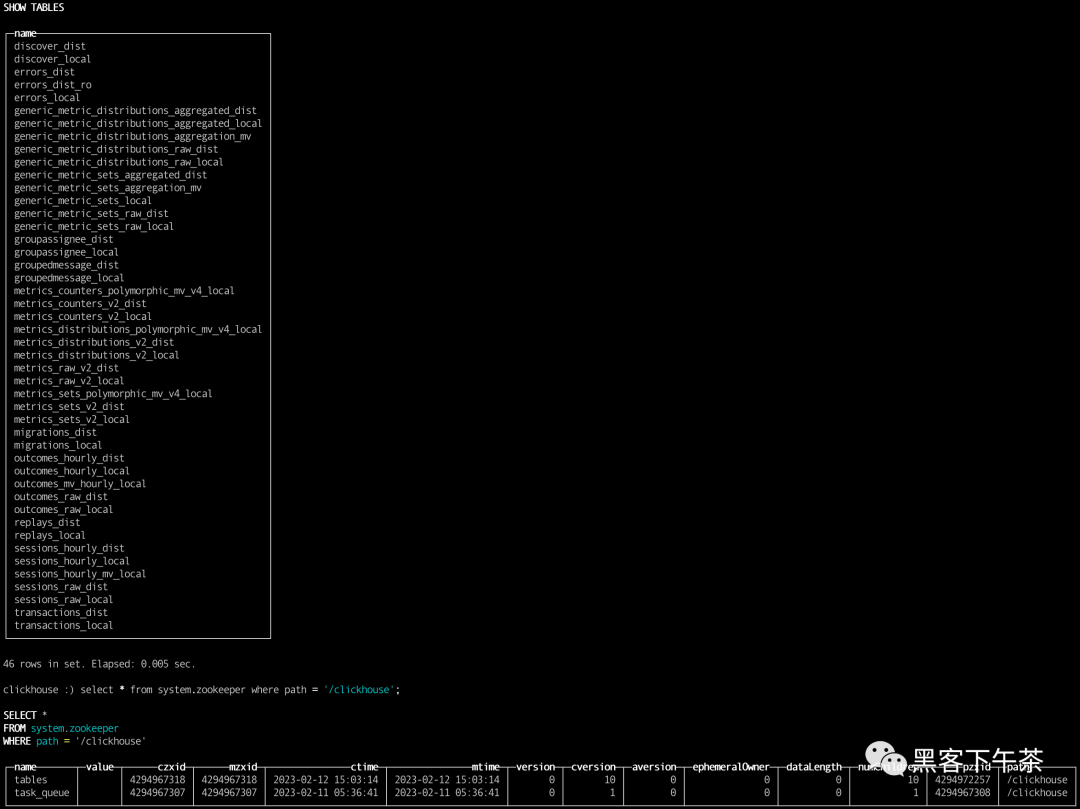
 关于针对 ClickHouse 集群各个分片、副本之间的读写负载均衡、连接池等问题。Snuba 在系统设计、代码层面部分就已经做了充分的考虑以及优化。关于 ClickHouse Operator 独立的多个云原生编排集群以及 Snuba 系统设计等高级部分会在 VIP 专栏直播课单独讲解。
关于针对 ClickHouse 集群各个分片、副本之间的读写负载均衡、连接池等问题。Snuba 在系统设计、代码层面部分就已经做了充分的考虑以及优化。关于 ClickHouse Operator 独立的多个云原生编排集群以及 Snuba 系统设计等高级部分会在 VIP 专栏直播课单独讲解。 是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
我正在尝试将以下SQL查询转换为ActiveRecord,它正在融化我的大脑。deletefromtablewhereid有什么想法吗?我想做的是限制表中的行数。所以,我想删除少于最近10个条目的所有内容。编辑:通过结合以下几个答案找到了解决方案。Temperature.where('id这给我留下了最新的10个条目。 最佳答案 从您的SQL来看,您似乎想要从表中删除前10条记录。我相信到目前为止的大多数答案都会如此。这里有两个额外的选择:基于MurifoX的版本:Table.where(:id=>Table.order(:id).
这是我在ActiveAdmin中的自定义页面ActiveAdmin.register_page"Settings"doaction_itemdolink_to('Importprojects','settings/importprojects')endcontentdopara"Text"endcontrollerdodefimportprojectssystem"rakedataspider:import_projects_ninja"para"OK"endendend我想做的是,当我单击“导入项目”按钮时,我想在Controller中执行rake任务。但是我无法访问该方法。可能是什
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
我有一个将某些事件写入队列的Rails3应用。现在我想在服务器上创建一个服务,每x秒轮询一次队列,并按计划执行其他任务。除了创建ruby脚本并通过cron作业运行它之外,还有其他稳定的替代方案吗? 最佳答案 尽管启动基于Rails的持久任务是一种选择,但您可能希望查看更有序的系统,例如delayed_job或Starling管理您的工作量。我建议不要在cron中运行某些东西,因为启动整个Rails堆栈的开销可能很大。每隔几秒运行一次它是不切实际的,因为Rails上的启动时间通常为5-15秒,具体取决于您的硬件。不过,每天这样做几
我有一个帖子属于城市的关系,城市又属于一个州,例如:classPost现在我想找到所有帖子及其所属的城市和州。我编写了以下查询来获取带有城市的帖子,但不知道如何在同一查找器中获取带有城市的相应州:@post=Post.find:all,:include=>[:city]感谢任何帮助。谢谢。 最佳答案 Post.all(:include=>{:city=>:state}) 关于ruby-on-rails-使用Rails事件记录获取二级模型,我们在StackOverflow上找到一个类似的问
我觉得我错过了什么。我正在编写一个rubygem,它允许与事件记录进行交互,作为其主要功能的附加功能。在为其编写测试用例时,我需要能够指定虚拟事件记录模型来测试此功能。如果我可以获得一个事件记录模型的实例,它不需要与数据库的任何连接,可以有关系,所有这些东西,但不需要我在数据库中设置表,那就太棒了。我对测试还很陌生,在Rails测试之外我也很陌生,但似乎我应该能够相当轻松地完成类似的事情,但我什么也没找到。谁能告诉我我错过了什么?我看过工厂、制造商、固定装置,所有这些似乎都想达到目标。人们如何在您只需要AR对象进行测试的地方测试gem? 最佳答案
我想创建一个模块,为从事件记录库继承的类提供一些通用方法。以下是我们可以实现的两种方式。1)moduleCommentabledefself.extended(base)base.class_evaldoincludeInstanceMethodsextendClassMethodsendendmoduleClassMethodsdeftest_commentable_classmethodputs'testclassmethod'endendmoduleInstanceMethodsdeftest_commentable_instance_methodputs'testinstanc
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.