
 针对这些问题,字节跳动推出了全新版本的 LightSeq GPU 量化训练与推理引擎。支持 Transformer 系列模型的量化训练与推理,并做到了开箱即用,用户友好。LightSeq 快准狠地实现了 int8 精度的量化训练和推理:
针对这些问题,字节跳动推出了全新版本的 LightSeq GPU 量化训练与推理引擎。支持 Transformer 系列模型的量化训练与推理,并做到了开箱即用,用户友好。LightSeq 快准狠地实现了 int8 精度的量化训练和推理: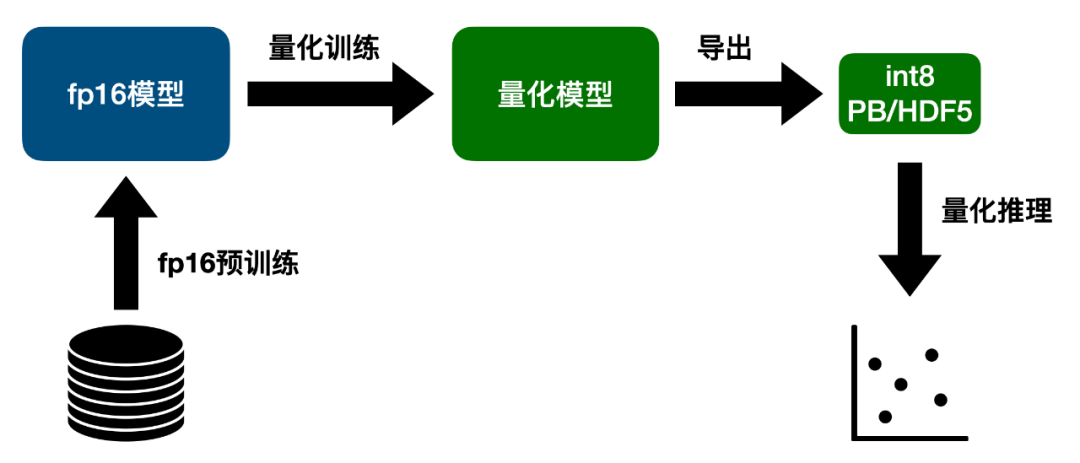 如上图所示,为了最大程度减小量化带来的损失,首先需要用 fp16 精度训练一个浮点数模型,将模型效果训到最好。然后开启量化进行 finetune,得到微调过的量化模型,此时模型效果已经基本恢复到浮点数模型的水平。接着将量化模型转换为 LightSeq 支持的 PB 或者 HDF5 模型格式,最后用 LightSeq 进行量化推理。
如上图所示,为了最大程度减小量化带来的损失,首先需要用 fp16 精度训练一个浮点数模型,将模型效果训到最好。然后开启量化进行 finetune,得到微调过的量化模型,此时模型效果已经基本恢复到浮点数模型的水平。接着将量化模型转换为 LightSeq 支持的 PB 或者 HDF5 模型格式,最后用 LightSeq 进行量化推理。pip install lightseqfrom lightseq.training import LSTransformerEncoderLayerfrom lightseq.training.ops.pytorch.quantization import enable_quant
config = LSTransformerEncoderLayer.get_config( model="bert-base", max_batch_tokens=4096, max_seq_len=512, fp16=True, local_rank=0,)layer = LSTransformerEncoderLayer(config)# 开启量化layer.apply(enable_quant)import lightseq.inference as lsi
model = lsi.QuantTransformer(pb_path, batch_size)result = model.infer(input)from lightseq.training.gradient_comm_quantization import encode_and_decode, GCQStatefrom torch.nn.parallel import DistributedDataParallel
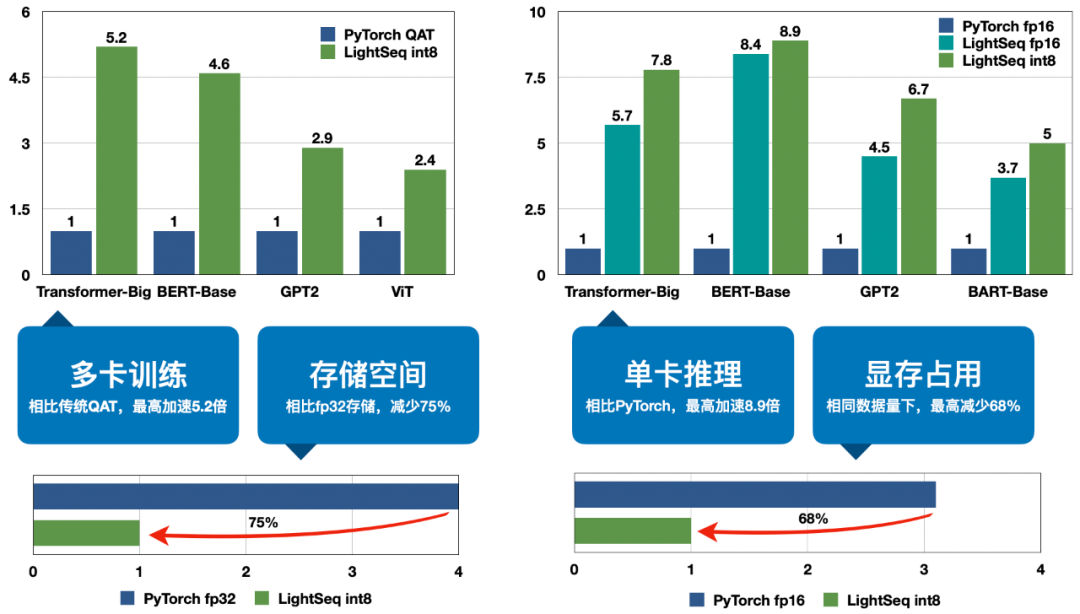
# model could be from Fairseq or Hugging Face, wrapped by DDPmodel = DistributedDataParallel(model)state = GCQState(process_group)# register hookmodel.register_comm_hook(state=state, hook=encode_and_decode)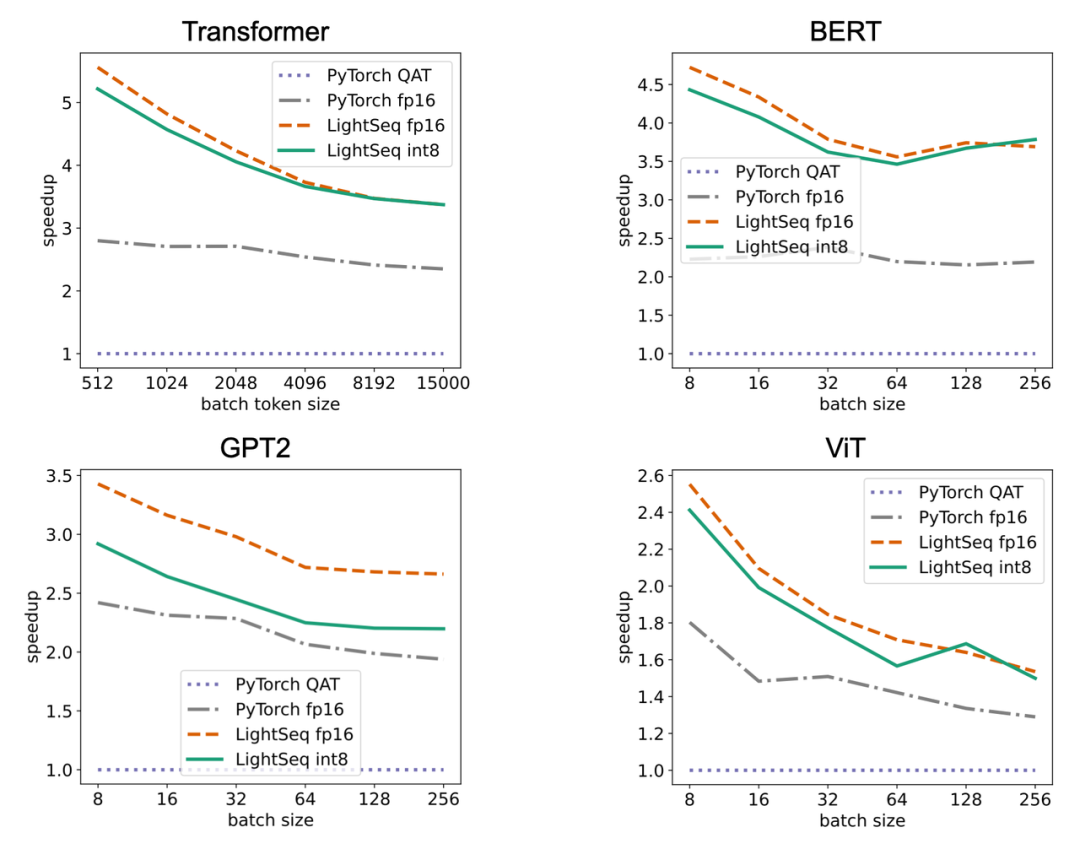 LightSeq 在 8 张 A100 显卡上进行了训练实验,主要对比对象是 Fairseq 的 Transformer、Hugging Face 的 BERT、GPT2 和 ViT。可以看出,四种模型结构加速趋势都是类似的,加速比都会随着数据量的增大而减小,原因有三点:
LightSeq 在 8 张 A100 显卡上进行了训练实验,主要对比对象是 Fairseq 的 Transformer、Hugging Face 的 BERT、GPT2 和 ViT。可以看出,四种模型结构加速趋势都是类似的,加速比都会随着数据量的增大而减小,原因有三点: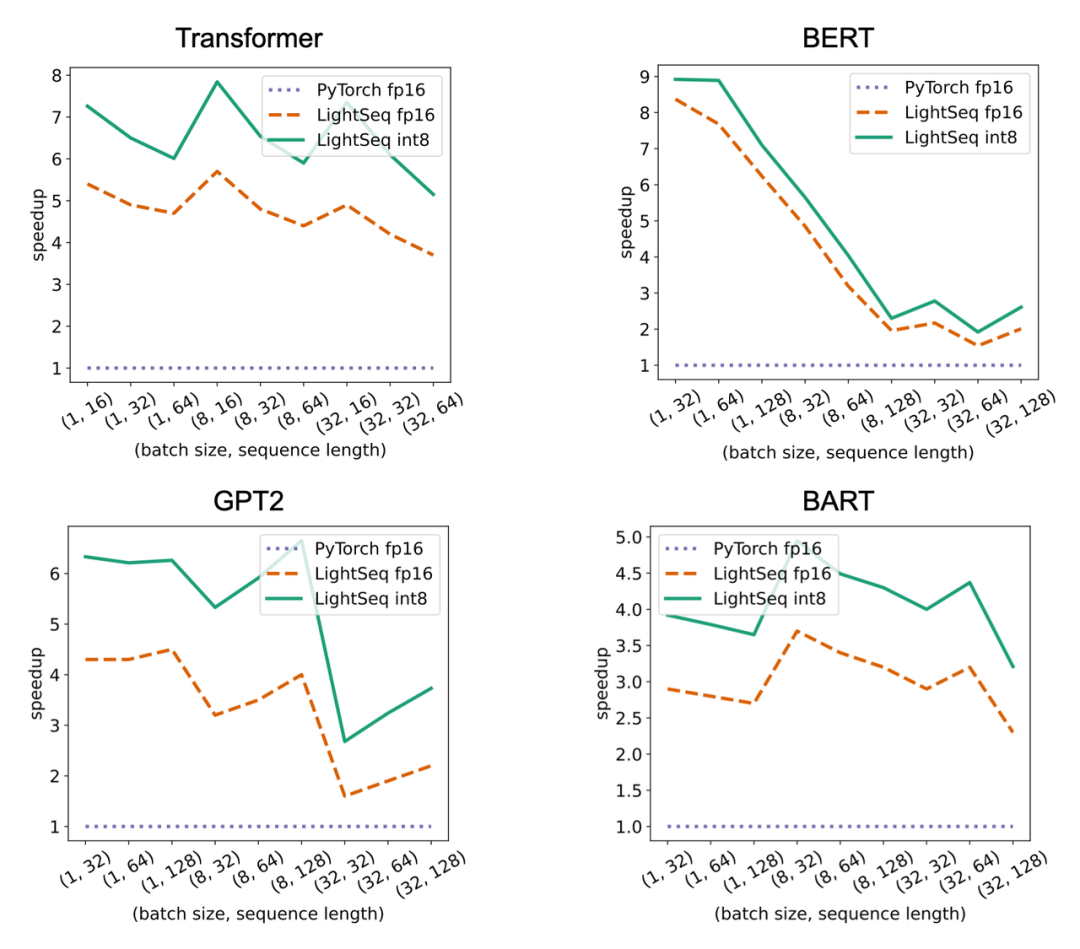 LightSeq 在单张 T4 显卡上进行了推理实验,主要对比对象是 Hugging Face 的 Transformer、BERT、GPT2 和 ViT。可以看出,随着输入数据量的增大,LightSeq 与 PyTorch 的差距会逐渐减小,这也是 GEMM 占比升高造成的。比较 LightSeq fp16 和 LightSeq int8,可以看出随着数据量的增大,LightSeq int8 越来越快。这是因为在 T4 显卡上,int8 GEMM 的加速会随着 shape 的增大而有明显增加。因此在 T4 显卡上进行量化推理时,输入数据量越大,加速效果越好。
LightSeq 在单张 T4 显卡上进行了推理实验,主要对比对象是 Hugging Face 的 Transformer、BERT、GPT2 和 ViT。可以看出,随着输入数据量的增大,LightSeq 与 PyTorch 的差距会逐渐减小,这也是 GEMM 占比升高造成的。比较 LightSeq fp16 和 LightSeq int8,可以看出随着数据量的增大,LightSeq int8 越来越快。这是因为在 T4 显卡上,int8 GEMM 的加速会随着 shape 的增大而有明显增加。因此在 T4 显卡上进行量化推理时,输入数据量越大,加速效果越好。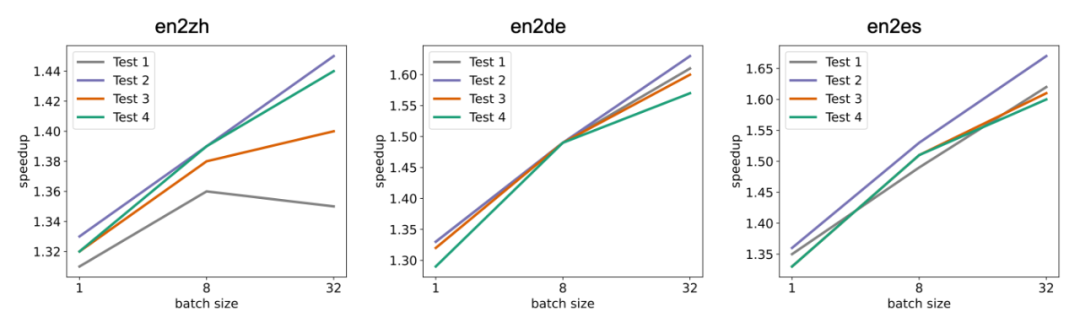 LightSeq 还针对机器翻译多个语向和多个测试集,测试了不同 batch size 下,LightSeq int8 推理相对于 LightSeq fp16 推理的加速比,实验同样是在单张 T4 显卡上进行的,采用的模型都是标准的 Transformer-Big。可以得到和上文中相同的结论,随着 batch size 的增大,量化推理的加速比会逐渐升高。相比于 LightSeq fp16,最高还可以再加速近 70%,这极大地缩短了线上翻译模型的推理延时。
LightSeq 还针对机器翻译多个语向和多个测试集,测试了不同 batch size 下,LightSeq int8 推理相对于 LightSeq fp16 推理的加速比,实验同样是在单张 T4 显卡上进行的,采用的模型都是标准的 Transformer-Big。可以得到和上文中相同的结论,随着 batch size 的增大,量化推理的加速比会逐渐升高。相比于 LightSeq fp16,最高还可以再加速近 70%,这极大地缩短了线上翻译模型的推理延时。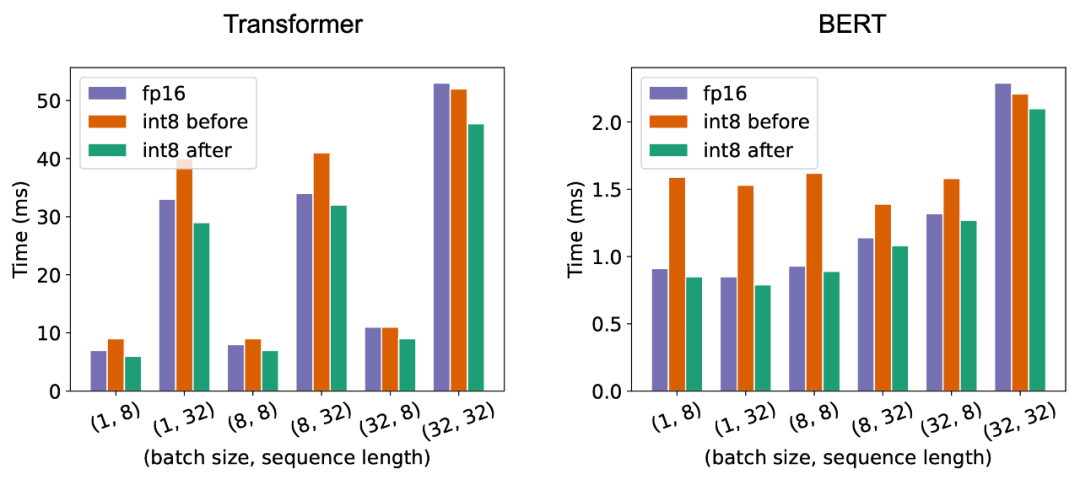 最后如上图所示,为了展示自动 GEMM 调优技术的效果,LightSeq 测试对比了 A100 显卡上 Transformer 和 BERT 模型 fp16、int8 调优前和 int8 调优后的延时。可以看出调优前某些 shape 的 int8 GEMM 速度甚至比 fp16 还要慢,而调优后全面超越了 fp16。
最后如上图所示,为了展示自动 GEMM 调优技术的效果,LightSeq 测试对比了 A100 显卡上 Transformer 和 BERT 模型 fp16、int8 调优前和 int8 调优后的延时。可以看出调优前某些 shape 的 int8 GEMM 速度甚至比 fp16 还要慢,而调优后全面超越了 fp16。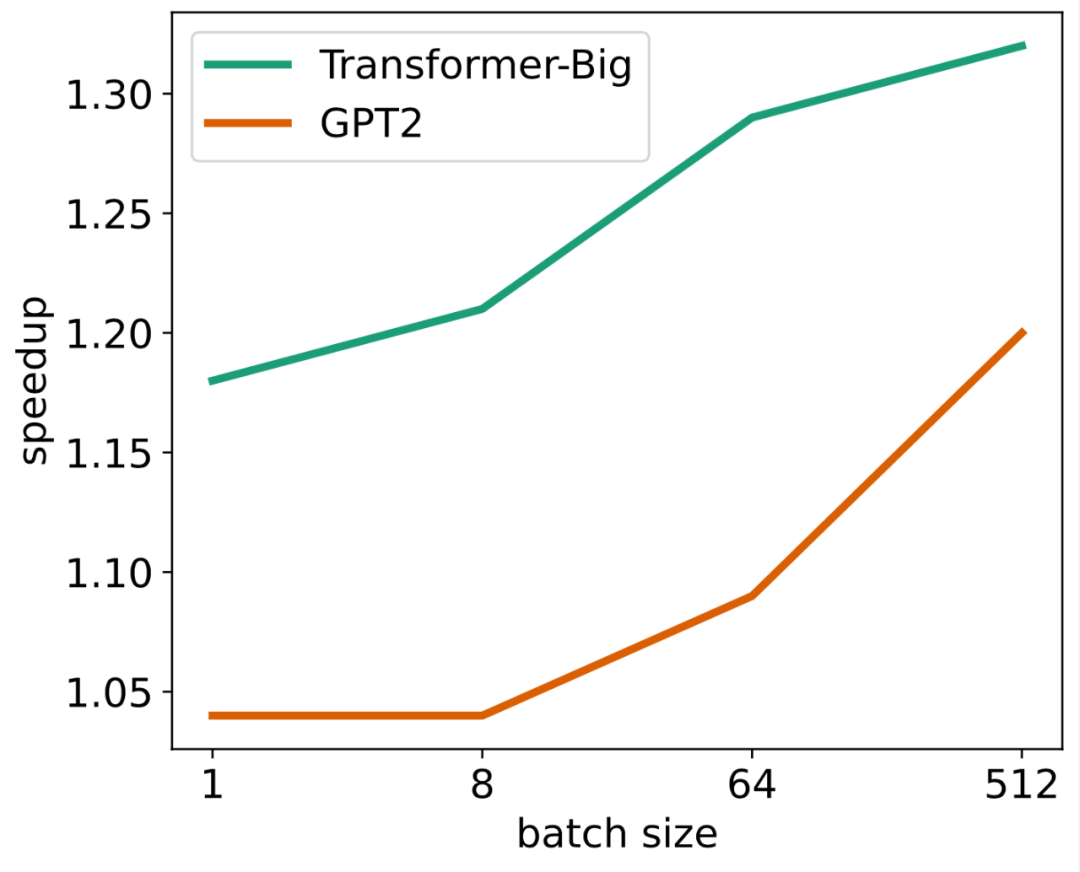 LightSeq 分析了不同 batch size 下,量化模型相对于浮点数模型显存占用的加速比。可以看出随着 batch size 的增大,量化模型的显存占用优势更明显,最高可以减少 30% 左右。而 LightSeq fp16 引擎相对于 PyTorch 模型也极大程度减少了显存占用,因此 LightSeq int8 引擎最终能够减少最多 68% 左右的显存。
LightSeq 分析了不同 batch size 下,量化模型相对于浮点数模型显存占用的加速比。可以看出随着 batch size 的增大,量化模型的显存占用优势更明显,最高可以减少 30% 左右。而 LightSeq fp16 引擎相对于 PyTorch 模型也极大程度减少了显存占用,因此 LightSeq int8 引擎最终能够减少最多 68% 左右的显存。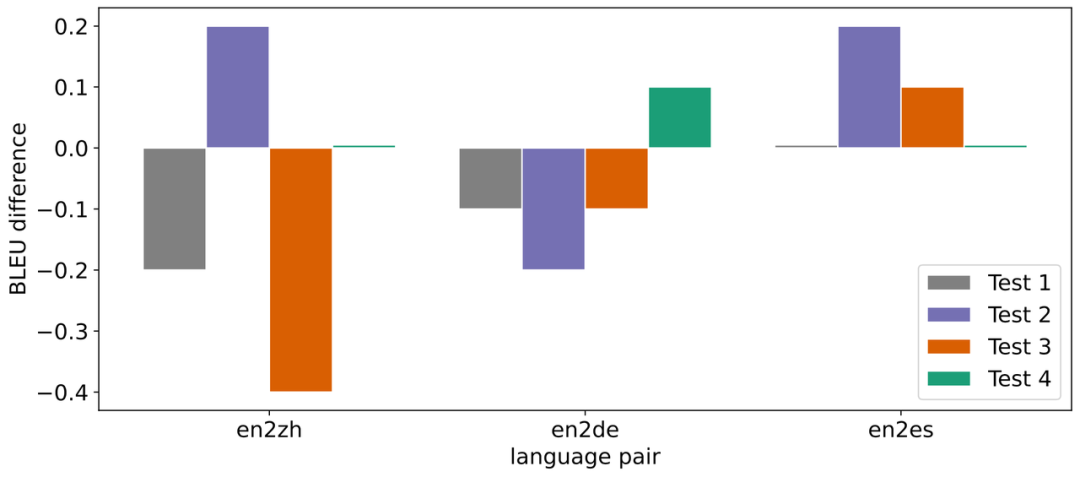 针对机器翻译多个语向和多个测试集,LightSeq 测试了量化模型推理相对于浮点数模型 BLEU 的损失,采用的模型都是标准的 Transformer-Big。在数据量较大的语向 en2zh 上,LightSeq int8 相对 BLEU 损失较大些,最大达到了 - 0.4。而在数据量较小的语向 en2es 上,LightSeq int8 不仅没有任何效果损失,反而比浮点数模型更好。总体而言,int8 量化模型的平均 BLEU 相比浮点数模型基本无损。在 GLUE 和 SQuAD 等多个任务上,LightSeq 也验证了量化模型的效果。
针对机器翻译多个语向和多个测试集,LightSeq 测试了量化模型推理相对于浮点数模型 BLEU 的损失,采用的模型都是标准的 Transformer-Big。在数据量较大的语向 en2zh 上,LightSeq int8 相对 BLEU 损失较大些,最大达到了 - 0.4。而在数据量较小的语向 en2es 上,LightSeq int8 不仅没有任何效果损失,反而比浮点数模型更好。总体而言,int8 量化模型的平均 BLEU 相比浮点数模型基本无损。在 GLUE 和 SQuAD 等多个任务上,LightSeq 也验证了量化模型的效果。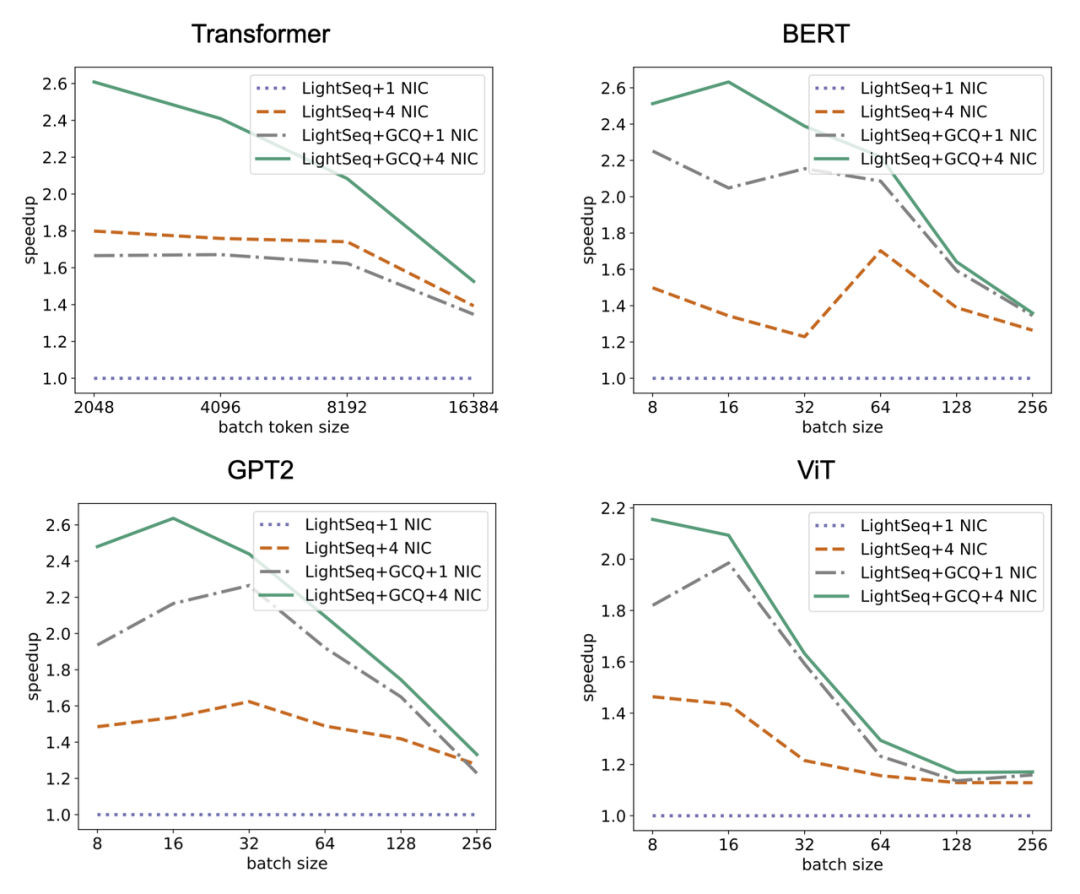 由于在多机多卡场景下通信瓶颈更加明显,所以梯度通信量化主要应用在分布式训练场景。因此 LightSeq 在 2 机 8 卡的 A100 上进行了分布式训练的速度测试。可以看出,梯度通信量化的训练加速效果整体上随着输入数据的增大而减弱。这主要是因为随着输入数据的增大,计算时间占比升高,梯度通信时间占比减少,梯度量化的收益也随之减小。LightSeq 还额外增加了不同数量网卡(NIC)下的训练速度测试。可以看到使用梯度通信量化的分布式训练速度相比原始的 LightSeq fp16 有大幅度提升。
由于在多机多卡场景下通信瓶颈更加明显,所以梯度通信量化主要应用在分布式训练场景。因此 LightSeq 在 2 机 8 卡的 A100 上进行了分布式训练的速度测试。可以看出,梯度通信量化的训练加速效果整体上随着输入数据的增大而减弱。这主要是因为随着输入数据的增大,计算时间占比升高,梯度通信时间占比减少,梯度量化的收益也随之减小。LightSeq 还额外增加了不同数量网卡(NIC)下的训练速度测试。可以看到使用梯度通信量化的分布式训练速度相比原始的 LightSeq fp16 有大幅度提升。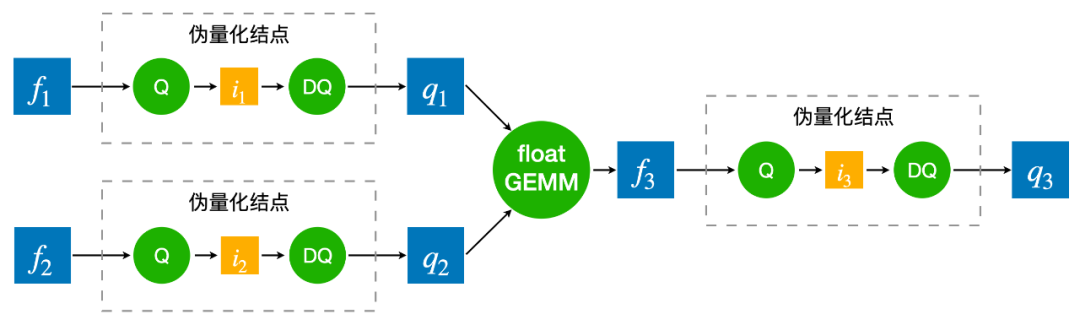 为了弥补量化带来的精度损失,通常需要用量化感知训练来模拟量化过程。如上图所示,量化感知训练就是将 float GEMM 的两个 float 输入分别做一遍量化和反量化(称之为伪量化结点),离散化成分段的浮点数输入,然后进行 float GEMM 运算。得到结果后再次进行量化与反量化,得到最终的浮点数结果。而量化的过程是不可导的,因此需要用 STE 方法来估计量化参数的梯度。之所以量化感知训练中需要插入伪量化结点,然后用 float GEMM 去模拟量化过程,是因为 TensorFlow 和 PyTorch 等训练框架不支持 int8 GEMM。
为了弥补量化带来的精度损失,通常需要用量化感知训练来模拟量化过程。如上图所示,量化感知训练就是将 float GEMM 的两个 float 输入分别做一遍量化和反量化(称之为伪量化结点),离散化成分段的浮点数输入,然后进行 float GEMM 运算。得到结果后再次进行量化与反量化,得到最终的浮点数结果。而量化的过程是不可导的,因此需要用 STE 方法来估计量化参数的梯度。之所以量化感知训练中需要插入伪量化结点,然后用 float GEMM 去模拟量化过程,是因为 TensorFlow 和 PyTorch 等训练框架不支持 int8 GEMM。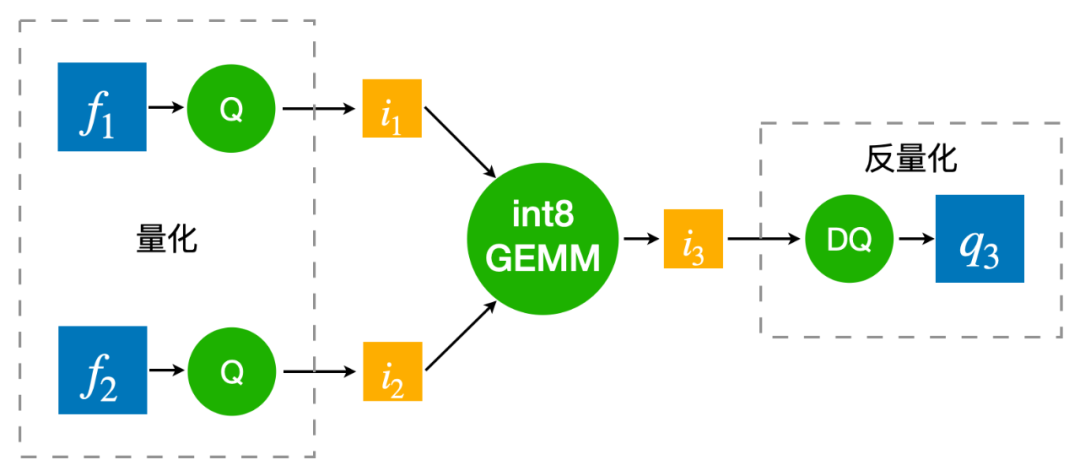 而 LightSeq 量化训练直接采用 int8 GEMM 来真实还原量化过程,因此相比传统的实现要更快,且更加节省显存。在推理的时候,同样采用离散化后的整数进行 int8 GEMM 运算,最后再反量化回浮点数结果。量化推理过程和量化训练完全一致,并且和传统的量化感知训练是完全等价的。
而 LightSeq 量化训练直接采用 int8 GEMM 来真实还原量化过程,因此相比传统的实现要更快,且更加节省显存。在推理的时候,同样采用离散化后的整数进行 int8 GEMM 运算,最后再反量化回浮点数结果。量化推理过程和量化训练完全一致,并且和传统的量化感知训练是完全等价的。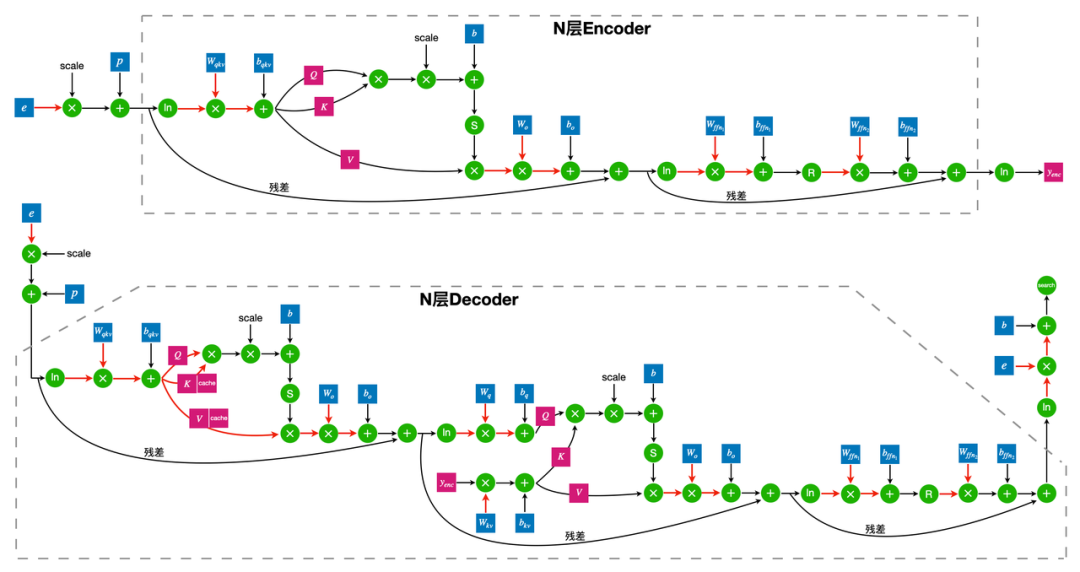 整个量化 Transformer 的网络结构如上图所示,红色箭头表示需要加上量化和反量化结点的位置。首先所有 int8 GEMM 的输入和输出都需要进行量化。由于 int8 GEMM 的 shape 限制,部分 GEMM(例如注意力分数的计算)仍然采用 float GEMM。此外第二层 FFN 的 GEMM 采用的是 int32 的输出,因为它的 GEMM 输入是 ReLU 激活函数的输出结果,只包含正数,非对称,因此如果采用 int8 输出的 GEMM,将无法反量化为正确的浮点数结果。然后所有的模型权重 weight 都需要存储为 int8 类型,因此需要对 weight 做量化。而权重 bias 参数量较小,无需量化,保留 float 精度反而可以提升模型效果。最后需要对 decoder 端的 cache 进行量化。因为在推理时,decoder 端的 cache 需要频繁进行读写,因此将 cache 量化为 int8 可以大大加快解码的速度。
整个量化 Transformer 的网络结构如上图所示,红色箭头表示需要加上量化和反量化结点的位置。首先所有 int8 GEMM 的输入和输出都需要进行量化。由于 int8 GEMM 的 shape 限制,部分 GEMM(例如注意力分数的计算)仍然采用 float GEMM。此外第二层 FFN 的 GEMM 采用的是 int32 的输出,因为它的 GEMM 输入是 ReLU 激活函数的输出结果,只包含正数,非对称,因此如果采用 int8 输出的 GEMM,将无法反量化为正确的浮点数结果。然后所有的模型权重 weight 都需要存储为 int8 类型,因此需要对 weight 做量化。而权重 bias 参数量较小,无需量化,保留 float 精度反而可以提升模型效果。最后需要对 decoder 端的 cache 进行量化。因为在推理时,decoder 端的 cache 需要频繁进行读写,因此将 cache 量化为 int8 可以大大加快解码的速度。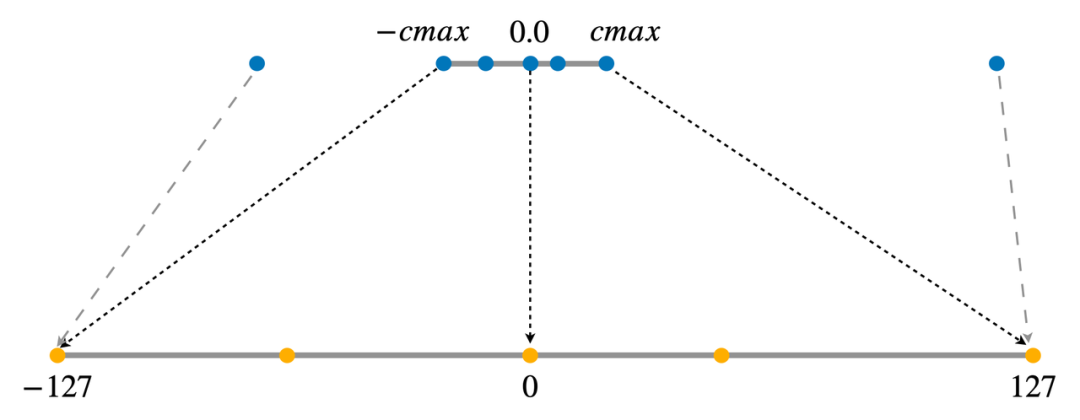 将一个浮点数矩阵量化为 int8 整数矩阵有很多方法,LightSeq 采用的是对称量化,即将正负数范围对称的浮点数区间等比例地映射到整数区间 [-127, 127] 上。而实际上浮点数矩阵的数值范围通常并不对称,存在极少的离群值。如果直接按照离群值的范围来量化矩阵,会影响到量化后的精度,所以需要先对矩阵进行数值截断。LightSeq 采用 PACT 方法进行截断[6],将截断的范围当作模型可学习的参数,然后利用 STE 算法去估计参数的梯度,并进行反向传播优化。根据实践经验,权重 weight 的初始截断范围设为[-1, 1],中间结果的初始截断范围设为[-16, 16],可以在大部分任务上达到最好的效果。最后经过截断范围和其他模型参数的联合优化,量化模型的效果可以达到基本无损。
将一个浮点数矩阵量化为 int8 整数矩阵有很多方法,LightSeq 采用的是对称量化,即将正负数范围对称的浮点数区间等比例地映射到整数区间 [-127, 127] 上。而实际上浮点数矩阵的数值范围通常并不对称,存在极少的离群值。如果直接按照离群值的范围来量化矩阵,会影响到量化后的精度,所以需要先对矩阵进行数值截断。LightSeq 采用 PACT 方法进行截断[6],将截断的范围当作模型可学习的参数,然后利用 STE 算法去估计参数的梯度,并进行反向传播优化。根据实践经验,权重 weight 的初始截断范围设为[-1, 1],中间结果的初始截断范围设为[-16, 16],可以在大部分任务上达到最好的效果。最后经过截断范围和其他模型参数的联合优化,量化模型的效果可以达到基本无损。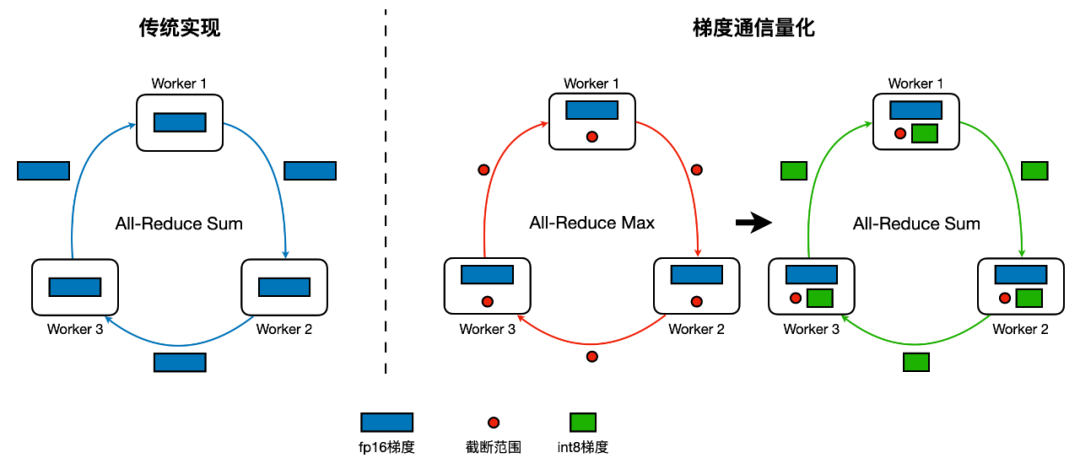 如上图所示,梯度通信量化的主要流程如下:
如上图所示,梯度通信量化的主要流程如下: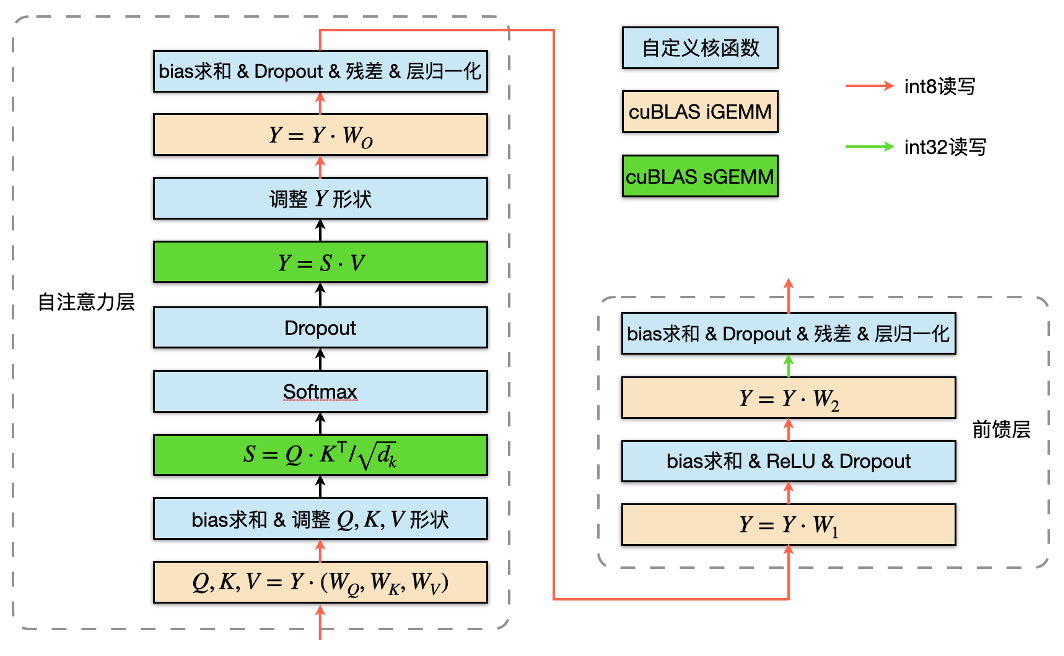 上图是 encoder 模块量化训练的计算图,LightSeq 将两次 GEMM 运算之间的所有操作融合成一个算子[7],减少了 kernel 调用的次数,因此减少了总的计算时间。图中黄色矩形表示 int8 GEMM,绿色矩形表示 float GEMM。这里采用 float GEMM 是由于 shape 的限制,不适合使用 int8 GEMM 加速。红色箭头表示流动数据的类型是 int8,绿色箭头表示第二层 FFN 的 GEMM 输出是 int32 数据类型。int8 GEMM 输入输出的量化与反量化操作都被融合到了前后 kernel 里,这不仅可以减少数据搬运,还可以减小显存占用。
上图是 encoder 模块量化训练的计算图,LightSeq 将两次 GEMM 运算之间的所有操作融合成一个算子[7],减少了 kernel 调用的次数,因此减少了总的计算时间。图中黄色矩形表示 int8 GEMM,绿色矩形表示 float GEMM。这里采用 float GEMM 是由于 shape 的限制,不适合使用 int8 GEMM 加速。红色箭头表示流动数据的类型是 int8,绿色箭头表示第二层 FFN 的 GEMM 输出是 int32 数据类型。int8 GEMM 输入输出的量化与反量化操作都被融合到了前后 kernel 里,这不仅可以减少数据搬运,还可以减小显存占用。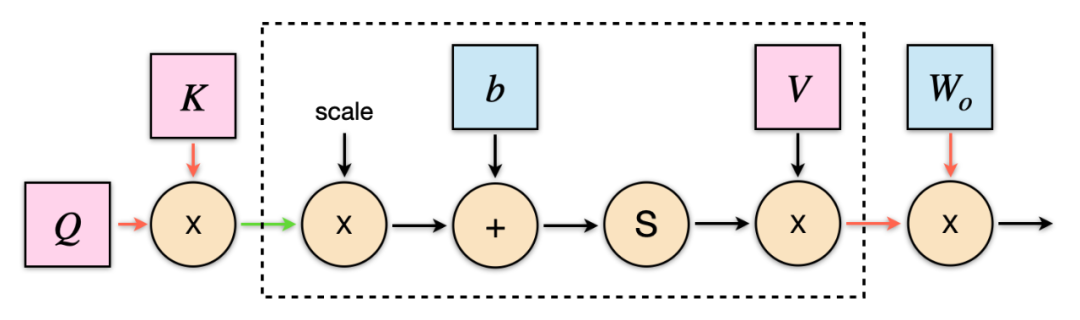 在推理时,LightSeq 还针对 decoder 做了优化。如上图所示,在计算 self-attention 时,注意力得分的维度是(batch size, 1, sequence length)。因此在计算 value 乘积时,可以不采用 GEMM 运算,而直接手写加权求和的算子,从而将图中虚线框中的计算融合成一个 kernel。
在推理时,LightSeq 还针对 decoder 做了优化。如上图所示,在计算 self-attention 时,注意力得分的维度是(batch size, 1, sequence length)。因此在计算 value 乘积时,可以不采用 GEMM 运算,而直接手写加权求和的算子,从而将图中虚线框中的计算融合成一个 kernel。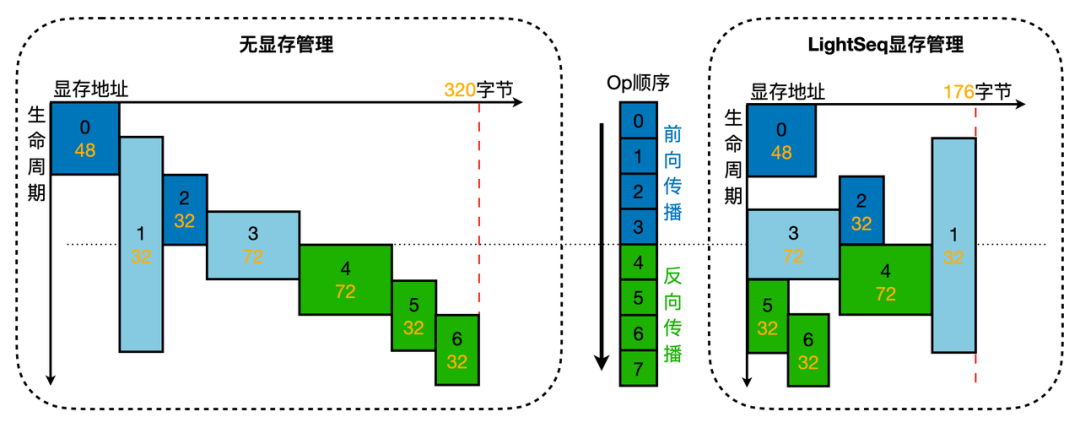 模型量化引入了更复杂的张量类型和张量依赖关系,这给显存管理带来新的挑战。为此,LightSeq 设计了新的显存管理机制。如上图所示,主要包括以下过程:
模型量化引入了更复杂的张量类型和张量依赖关系,这给显存管理带来新的挑战。为此,LightSeq 设计了新的显存管理机制。如上图所示,主要包括以下过程:我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我想为我的Rails网络应用程序提供推荐功能。特别是,我想向新注册的用户推荐他可能想要关注的其他用户。Rails中是否有用于此目的的引擎/gem?如果没有,我应该从哪里开始构建它?谢谢。 最佳答案 有Coletivogemhttps://github.com/diogenes/coletivo我试了一下。在MySQL上运行。Neo4jhttp://neo4j.org真的很容易实现一个“跟随谁”。事实上,大多数展示其能力的样本都涉及“跟随谁”。快速提示-只有在JRuby上运行时,Neo4j.rb才会很酷。如果不是-使用Neograph
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
我正在使用Ruby,我正在与一个网络端点通信,该端点在发送消息本身之前需要格式化“header”。header中的第一个字段必须是消息长度,它被定义为网络字节顺序中的2二进制字节消息长度。比如我的消息长度是1024。如何将1024表示为二进制双字节? 最佳答案 Ruby(以及Perl和Python等)中字节整理的标准工具是pack和unpack。ruby的packisinArray.您的长度应该是两个字节长,并且按网络字节顺序排列,这听起来像是n格式说明符的工作:n|Integer|16-bitunsigned,network(bi
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
我有一个模块:moduleMyModuledefdo_something#...endend由类使用如下:classMyCommandextendMyModuledefself.execute#...do_somethingendend如何验证MyCommand.execute调用了do_something?我已经尝试使用mocha进行部分模拟,但是当未调用do_something时它不会失败:it"callsdo_something"doMyCommand.stubs(:do_something)MyCommand.executeend 最佳答案
所以我只是对此感到好奇:DataMapper为其模型使用混合classPostincludeDataMapper::Resource虽然active-record使用继承classPost有谁知道为什么DataMapper选择这样做(或者为什么AR选择不这样做)? 最佳答案 它允许您从另一个不是DM类的类继承。它还允许动态地将DM功能添加到类中。这是我正在处理的模块中的类方法:defdatamapper_classklass=self.dupklass.send(:include,DataMapper::Resource)klass