b站源视频(视频理解论文串讲(上)【论文精读】):https://www.bilibili.com/video/BV1fL4y157yA/
视频里将视频理解分四大方向:
1,hand-crafted --> cnn
2,two-stream
3,3D cnn
4,video transformer
cvpr 14
论文pdf:Large-scale Video Classification with Convolutional Neural Networks
DeepVideo是在Alexnet出现之后,在深度学习时代,使用超大规模的数据集,使用比较深的卷积神经网络去做的视频理解(DeepVideo是处理视频理解的最早期工作之一)。
作者团队来自:Google Research、 Stanford University
该团队为视频领域作出很大的贡献,如:Sports-1M、YouTube-8M、AVA(action detection)等数据集。很大程度推动了视频领域的发展。
DeepVideo论文中的方法是比较直接的,论文中的想法就是如何将卷积神经网络从图片识别应用到视频识别中。视频与图片的不同在于,视频多了一个时间轴(有更多的视频帧)。所以论文中尝试了以下几个变体(下图后3种):
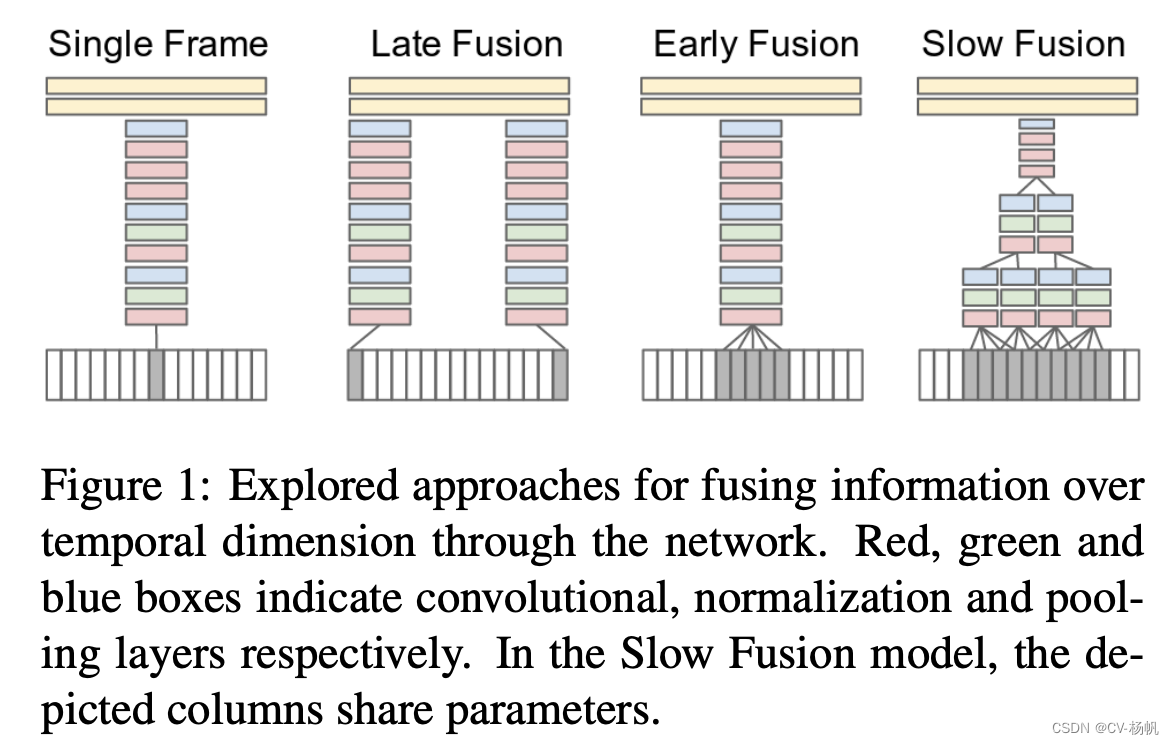
首先看下面的single frame的方式(即单帧的方式),其实就是一个图片分类的任务。在视频里任选一帧,然后把这一帧通过一个卷积神经网络,然后通过两个FC,最后得到分类结果,这个其实就是一个baseline。它完全没有时间信息,也没有视频信息在里面。
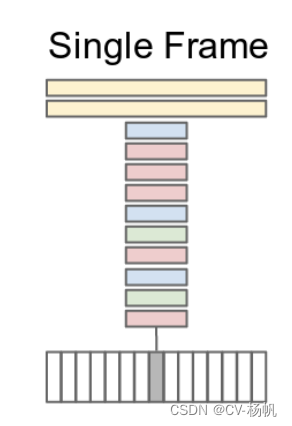
接着,作者做了Late Fusion,之所以叫Late,就是因为它在网络输出层做的一些结合。如下图,从视频中,随机选几帧,然后每一帧都单独通过一个卷积神经网络,这两个神经网络是权值共享的,将两个特征合并,再通过FC【全连接层】,最后做输出。 这样就稍微有一些时序上的信息了。
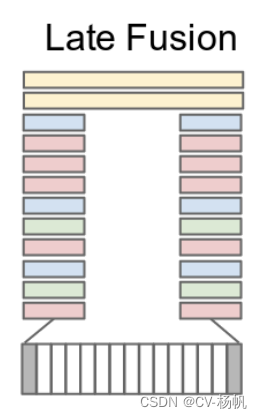
然后是Early Fusion,作者在输入层就做了融合。具体做法就是在RGB在Channel上直接合起来。
原来一张图片,有3个channel,现在有5张图片,就有3x5=15个channel。那就意味着网络结构要进行一定的改变了,尤其是第一层。
第一个卷积层接受的输入的通道数,就要由原来的3变成15,之后的网络都和之前的保持不变。
这样的做法,可以在输入层就可以感受到时序上的改变,希望能学到一些全局的运动或者时间信息。
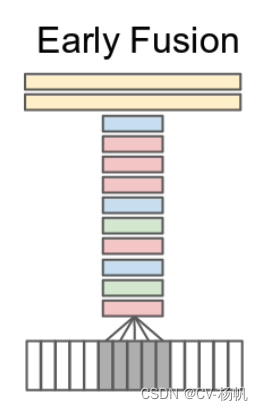
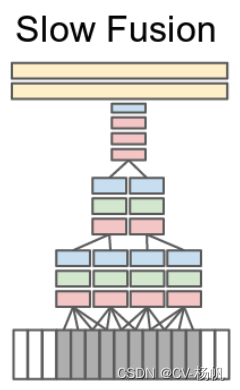
Slow Fusion是在Late Fusion 和 Early Fusion的基础上提出,Late Fusion合并太晚,Early Fusion合并太早了,Slow Fusion在特征层面做了一些融合。
具体做法就是选19个视频帧的1个小的视频片段,每4个视频帧就通过一个卷积神经网络,刚开始的层也是权值共享的,在抽出最开始的这些特征之后,由最开始的4个输入片段,慢慢合并成2个输入片段,再去做一些卷积操作,去学习更深层的特征。然后在融合2个特征,最后把学习到的特征给FC。
也就是说,整个网络都是多视频的整体的学习,作者最后实验结果,Slow Fusion结果较好(相对于前三个)。
但是从总体看来,这几种方法的差别都不大。即使在100万个视频上去做了预训练之后,在UCF101小数据集上去做迁移学习的时候,效果竟然还比不上之前的手工特征。
这就十分诡异了,所以作者就开始尝试另外一条路。
作者发现,用2D卷积神经网络去学时许特征,不好学,很难学。
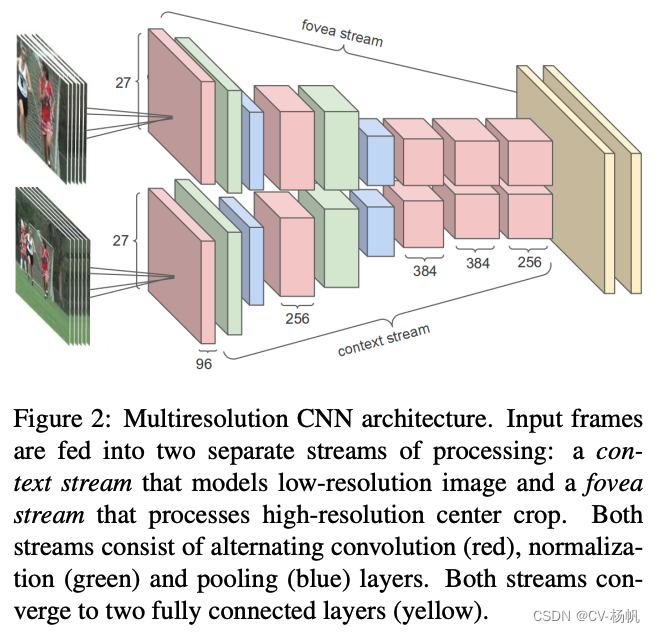
作者尝试了【多分辨率卷积网络】(Multiresolution CNN),作者将输入分成了2部分,一个是原图,另外一个是从原图的正中间抠出来的一部分。无论是对图片还是视频,最有用的物体大多会出现在图片或者视频的正中间。图中上面一条流称为fovea stream,下面一条流称为context stream。fovea是人眼视网膜最中心的凹陷地方,是对外界变化最敏感的一个区域。context就是指图片的整体信息。作者想通过这些操作让网络学习到网络中最有用的信息,又能学习到这个图片整体的理解。这个架构也算是双流结构。Multiresolution CNN中的两个网络是权值共享的。这种结构也可以理解为早期对注意力的一种使用方式。作者强制性想让这个网络去关注图片的中心区域。
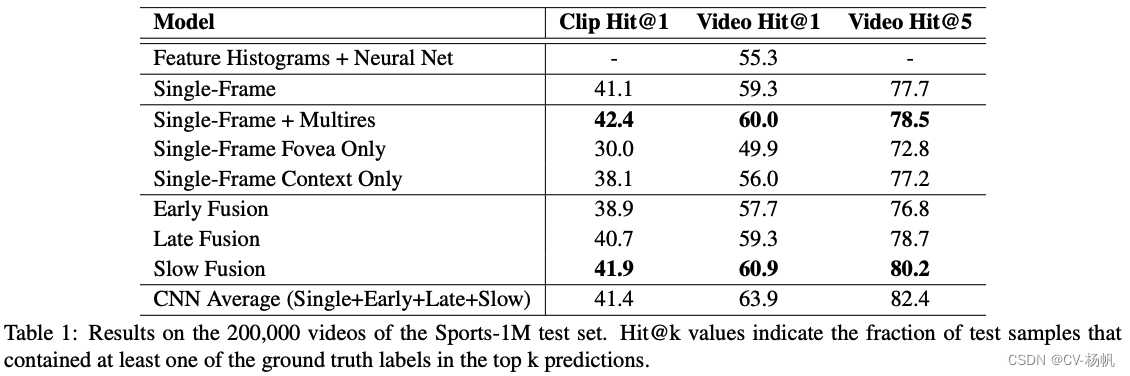
经过在Sports-1M数据上实验后发现,多分辨率卷积网络又一定提升,比如和Single-Frame(基准 Baseline)与Single-Frame Multires相比,有一定提升,但是提升相对来说比较小。Early Fusion和Late Fusion 都比Single-Frame(基准 Baseline)差。Slow Fusion经过一系列复杂操作后,也只比Single-Frame(基准 Baseline)高一点点。
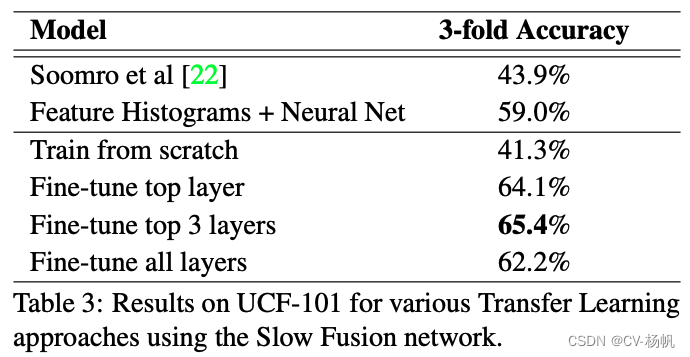
作者又在14年大家广为接受的UCF101数据集上,作者做好的变体:Fine-tune top 3 layers,也只有65.4%的准确度。而当时最好的手工方法已经可以达到87%的准确度。这样巨大的差异,让人们思考,深度学习网络在图片分类、图片检测效果都很好,为啥到了视频分类就碰壁了呢?
其实这篇文章的意义,不在于它的效果,作者不仅提出了当时最大的视频理解数据集,而且把你能想到的,最直接的方式,全都试了一遍,为后续的工作做了一个很好的铺垫。这才有了深度学习在视频领域的飞速发展。所以到了18、19年,视频理解(或者动作识别),已经是cv领域排名前5、6的关键词。
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭3年前。Improvethisquestion我正处于学习Ruby的阶段,我想查看一些小型库的源代码以了解它们是如何构建的。我不知道什么是小型图书馆,但希望SO能推荐一些易于理解的图书馆来学习。因此,如果有人知道一两个非常小的库,这是新手Rubyists学习的好例子,请推荐!我想使用Manveru'sInnatelib,因为它试图保持在2000LOC以下,但我还不熟悉其中经常使用的Ruby速记。也许大约100-5
由于匿名block和散列block看起来大致相同。我正在玩它。我做了一些严肃的观察,如下所示:{}.class#=>Hash好的,这很酷。空block被视为Hash。print{}.class#=>NilClassputs{}.class#=>NilClass为什么上面的代码和NilClass一样,下面的代码又显示了Hash?puts({}.class)#Hash#=>nilprint({}.class)#Hash=>nil谁能帮我理解上面发生了什么?我完全不同意@Lindydancer的观点你如何解释下面几行:print{}.class#NilClassprint[].class#A
我很难理解Ruby中sender和receiver的实际含义。它们一般是什么意思?到目前为止,我只是将它们理解为方法调用和获取其返回值的调用。但是,我知道我的理解还远远不够。谁能给我一个Ruby中发送者和接收者的具体解释? 最佳答案 面向对象中的一个核心概念是消息传递和早期概念化,这在很大程度上借鉴了计算的Actor模型。艾伦·凯(AlanKay)创造了面向对象一词并发明了最早的OO语言之一SmallTalk,他拥有voicedregretatusingatermwhichputthefocusonobjectsinsteadofo
rails新手。只是想了解\assests目录中的这两个文件。例如,application.js文件有如下行://=requirejquery//=requirejquery_ujs//=require_tree.我理解require_tree。只是将所有JS文件添加到当前目录中。根据上下文,我可以看出requirejquery添加了jQuery库。但是它从哪里得到这些jQuery库呢?我没有在我的Assets文件夹中看到任何jquery.js文件——或者直接在我的整个应用程序中没有看到任何jquery.js文件?同样,我正在按照一些说明安装TwitterBootstrap(http:
目前我正在使用这个正则表达式从YoutubeURL中提取视频ID:url.match(/v=([^&]*)/)[1]我怎样才能改变它,以便它也可以从这个没有v参数的YoutubeURL获取视频ID:http://www.youtube.com/user/SHAYTARDS#p/u/9/Xc81AajGUMU感谢阅读。编辑:我正在使用ruby1.8.7 最佳答案 对于Ruby1.8.7,这就可以了。url_1='http://www.youtube.com/watch?v=8WVTOUh53QY&feature=feedf'url