kafka总结
Kafka是一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据,具有高性能,持久化,多副本备份,横向扩展能力等。

Producer: 生产者,消息的生产者,消息的入口
Kafka cluster:
Broker: brocker是kafka的实例,每个服务器上有一个或多个kafka的实例,每个broker对应一台服务器,每个kafka集群内的broker都有一个编号,如broker0,broker1等
Topic: 消息的主题,可以理解为分类,kafka的数据就保存在topic。在每个broker上可以创建多个topic
Partiton: Topic的分区,每个topic有多个分区,分区的作用做负载,提高kafka的吞吐。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹
Replication: 每一个分区都有多个副本,主分区也就是leader故障的时候就会选择一个备胎(follower)上位升级成一个leader,在kafka中默认副本的最大数量是10个,副本的数量不能大于broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只能存放一个副本
Message: 每一条发送的消息主体
Consumer: 消费者,即消息的消费方,是消息的出口
Consumer Group: 我们可以将多个消费者组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量
Zookeeper: kafka集群依赖zookeper来保存集群的元信息,保证系统的可用性
生产者在写入数据的时候永远先找leader,不会直接将数据写入备胎

消息写入leader之后,follower是主动去找leader进行同步,生产者把数据push到broker,每条消息追加到分区中,顺序写入磁盘,写入磁盘的顺序如下:

所以kafka为什么要做分区有如下几个目的:
那么在Kafka中,某个topic有多个partition,生产者怎么判断将数据发往哪个partition?
在生产者写数据时如何保证数据不丢失呢?
如果生产者向不存在的topic分区中写入数据,Kafka会自动创建topic,分区和副本的数量根据默认配置都是1
producer将数据写入后,集群就要对数据进行保存了,Kafka是将数据保存在磁盘中,Kafka会单独开辟一块磁盘空间,顺序写入数据(效率比随机写入高)
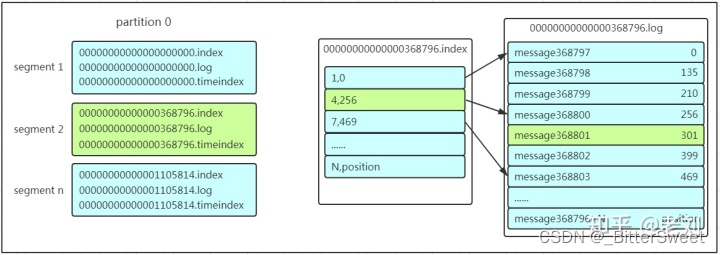
每个topic都可以分为一个或多个partition,如果topic理解起来抽象,那么partition比较具体,本质在服务器上就是一个一个的文件夹,每一个partition文件夹下面会有多个segment文件,每组segment文件又包含.index文件、.log文件、.timeindex文件,log文件存储message,index和timeindex为索引文件,用于检索消息

如上图,这个partition有三组segment文件,每个log文件的大小是一样的,但是存储的message数量是不一定相等的(每条的message大小不一致)。文件的命名是以该segment最小offset来命名的,如000.index存储offset为0~368795的消息,kafka就是利用分段+索引的方式来解决查找效率的问题。
log文件时存储message的地方,那么producer在向kafka写入的也是一条条的message,那么存储在log的message是什么样子的,消息主要包含消息体、消息大小、offset、压缩类型等,主要关注如下三点:
无论消息是否被消费,kafka都会保存所有的消息,那么对于旧数据有什么淘汰策略呢?
需要注意的是,kafka读取特定消息的时间复杂度是O(1),所以这里删除过期的文件并不会提高kafka的性能
消息存储在log文件后,消费者可以开始消费了,多个消费者组成一个消费者组,每个消费者组都有一个组id,同一个消费者组的消费者可以消费同一topic下不同分区的数据,但是不会消费同一分区的数据!

上图中消费者组内的消费者小于partition,3个消费者,4个分区,这样就会出现消费者消费多个partition数据的情况,可能消费不过来,简单说就是供大于求,如消费者数大于分区数,是否会出现供不应求的情况,这种情况是不会出现的,多出来的消费者是不消费任何partition的数据的,所以在实际应用中,建议消费者的数量和分区数量一致。
在保存数据那里说过,partition划分为多组segment,每个segment又包含几个文件,存放的每条message包含offset、消息大小、消息体等。那么在查找过程中,每次提到segment和offset,比如现在想要查找一个offset为368801的message,该怎么找呢?
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
Rails相对较新。我正在尝试调用一个API,它应该向我返回一个唯一的URL。我的应用程序中捆绑了HTTParty。我已经创建了一个UniqueNumberController,并且我已经阅读了几个HTTParty指南,直到我想要什么,但也许我只是有点迷路,真的不知道该怎么做。基本上,我需要做的就是调用API,获取它返回的URL,然后将该URL插入到用户的数据库中。谁能给我指出正确的方向或与我分享一些代码? 最佳答案 假设API为JSON格式并返回如下数据:{"url":"http://example.com/unique-url"
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭3年前。Improvethisquestion我正处于学习Ruby的阶段,我想查看一些小型库的源代码以了解它们是如何构建的。我不知道什么是小型图书馆,但希望SO能推荐一些易于理解的图书馆来学习。因此,如果有人知道一两个非常小的库,这是新手Rubyists学习的好例子,请推荐!我想使用Manveru'sInnatelib,因为它试图保持在2000LOC以下,但我还不熟悉其中经常使用的Ruby速记。也许大约100-5
由于匿名block和散列block看起来大致相同。我正在玩它。我做了一些严肃的观察,如下所示:{}.class#=>Hash好的,这很酷。空block被视为Hash。print{}.class#=>NilClassputs{}.class#=>NilClass为什么上面的代码和NilClass一样,下面的代码又显示了Hash?puts({}.class)#Hash#=>nilprint({}.class)#Hash=>nil谁能帮我理解上面发生了什么?我完全不同意@Lindydancer的观点你如何解释下面几行:print{}.class#NilClassprint[].class#A
我正在尝试复制此GETcurl请求:curl-D--XGET-H"Authorization:BasicdGVzdEB0YXByZXNlYXJjaC5jb206NGMzMTg2Mjg4YWUyM2ZkOTY2MWNiNWRmY2NlMTkzMGU="-H"Content-Type:application/json"http://staging.example.com/api/v1/campaigns在Ruby中,通过电子邮件+apikey生成身份验证:auth="Basic"+Base64::encode64("test@example.com:4c3186288ae23fd9661c
我很难理解Ruby中sender和receiver的实际含义。它们一般是什么意思?到目前为止,我只是将它们理解为方法调用和获取其返回值的调用。但是,我知道我的理解还远远不够。谁能给我一个Ruby中发送者和接收者的具体解释? 最佳答案 面向对象中的一个核心概念是消息传递和早期概念化,这在很大程度上借鉴了计算的Actor模型。艾伦·凯(AlanKay)创造了面向对象一词并发明了最早的OO语言之一SmallTalk,他拥有voicedregretatusingatermwhichputthefocusonobjectsinsteadofo
rails新手。只是想了解\assests目录中的这两个文件。例如,application.js文件有如下行://=requirejquery//=requirejquery_ujs//=require_tree.我理解require_tree。只是将所有JS文件添加到当前目录中。根据上下文,我可以看出requirejquery添加了jQuery库。但是它从哪里得到这些jQuery库呢?我没有在我的Assets文件夹中看到任何jquery.js文件——或者直接在我的整个应用程序中没有看到任何jquery.js文件?同样,我正在按照一些说明安装TwitterBootstrap(http: