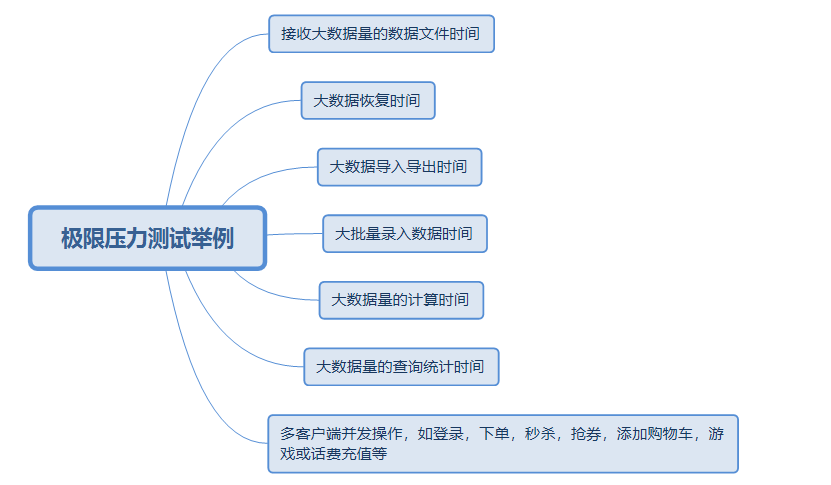
分布式测试是指通过局域网和Internet,把分布于不同地点、独立完成特定功能的测试计算机连接起来,以达到测试资源共享、分散操作、集中管理、协同工作、负载均衡、测试过程监控等目的的计算机网络测试。
(1)Webbench:开源,由Lionbridge公司开发,主要测试每秒钟请求数和每秒钟数据传输量,同时支持静态、动态、SSL。部署简单,静、动态均可测试。适用于小型网站压力测试(单例最多可模拟3万并发)。
(2)Apache bench: 开源, Apache自带的压力测试工具,主要用于测试网站每秒钟处理请求个数。多见用于静态压力测试,功能较弱,非专业压力测试工具。
(3)Tcpcopy: 开源 ,基于底层应用请求复制,可转发各种在线请求到测试服务器,具有分布式压力测试功能,所测试数据与实际生产数据较为接近。主要用于中大型压力测试,所有基于 tcp的packets均可测试。
(4)Loadrunner :付费/破解版本, 压力测试界的泰斗,可以创建虚拟用户,可以模拟用户真实访问流程从而录制成脚本,其测试结果也最为逼真。模拟最为逼真,并可进行独立的单元测试,但是部署配置较为复杂,需要专业人员才可以。
(5)JMeter: 开源免费, Jmeter 是一款使用Java开发的,开源免费的测试工具, 主要用来做功能测试和性能测试(压力测试/负载测试).,而且用Jmeter 来测试 Restful API,非常好用。
(6)WeTest :付费, 腾讯出品的线上服务器压力工具, 最高可模拟亿级并发,可实时查看性能数据报表,提供专家级性能优化建议。我们通常要分析的性能数据,如TPS,在线用户数,事务数,网络带宽,吞吐量,CPU,内存,磁盘IO等,报告里都有。
(7)PTS:付费, 阿里云出品的PTS(Performance Testing Service)是面向所有技术相关背景人员的云化性能测试工具,有别于传统工具的繁复,PTS以互联网化的交互,面向分布式和云化的设计,更适合当前的主流技术架构。无论是自研还是适配开源的功能,PTS都可以轻松模拟大量用户访问业务的场景,任务随时发起,免去搭建和维护成本。更是紧密结合监控类产品提供一站式监控、定位等附加价值,高效检验和管理业务性能。
(1)先了解几个专业术语
控制器节点(Controller Node),又叫Master:运行 JMeter GUI 的系统,它控制测试。
工作节点(Worker Nodes),又叫Slave:运行jmeter-server的系统,它从 GUI 接收命令并将请求发送到目标系统。
目标(Target):计划进行测试的网络服务器。
(2)原理:控制器节点启动时将压测脚本分发到各个工作节点上,然后通过远程启动各个工作节点,共同向目标服务器发送请求(产生压力)。测试结束以后,各个工作节点主动将压测数据回传给控制器节点,由控制器节点统一汇总数据,并输出测试报告。
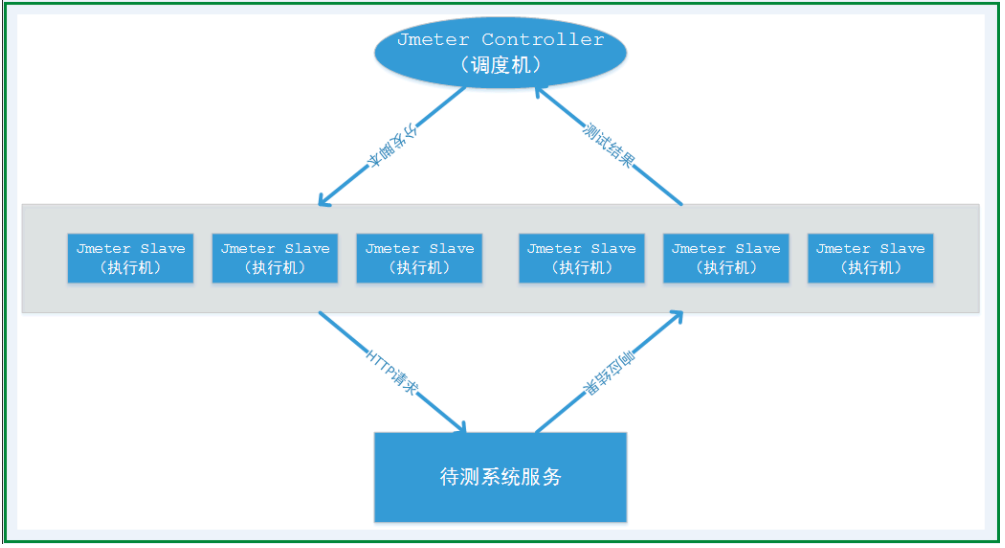
注意两点:
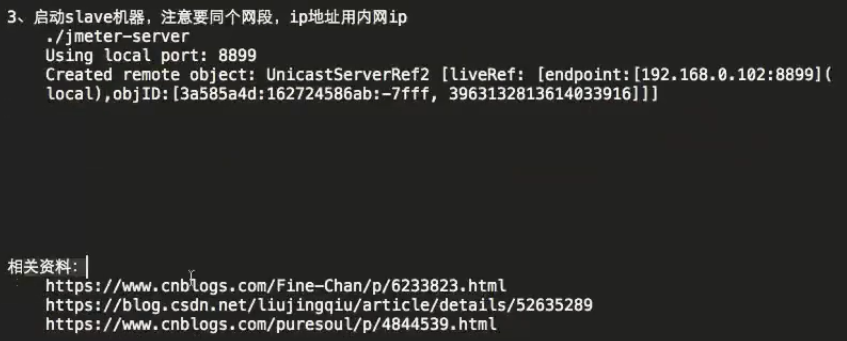
(1)master和各个slave机器必须使用同一局域网,尽可能减少网络带宽的影响。
(2)使用非GUI模式,避免不必要的cpu、内存损耗。
(2)master和各个slave的防火墙已关闭或打开了正确的端口,且端口未被占用。
(3)master和各个slave上安装的杀毒软件已关闭。
(4)master和各个slave在同一个子网内,尽量减少网络带宽的影响,减少时延问题。如果是多网卡环境需要保证启动的网卡都在同一个网段。
(5)确保 JMeter 可以访问服务器,可以使用ping命令查看。
(6)已经为 RMI 设置了 SSL或禁用了它。
(7)master和各个slave上安装Jmeter全部启动成功。
(8)如果压测脚本有依赖的测试数据,测试数据文件需要复制一份到Worker Nodes上,且文件路径必须Controller Node中一致。
(9)如果使用云服务器进行压测,一定要使用内网IP,不能使用公网IP,先使用ping命令检查网络是否通畅。
(10)压力测试瓶颈大都在带宽上面,需要保证slave的带宽要比Target的带宽高,不然压力上不去。
1、使用SpringBoot接口打包,并用jar包方式部署
(1)打包


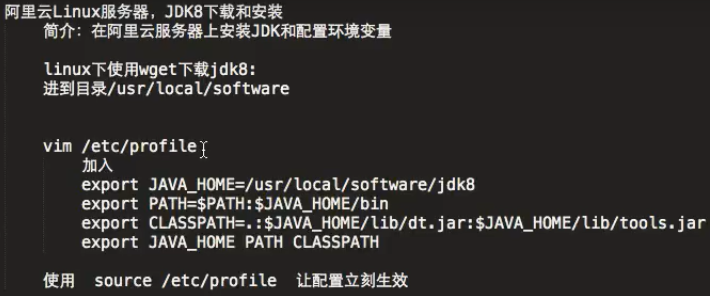
2、阿里云linux服务器下安装启动jdk8并配置环境变量
3、部署Java项目到阿里元服务器,守护进程讲解
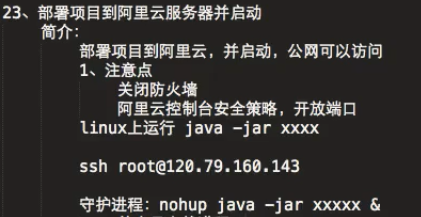
守护进程也称精灵进程(Daemon),是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。它不受用户登录注销的影响,它们一直在运行着。
4、阿里云liunx服务器上安装Jmeter
下载:wget https://archive.apache.org/dist/jmeter/binaries/apache-jmeter-5.1.tgz
解压:tar -zxvf apache-jmeter-5.1.tgz

拓展:

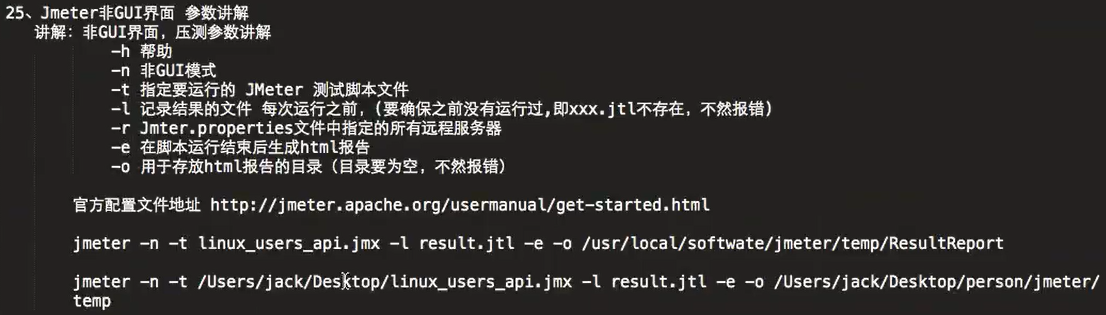
5、Jmeter非GUI界面参数讲解
FileZilla是一个免费开源的适合Windows、Mac和Linux的FTP客户端软件。FileZilla特点是:免费、跨平台、易用、下载速度非常快、功能齐全。
6、项目实战之阿里云linux服务器下非GUI界面执行Jmeter压测脚本
(1)Jmeter可视化界面开发压测脚本
(2)导出压测脚本linux_users_api.jmx保存在本地
(3)使用FileZilla工具将本地脚本上传到阿里云服务器上Jmeter安装路径的bin目录下
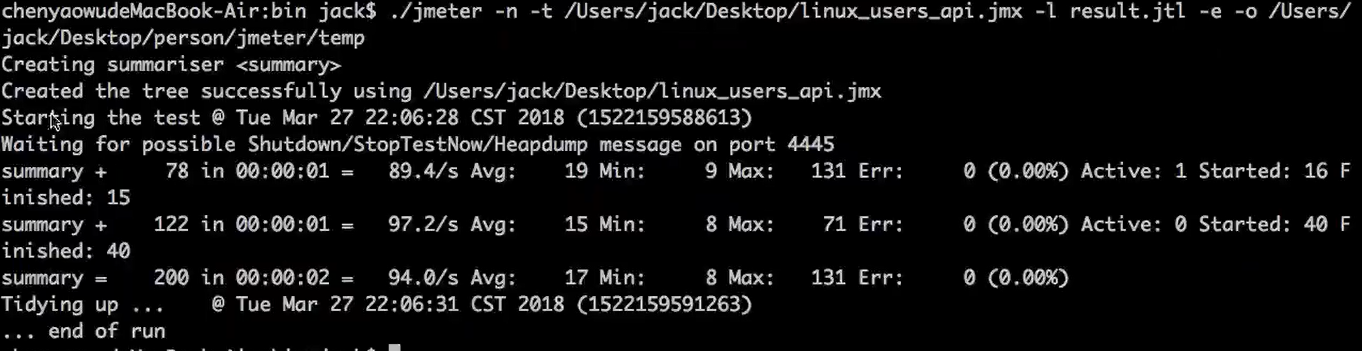
(4)执行压测脚本,查看日志:
7、Jmeter压测实战之jtl文件(压测结果文件)生成和查看
(1)使用FileZilla工具将阿里云服务器上的result.jtl文件下载到本地(直接拖拽到本地桌面)
(2)在本地打开Jmeter工具,Thread Group—>Add Listener—>Summary Report
(3)点击【Browse】,选择下载到本地桌面的result.jtl文件,打开。

8、Jmeter压测接口的性能优化

官网文档说明如下:

翻译下就是:
(1)使用非GUI模式:jmeter -n -t test.jmx -l test.jtl
(2)尽可能少低使用监听器,如果在监听器之前使用-l 标志,可以删除或禁用它们。
(3)在负载测试期间不要使用“查看结果树”或“聚合报告”监听器,仅在脚本编写阶段使用它们来调试脚本。
(4)不要使用大量类似的取样器,而是在循环中使用相同的取样器,并使用变量(CSV数据集)来改变样本。[此处包含控制器没有帮助,因为它将文件中的所有测试元素添加到测试计划中。
(5)不要使用功能模式。
(6)使用CSV输出而不是XML。
(7)只保存您需要的数据。
(8)使用尽可能少的断言。
(9)使用性能最好的脚本语言(请参阅JSR223部分)
(10)如果您的测试需要大量数据(特别是需要随机数据),请在可以使用CSV数据集读取的文件中创建测试数据。这避免了在运行时浪费资源。
9、Jmeter压测生成多维度图形化压测报告

(1)进度到bin目录下,执行上述指令,路径按自己实际情况来。
(2)将result目录打包成,result.tar.gz
(3)使用FileZilla工具下载本地解压
(4)找到index.html文件后,拖拽到浏览器中打开。
10、Jmeter图形化压测报告dashboard讲解

11、Jmeter图形化压测报告Charts讲解

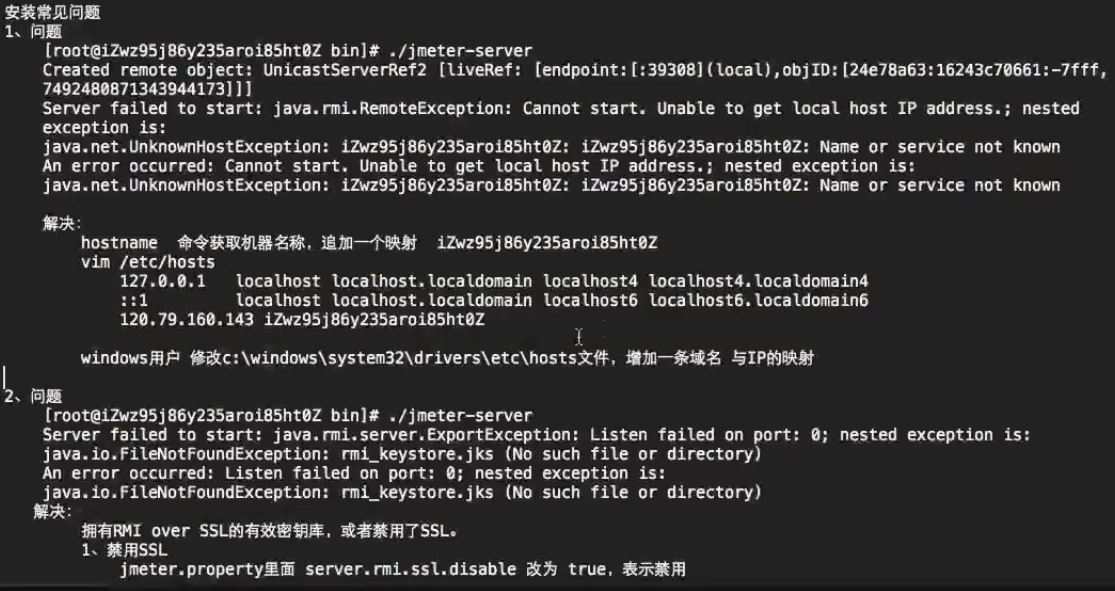
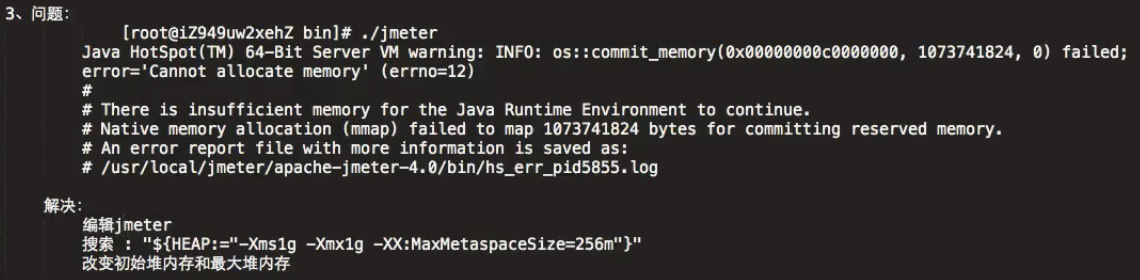
12、阿里云Jmeter分布式压测常见问题处理

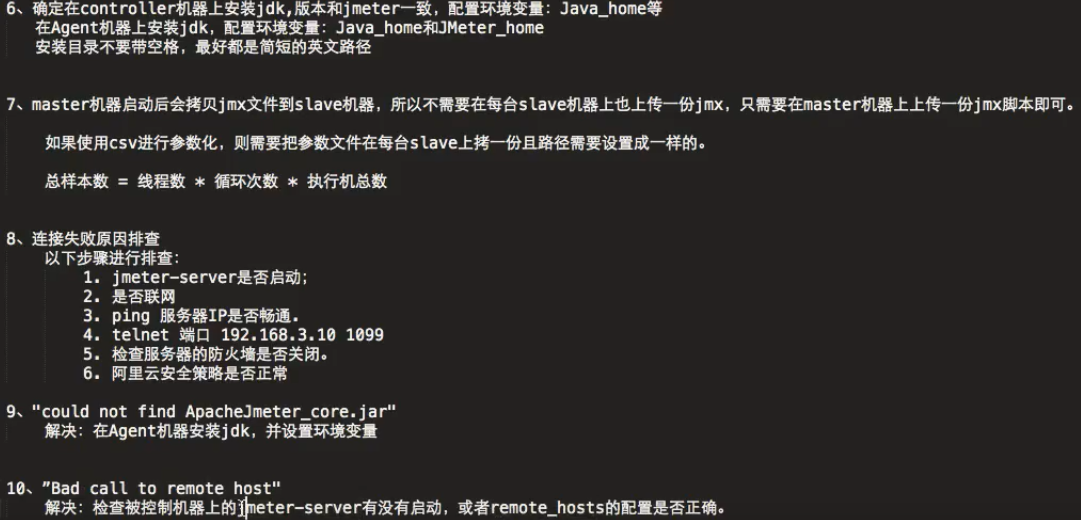
13、阿里云Jmeter分布式压实战

我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我想使用ruby-prof和JMeter分析Rails应用程序。我对分析特定Controller/操作/或模型方法的建议方法不感兴趣,我想分析完整堆栈,从上到下。所以我运行这样的东西:RAILS_ENV=productionruby-prof-fprof.outscript/server>/dev/null然后我在上面运行我的JMeter测试计划。然而,问题是使用CTRL+C或SIGKILL中断它也会在ruby-prof可以写入任何输出之前杀死它。如何在不中断ruby-prof的情况下停止mongrel服务器? 最佳答案
我有一个启动DRb服务的脚本,然后生成处理程序对象并通过DRb.thread.join等待。我希望脚本一直运行直到被明确杀死,所以我添加了trap"INT"doDRb.stop_serviceend在Ruby1.8下成功停止DRb服务并退出,但在1.9下似乎死锁(在OSX10.6.7上)。对该进程进行采样显示在semaphore_wait_signal_trap中有几个线程在旋转。我假设我在调用stop_service时做错了什么,但我不确定是什么。谁能给我任何关于如何正确处理它的指示? 最佳答案 好的,我想我已经找到了解决方案。如
BigData/CloudComputing:基于阿里云技术产品的人工智能与大数据/云计算/分布式引擎的综合应用案例目录来理解技术交互流程目录一、云计算网站建设:部署与发布网站建设:简单动态网站搭建云服务器管理维护云数据库管理与数据迁移云存储:对象存储管理与安全超大流量网站的负载均衡二、大数据MOOC网站日志分析搭建企业级数据分析平台基于LBS的热点店铺搜索基于机器学习PAI实现精细化营销基于机器学习的客户流失预警分析使用DataV制作实时销售数据可视化大屏使用MaxCompute进行数据质量核查使用Quick BI制作图形化报表使用时间序列分解模型预测商品销量三、云安全云平台使用安全云上服务
我不太确定如何表达这一点,所以我只是举个例子。如果我写:some_method(["a","b"],3)我希望它返回某种形式的[{"a"=>0,"b"=>3},{"a"=>1,"b"=>2},{"a"=>2,"b"=>1},{"a"=>3,"b"=>0}]如果我传入some_method(%w(abc),2)期望的返回值应该是[{"a"=>2,"b"=>0,"c"=>0},{"a"=>1,"b"=>1,"c"=>0},{"a"=>1,"b"=>0,"c"=>1},{"a"=>0,"b"=>2,"c"=>0},{"a"=>0,"b"=>1,"c"=>1},{"a"=>0,"b"=>0,"
文章目录概述定义使用场景特点工作流程连接器转换为何选择SeaTunnel安装下载配置文件部署模式入门示例启动脚本配置文件使用参数示例Kafka进Kafka出的ETL示例FlinkRun传递参数概述定义SeaTunnel官网http://seatunnel.incubator.apache.org/SeaTunnel最新版本官网文档http://seatunnel.incubator.apache.org/docs/2.1.3/intro/aboutSeaTunnelGitHub地址https://github.com/apache/incubator-seatunnelSeaTunnel是一个
用ruby生成正态分布随机数的代码是什么?(注意:我回答了我自己的问题,但我会等几天再接受,看看是否有人有更好的答案。)编辑:为此,我查看了两次搜索产生的SO上的所有页面:+“正态分布”ruby和+高斯+随机ruby 最佳答案 Python的random.gauss()和Boost的normal_distribution都使用Box-Mullertransform,所以这对Ruby来说也应该足够好了。defgaussian(mean,stddev,rand)theta=2*Math::PI*rand.callrho=Math.s
开始正文前需要先了解一下Jmeter线程组配置的含义,方便后面示例了解 一、压测相关插件安装1、下载jmeter-plugins-manager-1.7.jar(或者别的版本也可以),然后放到jmeter文件下的lib\ext目录中,然后启动jMeter2、在选项中选择pluginsmanager,再勾选3BasicGraphs,5AdditionalGraphs,Distribution/PercentileGraphs,KPIvaKPIGraphs,PerfMon,CustomThreadGroups。其他自己往下找就能找到3、添加性能监听指标(监听器中找一下)(1).bytesthrou
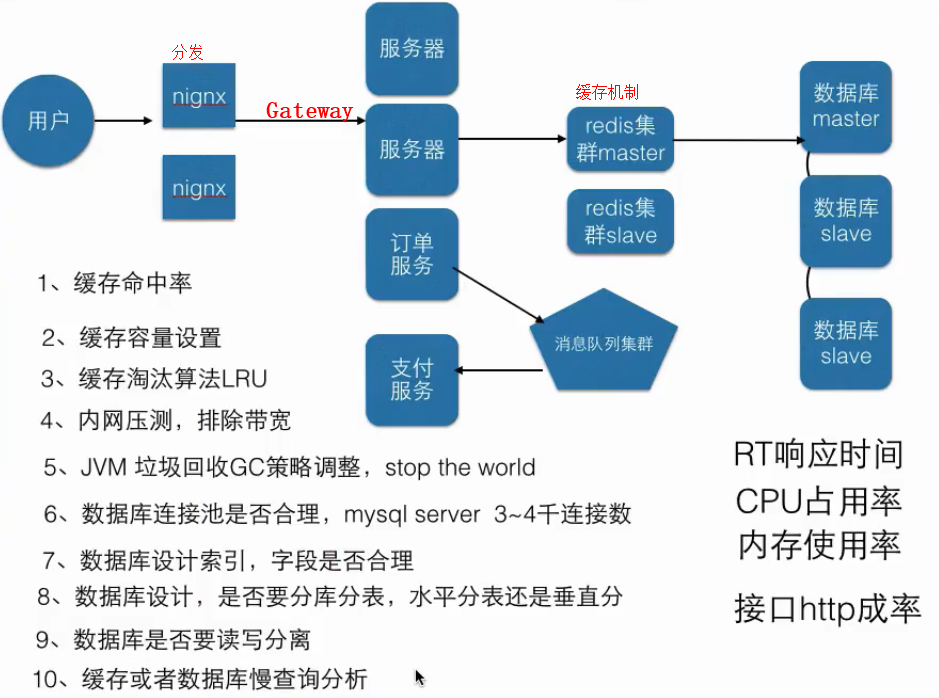
性能指标一、性能测试指标性能测试是通过测试工具模拟多种正常、峰值及异常负载条件来对系统的各项性能指标进行测试。目的:验证软件系统是否能够达到用户提出的性能指标,发现系统中存在的性能瓶颈并加以优化。二、指标分为两大类:软件指标:术语释义TPS:(每秒事务数)在每秒时间内系统可处理完毕的事务数。TPS很大程度体现系统性能能力。TPS(TransactionPerSecond)是指单位时间(每秒)系统处理的事务量。事务可以是用户自定义的一系列操作或者动作的集合,比如“用户注册“事务是点击注册按钮,填写用户注册信息,点击提交按钮,以及加载注册成功页面的动作集合。这3个个公式都是对的第1个公式计算的是绝
一、知识框架二、练习题调节一个装瓶机使其对每个瓶子的灌装量均值为μ盎司,通过观察这台装瓶机对每个瓶子的灌装量服从标准差σ=1.0盎司的正态分布。随机抽取这台机器灌装的9个瓶子组成一个样本,并测定每个瓶子的灌装量。试确定样本均值偏离总体均值不超过0.3盎司的概率。解:设每个瓶子的灌装量为X,X为样本均值,样本容量为n。由于总体X服从正态分布,样本均值X也服从正态分布,且均值相同,标准差为所以三、简述题1什么是统计量?为什么要引进统计量?统计量中为什么不含任何未知参数?答:(1)统计量的定义:设X1,X2,…,Xn是从总体X中抽取的容量为n的一个样本,如果由此样本构造一个函数T(X1,X2,…,X