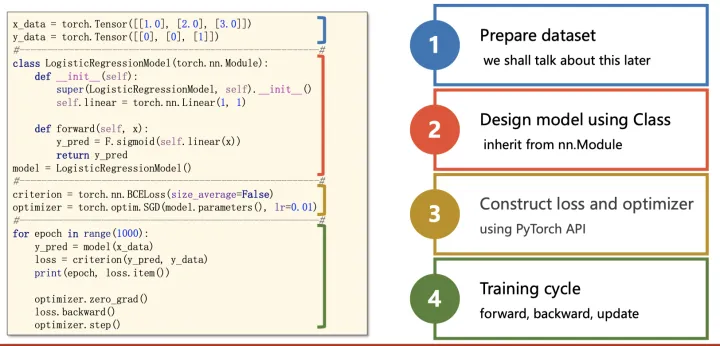
1. 数据预处理(Dataset、Dataloader)
2. 模型搭建(nn.Module)
3. 损失&优化(loss、optimizer)
4. 训练(forward、backward)
对于数据处理,最为简单的⽅式就是将数据组织成为⼀个 。
但许多训练需要⽤到mini-batch,直 接组织成Tensor不便于我们操作。
pytorch为我们提供了Dataset和Dataloader两个类来方便的构建。
torch.utils.data.DataLoader(dataset,batch_size,shuffle,drop_last,num_workers)

搭建一个简易的神经网络
除了采用pytorch自动梯度的方法来搭建神经网络,还可以通过构建一个继承了torch.nn.Module的新类,来完成forward和backward的重写。
# 神经网络搭建
import torch
from torch.autograd import Varible
batch_n = 100
hidden_layer = 100
input_data = 1000
output_data = 10
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
def forward(self,input,w1,w2):
x = torch.mm(input,w1)
x = torch.clamp(x,min = 0)
x = torch.mm(x,w2)
def backward(self):
pass
model = Model()
#训练
x = Variable(torch.randn(batch_n,input_data))
一点一点地看:
import torch
dtype = torch.float
device = torch.device("cpu")
N, D_in, H, D_out = 64, 1000, 100, 10
# Create random input and output data
x = torch.randn(N, D_in, device=device, dtype=dtype)
y = torch.randn(N, D_out, device=device, dtype=dtype)
# Randomly initialize weights
w1 = torch.randn(D_in, H, device=device, dtype=dtype)
w2 = torch.randn(H, D_out, device=device, dtype=dtype)
learning_rate = 1e-6
tensor 写一个粗糙版本(后面陆陆续续用pytorch提供的方法)
for t in range(500):
# Forward pass: compute predicted y
h = x.mm(w1)
h_relu = h.clamp(min=0)
y_pred = h_relu.mm(w2)
# Compute and print loss
loss = (y_pred - y).pow(2).sum().item()
if t % 100 == 99:
print(t, loss)
# Backprop to compute gradients of w1 and w2 with respect to loss
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
grad_h = grad_h_relu.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
# Update weights using gradient descent
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
Autograd
for t in range(500):
y_pred = x.mm(w1).clamp(min=0).mm(w2)
loss = (y_pred - y).pow(2).sum()
if t % 100 == 99:
print(t, loss.item())
loss.backward()
with torch.no_grad():
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
w1.grad.zero_()
w2.grad.zero_()对于需要计算导数的变量(w1和w2)创建时设定requires_grad=True,之后对于由它们参与计算的变量(例如loss),可以使用loss.backward()函数求出loss对所有requires_grad=True的变量的梯度,保存在w1.grad和w2.grad中。
在迭代w1和w2后,即使用完w1.grad和w2.grad后,使用zero_函数清空梯度。
nn
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
)
loss_fn = torch.nn.MSELoss(reduction='sum')
learning_rate = 1e-4
for t in range(500):
y_pred = model(x)
loss = loss_fn(y_pred, y)
if t % 100 == 99:
print(t, loss.item())
model.zero_grad()
loss.backward()
with torch.no_grad():
for param in model.parameters():
param -= learning_rate * param.gradoptim
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
for t in range(500):
y_pred = model(x)
loss = loss_fn(y_pred, y)
if t % 100 == 99:
print(t, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
迭代进行训练以及测试,其中训练的函数train里就保存了进行梯度下降求解的方法
# 定义训练函数,需要
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
# 从数据加载器中读取batch(一次读取多少张,即批次数),X(图片数据),y(图片真实标签)。
for batch, (X, y) in enumerate(dataloader):
# 将数据存到显卡
X, y = X.to(device), y.to(device)
# 得到预测的结果pred
pred = model(X)
# 计算预测的误差
# print(pred,y)
loss = loss_fn(pred, y)
# 反向传播,更新模型参数
optimizer.zero_grad() #梯度清零
loss.backward() #反向传播
optimizer.step() #更新参数
# 每训练10次,输出一次当前信息
if batch % 10 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
设置为测试模型并设置不计算梯度,进行测试数据集的加载,判断预测值与实际标签是否一致,统一正确信息个数
# 将模型转为验证模式
model.eval()
# 测试时模型参数不用更新,所以no_gard()
with torch.no_grad():
# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)
for X, y in dataloader:
加载数据
pred = model(X)#进行预测
# 预测值pred和真实值y的对比
test_loss += loss_fn(pred, y).item()
# 统计预测正确的个数
correct += (pred.argmax(1) == y).type(torch.float).sum().item()#返回相应维度的最大值的索引
test_loss /= size
correct /= size
print(f"correct = {correct}, Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
mark一下很有用的博客
用pytorch实现神经网络_徽先生的博客-CSDN博客_pytorch 神经网络
① 创建一个 Dataset 对象
② 创建一个 DataLoader 对象
③ 循环这个 DataLoader 对象,将xx, xx加载到模型中进行训练
DataLoader详解_sereasuesue的博客-CSDN博客_dataloader
都会|可能会_深入浅出 Dataset 与 DataLoader
Pytorch加载自己的数据集(使用DataLoader读取Dataset)_l8947943的博客-CSDN博客_pytorch dataloader读取数据
可以直接调用的数据集
https://www.pianshen.com/article/9695297328/
pytorch教程之nn.Sequential类详解——使用Sequential类来自定义顺序连接模型_LoveMIss-Y的博客-CSDN博客_sequential类
torch.nn.Module是torch.nn.functional中方法的实例化
pytorch教程之nn.Module类详解——使用Module类来自定义模型_LoveMIss-Y的博客-CSDN博客_torch.nn.module
对应Sequential的三种包装方式,Module有三种写法
model.train()
for epoch in range(epoch):
for train_batch in train_loader:
...
zhibiao = test(epoch, test_loader, model)
def test(epoch, test_loader, model):
model.eval()
for test_batch in test_loader:
...
return zhibiao
【Pytorch】model.train() 和 model.eval() 原理与用法_想变厉害的大白菜的博客-CSDN博客_pytorch train()
pytroch:model.train()、model.eval()的使用_像风一样自由的小周的博客-CSDN博客_model.train()放在程序的哪个位置
model = ...
dataset = ...
loss_fun = ...
# training
lr=0.001
model.train()
for x,y in dataset:
model.zero_grad()
p = model(x)
l = loss_fun(p, y)
l.backward()
for p in model.parameters():
p.data -= lr*p.grad
# evaluating
sum_loss = 0.0
model.eval()
with torch.no_grad():
for x,y in dataset:
p = model(x)
l = loss_fun(p, y)
sum_loss += l
print('total loss:', sum_loss)
https://www.jb51.net/article/211954.htm
MAE:
import torch
from torch.autograd import Variable
x = Variable(torch.randn(100, 100))
y = Variable(torch.randn(100, 100))
loos_f = torch.nn.L1Loss()
loss = loos_f(x,y)
MSE:
import torch
from torch.autograd import Variable
x = Variable(torch.randn(100, 100))
y = Variable(torch.randn(100, 100))
loos_f = torch.nn.MSELoss()#定义
loss = loos_f(x, y)#调用
torch.nn中常用的损失函数及使用方法_加油上学人的博客-CSDN博客_nn损失函数
基于pytorch框架下的一个简单的train与test代码_黎明静悄悄啊的博客-CSDN博客
1. GCN、GAT
图神经网络及其Pytorch实现_jiangchao98的博客-CSDN博客_pytorch 图神经网络
2. 用DGL
PyTorch实现简单的图神经网络_梦家的博客-CSDN博客_pytorch图神经网络
一文看懂图神经网络GNN,及其在PyTorch框架下的实现(附原理+代码) - 知乎
图神经网络的不足
•扩展性差,因为训练时需要用到包含所有节点的邻接矩阵,是直推性的(transductive)
•局限于浅层,图神经网络只有两层
•不能作用于有向图
3. 用PyG
图神经网络框架-PyTorch Geometric(PyG)的使用__Old_Summer的博客-CSDN博客_pytorch-geometric
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
我正在开发一个Rails应用程序,我需要在其中找到给定特定偏移量或时区的夏令时开始和结束日期。我基本上在我的数据库中保存了从用户浏览器接收到的时区偏移量(“+3”,“-5”),我想在它出现时修改它由于夏令时的变化。我知道Time实例变量有dst?和isdst方法,如果存储在它们中的日期在夏令时与否。>Time.new.isdst=>true但是使用它来查找夏令时的开始和结束日期会占用太多资源,而且我还必须为我拥有的每个时区偏移量执行此操作。我想知道更好的方法。 最佳答案 好的,基于你所说的和@dhouty'sanswer:您希望能够
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案
我在这方面尝试了很多URL,在我遇到这个特定的之前,它们似乎都很好:require'rubygems'require'nokogiri'require'open-uri'doc=Nokogiri::HTML(open("http://www.moxyst.com/fashion/men-clothing/underwear.html"))putsdoc这是结果:/Users/macbookair/.rvm/rubies/ruby-2.0.0-p481/lib/ruby/2.0.0/open-uri.rb:353:in`open_http':404NotFound(OpenURI::HT
我有一台生产机器和一台开发机器,都运行ubuntu8.10并且都运行最新的phusionpassenger。当我在osx上的本地开发机器上使用ruby1.9.1时,我想知道外面的人是否已经在使用带有ruby1.9.1甚至1.9.2的phusionpassenger?如果是这样,请告诉我们您的设置!此外,有没有办法在apache上使用phusionpassenger同时运行ruby1.8.7(ree)和1.9.1?感谢您的指点,我在任何地方都找不到任何提示... 最佳答案 是的,从某些2.2.x版本开始就正式支持它,我不记
date_select方法只能设置:start_year,但我想设置开始日期(例如3个月前的日期)(但没有这样的选项)。那么,我可以将开始日期设置为date_select方法吗?或者,要制作这样的选择框,我应该使用select_tag和options_for_select吗?或者,有什么解决办法吗?谢谢, 最佳答案 有可能……例如:start_year–设置年份选择的开始年份。默认为Time.now.year-5参见thisresource. 关于ruby-Rails3-我可以将开始日期
我想从特定索引开始遍历数组。我该怎么做?myj.eachdo|temp|...end 最佳答案 执行以下操作:your_array[your_index..-1].eachdo|temp|###end 关于ruby-从特定索引开始迭代数组,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/44151758/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG