从而避免了位置编码的内插。
当测试分辨率与训练分辨率不同时,位置编码会导致性能下降。
2.避免使用复杂的解码器,MLP聚合了不同层的信息
网络更小,效果也佳
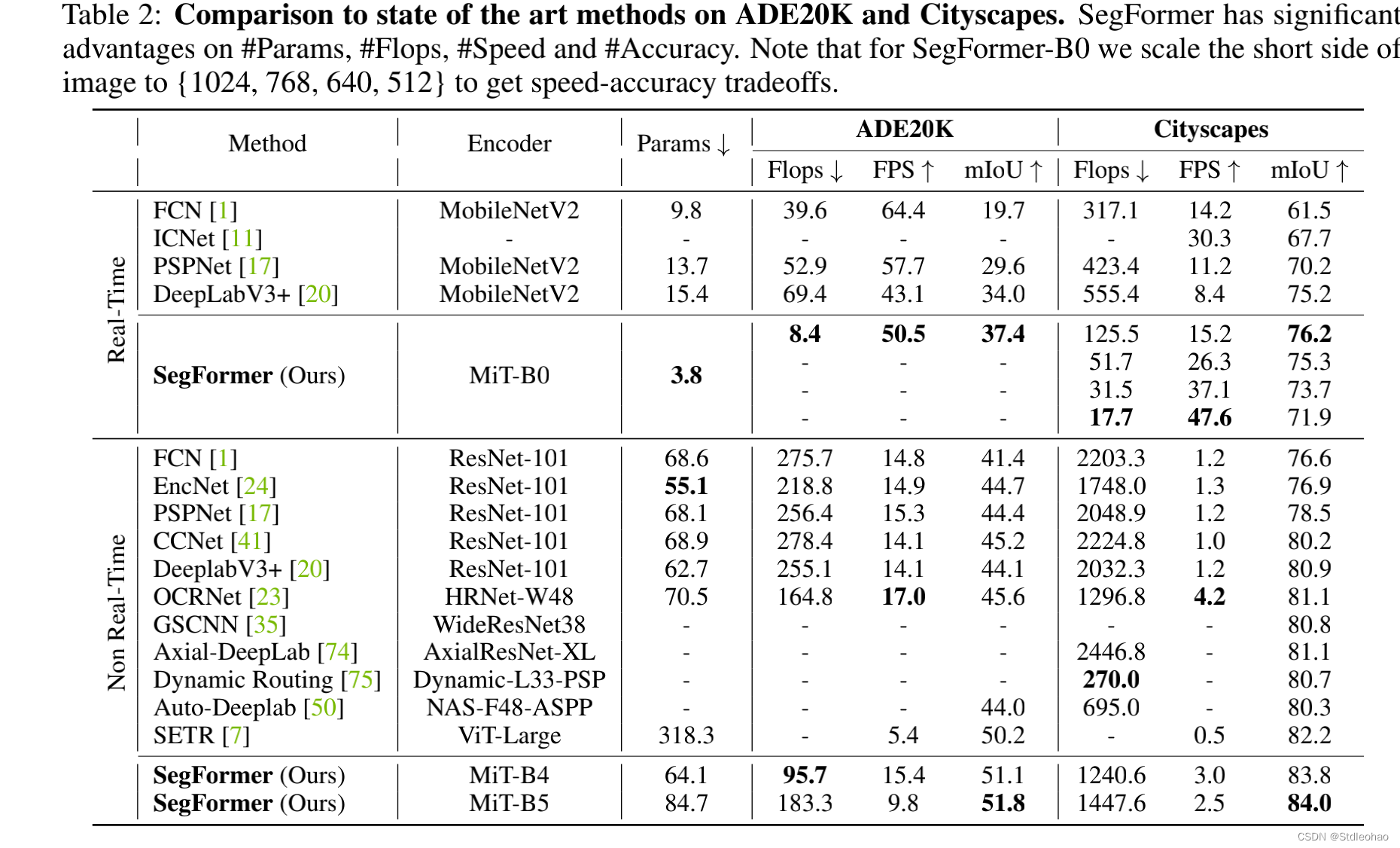
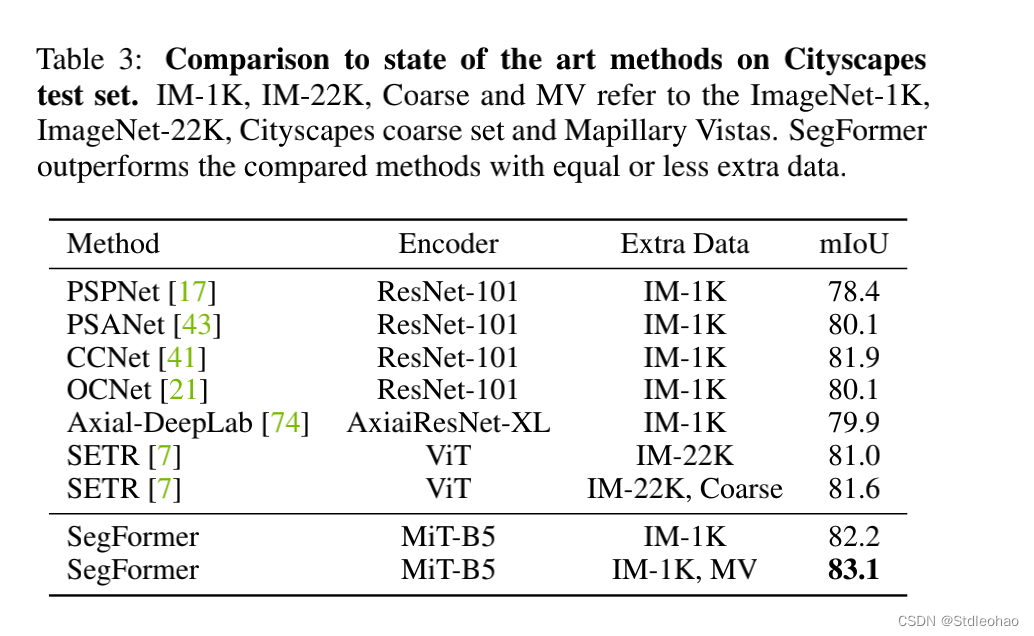
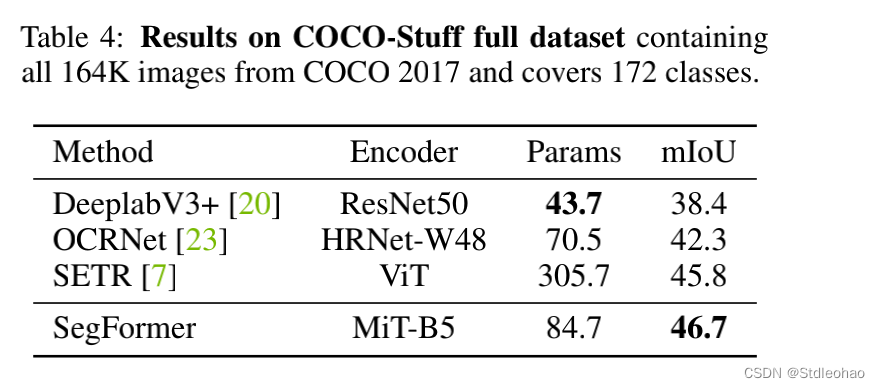
定量评估数据集
设计主干
结构化预测问题
设计模块和操作,有效捕捉上下文信息
ViT
SETR
SETR采用ViT作为主干并结合几个CNN解码来扩大特征分辨率
ViT的局限
PVT拓展ViT
还有SwinTransformer和Twins
FCN、改进
ViT
DeiT
T2T ViT ,CPVT,TNT,CrossViT, LocalViT
PVT
Swin[9]、CvT[58]、CoaT[59]、LeViT[60]和
Twins[10]
DETR
SETR
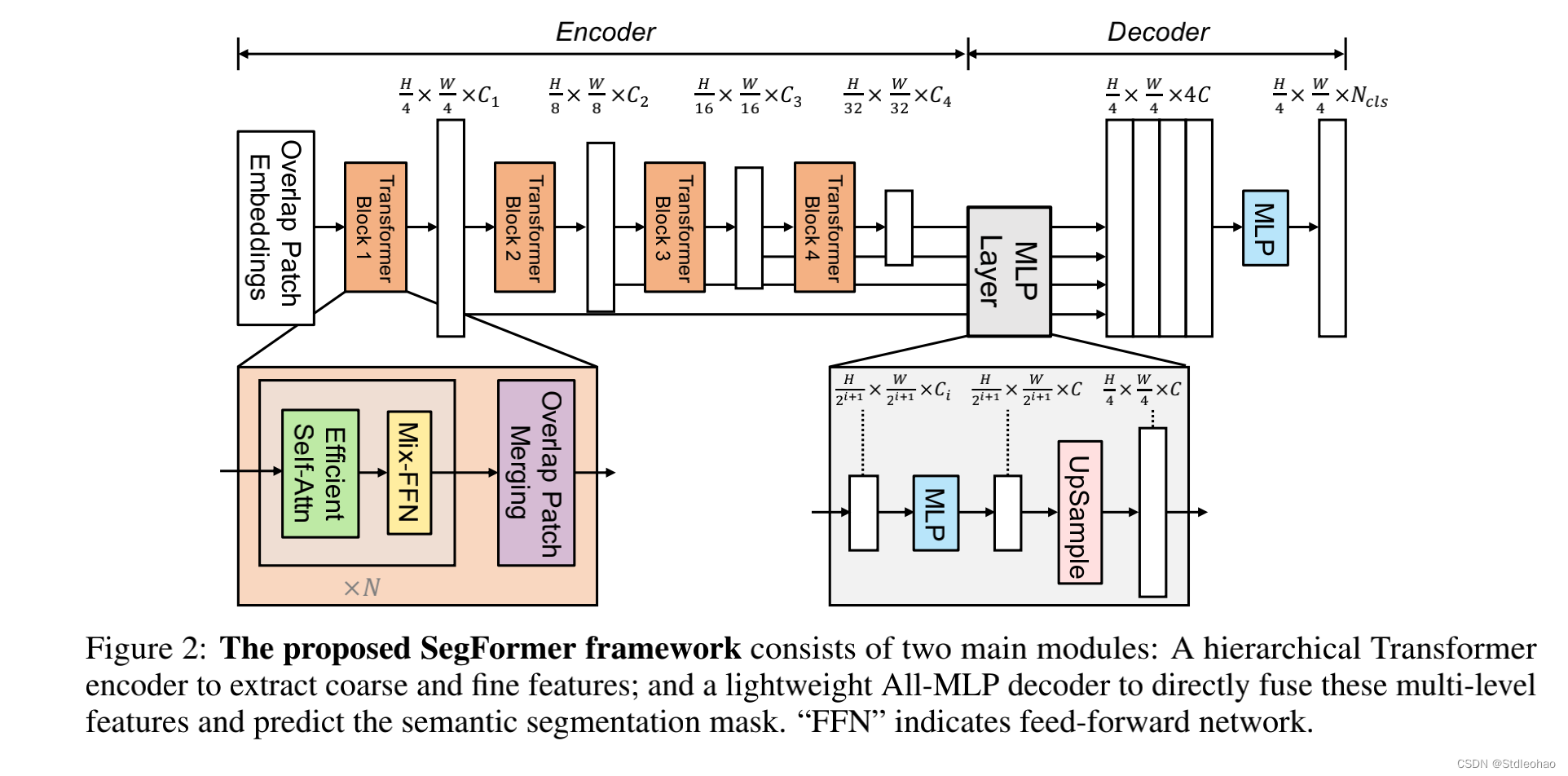
MiT-B0到B5具有相同的结构但尺寸不同。设计部分受到ViT的启发,但为语义分割量身定制和优化
Hierarchical Feature Representation.
Overlapped Patch Merging.
Efficient Self-Attention.
Mix-FFN.
我们认为位置编码对于语义分割来说实际上是没有必要的
MLP四步
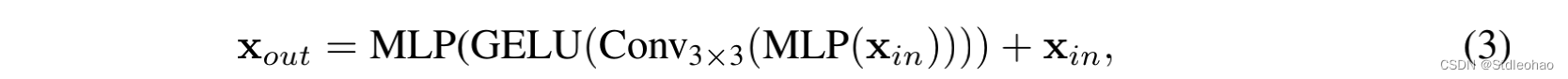
Effective Receptive Field Analysis.
-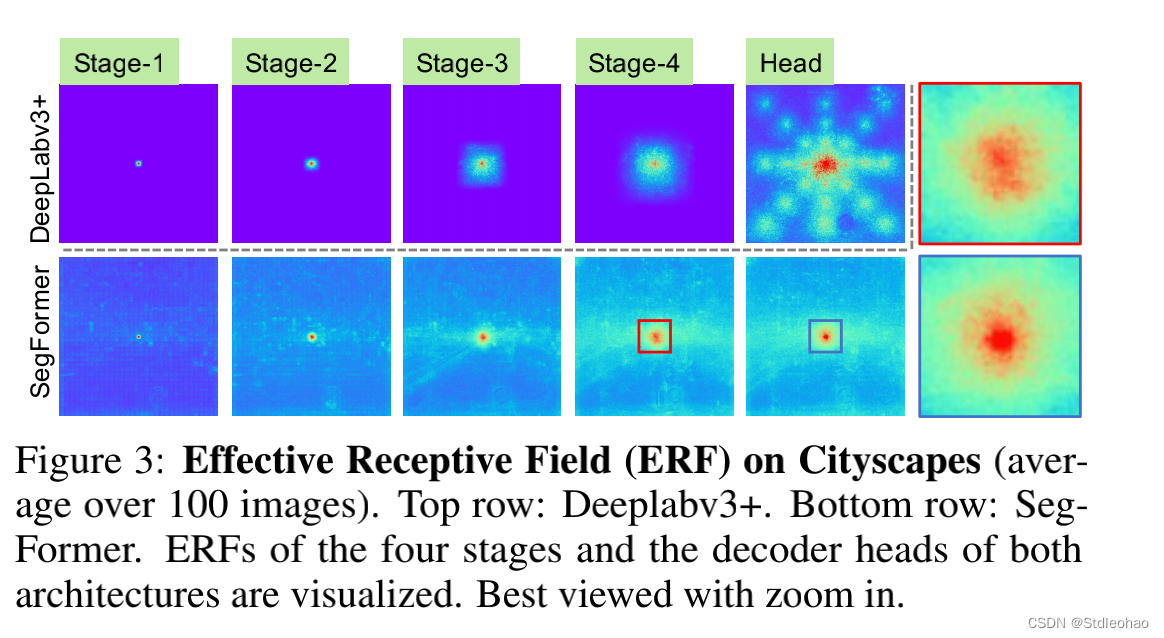
得益于Transformer里面的非局部注意,导致了更大的接收区域而不复杂
与ASPP不同
在CNN主干中并不能很好地工作,因为整体的感受野有上限
我们在ImageNet-1K中预训练,ViT在更大的ImageNet-22k中预训练
SegFormer的编码器有一个分层结构,比ViT更小,并且可以捕捉到高分辨率的粗略特征和低分辨率的精细特征,相比之下,SETR的ViT编码器可以只能生成单一的低分辨率特征图。
我们删除了编码器中的位置嵌入,而SETR使用固定形状的位置嵌入。
当推理时的分辨率与训练时的分辨率不同时,会降低准确性。
我们的MLP解码器比SETR中的解码器更紧凑,计算要求更低。
这导致了可忽略不计的计算开销。相比之下,SETR需要繁重的解码器与
多个3×3的卷积。
Datasets:
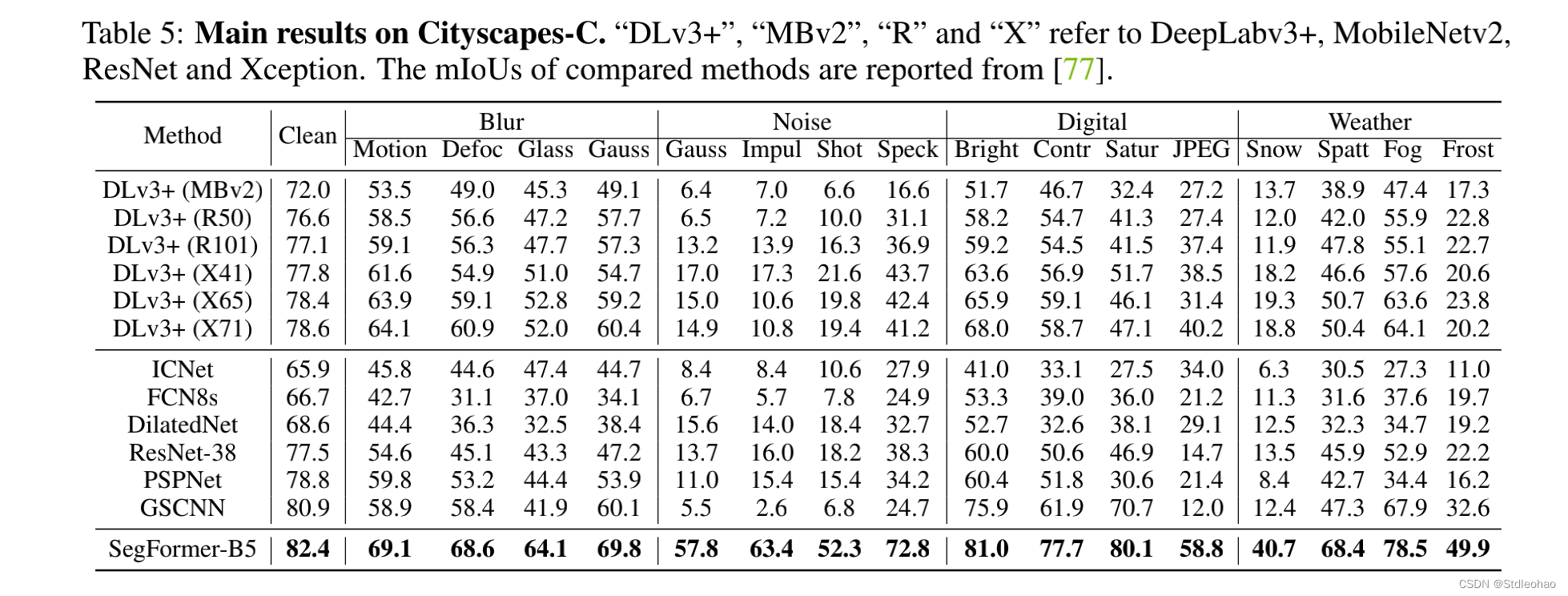
Cityscapes
ADE20k
COCOStuff
Implementation details:
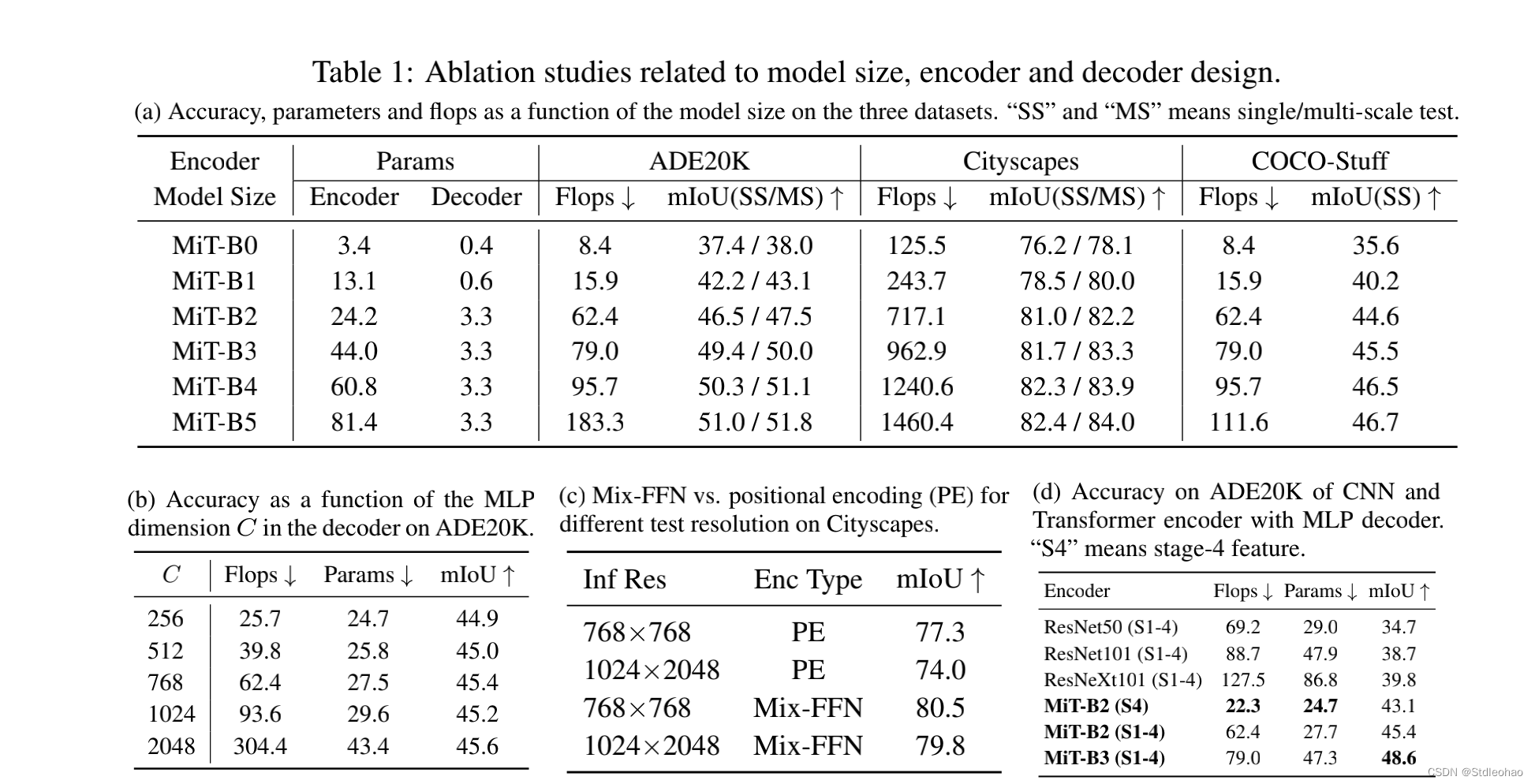
Influence of the size of model.
Influence of C, the MLP decoder channel dimension.
Mix-FFN vs. Positional Encoder (PE).
Effective receptive field evaluation.
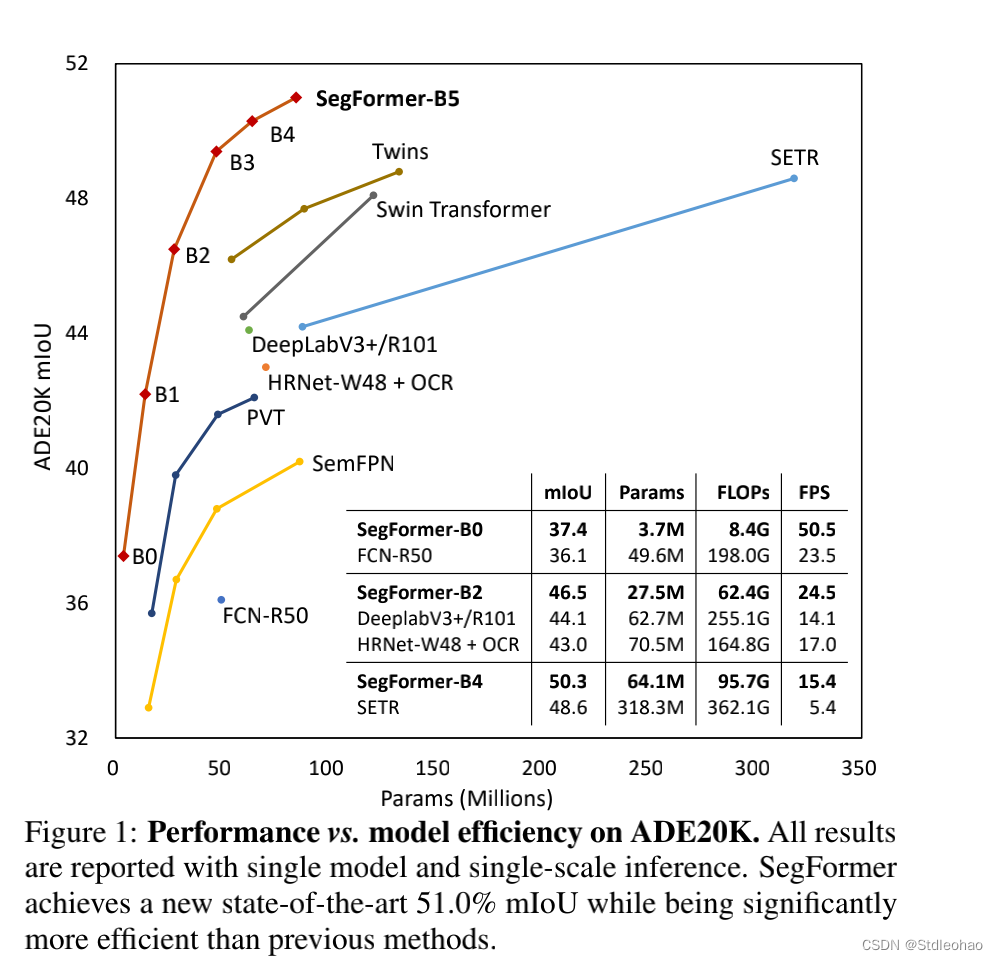
在本文中,我们提出了一种简单、干净而又强大的语义分割方法,它包含一个无位置编码的分层转换编码器和一个轻量级的All-MLP解码器。它避免了以往方法中常见的复杂设计,从而实现了高效率和性能。SegFromer不仅在公共数据集上获得了新的结果,而且还显示在零样本上的强鲁棒性。我们希望我们的方法能够作为语义分割的坚实基础,并激发进一步的研究。一个限制是,虽然我们最小的3.7M参数modEl比已知的CNN模型要小,目前尚不清楚它是否能在只有100k内存的边缘设备芯片上工作良好。
主要为记录自己学习实践mmsegmentation框架的过程,并顺便为一起学习的同学们提供参考,分享一下自己学习到的一些知识和所踩的坑,与大家共勉! 我个人主要是想要使用mmsegmentation框架训练自己的数据集,一开始跟着网上的教程使用了PspNet网络,但是可能由于数据集过小最后达到的效果不尽人意,因此考虑使用更新的、性能更好的SegFormer进行尝试,也是看到了SegFormer在各种数据集上的准确率都相较传统的神经网络有了较大提升,所以比较心动。 SegFormer在ADE20K数据集上的表现 那么让我
SegFormer:SimpleandEfficientDesignforSemanticSegmentationwithTransformersAbstract方法Transformers与轻量级多层感知器(MLP)统一起来吸引人的特点分层结构的transformers编码器,并且不需要位置编码从而避免了位置编码的内插。当测试分辨率与训练分辨率不同时,位置编码会导致性能下降。位置编码的缺点;2.避免使用复杂的解码器,MLP聚合了不同层的信息结合了局部和全局注意力来呈现强大的表征效果网络更小,效果也佳定量评估数据集CityscapesvalidationsetCityscapes-CADE20