
导读: 本文主要介绍了快手的精排模型实践,包括快手的推荐系统,以及结合快手业务展开的各种模型实战和探索,全文围绕以下几大方面展开:
--
快手的推荐系统类似于一个信息检索范式,只不过没有用户显示query。结构为数据漏斗,候选集有百亿量级的短视频,在召回层,会召回万级的视频给粗排打分,再选取数百个短视频,给精排模型打分,最后会有数十个短视频进行重排。推荐主要是双类或单类,快手推荐的特点是用户比较多,会超过3.0亿。我们的短视频,每天有百亿的分发量,候选的短视频有百亿之多,用户的行为差距会非常之大,比如,有些用户每天会刷成百上千条短视频,有些用户又刷得非常少。相对于电商或者新闻来说,短视频的玩法会更丰富,用户的兴趣非常广泛,并且是不变的。
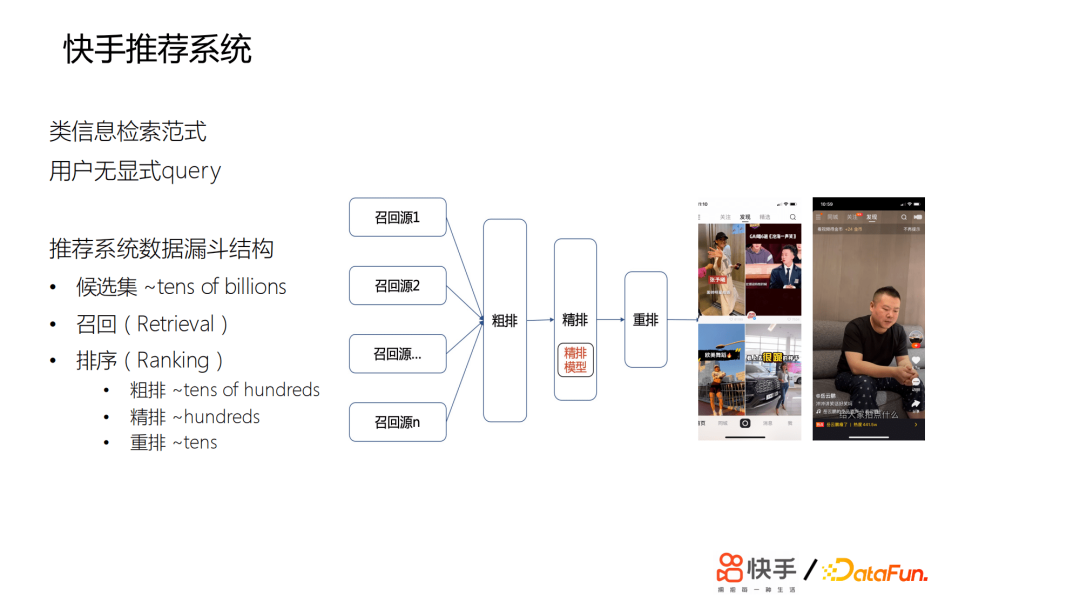
用户的交互类型非常多,场景复杂。这里简单展示一下,主要有主站的双列发现页、主站精选、极速版发现页,这些主要是用来帮助用户发现可能感兴趣的视频,还有关注页、同城页。除了短视频之外,还有直播、电商直播的推荐。对于整个推荐系统来说,我们最大的挑战是如何为用户的兴趣精准建模。

--

这是我们2019年的模型,ctr的个性化预估是推荐系统的核心,主要用来预估用户对视频会不会点击,预估效果直接影响用户体验。
从业界的演化来看,一方面是从特征的交叉角度,另一方面是从用户的行为序列建模来提升模型个性化。这里DNN核心为全连接网络。
特征全局共享,主要用来捕捉全局用户和短视频的特征。要做到真正的千人千面,需要用户个性化的特征更强一些。所以当时我们探索了如何为DNN网络增加个性化。我们尝试了一些方法,最开始尝试用stacking的方法,在最顶层或中间加一些user独有的一些网络,对网络的参数,每个用户是不同的,但是收益甚微。然后我们尝试了另外一种方式,受LHUC的启发,思想来源于语音识别,给每个用户学习个性化的偏置项。
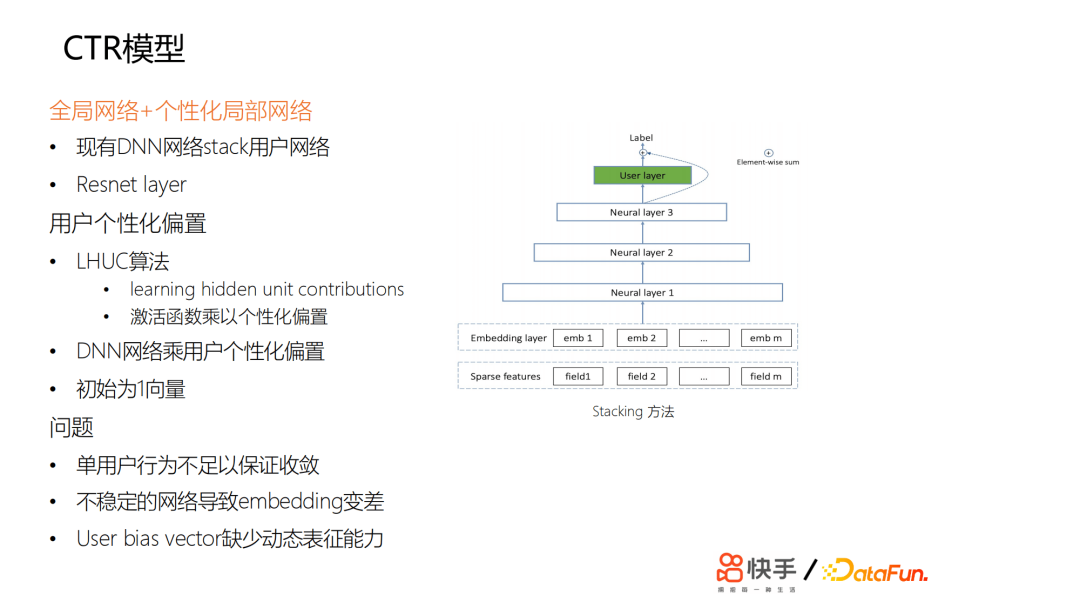
在网络输出的激活函数那里,设置了个性化的偏置项,可以认为是给每个用户学了一个bias和一个vector。我们做了一些尝试,但是基本上没有太大的收益。
我们发现一些问题,总结来说,首先是用户每天刷的样本不足以让网络的参数收敛,因为参数量相对来说比较少,这相当于是给一个用户学一个最宽的一个id的embedding向量。
另外用户每天都在上传新的视频,我们推荐的视频,主要约束在两天以内,所以会有一个视频冷启动的问题,而且基于流式训练,会导致训练样本中各方面的噪声非常大,如果是一个不稳定的网络,也会导致embedding的效果变差。如果只是简单学一个优质的id的embedding,则缺少足够的动态表达能力。另外,如果只是通过bp的方法传导梯度来更新id的embedding,其修正能力非常慢。最终我们在lte的基础上设计了一个pnet,以全局共享为基础,进行个性化的微调;我们又设计了gate网络来拟合个性化的参数:
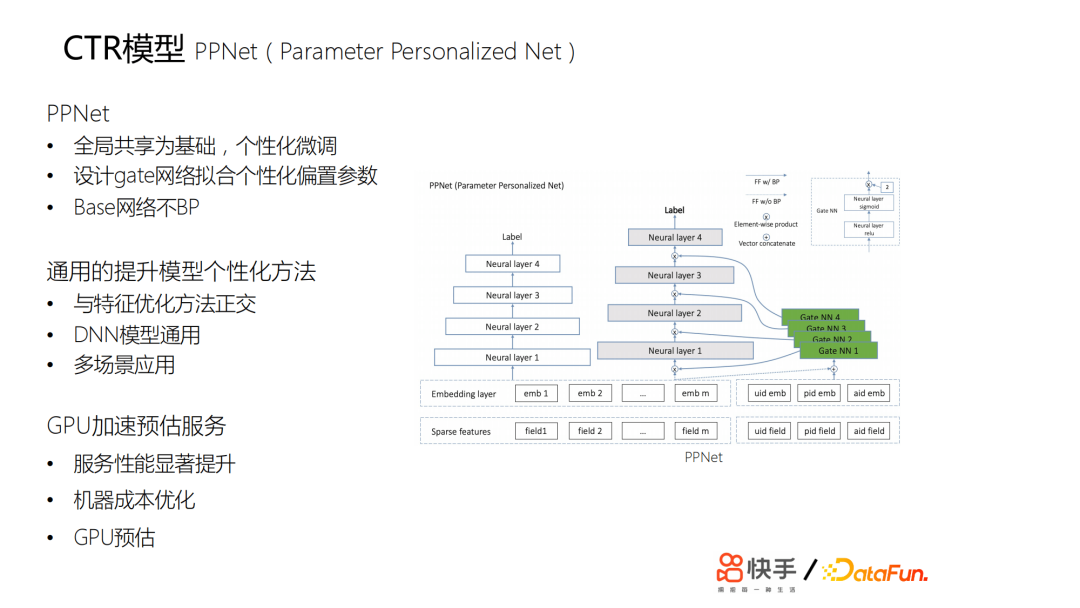
这两部分的网络也就是ppnet的网络结构。上线后,收益非常明显。包括所有用户细分上提升都是非常明显的,特别是一些行为比较稀疏的用户,他们的提升非常大,因为他们的行为相对来说比较少,之前的两个方案模型很难学到他们的一些特征。这套方案给我们提供了一个比较通用的提升模型个性化的方法。
我们推广到了一些其他场景,实现多场景应用。但是这个算法的计算量比较大,因此我们对线上的预估服务做了一次升级——原来是cpu预估,我们在2019年10月份做了gpu加速预估。
--

快手的产品场景非常多样,包括主站发现页、主站精选、发现页内流、极速版发现页等。另一方面,人群多样化,包括新用户、老用户、激活用户等。另外,这两个场景正交,就有几十个目标。因此,我们要预估的目标也会非常多。这样会存在一系列的问题,比如业务独占模型会导致训练资源低效、迭代低效、业务间不共享网络等。为了解决这些问题,我们在模型融合场景下做了多任务学习。

对于模型融合,我们做了很多工作,比如特征语义对齐,主要包括删减无用特征,改正语义不一致特征,添加单列播放列表类特征、交叉特征;embedding空间的对齐,通过Embedding transform gate,直接学习映射关系;特征重要性对齐,这里用到了slot gate,主要参考了前面提到的ppnet里面的gate设计方案。在不同的场景下,不同的用户或视频,对于特征的重要性选择,gate会把它约束在0~2,均值是1,动态选择这个特征是重要还是不重要,这样我们可以将样本的特征做一个比较好的对齐。最后,我们做了一个多目标的mmoe,动态建模目标之间的关系,每个task tower输入添加个性化偏置项。通过上面的工作,我们成功将在线与离线的模型融合成一套模型,全业务推全,用户交互涨幅提升近10%,效果显著。
--
接下来介绍短期行为序列建模的工作,在2019年初,快手交互场景越来越多,同时出现了单双列的交互体验,单双列业务下用户行为序列存在差异。单列剥夺了用户主动点的权利,用户更多是被动来看推荐系统推荐的短视频,因此,单列更适合作E&E。双列的交互体验下用户获得的主动性、可选择性强,用户的点击历史没有太多的特征可以学习,用户会不断地释放自己想看的内容,释放自己的欲望,可能会一直不断地在看相关的一些内容。我们当时做了一些尝试,发现RNN表现不如sum pooling,其相关性大于时序性。因此我们对算法做了四个方面的改进:
① 使用encoder部分:对历史序列进行表征
② 使用用户视频播放历史序列
③ Transformer layer self attention替为target attention
④ log(now - 视频观看时间戳) 代替position embedding
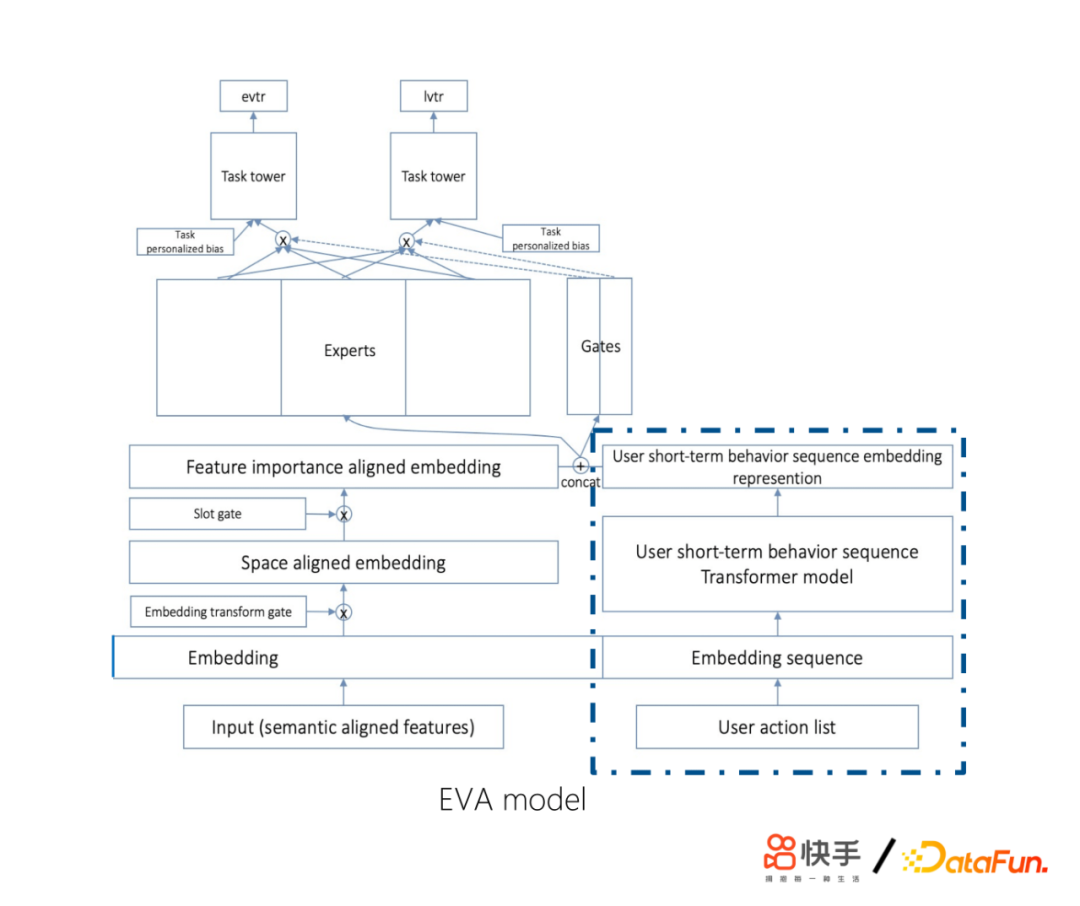
首先,使用encoder部分对历史序列进行表征。其次,使用用户视频播放历史序列,因为里面包含用户更多信息(观看时长、交互label)。另外,将Transformer layer self attention替换为target attention,主要是self attention无明显收益,然后使用当前embeding层对sequence做attention,因为我们认为对用户的行为历史作为监测的时候,不应该只看要推荐的这个视频,我们还会关注这是一个什么用户,这个用户的上下文信息是非常有用的。最后,使用log(现在时间-视频观看时间)代替position embedding,因为最近观看视频更相关,log处理更合适。上线之后,取得了非常大的收益。
--
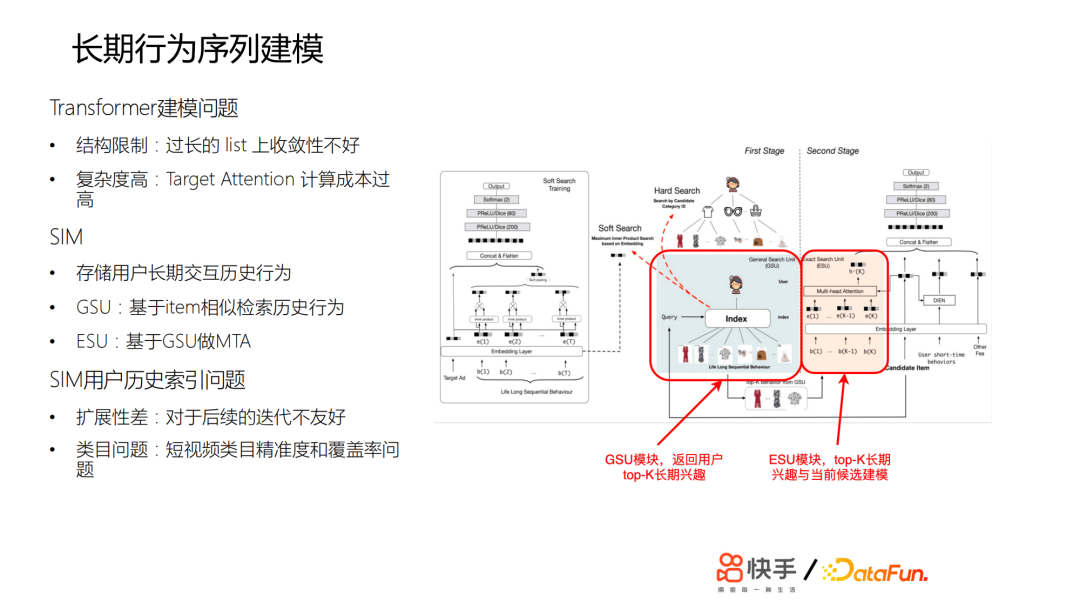
推荐系统拥有短期记忆,容易导致信息茧房或者出现多样性不足的一些问题。但是在长期行为建模的时候又遇到了各种问题,比如:Transformer建模问题,SIM用户历史索引问题等。Transformer建模容易出现结构限制,模型在过长的list上收敛性不好。另外,模型复杂度高,Target Attention计算成本也会很高。SIM用户历史索引的扩展性差,对于后续的迭代不友好,而且对于短视频类目精准度和覆盖率也有问题。为了能够捕捉到用户不同程度的兴趣偏好,我们迭代了两个版本模型,作了很多探索和改进。
下面介绍快手在长期行为序列建模的工作。
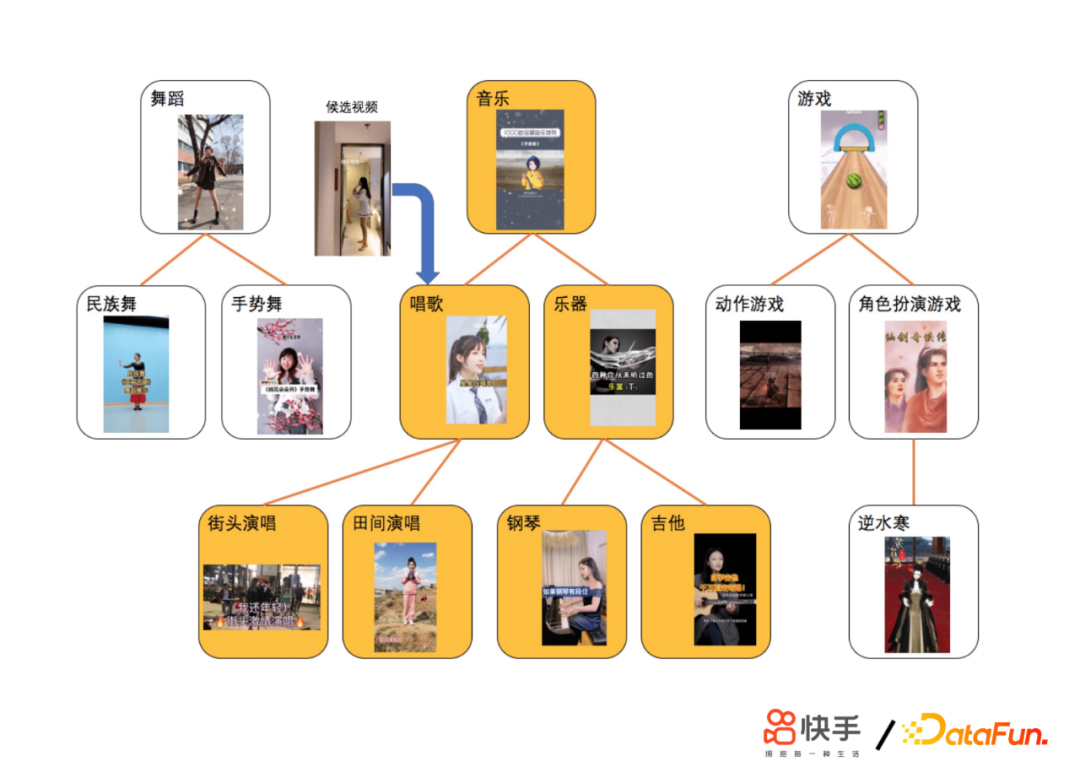
为了应对上面提到的一些问题,我们采用了独立存储方案,依托AEP高密度存储设备直接存储用户超长行为历史;进一步完善类目体系;GSU检索采用回溯补全算法,最大路径匹配的算法衡量相似度;ESU采用短时。关于Transformer方案,难点在于计算量增加,因此我们进行了算法优化;合并相同Tag候选视频的搜索过程;提前建立类目倒排链,简化搜索流程;成本优化,利用线上 GPU 推理服务器的闲置 CPU 资源。通过这些尝试,我们做到了让SIM算法首次在短视频推荐落地;在业界首次覆盖用户历史至年,这是数万级别的;收益巨大,建立了护城河;扩展到了其他场景。
后面又做了第二个版本,基于视频内容embedding的聚类。采用GSU检索算法:优先聚类内视频;最近聚类补全;近似做了余弦相似度检索。
其次,又节省了余弦相似度计算量。通过这些工作,我们取得了一些成果:建立了快手特色的长期行为建模机制;收益巨大,建立了护城河;扩展到了其他场景。
经过这两版的迭代,整体效果提升明显,人均app使用时长提升显著,其中我们的工作做了非常多的贡献。
--
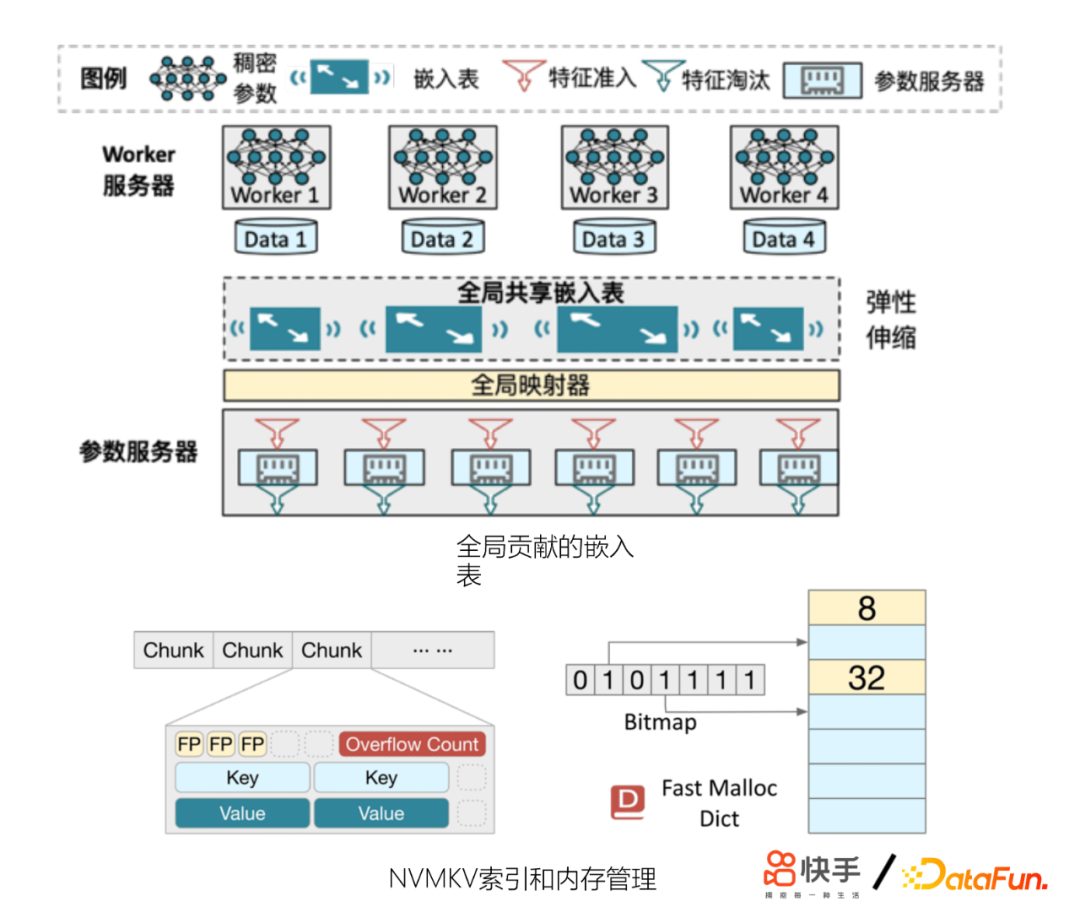
另外,我们发现模型的特征量还会制约模型精排的效果。模型收敛不稳定,模型更容易逐出低频特征、冷启动效果变差等。为此,我们在工程上做了一些优化,也起到了非常好的收益。主要包括:
--
对于未来优化的重点,我们会放在模型融合,多任务学习方向。另外用户长短期兴趣怎样更好得建模和融合,以及用户的留存建模也是我们未来优化的重点。
今天的分享就到这里,谢谢大家。
本文首发于微信公众号“DataFunTalk”。
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里