\qquad
Transformer最早起源于论文Attention is all your need,是谷歌云TPU推荐的参考模型。
\qquad
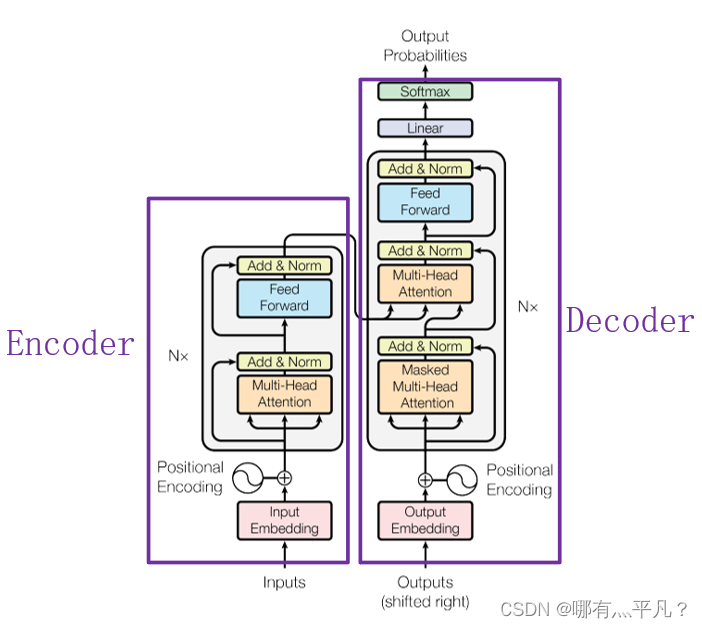
目前,在NLP领域当中,主要存在三种特征处理器——CNN、RNN以及Transformer,当前Transformer的流行程度已经大过CNN和RNN,它抛弃了传统CNN和RNN神经网络,整个网络结构完全由Attention机制以及前馈神经网络组成。首先给出一个来自原论文的Transformer整体架构图方便之后回顾。
 \qquad
上图中的Transformer可以说是一个使用“self attention”的Seq2seq模型。
\qquad
上图中的Transformer可以说是一个使用“self attention”的Seq2seq模型。
那么要想了解Transformer,就必须先了解"self attention"。
\qquad
如果给出一个Sequence要处理,最常想到的可能就是RNN了,如下图1所示。RNN被经常使用在输入是有序列信息的模型中,但它也存在一个问题——它不容易被“平行化”。那么“平行化”是什么呢?
\qquad
比如说在RNN中a1,a2,a3,a4就是输入,b1,b2,b3,b4就是输出。对于单向RNN,如果你要输出b3那么你需要把a1,a2,a3都输入并运算了才能得到;对于双向RNN,如果你要输出任何一个bi,那么你要把所有的ai都输入并运算过才能得到。它们无法同时进行运算得出b1,b2,b3,b4。

\qquad
而针对RNN无法“平行化”这个问题,有人提出了使用CNN来取代RNN,如下图所示。输入输出依然为ai、bi。它利用一个个Filter(如下图黄色三角形)(我的理解是类似于计网的滑动窗口协议)去得出相应的输出,比如b1是通过a1,a2一起得出;b2是通过a1,a2,a3得出。可能会存在一个疑问——这样不就只考虑临近输入的信息,而对长距离信息没有考虑了?
\qquad
当然不是这样,它可以考虑长距离信息的输入,只需要在输出bi上再叠加一层Filters就能涵盖更多的信息,如下图黄色三角形,所有输入ai运算得出b1,b2,b3作为该层的输入。所以说只要你叠加的层数够多,它可以包含你所有的输入信息。
\qquad
回到咱们对“平行化”问题的解答:使用CNN是可以做到“平行化”的,下图中每一个蓝色的三角形,并不用等前面的三角形执行完才能执行,它们可以同时进行运算。

\qquad
self attention模型输入的xi先做embedding得到ai,每一个xi都分别乘上三个不同的w得到q、k、v。
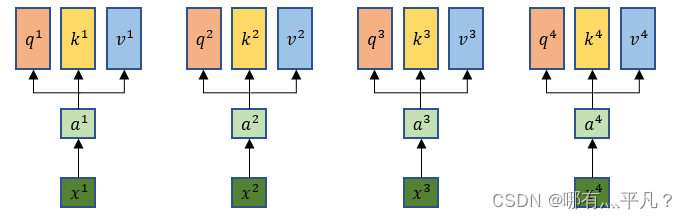
其中:
\qquad
\qquad
\qquad
\qquad
a
i
=
W
x
i
\ a^i=Wx^i
ai=Wxi
\qquad
\qquad
\qquad
\qquad
\qquad
q
i
=
W
q
a
i
\ q^i=W^qa^i
qi=Wqai
\qquad
\qquad
\qquad
\qquad
\qquad
k
i
=
W
k
a
i
\ k^i=W^ka^i
ki=Wkai
\qquad
\qquad
\qquad
\qquad
\qquad
v
i
=
W
v
a
i
\ v^i=W^va^i
vi=Wvai
拿每个qi去对每个ki做点积得到
a
1
,
i
\ a_{1,i}
a1,i,其中d是q和k的维度。
\qquad
\qquad
\qquad
\qquad
\qquad
a
1
,
i
=
q
1
⋅
k
i
/
d
\ a_{1,i}=q^1·k^i/{\sqrt d}
a1,i=q1⋅ki/d

再把
a
1
,
i
\ a_{1,i}
a1,i经过一个Soft-max之后得到
a
^
1
,
i
\hat a_{1,i}
a^1,i
a
^
1
,
i
=
e
x
p
(
a
1
,
i
)
/
∑
j
e
x
p
(
a
1
,
j
)
\hat a_{1,i} =exp(a_{1,i})/\sum_{j} exp(a_{1,j})
a^1,i=exp(a1,i)/j∑exp(a1,j)

\qquad
接下来把
a
^
1
,
j
\hat a_{1,j}
a^1,j与对应的
v
j
v^j
vj分别做乘积最后求和得出第一个输出
b
1
b_1
b1,同理可得到所有
b
i
b_i
bi。
b
1
=
∑
i
n
a
^
1
,
i
v
i
b^1 =\sum_{i}^n \hat a_{1,i}v^i
b1=i∑na^1,ivi
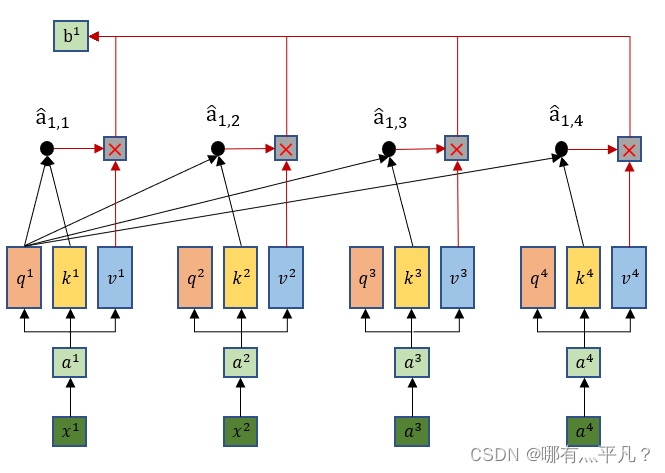
\qquad 那么到这里就可以看出输出b1是综合了所有的输入xi信息,同时这样做的优势在于——当b1只需要考虑局部信息的时候(比如重点关注x1,x2就行了),那么它可以让 a ^ 1 , 3 \hat a_{1,3} a^1,3和 a ^ 1 , 4 \hat a_{1,4} a^1,4输出的值为0就行了。
咱们复习一下前面说到的q、k、v的计算:
\qquad
\qquad
\qquad
\qquad
\qquad
q
i
=
W
q
a
i
\ q^i=W^qa^i
qi=Wqai
\qquad
\qquad
\qquad
\qquad
\qquad
k
i
=
W
k
a
i
\ k^i=W^ka^i
ki=Wkai
\qquad
\qquad
\qquad
\qquad
\qquad
v
i
=
W
v
a
i
\ v^i=W^va^i
vi=Wvai
\qquad
因为
q
1
=
w
q
a
1
\ q^1=w^qa^1
q1=wqa1,那么根据矩阵运算原理,我们将
a
1
、
a
2
、
a
3
、
a
4
\ a^1、a^2、a^3、a^4
a1、a2、a3、a4串起来作为一个矩阵I与
w
q
\ w^q
wq相乘可以得到
q
1
、
q
2
、
q
3
、
q
4
\ q^1、q^2、q^3、q^4
q1、q2、q3、q4构成的矩阵Q。同理可得
k
i
、
v
i
\ k^i、v^i
ki、vi的矩阵K、V。
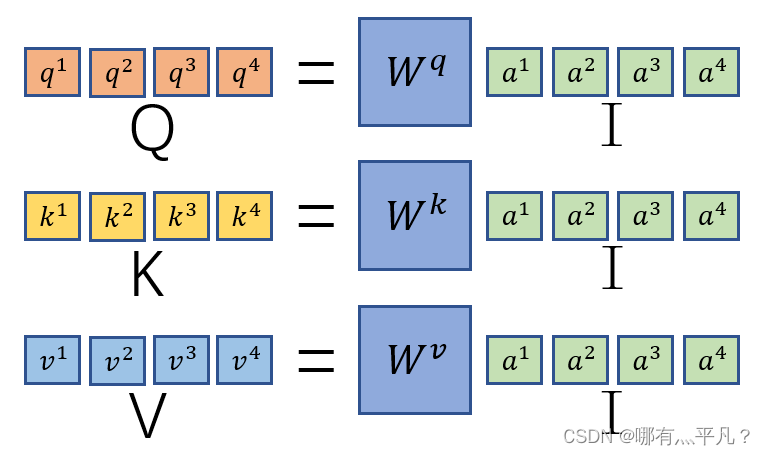
然后我们再回忆观察一下
a
1
,
i
\ a_{1,i}
a1,i的计算过程(为方便理解,此处省略
d
\sqrt d
d):
\qquad
\qquad
\qquad
a
1
,
1
=
k
1
⋅
q
1
\ a_{1,1}=k^1·q^1
a1,1=k1⋅q1
\qquad
a
1
,
2
=
k
2
⋅
q
1
\ a_{1,2}=k^2·q^1
a1,2=k2⋅q1
\qquad
\qquad
\qquad
a
1
,
3
=
k
3
⋅
q
1
\ a_{1,3}=k^3·q^1
a1,3=k3⋅q1
\qquad
a
1
,
4
=
k
4
⋅
q
1
\ a_{1,4}=k^4·q^1
a1,4=k4⋅q1
\qquad
我们可以发现计算都是用
q
1
\ q^1
q1去乘以每个
k
i
\ k^i
ki得出
a
1
,
i
\ a_{1,i}
a1,i,那么我们将
k
i
\ k^i
ki叠加起来与
q
1
\ q^1
q1相乘得到一列向量
a
1
,
i
\ a_{1,i}
a1,i(i=1,2,3,4)。然后你再加上所有的
q
i
\ q^i
qi就可以得到整个
a
i
,
j
\ a_{i,j}
ai,j矩阵。最后对
a
i
,
j
\ a_{i,j}
ai,j的每一列做一个soft-max就得到
a
^
i
,
j
\hat a_{i,j}
a^i,j矩阵。
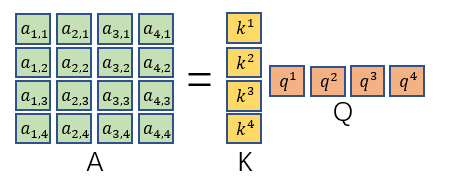
最后再把
a
^
i
,
j
\hat a_{i,j}
a^i,j与所有
v
i
\ v^i
vi构成的矩阵V相乘即可得到输出。
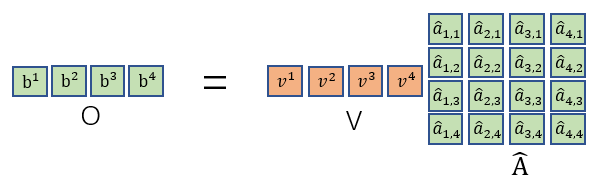
\qquad
在这里我们对输入I到输出O之间做的事情做一个总结:我们先用I分别乘上对应的
W
i
\ W^i
Wi得到矩阵Q,K,V,再把Q与
K
T
\ K^T
KT相乘得到矩阵A,再对A做soft-max处理得到矩阵KaTeX parse error: Expected group after '^' at position 7: \hat A^̲,最后再将KaTeX parse error: Expected group after '^' at position 7: \hat A^̲与V相乘得到输出结果O。整个过程都是进行矩阵乘法,都可以使用GPU加速。
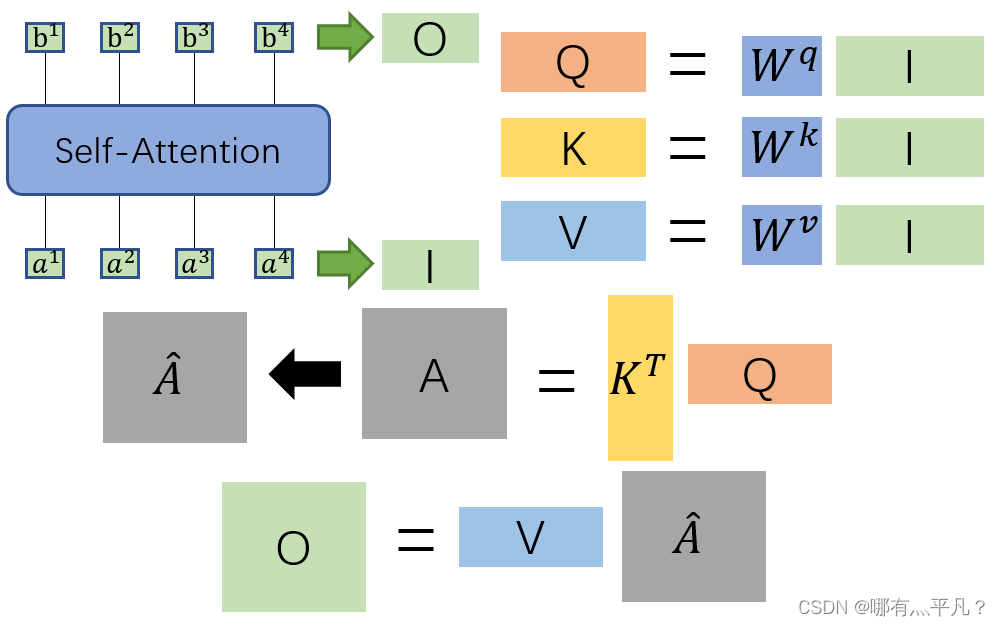
\qquad
Multi-head Self-attention跟self-attention一样都会生成q、k、v,但是Multi-head Self-attention会再将q、k、v分裂出多个
q
1
,
2
\ q^{1,2}
q1,2(这里举例分裂成两个),然后它也将q跟k去进行相乘计算,但是只跟其对应的k、v进行计算,比如
q
1
,
1
\ q^{1,1}
q1,1只会与
k
1
,
1
\ k^{1,1}
k1,1、
k
2
,
1
\ k^{2,1}
k2,1进行运算,然后一样的乘以对应的v得到输出
b
1
,
1
\ b^{1,1}
b1,1。
\qquad
\qquad
\qquad
q
1
,
1
=
W
q
,
1
q
1
\ q^{1,1}=W^{q,1}q^1
q1,1=Wq,1q1
\qquad
\qquad
q
1
,
2
=
W
q
,
2
q
1
\ q^{1,2}=W^{q,2}q^1
q1,2=Wq,2q1
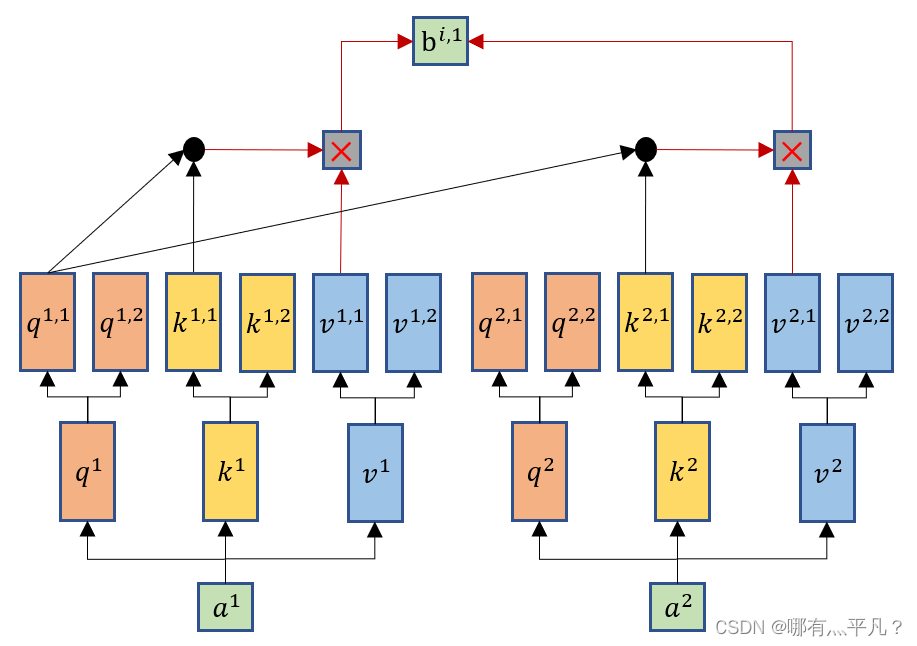
\qquad
对于
b
i
,
1
\ b^{i,1}
bi,1再进行一步处理就得到我们在self-attention所做的一步骤的输出
b
i
\ b^i
bi。
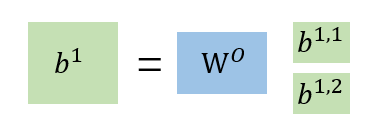
那么这个Multi-head Self-attention设置多个q,k,v有什么好处呢?
\qquad
举例来说,有可能不同的head关注的点不一样,有一些head可能只关注局部的信息,有一些head可能想要关注全局的信息,有了多头注意里机制后,每个head可以各司其职去做自己想做的事情。
Positional Encoding
\qquad
根据前面self-attention介绍中,我们可以知道其中的运算是没有去考虑位置信息,而我们希望是把输入序列每个元素的位置信息考虑进去,那么就要在
a
i
\ a^i
ai这一步还有加上一个位置信息向量
e
i
\ e^i
ei,每个
e
i
\ e^i
ei都是其对应位置的独特向量。——
e
i
\ e^i
ei是通过人工手设(不是学习出来的)。

最后挂上一张来自原论文的效果图,体验一下transformer的强大:

目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
文章目录1.任务背景2.任务目标3.相关知识点4.任务实操4.1安装配置JDK4.2启动FISCOBCOS4.3下载解压WeBASE-Front4.4拷贝sdk证书文件4.5启动节点4.6访问节点4.7检查运行状态5.任务总结1.任务背景FISCOBCOS其实是有控制台管理工具,用来对区块链系统进行各种管理操作。但是对于初学者来说,还是可视化界面更友好,本节就来介绍WeBASE管理平台,这是一款微众银行开源的自研区块链中间件平台,可以降低区块链使用的门槛,大幅提高区块链应用的开发效率。微众银行是腾讯牵头设立的民营银行,在国内民营银行里还是比较出名的。微众银行参与FISCOBCOS生态建设,一定
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建