就是多版本并发控制。MVCC 是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问。
为什么需要MVCC呢?数据库通常使用锁来实现隔离性。最原生的锁,锁住一个资源后会禁止其他任何线程访问同一个资源。但是很多应用的一个特点都是读多写少的场景,很多数据的读取次数远大于修改的次数,而读取数据间互相排斥显得不是很必要。所以就使用了一种读写锁的方法,读锁和读锁之间不互斥,而写锁和写锁、读锁都互斥。这样就很大提升了系统的并发能力。之后人们发现并发读还是不够,又提出了能不能让读写之间也不冲突的方法,就是读取数据时通过一种类似快照的方式将数据保存下来,这样读锁就和写锁不冲突了,不同的事务session会看到自己特定版本的数据。当然快照是一种概念模型,不同的数据库可能用不同的方式来实现这种功能。
全称Multi-Version Concurrency Control,即多版本并发控制,主要是为了提高数据库的并发性能。PS:基于InnoDB引擎的默认事务机制可重复读来讲的,因为Mylsam不支持事务。
同一行数据平时发生读写请求时,会上锁阻塞住。当读为快照读时mvcc用更好的方式去处理读—写请求,做到在发生读—写请求冲突时不用加锁。
select .. for update 即当前读是一种加锁操作,是悲观锁。
那它到底是怎么做到读—写不用加锁的,快照读和当前读又是什么。
当前读:它读取的数据都是当前最新的数据,会对读取到的数据进行加锁,防止其他事务修改其数据,是悲观锁的一种,这里不做展开。
例如如下操作:
快照读:最基础的不加锁的select操作
快照读的实现是基于多版本并发控制,即MVCC,既然是多版本,那么快照读读到的数据不一定是当前最新的数据,有可能是之前历史版本的数据。
MVCCC是“维持一个数据的多个版本,使读写操作没有冲突”的一个抽象概念。
这个概念需要具体功能去实现,这个具体实现就是快照读。
读-读:不存在任何问题,也不需要并发控制读-写:有线程安全问题,可能会造成事务隔离性问题,可能遇到脏读,幻读,不可重复读写-写:有线程安全问题,可能会存在更新丢失问题,比如第一类更新丢失,第二类更新丢失mvcc用来解决读—写冲突的无锁并发控制,就是为事务分配单向增长的时间戳。为每个数据修改保存一个版本,版本与事务时间戳相关联。
读操作只读取该事务开始前的数据库快照。
解决问题如下:
并发读-写时:可以做到读操作不阻塞写操作,同时写操作也不会阻塞读操作。脏读、大部分幻读、不可重复读等事务隔离问题,但不能解决上面的写-写 更新丢失问题。(PS:不能完全解决幻读)它的实现原理主要是版本链,undo日志 ,Read View 来实现的
在InnoDB引擎表中,它的聚簇索引记录中有两个必要的隐藏列:
trx_id这个id用来存储的每次对某条聚簇索引记录进行修改的时候的事务id。
roll_pointe每次对哪条聚簇索引记录有修改的时候,都会把老版本写入undo日志中。这个roll_pointer就是存了一个指针,它指向这条聚簇索引记录的上一个版本的位置,通过它来获得上一个版本的记录信息。(注意插入操作的undo日志没有这个属性,因为它没有老版本)(实现版本链的关键)
row_id,隐含的自增ID(隐藏主键),如果数据表没有主键,InnoDB会自动以db_row_id产生一个聚簇索引。
删除flag隐藏字段, 记录被更新或删除并不代表真的删除,而是删除flag变了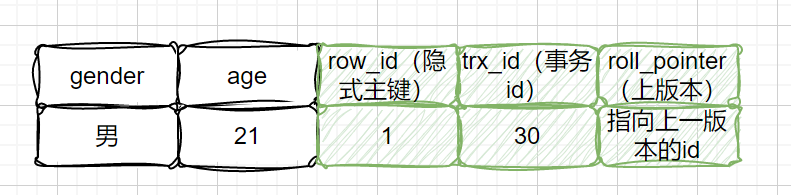
如上图,row_id是数据库默认为该行记录生成的唯一隐式主键,trx_id是当前操作该记录的事务ID,而roll_pointer是一个回滚指针,用于配合undo日志,指向上一个旧版本。
若此时执行下列语句。
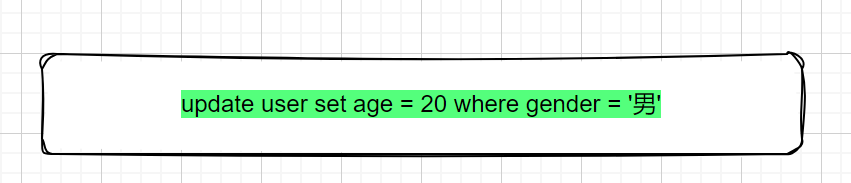
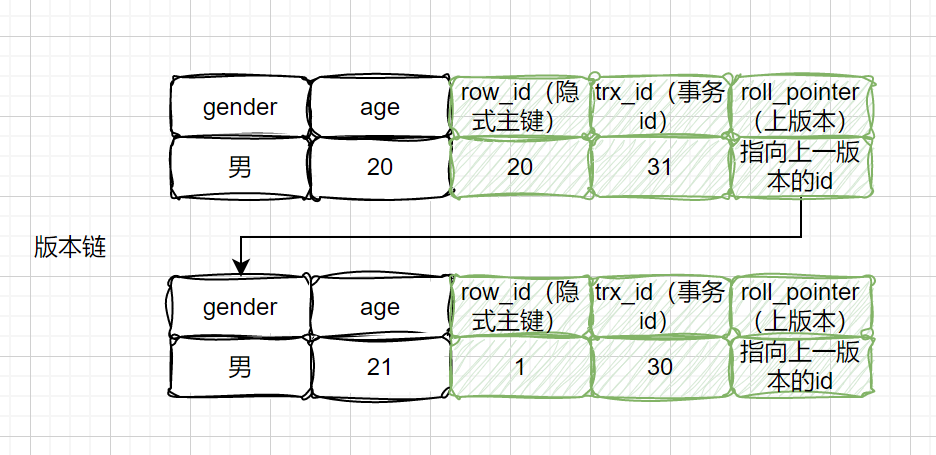
更新后的版本链:
Undo log 主要用于记录数据被修改之前的日志,在表信息修改之前先会把数据拷贝到undo log里。
当事务进行回滚时可以通过undo log 里的日志进行数据还原。
Undo log 的用途
事务进行rollback时的原子性和一致性,当事务进行回滚的时候可以用undo log的数据进行恢复。快照读的数据,在MVCC多版本控制中,通过读取undo log的历史版本数据可以实现不同事务版本号都拥有自己独立的快照数据版本。undo log主要分为两种:
insert undo log
代表事务在insert新记录时产生的undo log , 只在事务回滚时需要,并且在事务提交后可以被立即丢弃
update undo log(主要)
事务在进行update或delete时产生的undo log ; 不仅在事务回滚时需要,在快照读时也需要;
所以不能随便删除,只有在快速读或事务回滚不涉及该日志时,对应的日志才会被purge线程统一清除
事务进行快照读操作的时候生产的读视图(Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照。
记录并维护系统当前活跃事务的ID(没有commit,当每个事务开启时,都会被分配一个ID, 这个ID是递增的,所以越新的事务,ID值越大),是系统中当前不应该被本事务看到的其他事务id列表。
Read View主要是用来做可见性判断的, 即当我们某个事务执行快照读的时候,对该记录创建一个Read View读视图,把它比作条件用来判断当前事务能够看到哪个版本的数据,既可能是当前最新的数据,也有可能是该行记录的undo log里面的某个版本的数据。
Read View几个属性
trx_ids: 当前系统活跃(未提交)事务版本号集合。low_limit_id: 创建当前read view 时“当前系统最大事务版本号+1”。up_limit_id: 创建当前read view 时“系统正处于活跃事务最小版本号”creator_trx_id: 创建当前read view的事务版本号;一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
min_trx_id 值,表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务可见。max_trx_id 值,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务不可见。min_trx_id和max_trx_id之间,需要判断 trx_id是否在m_ids 列表中:
m_ids 列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)。
db_trx_id < up_limit_id || db_trx_id == creator_trx_id(显示)
如果数据事务ID小于read view中的最小活跃事务ID,则可以肯定该数据是在当前事务启之前就已经存在了的,所以可以显示。
或者数据的事务ID等于creator_trx_id ,那么说明这个数据就是当前事务自己生成的,自己生成的数据自己当然能看见,所以这种情况下此数据也是可以显示的。
db_trx_id >= low_limit_id(不显示)
如果数据事务ID大于read view 中的当前系统的最大事务ID,则说明该数据是在当前read view 创建之后才产生的,所以数据不显示。如果小于则进入下一个判断
db_trx_id是否在活跃事务(trx_ids)中
不存在:则说明read view产生的时候事务已经commit了,这种情况数据则可以显示。已存在:则代表我Read View生成时刻,你这个事务还在活跃,还没有Commit,你修改的数据,我当前事务也是看不见的。上面所讲的Read View用于支持RC(Read Committed,读提交)和RR(Repeatable Read,可重复读)隔离级别的实现。
RC隔离级别下,是每个快照读都会生成并获取最新的Read View;RR隔离级别下,则是同一个事务中的第一个快照读才会创建Read View, 之后的快照读获取的都是同一个Read View,之后的查询就不会重复生成了,所以一个事务的查询结果每次都是一样的。快照读:通过MVCC来进行控制的,不用加锁。按照MVCC中规定的“语法”进行增删改查等操作,以避免幻读,没有完全解决。当前读:通过next-key锁(行锁+gap锁)来解决问题的。从以上的描述中我们可以看出来,所谓的MVCC指的就是在使用READ COMMITTD、REPEATABLE READ这两种隔离级别的事务在执行普通的SEELCT操作时访问记录的版本链的过程,这样子可以使不同事务的读-写、写-读操作并发执行,从而提升系统性能。
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭3年前。Improvethisquestion我正处于学习Ruby的阶段,我想查看一些小型库的源代码以了解它们是如何构建的。我不知道什么是小型图书馆,但希望SO能推荐一些易于理解的图书馆来学习。因此,如果有人知道一两个非常小的库,这是新手Rubyists学习的好例子,请推荐!我想使用Manveru'sInnatelib,因为它试图保持在2000LOC以下,但我还不熟悉其中经常使用的Ruby速记。也许大约100-5
由于匿名block和散列block看起来大致相同。我正在玩它。我做了一些严肃的观察,如下所示:{}.class#=>Hash好的,这很酷。空block被视为Hash。print{}.class#=>NilClassputs{}.class#=>NilClass为什么上面的代码和NilClass一样,下面的代码又显示了Hash?puts({}.class)#Hash#=>nilprint({}.class)#Hash=>nil谁能帮我理解上面发生了什么?我完全不同意@Lindydancer的观点你如何解释下面几行:print{}.class#NilClassprint[].class#A
我很难理解Ruby中sender和receiver的实际含义。它们一般是什么意思?到目前为止,我只是将它们理解为方法调用和获取其返回值的调用。但是,我知道我的理解还远远不够。谁能给我一个Ruby中发送者和接收者的具体解释? 最佳答案 面向对象中的一个核心概念是消息传递和早期概念化,这在很大程度上借鉴了计算的Actor模型。艾伦·凯(AlanKay)创造了面向对象一词并发明了最早的OO语言之一SmallTalk,他拥有voicedregretatusingatermwhichputthefocusonobjectsinsteadofo
rails新手。只是想了解\assests目录中的这两个文件。例如,application.js文件有如下行://=requirejquery//=requirejquery_ujs//=require_tree.我理解require_tree。只是将所有JS文件添加到当前目录中。根据上下文,我可以看出requirejquery添加了jQuery库。但是它从哪里得到这些jQuery库呢?我没有在我的Assets文件夹中看到任何jquery.js文件——或者直接在我的整个应用程序中没有看到任何jquery.js文件?同样,我正在按照一些说明安装TwitterBootstrap(http:
我在某些代码中遇到了三元组,但我无法理解条件:str.split(/',\s*'/).mapdo|match|match[0]==?,?match:"somestring"end.join我确实理解我是在某些点上拆分字符串并将总结果转换为数组,然后依次处理数组的每个元素。除此之外,我不知道发生了什么。 最佳答案 一种(稍微)不那么令人困惑的写法是:str.split(/',\s*'/).mapdo|match|ifmatch[0]==?,matchelse"somestring"endend.join我认为多行三元语句很糟糕,尤其是
有没有人成功地将S3存储桶读取为子文件夹?文件夹1--子文件夹2----文件3----文件4--文件1--文件2文件夹2--子文件夹3--文件5--文件6我的任务是读取文件夹1。我希望看到子文件夹2、文件1和文件2,但看不到文件3或文件4。现在,因为我将存储桶键限制为prefix=>'folder1/',你仍然会得到file3和4,因为它们在技术上具有folder1前缀。似乎真正做到这一点的唯一方法是吸收folder1下的所有键,然后使用字符串搜索从结果数组中实际排除file3和file4。有没有人有过这方面的经验?我知道像Transmit和Cyberduck这样的FTP风格的S3
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
我在理解GrapeAPI时遇到很多困难,特别是route_param以及它如何仅使用params。考虑这段代码:desc"Returnastatus."paramsdorequires:id,type:Integer,desc:"Statusid."endroute_param:iddogetdoStatus.find(param[:id])endend这个街区产生什么路线?我知道这是一个get请求,但为什么它被包裹在route_paramblock中?为什么它不能在paramsblock中? 最佳答案 你的block产生这条路线: