文章目录

本题是在栈与队列的基础上,为巩固两者而出的题,所以基本是在实现了栈与队列的基础上做的,如果没有栈与队列的基础,请看我之前的文章,数据结构之栈与队列详解
题目在225. 用队列实现栈

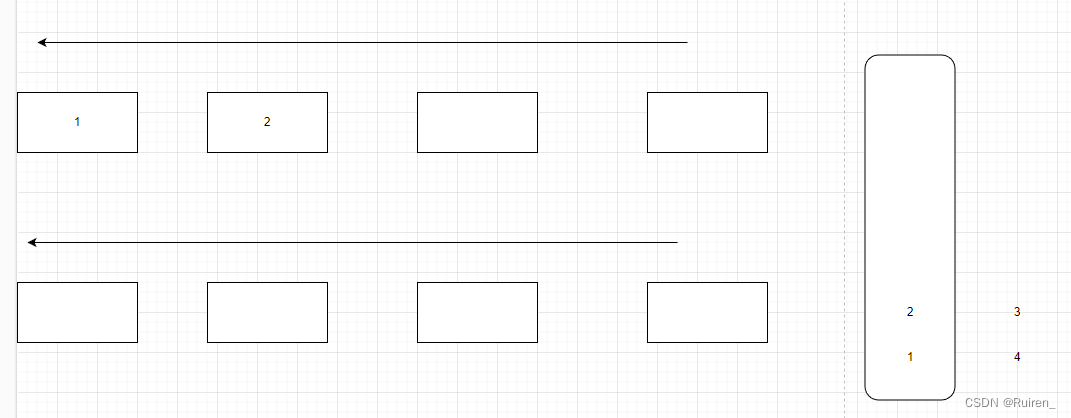
1️⃣将不为空的队列的数据导入为空的队列中至数据只剩余一个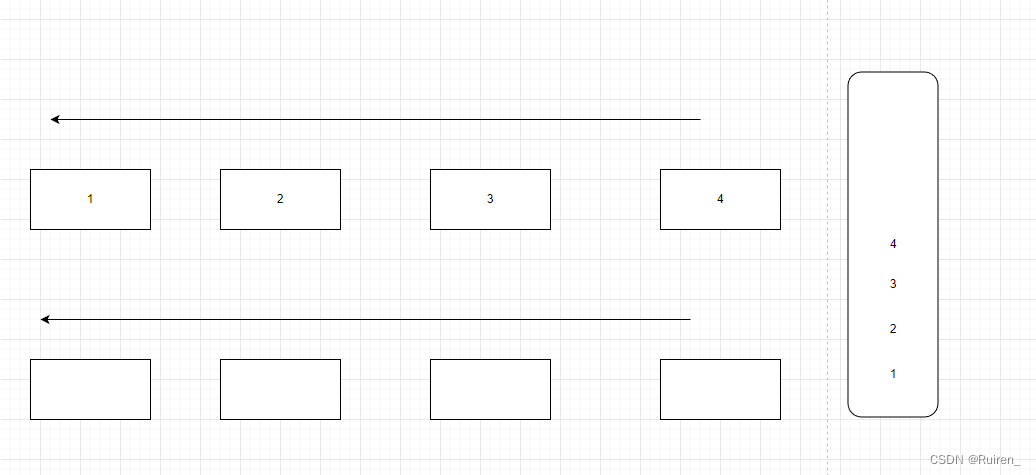
2️⃣队列出掉4,对于栈来说,就是4出栈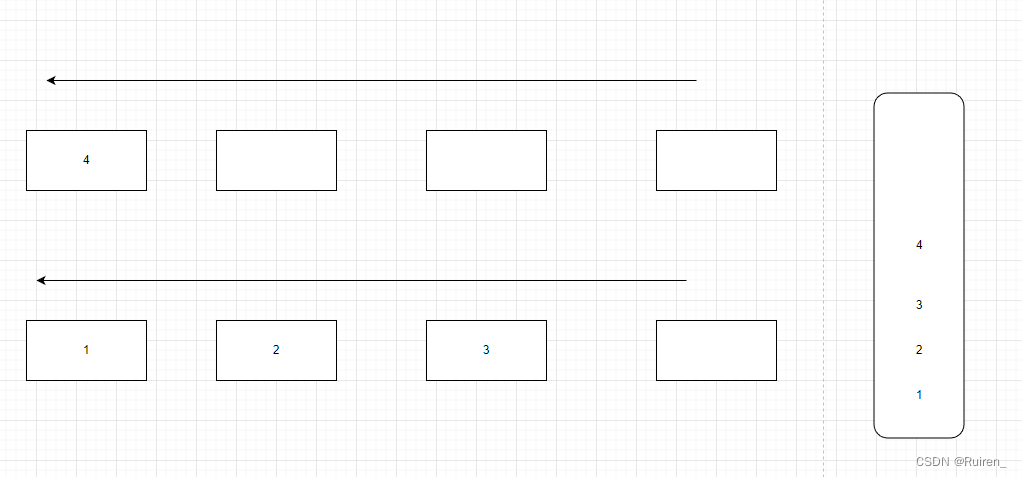
3️⃣
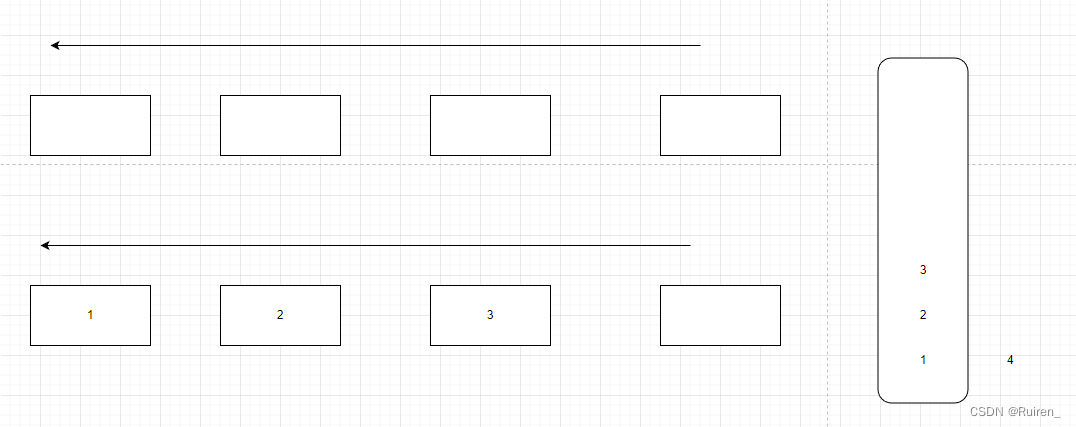
4️⃣当其中一个队列为空时,将不为空的队列的数据导入为空的队列中至数据只剩余一个
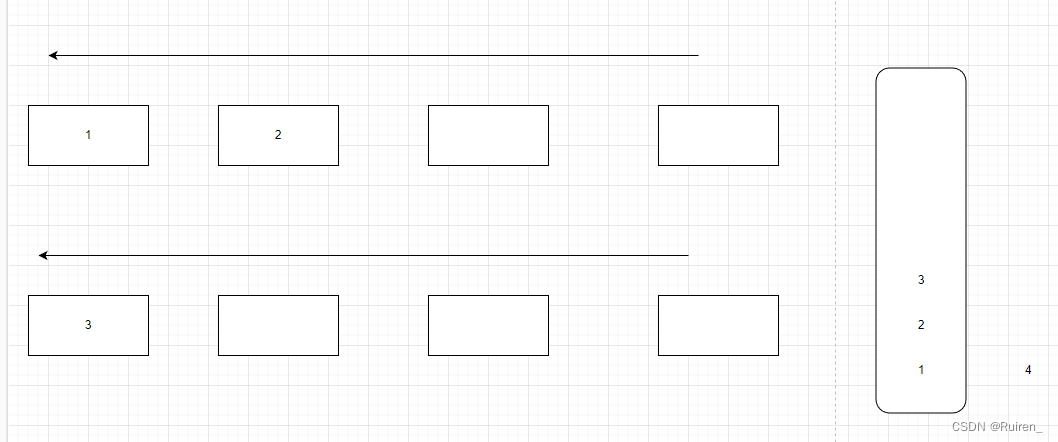
5️⃣重复上述操作
typedef char QDatatype;
typedef struct QueueNode
{
struct QueueNode* next;
QDatatype Data;
}QNode;
typedef struct Queue
{
QNode* head;
QNode* tail;
int size;
}Queue;
typedef struct
{
Queue q1;
Queue q2;
}MyStack;
void QueueInit(Queue* pq)
{
assert(pq);
pq->head = pq->tail = NULL;
pq->size = 0;
}
void QueueDestroy(Queue* pq)
{
assert(pq);
QNode* cur = pq->head;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
pq->head = pq->tail = NULL;
pq->size = 0;
}
void QueuePush(Queue* pq, QDatatype x)
{
assert(pq);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
assert(newnode);
newnode->Data = x;
newnode->next=NULL;
if (pq->size == 0)
{
pq->head =pq->tail= newnode;
}
else
{
pq->tail->next = newnode;
pq->tail = newnode;
}
pq->size++;
}
void QueuePop(Queue* pq)
{
assert(pq);
assert(pq->size);
if (pq->head->next==NULL)
{
free(pq->head);
pq->head =pq->tail= NULL;
}
else
{
QNode* next = pq->head->next;
free(pq->head);
pq->head = next;
}
pq->size--;
}
int QueueSize(Queue* pq)
{
assert(pq);
return pq->size;
}
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->size==0;
}
QDatatype QueueFront(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->head->Data;
}
QDatatype QueueBack(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->tail->Data;
}
//此位置之上属于队列的实现代码,此下为题目所需完成的
MyStack* myStackCreate() {
MyStack *pst=( MyStack *)malloc(sizeof( MyStack));
QueueInit(&pst->q1);
QueueInit(&pst->q2);
return pst;
}
void myStackPush(MyStack* obj, int x) {
assert(obj);
if(!QueueEmpty(&obj->q1))
{
QueuePush(&obj->q1,x);
}
else
{
QueuePush(&obj->q2,x);
}
}
int myStackPop(MyStack* obj) {
if(!QueueEmpty(&obj->q1))
{
while(QueueSize(&obj->q1)>1)
{
QDatatype front=QueueFront(&obj->q1);
QueuePop(&obj->q1);
QueuePush(&obj->q2,front);
}
QDatatype front=QueueFront(&obj->q1);
QueuePop(&obj->q1);
return front;
}
else
{
while(QueueSize(&obj->q2)>1)
{
QDatatype front=QueueFront(&obj->q2);
QueuePop(&obj->q2);
QueuePush(&obj->q1,front);
}
QDatatype front=QueueFront(&obj->q2);
QueuePop(&obj->q2);
return front;
}
}
int myStackTop(MyStack* obj) {
if(!QueueEmpty(&obj->q1))
{
return QueueBack(&obj->q1);
}
else
{
return QueueBack(&obj->q2);
}
}
bool myStackEmpty(MyStack* obj) {
return (QueueEmpty(&obj->q1)&&QueueEmpty(&obj->q2));
}
void myStackFree(MyStack* obj) {
QueueDestroy(&obj->q1);
QueueDestroy(&obj->q2);
free(obj);
}
题目在用栈实现队列

这题我们需要仔细思考是否还需要像上面那样来回倒腾数据,比如我给个例子
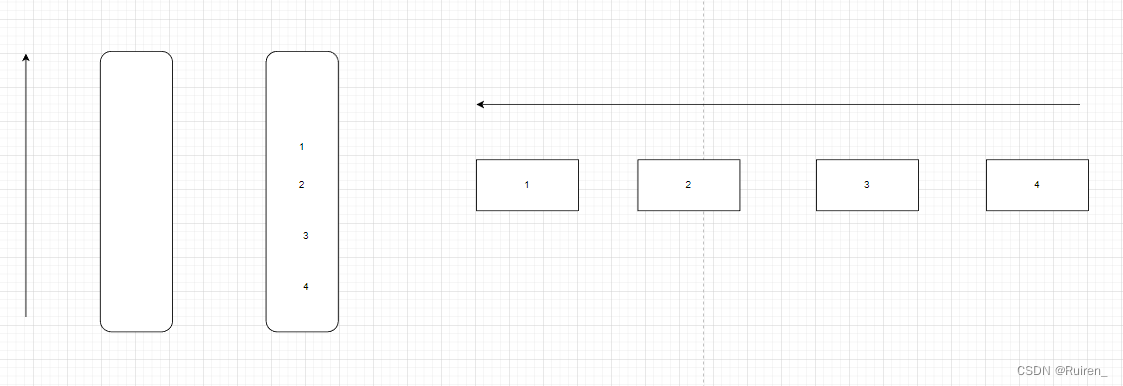
当我们出掉一个数据1后,发现我们不需要在来回倒腾了,
当我们在想出后面的时,我们一直只需要出另外一个
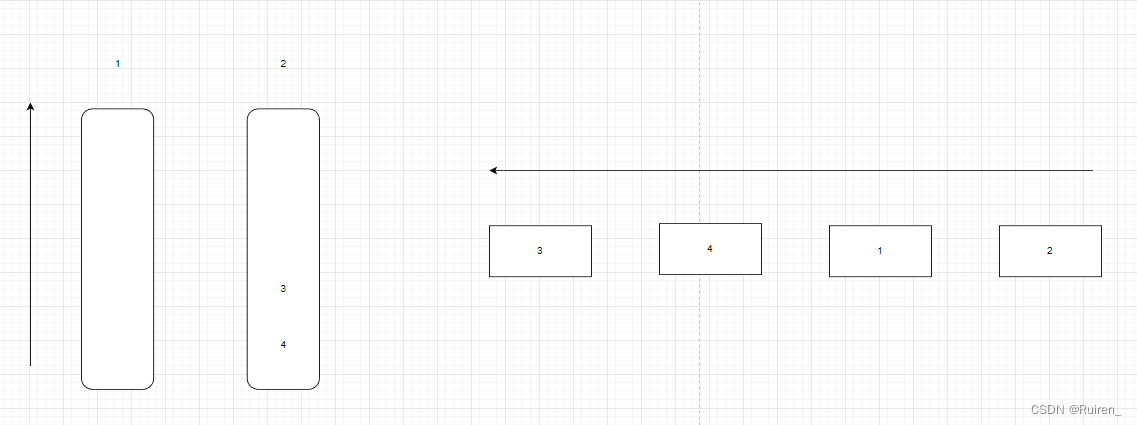
那么如果我们在出一个后需要入数据呢,我们入到什么地方去呢,比如想下面这种情况,当我们出掉1和2后,我们在队列后面入1和2,那么我们在栈里面怎么入呢,因为3,和4的那个栈需要出掉其他数据,不能入,所以我们只能操作左边的栈
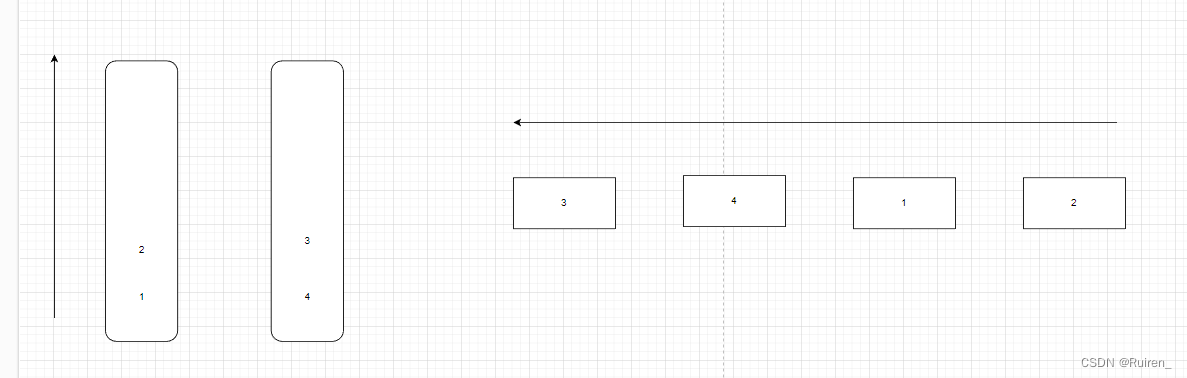
然后如果我们的右边的栈出完后,我们就重复上述操作
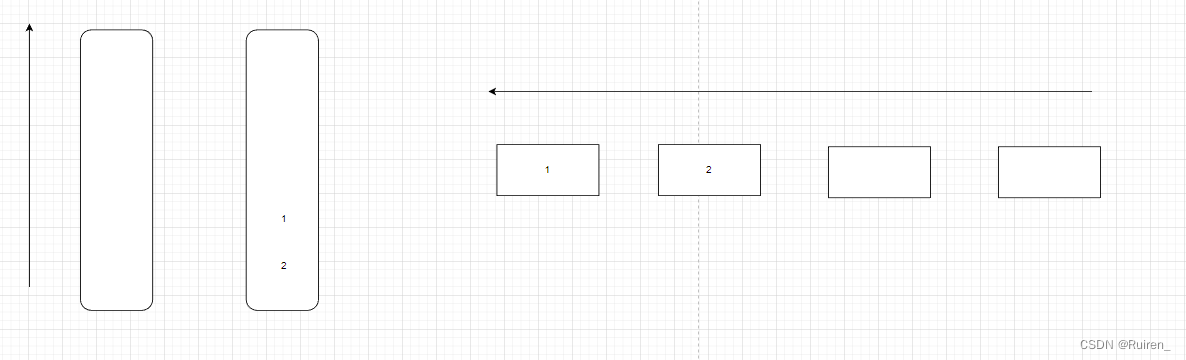
那么我们可以总结
1️⃣我们将一个栈只当作出数据的的,将一个栈只当入数据的(对于上图来说左边是入的,右边是出的)
2️⃣当出的栈为空时,我们就将入的栈的数据入到出的栈里面
3️⃣当出的栈不为空时,我们出数据就只向出栈出数据
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
void StackInit(ST* ps)
{
assert(ps);
ps->a = NULL;
ps->top = 0;//初始化时如果top是0,即top指向栈顶上的后一位
ps->capacity = 0;
}
void StackDestroy(ST* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->capacity = 0;
ps->top = 0;
}
void StackPush(ST* ps, STDataType x)
{
assert(ps);
if (ps->top == ps->capacity)
{
int newcapacity = ps->capacity == 0 ? 4: ps->capacity * 2;
STDataType* temp = (STDataType * )realloc(ps->a, sizeof(STDataType)*newcapacity);
if (temp == NULL)
{
printf("realloc fail\n");
exit(-1);
}
ps->a = temp;
ps->capacity = newcapacity;
}
ps->a[ps->top] = x;
ps->top++;
}
void StackPop(ST* ps)
{
assert(ps);
assert(ps->top > 0);
ps->top--;
}
STDataType StackTop(ST* ps)
{
assert(ps);
assert(ps->top > 0);
return ps->a[ps->top - 1];
}
bool StackEmpty(ST* ps)
{
return ps->top == 0;
}
void StackPrint(ST* ps)
{
while (ps->top)
{
printf("%d", StackTop(ps));
StackPop(ps);
}
}
typedef struct {
ST st1;//入的栈
ST st2;//出的栈
} MyQueue;
MyQueue* myQueueCreate() {
MyQueue* Queue=(MyQueue*)malloc(sizeof(MyQueue));
StackInit(&Queue->st1);
StackInit(&Queue->st2);
return Queue;
}
void myQueuePush(MyQueue* obj, int x) {
StackPush(&obj->st1,x);
}
int myQueuePeek(MyQueue* obj) {
if(StackEmpty(&obj->st2))
{
while(!StackEmpty(&obj->st1))
{
StackPush(&obj->st2,StackTop(&obj->st1));
StackPop(&obj->st1);
}
}
return StackTop(&obj->st2);
}
int myQueuePop(MyQueue* obj) {
int front=myQueuePeek(obj);
StackPop(&obj->st2);
return front;
}
bool myQueueEmpty(MyQueue* obj) {
return (StackEmpty(&obj->st1)&&StackEmpty(&obj->st2));
}
void myQueueFree(MyQueue* obj) {
StackDestroy(&obj->st2);
StackDestroy(&obj->st1);
free(obj);
}
/**
* Your MyQueue struct will be instantiated and called as such:
* MyQueue* obj = myQueueCreate();
* myQueuePush(obj, x);
* int param_2 = myQueuePop(obj);
* int param_3 = myQueuePeek(obj);
* bool param_4 = myQueueEmpty(obj);
* myQueueFree(obj);
*/
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我有一个将某些事件写入队列的Rails3应用。现在我想在服务器上创建一个服务,每x秒轮询一次队列,并按计划执行其他任务。除了创建ruby脚本并通过cron作业运行它之外,还有其他稳定的替代方案吗? 最佳答案 尽管启动基于Rails的持久任务是一种选择,但您可能希望查看更有序的系统,例如delayed_job或Starling管理您的工作量。我建议不要在cron中运行某些东西,因为启动整个Rails堆栈的开销可能很大。每隔几秒运行一次它是不切实际的,因为Rails上的启动时间通常为5-15秒,具体取决于您的硬件。不过,每天这样做几
在神经网络方面,我完全是个初学者。我整天都在与ruby-fann和ai4r搏斗,不幸的是我没有任何东西可以展示,所以我想我会来到StackOverflow并询问这里的知识渊博的人。我有一组样本——每天都有一个数据点,但它们不符合我能够找出的任何明确模式(我尝试了几次回归)。不过,我认为看看是否有任何方法可以仅从日期预测future的数据会很好,而且我认为神经网络将是生成希望表达这种关系的函数的好方法.日期是DateTime对象,数据点是十进制数,例如7.68。我一直在将DateTime对象转换为float,然后除以10,000,000,000得到一个介于0和1之间的数字,我一直在将
我正在尝试为现有队列编写消费者。RabbbitMQ在一个单独的实例中运行,名为“org-queue”的队列已经创建并绑定(bind)到一个交换器。org-queue是一个持久队列,它还有一些额外的属性。现在我需要从这个队列接收消息。我使用下面的代码来获取队列的实例conn=Bunny.newconn.startch=conn.create_channelq=ch.queue("org-queue")它抛出一个错误,指出不同的耐用属性。默认情况下,Bunny似乎使用durable=false。所以我添加了durabletrue作为参数。现在它说明了其他参数之间的区别。我是否需要指定所有参
我知道我们可以做到:sidekiq_optionsqueue:"Foo"但在这种情况下,Worker只分配给一个队列:“Foo”。我需要在特定队列中分配作业(而不是worker)。使用Resque很容易:Resque.enqueue_to(queue_name,my_job)另外,为了并发问题,我需要限制每个队列的Worker数量为1。我该怎么做? 最佳答案 您可能会使用https://github.com/brainopia/sidekiq-limit_fetch然后:Sidekiq::Client.push({'class'=>
我正在尝试训练一个前馈网络来使用Ruby库AI4R执行异或运算。然而,当我在训练后评估XOR时。我没有得到正确的输出。有没有人以前使用过这个库并得到它来学习异或运算。我使用了两个输入神经元,一个隐藏层中的三个神经元,一个输出层,正如我看到的预计算XOR前馈神经网络就像这样。require"rubygems"require"ai4r"#Createthenetworkwith:#2inputs#1hiddenlayerwith3neurons#1outputsnet=Ai4r::NeuralNetwork::Backpropagation.new([2,3,1])example=[[0,
题目描述小张买了 n 件白色的衣服,他觉得所有衣服都是一种颜色太单调,希望对这些衣服进行染色,每次染色时,他会将某种颜色的所有衣服寄去染色厂,第 i 件衣服的邮费为 ai 元,染色厂会按照小张的要求将其中一部分衣服染成同一种任意的颜色,之后将衣服寄给小张,请问小张要将 n 件衣服染成不同颜色的最小代价是多少?输入描述第一行为一个整数 n ,表示衣服的数量。第二行包括 n 个整数a1,a2...an 表示第 i 件衣服的邮费为 ai 元。(1≤n≤10^5,1≤ai≤10^9 )输出描述输出一个整数表示小张所要花费的最小代价。输入输出样例输入551321输出25 思考🤔:题意:意思是
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
1.深度优先搜索(DFS)深度优先遍历主要思路是从图中一个未访问的顶点V开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成。例题P1605迷宫题目描述给定一个N×MN\timesMN×M方格的迷宫,迷宫里有TTT处障碍,障碍处不可通过。在迷宫中移动有上下左右四种方式,每次只能移动一个方格。数据保证起点上没有障碍。给定起点坐标和终点坐标,每个方格最多经过一次,问有多少种从起点坐标到终点坐标的方案。输入格式第一行为三个正整数N,M,TN,M,TN,M,T,分别表示迷宫的长宽和障碍总数。第二行为四个正整数SX,S
我目前有一个Rails3.0项目,使用Ruby1.9.2和Resque。我的应用程序有多个工作类和多个队列,它们是动态创建的(在运行时)。此外,有多个worker已启动,可以自由地在任何队列上工作,因为在启动时没有任何现有队列,并且无法预测它们:$COUNT=3QUEUE=*rakeresque:workers根据project的id创建队列:@queue="project_#{project.id}".to_sym对于给定的队列,他们的作业必须按顺序处理,一次处理一个。我的问题是,通过拥有多个工作人员,可以并行处理多个作业。有没有办法设置每个队列的最大worker数(为1)?有没有办