- 💂 个人主页: 同学来啦
- 🤟 版权: 本文由【同学来啦】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有帮助,欢迎关注、点赞、收藏和订阅专栏哦
文章目录
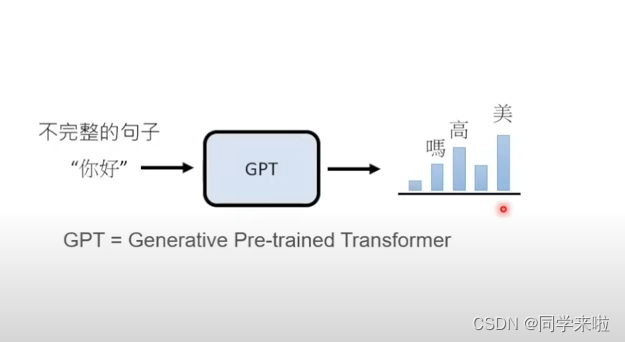
ChatGPT是美国OpenAI公司研发的大参数预训练生成语言模型,是一款通用的自然语言生成模型,其中GPT “生成性预先训练转换器”(generative pretrained transformer)的缩写。该模型被互联网巨大的语料库训练之后,其可以根据你输入的文字内容来生成对应的文字回答,即为常见的聊天问答模式。

语言模型的工作方式是对语言文本进行概率建模,用来预测下一段输出内容的概率,形式上有些类似于文字接龙游戏。比如输入的内容是“你好”,模型可能就会在可能的结果中选出概率最高的那一个,用来生成下一部分的内容。

ChatGPT之所以有如此强烈的反响,很大程度上是因为其在语言能力上的显著提升。ChatGPT相比于其他聊天机器人,主要表现在以下几个方面:

截止目前尚未发现ChatGPT的公开论文(如有请指出),但可以明确的是ChatGPT与Open AI此前发布的InstructGPT具有非常接近的姊妹关系,两个模型的训练过程也非常接近,因此InstructGPT有较为可靠的参考价值。

在OpenAI关于InstrcutGPT的论文中,可以找到一些直观优势的量化分析,InstrcutGPT对比GPT-3模型有如下特点:
为何ChatGPT可以做到如此出色的效果?让我们把视角稍微拉远一些,看看该款模型近几年的发展历史。
从演进关系来看,ChatGPT是OpenAI的另一款模型,InstrcutGPT的姊妹版本,其基于InstrcutGPT做了一些调整。具体的发展路线如下:

限于篇幅和实际情况,本文无法对每篇文章进行解析,重点提一下几个有意思的决定和突破。
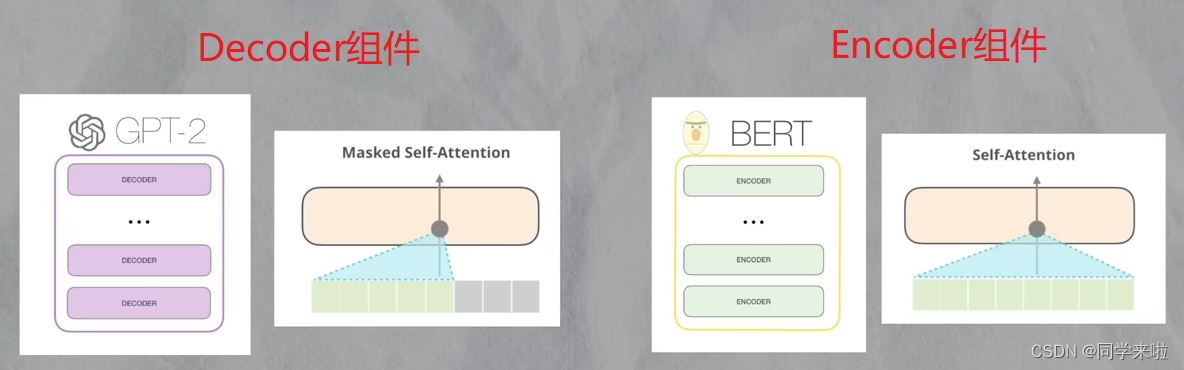
对于从Transformer结构上分支出来的BERT和GPT,有一点不同是来自于Transformer的结构区别。BERT使用的是Transformer的Encoder组件,Encoder组件在计算某个位置时会关注文章的上下文信息;而GPT使用的是Transformer的decoder组件,decoder组件在计算某个位置时只关注文章的上文信息。
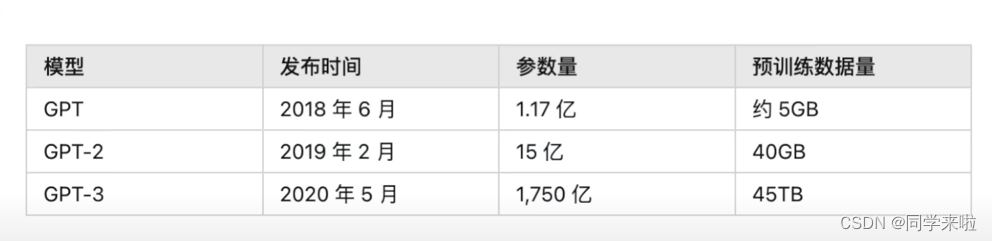
一个有趣的突破是来自于模型量级上提升。从GPT-1到GPT-3,模型参数量从1.17亿到15亿,再到1750亿。GPT-3相比于同类型的语言模型参数量增加了10倍以上。训练数据量也由从 GPT 的 5GB,增加到GPT-2的40GB,再到GPT-3的45TB。
在方向上,OpenAI并未追求在特定类型任务上的表现,而是不断增强模型的泛化能力。因而就对训练数据量和参数量提出来更高的要求。伴随着巨大参数量的是巨大的训练成本,GPT-3的训练费用也达到了惊人的1200万美元,
从GPT-3到 InstrcutGPT的一个有趣改进是引入了人类的反馈。引自OpenAI论文的说法,在InstrcutGPT之前,大部分大规模语言模型的目标都是基于上一个输入片段token来推测下一个输出片段,然而这个目标和用户的意图是不一致的,用户的意图是让语言模型能够有用并且安全地遵循用户的指令。此处的指令也就是InstrcutGPT名字的来源,也呼应了ChatGPT的最大优势,即对用户意图的理解。

为了达到该目的,引入了人类老师(即标记人员),通过标记人员的人工标记来训练出一个反馈模型,该反馈模型再去训练GPT-3。之所以没有让标记人员直接训练GPT-3,可能是由于数据量过大的原因。该反馈模型就像是被抽象出来的人类意志可以用来激励GPT-3的训练,整个训练方法即为基于人类反馈的强化学习。

OpenAI追求的特点:
上下文对话原理:
语言模型生成回答的方式是基于一个个token(单词),ChatGPT生成一句话的回答是从第一个词开始,重复把问题以及当前生成的所有内容再作为下一次的输入,生成下一个token,直到生成完整的回答。

既然一句话是基于前面所有上文的一个个词生成的,同样的原理也可以把之前的对话作为下一次问题的输入,这样下一次的回答就可以包含之前对话的上下文。由于GPT-3 API里面,单次交互最多支持4000多个token,猜测Chat GPT估计也是4000个token左右。
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分
3月26日,映宇宙(HK:03700,即“映客”)发布截至2022年12月31日的2022年度业绩财务报告。财报显示,映宇宙2022年的总营收为63.19亿元,较2021年同期的91.76亿元下降31.1%。2022年,映宇宙的经营亏损为4698.7万元,2021年同期则为净利润4.57亿元;期内亏损(净亏损)为1.68亿元,2021年同期的净利润为4.33亿元;非国际财务报告准则经调整净利润为3.88亿元,2021年同期为4.82亿元,同比下降19.6%。 映宇宙在财报中表示,收入减少主要是由于行业竞争加剧,该集团对旗下产品采取更为谨慎的运营策略以应对市场变化。不过,映宇宙的毛利率则有所提升
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
LL库和HAL库简介LL:Low-Layer,底层库HAL:HardwareAbstractionLayer,硬件抽象层库LL库和hal库对比,很精简,这实际上是一个精简的库。LL库的配置选择如下:在STM32CUBEMX中,点击菜单的“ProjectManager”–>“AdvancedSettings”,在下面的界面中选择“AdvancedSettings”,然后在每个模块后面选择使用的库总结:1、如果使用的MCU是小容量的,那么STM32CubeLL将是最佳选择;2、如果结合可移植性和优化,使用STM32CubeHAL并使用特定的优化实现替换一些调用,可保持最大的可移植性。另外HAL和L
一、机器人介绍 此处是基于MATLABRVC工具箱,对ABB-IRB-1200型号的微型机械臂进行正逆向运动学分析,并利Simulink工具实现对机械臂进行具有动力学参数的末端轨迹规划仿真,最后根据机械模型设计Simulink-Adams联合仿真。 图1.ABBIRB 1200尺寸参数示意图ABBIRB 1200提供的两种型号广泛适用于各作业,且两者间零部件通用,两种型号的工作范围分别为700 mm 和 900 mm,大有效负载分别为 7 kg 和5 kg。 IRB 1200 能够在狭小空间内能发挥其工作范围与性能优势,具有全新的设计、小型化的体积、高效的性能、易于集成、便捷的接