每年在各类顶级会议期刊如CVPR(IEEE Conference on Computer Vision and Pattern Recognition,Ieee国际计算机视觉与模式识别会议)、ICCV(IEEE International Conference on Computer Vision,国际计算机视觉大会)、ECCV(European Conference on Computer Vision,欧洲计算机视觉国际会议)、SIGGRAPH(Special Interest Group for Computer GRAPHICS,计算机图形图像特别兴趣小组)都会出现很多篇视频降噪的论文,范围涉及到各类传统算法与深度学习算法。学术界拥有如此多的视频降噪算法,但拍照或者视频还是会出现很多噪点,这就是学术届优秀降噪成果难以有效在工业界落地的问题。
在视频应用广泛的互联网时代,清晰纯净的视频一定是各类应用场景的追求。在刷短视频或者观看直播,我们更愿意将目光长时间停留在图1.1,而图1.2是我们第一时间想划过去的视频画面。
降噪是图像/视频处理领域一直很基础很热门也很难的问题,也出现在不少产品应用中,但却很少在视频直播产品中见到降噪技术的应用。比如腾讯会议一款软件应用了视频降噪技术,带来的实际视频效果体验以及隐形的带宽流量节省都是显而易见。

图1.1

图1.2
● 噪声来源主要分为两种:
○ 图像获取中:图像传感器CCD 、CMOS采集图像时,受到传感器材料属性、工作环境、电子元器件、电路结构影响;
○ 图像信号传输中:传输介质和记录设备不完善;
● 噪声分类
○ 高斯噪声:概率密度函数服从高斯分布(正态分布);
○ 泊松噪声:光子离散噪声,实际数字图像中的噪声基本是高斯噪声和泊松噪声的混合噪声;
○ 椒盐噪声、加性噪声、乘性噪声、量化噪声等;
● 噪声场景
○ 夜晚场景:夜晚除了画面不清楚外,大量噪声也是引起视频体验的主要因素;
○ 平坦区域:摄像头的物理硬件的随机波动,在平坦区域会产生被视觉更容易察觉的噪声;
○ 高分辨率:分辨率越高,噪声波动对人眼视觉越明显;
○ 背光区域:由于前后景亮度差异过大,背光区域曝光不足,会让噪声看起来更明显;
● 滤波法
○ 空域法:mean filters、gaussian filters、medium filters、bilateral filters、NLM、NLB等;
○ 变换域法:维纳、离散傅立叶、离散小波、DCT等;
○ 混合时空变换法 :BM3D、meshflow、hqdn3d、卡尔曼等;
● 稀疏表达:k-SVD
● 聚类低秩:WNNM(weighted nuclear norm minization,加权核范数最小化)
● 统计模型:高斯混合模型
● 深度学习:FFDNet、CBDNet等;
● 视觉效果:大幅提升视频主观体验,增加视频观看舒适度。
● 编码压缩与带宽传输:提升视频编码RD性能、运动估计更准确更高效、熵编码速度更快、降低码率、降低编码复杂度。
典型的空域线性滤波算法,原理简单,即在图像上对目标像素给一个模板,该模板包括了其周围的临近像素(以目标像素为中心的周围8个像素,构成一个滤波模板,即包括目标像素本身),再用模板中的全体像素的平均值来代替原来像素值。
典型的空域非线性滤波算法,原理简单,每一个目标像素值设置为该点某邻域窗口内的所有像素值的中值。
典型的空域线性平滑滤波算法,原理简单,每一个像素值,都由其本身和邻域内的其他像素值经过加权平均后得到。
典型的空域非线性滤波算法,原理简单,即可以认为是高斯滤波的改进迭代版,同时考虑图像的空间近邻度和像素值相似度的一种折中算法。
“Non-Local Bayes” (NL-Bayes)非局部贝叶斯,利用图像的自相似结构进行去噪。
○ 原理
■ one-step
● 找到与给定图像块相似的图像块,并组成3D块
● 协方差滤波
○ 贝叶斯公式应用到3D块;
○ 重新定位3D块;
● 聚合
○ 聚合就是为了消除3D滤波产生的滤波块重叠,被获取的许多估计数需要为每个像素组合;
● Acceleration 加速
■ two-step
● grouping 组块
● Collaborative Filtering 协方差滤波
● Aggregation 聚合
○ 迭代版本
■ Non-local Bayesian Video Denoising 非局部贝叶斯视频去噪
■ https://github.com/pariasm/vnlb
代码:https://github.com/gfacciol/bm3d
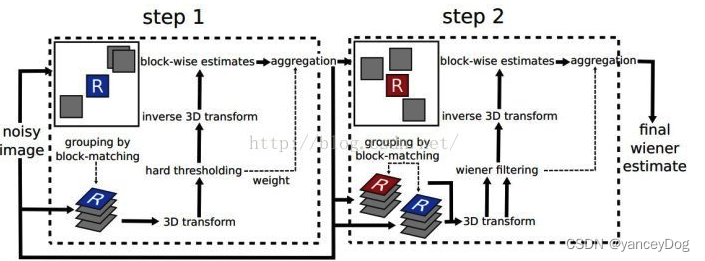
典型的且效果较好的空域与变换域结合的去噪算法,原理相对较复杂,算法复杂度也相对较高,当然实际去噪效果也相对传统的去噪算法有明显的提升。
中心思想:充分利用自然图像中丰富的自相似结构来进行图像降噪;
step1:基础估计
■ 相似块分组Grouping
■ 协同滤波Collaborative Filtering
■ 聚合 Aggregation
step2:最终估计
■ 块匹配Grouping
■ 3D协同维纳滤波 Collaborative Filtering
■ 聚合加权滤波Aggregation
meshflow来源于2017年中国电子科技大学一篇sci级别论文。steadyflow需要计算密集的光流(optical flow)并提取所有像素位置的像素配置来进行处理;与steadyflow相比,meshflow仅在稀疏规则的顶点配置网格上进行操作。
通过对论文中meshflow算法剖析,在相邻帧之间进行估计,这些帧用于在一个滑动时间窗口内对齐帧,整个方案可以分成特征跟踪、网格流估计、运动累积、一致性检查、像素融合;该算法具有模型轻量级、非参数化、空间变形体等内在特征,能够有效地实现多帧图像的去噪,具体算法思路如图2.1所示:
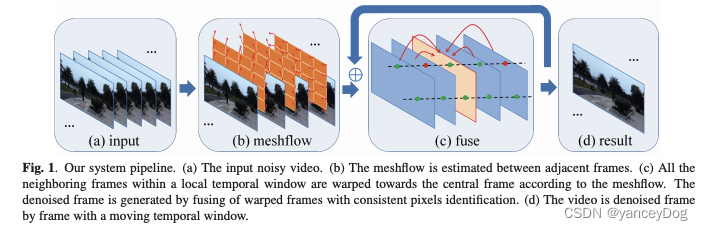
图2.1
论文介绍实验结果,1920x1080的分辨率单帧平均需要260 ms,具体来说,特征跟踪27ms、网格流估计21ms、运动累积38 ms、一致性检查25 ms、像素融合149ms。从论文实验结果对比分析,视频降噪效果大多数场景效果非常明显,但算法复杂度仍然相对较高,距离实时视频应用场景落地还有一段路程。
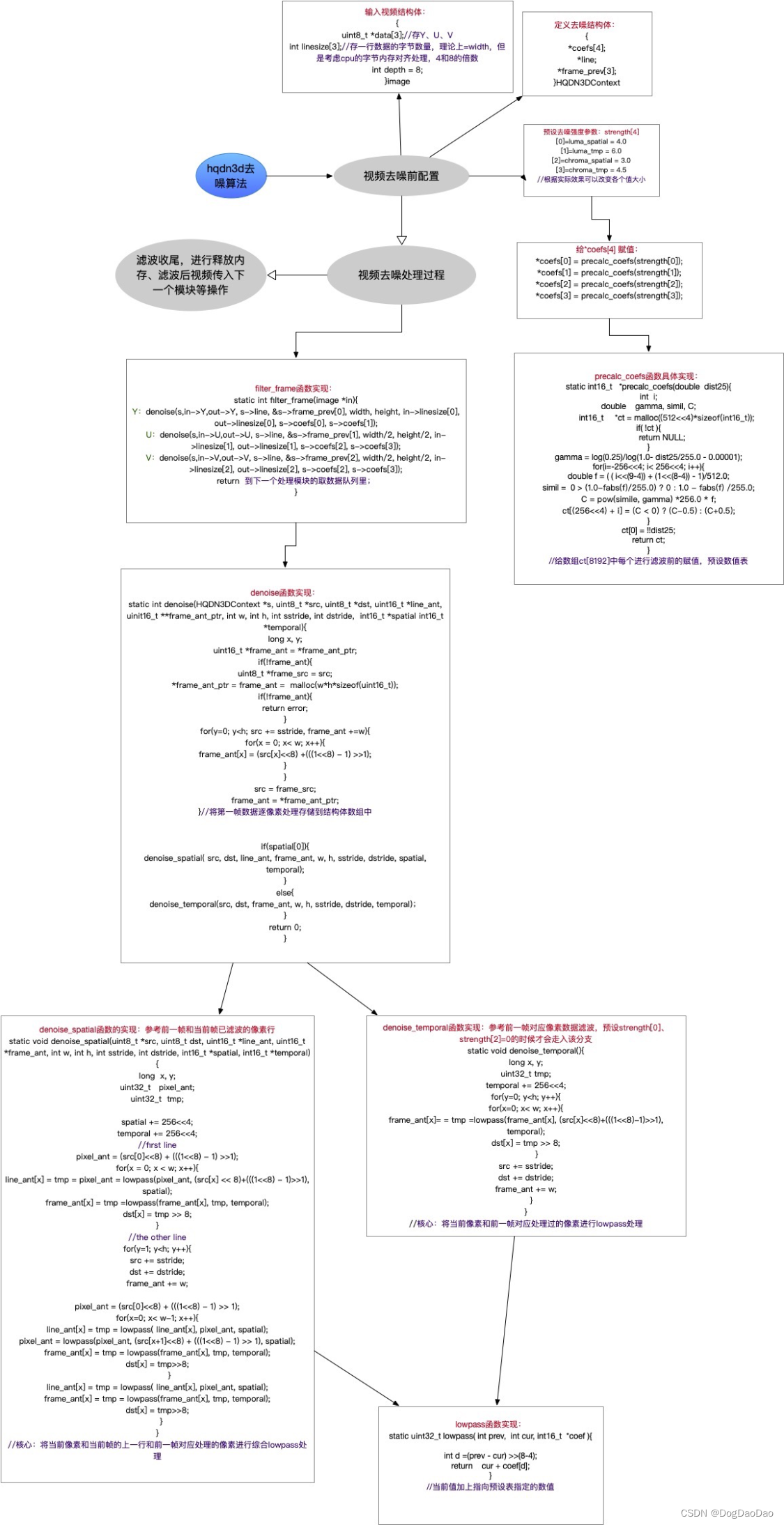
作为Avisynth一款视频处理插件,集成应用到Mplayer播放器中。hqdn3d是时域、空域混合滤波算法,不涉及变换域 ,算法原理容易理解,总结其原理,包含几点:
● 逐像素进行,不涉及频域变换,不涉及运动搜索,不涉及帧间对齐;
● 3D去噪,当前像素参考左邻、上邻、上帧同一位置的三个像素;
● 根据相邻像素的差,确定偏移量,将相邻像素颜色值“拉近”,即对像素做加减法;
● 较小的像素差异,拉近距离,若差异较大,降低偏置系数,达到保边效果;
● 通过外部设置滤波强度,调整峰值位置;

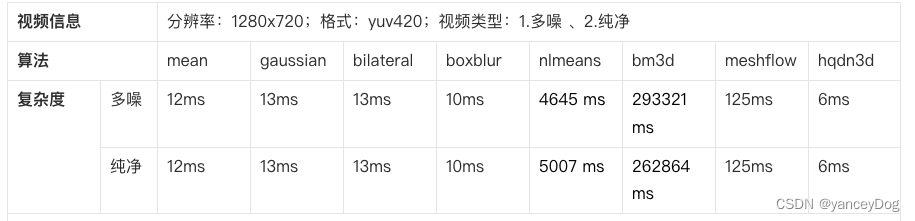
在线实验各类新算法网址:https://www.ipol.im/
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
目前我正在使用这个正则表达式从YoutubeURL中提取视频ID:url.match(/v=([^&]*)/)[1]我怎样才能改变它,以便它也可以从这个没有v参数的YoutubeURL获取视频ID:http://www.youtube.com/user/SHAYTARDS#p/u/9/Xc81AajGUMU感谢阅读。编辑:我正在使用ruby1.8.7 最佳答案 对于Ruby1.8.7,这就可以了。url_1='http://www.youtube.com/watch?v=8WVTOUh53QY&feature=feedf'url
一、什么是web项目ui自动化测试?通过测试工具模拟人为操控浏览器,使软件按照测试人员的预定计划自动执行测试的一种方式,可以完成许多手工测试无法完成或者不易实现的繁琐工作。正确使用自动化测试,可以更全面的对软件进行测试,从而提高软件质量进而缩短迭代周期。二、构建测试用例的“九部曲”(一)创建流程包划分功能模块日常测试活动中,都会根据功能模块进行拆分,所以在设计器中我们可以通过创建流程包的方式来拆分需要测试的功能模块,如下图中操作创建一个电脑流程包并且取名为对应的功能模块名称,如果有多个功能模块就创建多个对应的流程包,实在RPA设计器有易用的图形可视化界面,方便管理较多的功能模块。(二)在流程包
目录需求基于JavaCV跨平台执行ffmpeg命令[^1]坑一内存不足坑二多个ffmpeg进程并行导致IO负载大,进而导致ioerror?坑三使用Java操作ffmpeg时,有时会卡死坑四Process的waitFor死锁问题及解决办法需求给透明背景的视频自动叠加一张背景图片基于JavaCV跨平台执行ffmpeg命令1我测试发现的本需求的最小依赖:dependency>groupId>org.bytedecogroupId>artifactId>ffmpeg-platform-gplartifactId>version>5.0-1.5.7version>dependency>核心代码:Stri
摘要本论文主要论述了如何使用Python技术开发一个短视频智能推荐,本系统将严格按照软件开发流程进行各个阶段的工作,采用B/S架构,面向对象编程思想进行项目开发。在引言中,作者将论述短视频智能推荐的当前背景以及系统开发的目的,后续章节将严格按照软件开发流程,对系统进行各个阶段分析设计。 短视频智能推荐的主要使用者分为管理员和用户,实现功能包括管理员:首页、个人中心、用户管理、热门视频管理、用户上传管理、系统管理,用户:首页、个人中心、用户上传管理、我的收藏管理,前台首页;首页、热门视频、用户上传、公告信息、个人中心、后台管理等功能。由于本网站的功能模块设计比较全面,所以使得整个短视频智能推荐信
基于ffmpeg的视频处理与MPEG的压缩试验ffmpeg介绍与基础知识对提取到的图像进行处理RGB并转化为YUV对YUV进行DCT变换对每个8*8的图像块进行进行量化操作ffmpeg介绍与基础知识ffmpeg是视频和图像处理的工具包,它的下载网址是https://ffmpeg.org/download.html。页面都是英文且下载正确的包的路径笔者找的时候还费点劲,这里记录一下也方便读者。选中这个Windows下的下午files,选择第一个这里有essential和full版本的,大家根据需要自行选择版本包下载下载好之后,在官网上下载ffmpeg的full包,一共300+MB解压,然后安装b
近年来,随着信息化时代的到来,三维全景拼接以视频监控领域为代表的智能硬件公司迅速崛起,随后全国各地在视频监控领域进行了大量的建设。但随着摄像头数量的增加,视频监控画面离散、庞杂、关联性差等诸多问题日渐凸显。如何优化现有视频技术,助力管理者或使用者有效、直观、准确地掌控现场实时动态,成为我国信息化前行路上面临的新课题。视频融合技术平台解决方案北京智汇云舟科技有限公司成立于2012年,专注于创新性的“视频孪生(实时实景数字孪生)”技术研发与应用。公司依托自研三维地理信息引擎(3DGIS),融合建筑信息模型(BIM)、视频监控(Video)、人工智能(AI)及物联网(IOT)等多种技术,并在此基础上
动手点关注干货不迷路1. 背景随着RTC使用场景的不断复杂化,新特性不断增多,同时用户对清晰度提升的诉求也越来越强烈,这些都对客户端机器性能提出了越来越高的要求(越来越高的分辨率,越来越复杂的编码器等)。但机器性能差异千差万别,同时用户的操作也不可预知,高级特性的使用和机器性能的矛盾客观存在。当用户机器负载过高时,我们需要适当降级视频特性来减轻系统复杂性,确保重要功能正常使用,提升用户体验。视频性能降级能做什么?一是解决因设备性能不足、突发的性能消耗冲击(如杀毒软件)带来的用户音视频体验问题(如视频卡顿、延时高、设备卡死)等问题;二是提升一些高级功能的渗透率,例如默认情况下开启视频超分,设备性