C/C++常用函数
大部分为C++ STL函数,并且大多需要添加头文件#include<cmath>(C语言的头文件)或者#include<algorithm>
常用函数一览:
swap(nums[i], nums[ptr]); //交换函数
max(merged.back()[1], R); //大小比较选取
max_element(myvector.begin(),myvector.end());//返回向量中最大元素的迭代器,注意返回的是迭代器,头文件是algorithm
reverse(ans.begin(), ans.end());//答案反转
rand函数,C语言中用来产生一个随机数的函数。
int a = round(11.5); //四舍五入,得到a=12
sqrt(5); //根号5
pow(a,2); //a的平方
num = abs(num);//取绝对值,abs是针对于int类型的
//distance() 函数用于计算两个迭代器表示的范围内包含元素的个数
rand(); //返回一个从0到最大随机数的任意整数
int result = accumulate(nums.begin(), nums.end(), 0);//序列求和
头文件 #include<algorithm>
vector<int> v{ 4, 7, 9, 1, 2, 5 };
int key = 2;
if (count(v.begin(), v.end(), key)){
cout << "Element found" << endl;
}
if (std::find(v.begin(), v.end(), key) != v.end())
条件判断语句:
if (std::find_if(v.begin(), v.end(), [] (int i) { return i < 3 && i > 1 } ) != v.end())
条件判断语句:
if (std::any_of(v.begin(), v.end(), [] (int i) { return i < 3 && i > 1 } ))
扩展:std::none_of,是any_of的反面。也就是,当判断式是false时它返回true,否则返回flase。
小结
方法虽多,侧重各不相同。选择适合的算法有助于提高代码可读性和执行效率,简单总结如下:
对于已经排序的vector,使用binary_search
仅判断是否存在某元素,使用find
需要某元素总个数时,使用count
支持复杂条件的查找时,使用any_of(仅知道是否存在)或者find_if(返回了第一个元素的迭代器)
头文件:#include <algorithm>
常用用法: for_each(v.begin(), v.end(), 全局函数名);
for_each() 函数,允许对区间内的元素进行修改,当然transform也可以实现相同的操作,只是transform效率较低,因为transform是通过拷贝函数返回值实现。 当然 C++ 11之后 for_each 变得不再重要,因为range-based for更加直观简单。这里仅作为了解。
for_each()事实上是個function template,其实质如下[effective STL item 41],for_each()只能配合global function和function object。
template<typename InputIterator, typename Function>
Function for_each(InputIterator beg, InputIterator end, Function f) {
while(beg != end)
f(*beg++);
}
经常和 vector 容器搭配使用,在vector容器中 for_each 遍历算法如下:
void MyPrint(int val){
cout << val << endl;
}
for_each(v.begin(), v.end(), MyPrint);
相对于使用for循环来遍历容器来说,使用for_each算法更实用一些,而且代码简短,可读性更强,但不如range-based for更加直观简单。
功能是逆序(或反转),多用于字符串、数组、容器。头文件是#include <algorithm>
reverse函数用于反转在[first,last)范围内的顺序(包括first指向的元素,不包括last指向的元素),reverse函数无返回值。
举例:
string str="hello world , hi";
reverse(str.begin(),str.end());//str结果为 ih , dlrow olleh
vector<int> v = {5,4,3,2,1};
reverse(v.begin(),v.end());//容器v的值变为1,2,3,4,5
① max_element() 找有前向迭代器序列区间中的最大值,如数组、列表等。
头文件:#include<algorithm>
返回【前闭后开)序列区间中指向最大值的迭代器,输出值的话要在max_element前面加星号,第三个参数cmp可写可不写。
max_element() 和 min_element() 默认是从小到大排列,然后
max_element() 输出最后一个值, min_element() 输出第一个值。如果自定义的 cmp函数写的是从大到小排列,那么会导致 max_element() 和min_element() 的两个结果是对调的。
可以用于 vector< int > 或者 vector< string > 等,也可以用于 int arr[4] 或者string arr[4] ,也可以用于结构体vector或者结构体数组。
用法举例:
int a[5] = {0, 3, 9, 4, 5};
int *b;
b = max_element(a, a+5);
cout << *b;
//也适用于向量
vector<int> myvector;
vector<int>::iterator it;
it = max_element(myvector.begin(),myvector.end());
cout<<*max_element(myvector.begin(),myvector.end());
//或者自己写一个比较函数,作为第三个参数
static bool cmp(int& a, int& b)
{
return abs(a)<abs(b);
}
it = max_element(myvector.begin(),myvector.end(),cmp);
cout<<*it<<end;
②max({a, b, c}) 利用 initializer_list 来找多个元素中的最大值
在C++11中有了initializer_list(初始化列表)后,max函数可以传递更多的参数,如下:
cout << max({ 54,16,48,5 }) << endl; //输出54
【注意】max 函数中的参数类型需要一致,不一致时需要进行类型转换,如下,size()函数返回值为 unsigned int 类型,不是int类型,类型不一致时会报错!
int maxlen = 0;
maxlen = max(maxlen, (int)word.size());
//word.size()不是int,max 函数需要参数类型统一
【补充-初始化列表】
c++11中统一了初始化列表(Uniform Initiaization),即均可以使用{}来对对象进行初始化。例如:
int value[]{1,2,3};
vector<int> v{2,3,4,5,6,7};
vector<string> cities{"Beijing","Dezhou"};
int i; //i has undefined value
int j{}; //j is initialized by 0
int *p; //p has undfined value
int *q{}; //q is initialized by nullptr
我们使用{}可以给上面进行赋值,那如果是结构体呢?
struct Peo
{
std::string name;
int pos;
};
Peo p[2]{ {"abo",1},{"abo2",2} };
综上,上面的初始化列表背后就是使用initializer_list来进行实现的,initializer_list背后是由array实现的。
array中的元素可被编译器分解逐一传给参数:
for(auto x:{1,2,3,4,5})
cout << x << endl;
作用:
把一个序列(sequence)拷贝到一个容器(container)中去,复制任何具有迭代器对象的元素。
函数原型:
std::copy(start, end, container);
start,end是需要复制的源文件的头地址和尾地址,container是接收器的起始地址,该容器的接口包含函数push_back。
copy只负责复制,不负责申请空间,所以复制前必须要有足够的空间。
用法样例:
① 覆盖复制
在一个已有的元素上直接copy覆盖,往往比较高效。但注意需要足够的空间。
int arr[] = {1,2,3,4,5,6,7,8,9,10};
int newArr[12] = {0};
copy(arr,arr+10,newArr);
② 在已有元素之后复制
只需要改变copy函数第三个参数为需要开始插入的元素地址(接收数组的起始地址加上原有数据的长度)
int arr[] = {1,2,3,4,5,6,7,8,9,10};
int newArr[12] = {11,12,0};
copy(arr,arr+10,newArr+2); //从11,12,0之后复制
③ 使用标准库提供的模板函数
包括inserter或者front_inserter或者back_inserter模板函数。
inserter,注意需要两个参数。此函数接受第二个参数,这个参数必须是一个指向给定容器的迭代器。元素将被正序插入到给定迭代器所表示的元素之前,并且为覆盖复制。
front_inserter和back_inserter分别为头插法和尾插法,只有一个参数(接收容器)。头插法会导致被复制元素倒序插入接收容器头部,尾插法会让被复制元素正序插入接收容器尾部
list<int> lst = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
list<int> lst2 ={10}, lst3={10},lst4={10};
//lst被正序复制插入到迭代器lst2.begin()之前
//list类型里面迭代器不能加减,也不能使用下标运算符[]
//lst2包含1,2,3,4,5,6,7,8,9,10
copy(lst.cbegin(), lst.cend(), inserter(lst2, lst2.begin())); //在lst2首部插入复制元素
//insert函数通常可以与copy函数(结合inserter)实现相同的效果,等价于下面这句
lst2.insert(lst2.begin(), lst.begin(), lst.end()); //在lst2首部插入元素
//lst3是头插法,lst每个元素都插在lst3的前面,注意插完变成倒序了
//lst3包含9,8,7,6,5,4,3,2,1,10
copy(lst.cbegin(), lst.cend(), front_inserter(lst3));
//lst4使用尾插法,lst中每个元素都插在了lst4末尾,而且保持了正序。
//lst4包含10,1,2,3,4,5,6,7,8,9
copy(lst.cbegin(), lst.cend(), back_inserter(lst4));
【注】
C语言的abs函数:
#include <stdio.h>
#include <stdlib.h> //用这个头文件
//abs是针对于int类型取绝对值
num = abs(num);
//针对long类型使用labs()
long b=-2;
b = labs(b);
//针对float,double 类型
float d = -4.12;
//float总有效位数一般为7位,例如12.34总有效位位数为5
d = fabs(d);
C++的abs则可以自然支持对整数和浮点数两个版本,在cmath头文件中定义,#include <cmath>
【注】math.h是C语言的头文件。在C++中用math.h也是可以的,C++是兼容C的。不过推荐的是使用#include <cmath>,不过这样必须声明在std命名空间:using namespace std; 其中的函数和使用方法几乎完全相同。
math类中提供了三个与取整有关的方法:ceil,floor,round,这些方法的作用于它们的英文名称的含义相对应
1、ceil的英文意义是天花板,该方法表示向上取整
int a = ceil(11.3); //a = 12
int b = ceil(-11.6); //b = -11
auto c = double(11)/2; //c = 5.5
auto d = ceil(double(11)/2); // d = 6
2、floor的英文是地板,该方法就表示向下取整
int a = floor(11.6); //a = 11
int b = floor(-11.6); //b = -12
auto c = double(11)/2; //c = 5.5
auto d = floor(double(11)/2); // d = 5
3、round方法表示“四舍五入”,算法为floor(x+0.5),即将原来的数字加上0.5后再向下取整,等价于(int)(m +0.5)。
int a = round(11.5); //a = 12
int b = round(-11.5); //b = -12
auto c = double(11)/2; //c = 5.5
auto d = round(double(11)/2); // d = 6
头文件#include<iterator>
advance(it, n) it 表示某个迭代器,n 为整数。该函数的功能是将 it 迭代器前进或后退 n 个位置。
如果 it 为输入迭代器或者前向迭代器,则 n 必须为一个正数,即表示将 it 右移(前进) n 个位置;反之,如果 it 为双向迭代器或者随机访问迭代器,则 n 为正数时表示将 it 右移(前进) n 个位置,n 为负数时表示将 it 左移(后退) n 个位置。
以 forward_list 容器(仅支持使用前向迭代器)为例, it 为前向迭代器,其只能进行 ++ 操作,即只能前进(右移):
#include <iostream> // std::cout
#include <iterator> // std::advance
#include <forward_list>
using namespace std;
int main() {
//创建一个 forward_list 容器
forward_list<int> mylist{1,2,3,4};
//it为前向迭代器,其指向 mylist 容器中第一个元素
forward_list<int>::iterator it = mylist.begin();
//借助 advance() 函数将 it 迭代器前进 2 个位置
advance(it, 2);
cout << "*it = " << *it; //*it = 3
return 0;
}
注意:
1)对于vector向量容器,it为随机访问迭代器,advance() 函数底层采用 it+n 操作实现的,因此n可正可负,可以前后移动迭代器。
2)当 it 为其他类型迭代器时,它们仅支持进行 ++ 或者 – 运算,这种情况下,advance() 函数底层是通过重复执行 n 个 ++ 或者 – 操作实现的。
3)advance() 函数本身不会检测 it 迭代器移动 n 个位置的可行性,如果 it 迭代器的移动位置超出了合理范围,it 迭代器的指向将无法保证,此时使用 *it 将会导致程序崩溃。
pre具有前一个的意思,该函数可用来获取一个距离指定迭代器 n 个元素的迭代器。
用法:
new_iterator = prev(iterator,n)
表示迭代器左移 n 个单位,即迭代器 - n。
若移动n个单位的步长后,超出迭代器范围[begin,end),则此行为未定义。
函数的返回值为一个迭代器,也就是传入迭代器左移n个单位后,返回这个移动后的新迭代器。
当“n“为正数时,返回传入迭代器“iterator”左边,距离”iterator“ n个单位的迭代器”new_iterator“。
当“n“为负数时,返回传入迭代器“iterator”右边,距离”iterator“ n个单位的迭代器"new_iterator"。
特别地,当不写n时,表示默认向“iterator”左边移动1个单位。
new_iterator = prev(iterator)
注:如果是随机访问迭代器,就只执行一次运算符操作 +=n( -=n ),否则,执行n次持续的递减或递增操作 ++(–)。
样例:
vector<int> vec{ 1,2,3,4,5,6,7 };
vector<int>::iterator end = vec.end();
for (int i = 1; i <= vec.size(); ++i)
{
auto it = prev(end, i);
cout << "end左移" << i << "个单位后的元素值为:" << *it << endl;
}
输出结果:
end左移1个单位后的元素值为:7
end左移2个单位后的元素值为:6
end左移3个单位后的元素值为:5
end左移4个单位后的元素值为:4
end左移5个单位后的元素值为:3
end左移6个单位后的元素值为:2
end左移7个单位后的元素值为:1
distance() 函数定义在#include<iterator>头文件,并位于 std 命名空间中,用于计算两个迭代器表示的范围内包含元素的个数。该函数会返回[first, last)范围内包含的元素的个数(距离)。
int num = distance (InputIterator first, InputIterator last);
//创建一个空 list 容器
list<int> mylist;
//向空 list 容器中添加元素 0~9
for (int i = 0; i < 10; i++) {
mylist.push_back(i);}
//获取 [first,last) 范围内包含元素的个数
cout << "distance() = " << distance(mylist.begin(), mylist.end());
//distance() = 10
C++中常量INT_MAX和INT_MIN分别表示最大、最小整数。
头文件#include<climits>
比如想给某个变量赋一个最大的初始值,可以如下:
int indexSum = INT_MAX;
因为int占4字节32位,根据二进制编码的规则,INT_MAX =
2
31
−
1
\ 2^{31}-1\,
231−1(2147483647)
,INT_MIN=
−
2
31
\ -2^{31}\,
−231(-2147483648)
#define INT_MAX 2147483647
#define INT_MIN (-INT_MAX - 1)
C++整型上下限INT_MAX INT_MIN及其运算
【拓展总结】
| 常量 | 含义 | 值 |
|---|---|---|
| CHAR_MIN | char 类型最小值 | -128 |
| CHAR_MAX | char类型最大值 | 127 |
| UCHAR_MAX | unsigned char 类型最大值 | 255(0xff) |
| SHRT_MIN | short 类型最小值 | -32768 |
| SHRT_MAX | short 类型最大值 | 32767 |
| USHRT_MAX | unsigned short 类型最大值 | 65535(0xffff) |
| INT_MIN | int 类型最小值 | -2147483647-1 |
| INT_MAX | int 类型最大值 | 2147483647 |
| UINT_MAX | unsigned int 类型最大值 | 4294967295(0xffffffff) |
| LONG_MIN | long 类型最小值 | -2147483647-1 |
| LONG_MAX | long 类型最大值 | 2147483647 |
| ULONG_MAX | unsigned long 类型最大值 | 4294967295(0xffffffff) |
| LLONG_MIN | long long 类型最小值 | -9223372036854775807-1 |
| LLONG_MAX | long long 类型最大值 | 9223372036854775807 |
| ULLONG_MAX | unsigned long long 类型最大值 | 18446744073709551615(0xffffffffffffffff) |
全排列除了以递归的方式实现以外,还可以利用c++标准函数库中的next_permutation()和prev_permutation()函数来实现。它们的头文件为#include<algorithm>。
该函数有两个形参,一个为数列的首元素地址,一个为数列的尾元素地址。返回值为bool类型,当全排列进行到到最后一种情况时返回false,否则返回true。
注:使用 next_permutation(首地址,尾地址) 进行全排列的数列必须是以最小字典排列(即由小到大排列)开始的。
prev_permutation()函数则要求原数列必须由大到小进行排列。
因此这两个库函数一般与sort()函数结合使用
样例如下:
//46. 全排列
vector<vector<int>> permute(vector<int>& nums) {
vector<vector<int> > ans;
sort(nums.begin(),nums.end());//从小到大排列
ans.emplace_back(nums);
while(next_permutation(nums.begin(),nums.end()))
{
ans.emplace_back(nums);
}
return ans;
}
如果对从大到小排列的数组 int a[] = {3,2,1}; 进行全排列,则需要使用while (prev_permutation(a, a+3))。
需要注意的是,全排列从当前数组的下一个排列开始,当前数组需要提前输出并保存。
用回溯递归方式实现全排列,输入为nums数组,输出其全排列:
//46. 全排列
void backTrace(vector<vector<int> >& ans, vector<int>& nums, int index, int n)
{
// 所有数都填完了
if(index==n)
{
ans.emplace_back(nums);
return ;
}
for(int i=index;i<n;++i)
{
// 动态维护数组,填入当前index位置及后面位置的任一个数,并进行交换,
//这样可以每次只选择未使用的右侧的数字
swap(nums[index],nums[i]);
// 继续递归填下一个数
backTrace(ans,nums,index+1,n);
// 撤销操作,换回当前数字,准备换下一个数字
swap(nums[index],nums[i]);
}
}
vector<vector<int>> permute(vector<int>& nums) {
vector<vector<int> > ans;
int n = nums.size();
backTrace(ans, nums, 0, n);
return ans;
}
重排序给定范围 [first, last) 中的元素,打乱顺序,使得这些元素的每个排列拥有相等的出现概率。
头文件:#include <algorithm>
函数原型:
template< class RandomIt, class URBG >
void shuffle( RandomIt first, RandomIt last, URBG&& g );
参数:
first, last - 要随机打乱的元素范围
g - 均匀随机位生成器 (UniformRandomBitGenerator)
RandomIt 必须满足值可交换 (ValueSwappable) 和 遗留随机访问迭代器 (LegacyRandomAccessIterator) 的要求。
同样的,内置类型数组也支持这种用法,比如下面的int型数组与char型数组。
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
char crr[] = "ABCDEFGH";
通常使用样例:
注意random_device{ }( ) 需要加头文件#include <random>
shuffle(myvector.begin(), myvector.end(), mt19937(random_device{}()));
vector使用样例:
#include <random>
#include <algorithm>
#include <iterator>
#include <iostream>
int main()
{
std::vector<int> v = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
//两种写法:
std::random_device rd; //随机数发生器
std::mt19937 g(rd()); // 随机数引擎:基于梅森缠绕器算法的随机数生成器
std::shuffle(v.begin(), v.end(), g); // 打乱顺序,重新排序(随机序列)
//上面三句等价于下面一句
std::shuffle(myvector.begin(), myvector.end(), std::mt19937(std::random_device{}()));
for (int a : v) std::cout << a << " "; //输出:3 1 4 9 5 10 2 8 7 6
std::cout << "\n";
}
头文件#include<numeric>
将一段数字从头到尾累加起来,或者使用指定的运算符进行运算。
accumulate(first, last, 初值,操作);四个参数:累加的元素起始地址;累加的元素结束地址,累加的初值(通常为0);第四个参数为进行的操作,默认为累加。
常用的求和样例:
#include<iostream>
#include<vector>
#include<numeric>
using namespace std;
int main() {
vector<int> nums = {1, 2, 3, 4, 5};
int result = accumulate(nums.begin(), nums.end(), 0);
cout << result << endl; //result = 15
return 0;
}
求和时,accumulate带有三个形参:累加的元素起始地址;累加的元素结束地址,累加的初值(通常为0)。
例如:
int list[10] = { 1,2,3,4,5,6,7,8,9,10 };
sum= accumulate(list, list+10, 0) ; //得出sum=55.
求连乘积时,accumulate带有四个形参:连乘的元素起始地址;连乘的元素结束地址,连乘的初值(通常为1), multiplies<int>() 运算
con_product= accumulate(list, list+3, 1, multiplies<int>()) ;//得出sum=6.
求string合并
vector<string>a{"1","-2345","+6"};
string a_sum=accumulate(a.begin(), a.end(),string("out: "));//得到out: 1-2345+6
头文件#include <numeric>
iota 函数 是一个计算机语言中的 函数 ,用于产生连续的值。 该 函数 得名自 APL 语言,其中用来产生从 T 开始的连续数值,增量为1,初始值T可以为小数。 定义在 numeric 头文件中的 iota () 函数 模板会用连续的 T 类型值填充序列。
iota函数作用:
对一个区间范围内的数据进行连续累加赋值。
template <class ForwardIterator, class T>
void iota (ForwardIterator first, ForwardIterator last, T val)
{
while (first!=last) {
*first = val;
++first;
++val;
}
}
例子:
int numbers[10];
std::iota (numbers, numbers + 10, 100);
//输出:100 101 …… 109
stoi()中放入(string)类型的参数,可以把string转换成int类型。
stoi函数会做范围检查,所以数字的类型不能超过int范围,不然会报错,而且在转换的过程中会发生int强制类型转换,所以当有小数点或题目输入字符串长度大于等于10位时,一定要注意!
一个可行的解决方法是使用stoll函数代替stoi,将string转化为long long int。
比如下面这种情况就会发生强制类型转换
int n=stoi("1.234");
cout<<n;
//此时会输出1。
用法:
stoi(字符串名) 或 stoi(字符串名,起始位置,n进制),将 n 进制的字符串转化为十进制
n进制的字符串指的是我们把字符串里存的内容当成几进制来看
示例:
string str = "1010";
int a = stoi(str, 0, 2); //将字符串 str 从 0 位置开始到末尾的 2 进制转换为十进制
int a = stoi(str); //简写
类似函数:
stol等:将string转化为其他类型
atoi等:不接受string作为输入参数,需将string转化为char*。同时,atoi不进行范围检查,超出类型上/下界时直接输出上/下界。
C++中的 to_string(value)系列函数将数值value转换成字符串形式。value不能为字符类型。
std::string pi = "pi is " + std::to_string(3.1415926);
//输出: pi is 3.1415926
- const char* 字符串 以 “\0”结尾。
- char[] 字符串 以 “\0”结尾。
- string 字符串 不以 “\0”结尾。
- char[n] = “string”, 当string 长度+“\0”>n时,会因空间不足出错。
- string.c_str() 转 const char* 时, 会在字符串末尾 自动补“\0”
- char* 转string 时, 会自动把末尾的 “\0” 去掉。
【附】C语言的atoi()函数:
atoi()函数——将char* 转换成int类型
功 能: 把字符串char* 类型转换成整型数int类型并返回结果,注意:不适用于string类,string类型需要先用c_str()函数进行转换再用atoi()函数。
用 法: int atoi(const char *nptr);
atoi()会扫描参数nptr字符串,跳过前面的空格字符,直到遇上数字或正负号才开始做转换,而再遇到非数字或字符串时(‘\0’)才结束转化,并将结果返回(返回转换后的整型数)。
举例:
#include <stdlib.h>
char *str = "12345.67";
int n = atoi(str);
int num = atoi(“1314.012”);//num值为1314
str.c_str()函数
C 库函数 int atoi(const char *str) 把参数 str 所指向的字符串转换为一个整数(类型为 int 型)。但不适用于string类串,可以使用string对象中的c_str()函数进行转换。
c_str()函数返回一个指向正规c字符串的指针,内容与string串相同。将string对象转换为C中的字符串样式。
std::string str="123";
int a =str-'0'; //错误,不可以直接用一个字符串减去‘0’
int n = atoi(*str); //错误
int n = atoi(str.c_str()); //正确,可以将string转为int
类似于尾插法, 在当前字符串尾部追加其他字符串
string str ;
string str2 =“123”;
用法:
//在str后面追加一个str2
str.append(str2); //输出123
//在后面追加上str2中从第二个元素开始的连续一个元素
str.strappend(str2,1,1); //1232
//在str后面追加上abc
str.append(“abc”); //1232abc
//在str后面追加上字符串123456中的前六个元素
str.append(“123456”, 6);
//在str后面追加5个m
str.append(5,‘m’);
//使用迭代器给str追加上str2的元素
str.append(str2.begin(),str2.end());
头文件#include<string>
replace的执行要遍历由区间[frist,last)限定的整个队列,以把old_value替换成new_value,因此复杂度为O(n)。
下面说下replace()函数常用的五种用法,另外有4种用法编译器可能会有警告,因此不推荐使用:
1)用str替换 指定字符串从 起始位置pos开始 长度为len 的字符
声明:
string& replace (size_t pos, size_t len, const string& str);
用例:
string str = "he is@ a@ good boy";
str = str.replace(str.find("a"), 2, "#"); //从第一个a位置开始的两个字符替换成#
cout << str << endl; //he is@ # good boy
2)用str替换 迭代器起始位置 和 结束位置 的字符
声明:
string& replace (const_iterator i1, const_iterator i2, const string& str);
用例:
string str = "he is@ a@ good boy";
str = str.replace(str.begin(), str.begin() + 5, "#"); //用#替换从begin位置开始的5个字符
cout << str << endl; //#@ a@ good boy
3)用substr的指定子串(给定起始位置和长度)替换从指定位置上的字符串
声明:
string& replace (size_t pos, size_t len, const string& str, size_t subpos, size_t sublen);
用例:
string str = "he is@ a@ good boy";
string substr = "12345";
str = str.replace(0,5, substr, substr.find("1"), 4); //用substr的指定字符串替换str指定字符串
cout << str << endl; //1234@ a@ good boy
4)用重复n次的c字符替换从指定位置pos长度为len的内容
声明:
string& replace (size_t pos, size_t len, size_t n, char c);
用例:
char ch = '#';
str = str.replace(0, 6, 3, ch); //用重复 3 次的 str1 字符替换的替换从位置 0~6 的字符串
cout << str << endl; //### a@ good boy
5)用重复n次的c字符替换从指定迭代器位置(从i1开始到结束)的内容
声明:
string& replace (const_iterator i1, const_iterator i2, size_t n, char c);
用例:
char ch = '#';
str = str.replace(str.begin(), str.begin() + 6, 3, ch); //用重复3次的str1字符替换的替换从指定迭代器位置的内容
cout << str << endl; //### a@ good boy
头文件 #include<cmath>
C ++中的acos()函数以弧度形式返回数字(参数)的反余弦值。
用法:
acos(data_type x)
参数:此函数接受一个强制性参数x,该参数指定应计算其反余弦值的值。它必须介于-1和+1之间,否则将抛出域错误(范围错误)。该参数可以是double,float或long double数据类型。
返回:该函数返回介于0和π之间。逆时针角度以弧度为单位,通常为double类型。
acos()函数采用[-1,1]范围内的单个强制性参数。这是因为余弦值在1到-1的范围内。
假设参数在[-1,1]范围内,则acos()函数返回[0,π]范围内的值。
如果参数大于1或小于-1,则acos()返回 NaN ,即不是数字。
| 参数x | 返回值 |
|---|---|
| x = [-1,1] | [0,π] 以弧度为单位 |
| x < -1 或 x > 1 | NaN(非数字) |
常用用法:
double acos(double x);
float acos(float x);
long double acos(long double x);
cout<<acos(-1.0);//3.14159
double result = acos(0.0); //result = 90.0027
同理是asin()函数,用于查找给定数字反正弦的主值,它接受数字( x )并以弧度返回x的反正弦的主值。
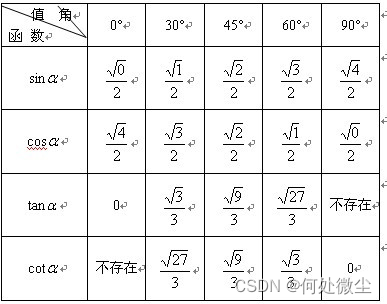
头文件:#include <stdlib.h>
作用:返回转换后的小写字母,若不须转换则将参数值返回
#include <cstdlib>
int main()
{
char s[] = "aBcDeFgH12345;!#$";
printf("before tolower() : %s\n", s);
//before tolower() : aBcDeFgH12345;!#$
for(int i = 0; i < sizeof(s); i++)
{
s[i] = tolower(s[i]);
}
printf("after tolower() : %s\n", s);
//after tolower() : abcdefgh12345;!#$
return 0;
}
把小写字母转换为大写字母。
toupper() 函数的声明:
int toupper(int c);
如果 c 有相对应的大写字母,则该函数返回 c 的大写字母,否则 c 保持不变。返回值是一个可被隐式转换为 char 类型的 int 值。
将某操作应用于指定范围的每个元素。
比较常用的重载函数版本是:transform(first,last,result,op);
其中,first是容器的首迭代器,last为容器的末迭代器,result为存放结果的容器,op为要进行操作的一元函数对象(比如::toupper或::tolower)或sturct、class。
比如利用transform函数将一个给定的字符串中的小写字母改写成大写字母,并将结果保存在一个叫second的数组里,原字符串内容不变。
#include <iostream>
#include <algorithm>
using namespace std;
char op(char ch)
{
if(ch>='A'&&ch<='Z')
return ch+32;
else
return ch;
}
int main()
{
string first,second;
cin>>first;
second.resize(first.size());
transform(first.begin(),first.end(),second.begin(),op);
cout<<second<<endl;
return 0;
}
当然可以用已有函数对象(比如::toupper或::tolower)进行简写,并将结果保存至str字符串自身中。
string str; cin>>str;
transform(str.begin(), str.end(), str.begin(), ::toupper);//转为大写
transform(str.begin(), str.end(), str.begin(), ::tolower);//转为小写
头文件:#include <ctype.h>
函数声明: int isalpha(int c);
返回值:如果 c 是一个字母,则该函数返回非零值,否则返回 0。
用法示例:
如果str[i] 是字母,就转为小写字母
if (isalpha(str[i]))
{
word.push_back(tolower(str[i]));//转为小写
}
头文件:#include <ctype.h>
声明:int isdigit(int c);
返回值:如果 c 是一个数字,则该函数返回非零值,否则返回 0。
检查所传的字符是否是字母和数字
声明:int isalnum(int c);
返回值:如果 c 是一个数字或一个字母,则该函数返回非零值,否则返回 0。
检查所传的字符是否是小写字母。
声明:int islower(int c);
返回值:如果 c 是一个小写字母,则该函数返回非零值(true),否则返回 0(false)。
检查所传的字符是否是大写字母
声明:int isupper(int c);
返回值:如果 c 是一个大写字母,则该函数返回非零值(true),否则返回 0(false)
__builtin_popcount是GCC自带的内建函数,它可以精确地计算1的个数。内部是用查表实现的。
作用:计算32 位无符号整数 x 在二进制下“1”的个数。
例子:461. 汉明距离
两个整数之间的 汉明距离 指的是这两个数字对应二进制位不同的位置的数目。
给你两个整数 x 和 y,计算并返回它们之间的汉明距离。
【分析】
计算 x 和 y 之间的汉明距离,可以先计算
x
⊕
y
x \oplus y
x⊕y,然后统计结果中等于 1 的位数。
现在,原始问题转换为位计数问题。位计数有多种思路
方法一:C++内置位计数功能(其他方法见数学编程模块)
int hammingDistance(int x, int y) {
return __builtin_popcount(x ^ y);
}
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我正在尝试用ruby中的gsub函数替换字符串中的某些单词,但有时效果很好,在某些情况下会出现此错误?这种格式有什么问题吗NoMethodError(undefinedmethod`gsub!'fornil:NilClass):模型.rbclassTest"replacethisID1",WAY=>"replacethisID2andID3",DELTA=>"replacethisID4"}end另一个模型.rbclassCheck 最佳答案 啊,我找到了!gsub!是一个非常奇怪的方法。首先,它替换了字符串,所以它实际上修改了
我有一些代码在几个不同的位置之一运行:作为具有调试输出的命令行工具,作为不接受任何输出的更大程序的一部分,以及在Rails环境中。有时我需要根据代码的位置对代码进行细微的更改,我意识到以下样式似乎可行:print"Testingnestedfunctionsdefined\n"CLI=trueifCLIdeftest_printprint"CommandLineVersion\n"endelsedeftest_printprint"ReleaseVersion\n"endendtest_print()这导致:TestingnestedfunctionsdefinedCommandLin
如何在Ruby中按名称传递函数?(我使用Ruby才几个小时,所以我还在想办法。)nums=[1,2,3,4]#Thisworks,butismoreverbosethanI'dlikenums.eachdo|i|putsiend#InJS,Icouldjustdosomethinglike:#nums.forEach(console.log)#InF#,itwouldbesomethinglike:#List.iternums(printf"%A")#InRuby,IwishIcoulddosomethinglike:nums.eachputs在Ruby中能不能做到类似的简洁?我可以只
说在前面这部分我本来是合为一篇来写的,因为目的是一样的,都是通过独立按键来控制LED闪灭本质上是起到开关的作用,即调用函数和中断函数。但是写一篇太累了,我还是决定分为两篇写,这篇是调用函数篇。在本篇中你主要看到这些东西!!!1.调用函数的方法(主要讲语法和格式)2.独立按键如何控制LED亮灭3.程序中的一些细节(软件消抖等)1.调用函数的方法思路还是比较清晰地,就是通过按下按键来控制LED闪灭,即每按下一次,LED取反一次。重要的是,把按键与LED联系在一起。我打算用K1来作为开关,看了一下开发板原理图,K1连接的是单片机的P31口,当按下K1时,P31是与GND相连的,也就是说,当我按下去时
我需要一个通过输入字符串进行计算的方法,像这样function="(a/b)*100"a=25b=50function.something>>50有什么方法吗? 最佳答案 您可以使用instance_eval:function="(a/b)*100"a=25.0b=50instance_evalfunction#=>50.0请注意,使用eval本质上是不安全的,尤其是当您使用外部输入时,因为它可能包含注入(inject)的恶意代码。另请注意,a设置为25.0而不是25,因为如果它是整数a/b将导致0(整数)。
我需要从json记录中获取一些值并像下面这样提取curr_json_doc['title']['genre'].map{|s|s['name']}.join(',')但对于某些记录,curr_json_doc['title']['genre']可以为空。所以我想对map和join()使用try函数。我试过如下curr_json_doc['title']['genre'].try(:map,{|s|s['name']}).try(:join,(','))但是没用。 最佳答案 你没有正确传递block。block被传递给参数括号外的方法
在这段Ruby代码中:ModuleMClassC当我尝试运行时出现“'M:Module'的未定义方法'helper'”错误c=M::C.new("world")c.work但直接从另一个类调用M::helper("world")工作正常。类不能调用在定义它们的同一模块中定义的模块函数吗?除了将类移出模块外,还有其他解决方法吗? 最佳答案 为了调用M::helper,你需要将它定义为defself.helper;结束为了进行比较,请查看以下修改后的代码段中的helper和helper2moduleMclassC
也许这听起来很荒谬,但我想知道这对Ruby是否可行?基本上我有一个功能...defadda,bc=a+breturncend我希望能够将“+”或其他运算符(例如“-”)传递给函数,这样它就类似于...defsuma,b,operatorc=aoperatorbreturncend这可能吗? 最佳答案 两种可能性:以方法/算子名作为符号:defsuma,b,operatora.send(operator,b)endsum42,23,:+或者更通用的解决方案:采取一个block:defsuma,byielda,bendsum42,23,