之所以有大小端,是由于在计算机中,数据都是二进制存储的,一个字节八位,比如 char 类型就一个字节,这在所有类型的机器上存储都一样,但是 int 类型呢,4 个字节,也就是 32 位,这四个字节是低字节先存储呢还是高字节先储存呢,这个就是大小端(Big endian 和 Little endian)的由来。
比如 int num = 16777220; 这个数用十六进制表示就是 0x12345678 ,从左往右数, 0x12 是高位字节,0x78 是低位字节。在小端序机子上依次是 0x78、0x56、0x34、0x12 存储,数据高位(高字节)存储在内存高地址,低位(低字节)对应低地址;相应的大端序就是反过来 0x12、0x34、0x56、0x78,数据高位存储在内存低地址,低位对应高地址。
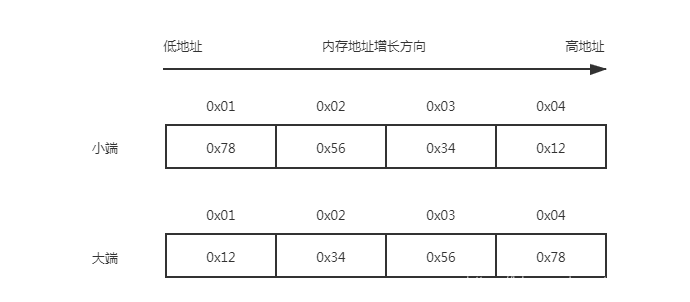
下面就用 GDB 来探索下在真实的机器上 0x12345678 在内存中是如何存储的。
#include <stdio.h>
int main()
{
int i = 0x12345678;
printf("%p\n", &i);
return 0;
}
编译并用 GDB 调试
# gcc test.c -g -o test
# gdb test
……
(gdb) p/x i
$1 = 0x12345678
(gdb) x/b &i
0x7fffffffe62c: 0x78
(gdb) x/4 &i
0x7fffffffe62c: 0x78 0x56 0x34 0x12
可以看到 0x12345678 在内存中是按照 0x78 0x56 0x34 0x12 顺序存储的,因此是小端序。
那如何计算计算机是大端还是小端呢?可以通过 C 中 union (联合体或叫共同体)来检测,union 中所有成员的存放顺序是从低字节到高字节的。
#include <stdio.h>
int isLittleEndian()
{
union {
short i;
char a[2];
} u;
u.a[0] = 0x11;
u.a[1] = 0x22;
return u.i == 0x2211;
}
int main()
{
int flag = isLittleEndian();
printf("this server is %s\n", flag == 1 ? "Little Endian" : "Big Endian");
return 0;
}
编译后运行
# gcc test.c -g -o test
# ./test
this server is Little Endian
若还是有些不明白,那咱们再用 GDB 去调试下,看下内存布局就一目了然了。
# gcc test.c -g -o test
# gdb test
……
(gdb) b isLittleEndian
Breakpoint 1 at 0x4004c8: file end.c, line 10.
(gdb) r
Starting program: /var/www/html/test/c/2105/./end
Breakpoint 1, isLittleEndian () at end.c:10
(gdb) p/x u
$1 = {i = 0x2211, a = {0x11, 0x22}}
(gdb) p/x u.i
$2 = 0x2211
(gdb) p/x u.a
$3 = {0x11, 0x22}
(gdb) x/b &u.a
0x7fffffffe600: 0x11
(gdb) x/4 &u.a
0x7fffffffe600: 0x11 0x22 0xa5 0xf7
仔细看最后一行,0x11 0x22 也就是低字节在低位,高字节在高位,妥妥的小端序嘛。
当然了,还有个更简单的方法
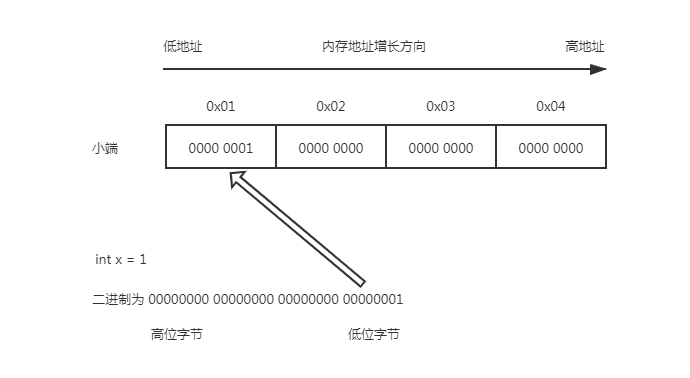
int testEndian() {
int x = 1;
return *((char *)&x);
}
如果返回 1,那么为小端,否则就是大端。原理和上面介绍的一致,x 类型为 int,占 4 个字节,char 占 1 个字节,当用 char 指向 int 时,只会指向首字节,如果这个字节存储的为 1,那么说明是小端。因为 x 二进制为 00000000 00000000 00000000 00000001,高字节为 0,低字节为 1,按照上面说的低字节放在低地址,那就是小端了。
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
我在一段非常简单的代码(如我所想)中得到了一个错误的值:org=4caseorgwhenorg=4val='H'endputsval=>nil请不要生气,我希望我错过了一些非常明显的东西,但我真的想不通。谢谢。 最佳答案 这是典型的Ruby错误。case有两种被调用的方法,一种是你传递一个东西作为分支的基础,另一种是你不传递的东西。如果您确实在case中指定了一个表达式语句然后评估所有其他条件并与===进行比较.在这种情况下org评估为false和org===false显然不是真的。所有其他情况也是如此,它们要么是真的,要么是假的。
我有以下内容:text.gsub(/(lower)(upper)/,'\1\2')我可以将\2替换为大写吗?类似于:sed-e's/\(abc\)/\U\1/'这在Ruby中可行吗? 最佳答案 查看gsub文档:str.gsub(模式){|匹配|block}→new_str在block形式中,当前匹配字符串作为参数传入,$1、$2、$`、$&、$'等变量将被适当设置。block返回的值将替换为每次调用的匹配项。"alowerupperb".gsub(/(lower)(upper)/){|s|$1+""+$2.upcase}
很难说出这里要问什么。这个问题模棱两可、含糊不清、不完整、过于宽泛或夸夸其谈,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开,visitthehelpcenter.关闭9年前。我正在创建一个Sinatra应用程序,它采用上传的CSV文件并将其内容放入哈希中。当我像这样在我的app.rb中引用这个散列时:hash=extract_values(path_to_filename)我不断收到此错误消息:undefinedmethod`bytesize'forHash:0x007fc5e28f2b90#object_idfile:utils.rblocation:bytesiz
2个数组的数组:a=[[1,2],[22,11],[18,9]]b=[[1,81]]用[0,0]填充第二个的最佳方法是什么,以便它们具有相同的大小? 最佳答案 b.fill(b.size..a.size-1){[0,0]} 关于ruby-使2个数组大小相同,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/29725615/
我收到“ArgumentError:数组大小太大”消息,代码如下:MAX_NUMBER=600_000_000my_array=Array.new(MAX_NUMBER)问题。Array.new函数在Ruby中的最大值是多少? 最佳答案 具有5亿个元素的数组的大小为2GiBytes,这取决于您使用的特定操作系统,通常是一个进程可以处理的最大值。换句话说:您的数组大于您的地址空间。因此,解决方案很明显:要么缩小数组(例如,将其分成block),要么扩大地址空间(在Linux中,您可以修补内核以获得3、3.5甚至4GiByte地址空间,
Model.exists?("lower(email)=?",params[:email].downcase)返回错误:ArgumentError(参数数量错误(2代表0..1)):是否可以使用不区分大小写的匹配来执行exists?? 最佳答案 您需要做的就是:Model.exists?(["lower(email)=?",params[:email].downcase])它正在寻找一个参数,但您提供了两个。使用数组形式和查找式条件应该可以满足您的需求。 关于ruby-on-rails-
给定一个数组['a','b','c','d','e','f'],我如何获得包含两个的所有子集的列表、三、四元素?我是Ruby的新手(从C#迁移过来),不确定“Ruby之道”是什么。 最佳答案 查看Array#combination然后是这样的:2.upto(4){|n|array.combination(n)} 关于ruby-使用Ruby在数组中查找大小为N的所有子集,我们在StackOverflow上找到一个类似的问题: https://stackoverf
我是Ruby的新手,正在尝试解决让我感到困惑的问题。在编写一个简单的解析器时,我发现将char与==进行比较与将其与case表达式进行比较会产生不同的结果:File.open('Quote.txt')do|f|f.chars.eachdo|c|putsc=='"'?'Quote':'Err'putscasecwhen'"'then'QuoteCase'else'ErrCase'endpc=='"',c==='"',cendend假设Quote.txt是一个包含单引号字符(0x22)的1字节文件,这将产生:QuoteErrCasetruetrue"\""我假设我做错了什么,但我无法弄清楚