Calico官方文档:https://projectcalico.docs.tigera.io/getting-started/kubernetes/quickstart
Calico是一套开源的网络和网络安全解决方案,用于容器、虚拟机、宿主机之前的网络连接,它是一个纯三层的虚拟化网络解决方案,它把每个节点都作为一个虚拟路由器,并把每个节点上的Pod当作是节点路由器后的一个终端设备并为其分配一个IP地址。各节点路由器通过BGP协议生成路由规则,从而实现不通节点上Pod间的通信。如下图:
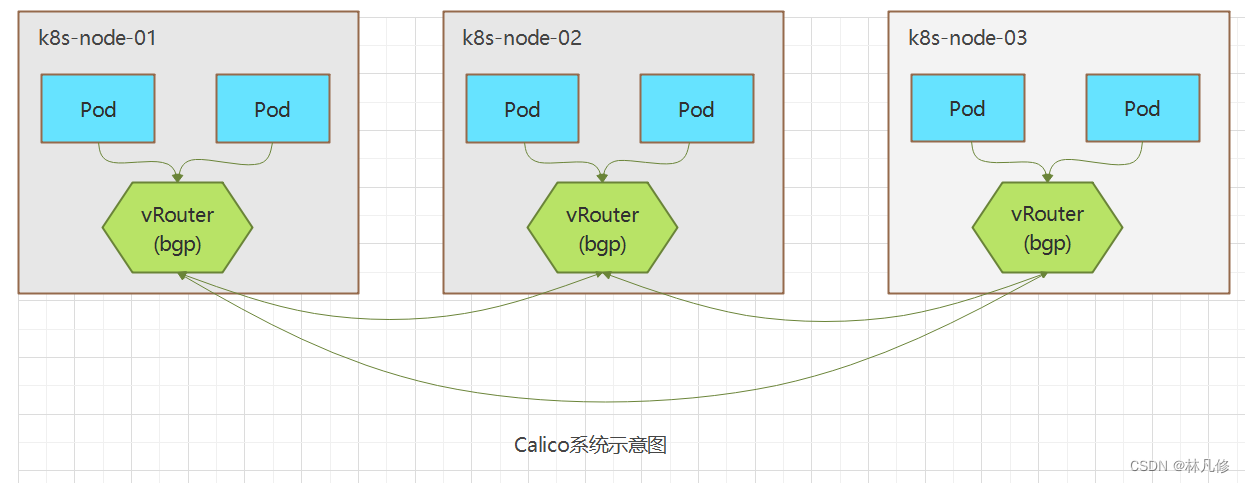
与Flannel相比,Calico的一个显著优势是对网络策略的支持,它允许用户定义访问控制规则以管控进出Pod的数据报文,从而为Pod间的通信施加安全策略。
BGP是一个去中心化自治路由协议,它通过维护IP路由表或“前缀”来实现自治系统之间的可达性,通常作为大规模数据中心维护不同自治系统之间路由信息的矢量路由协议。Linux内核原生支持BGP,因此可以把一台Linux主机配置为边界网关。
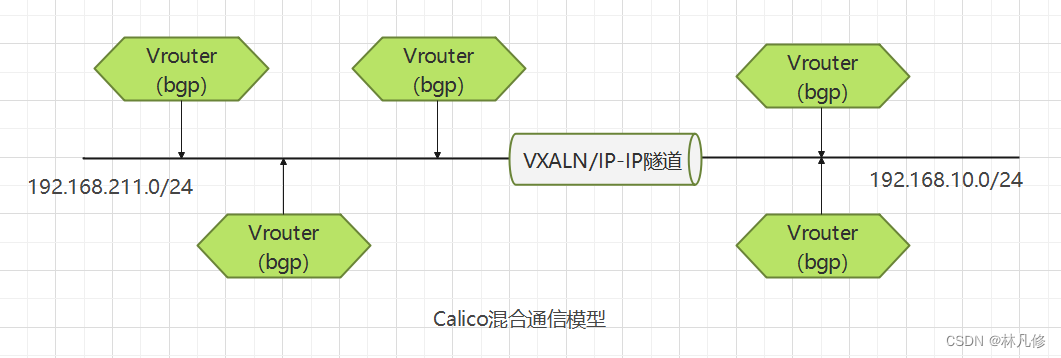
Calico把每个节点上Pod组成的网络视为一个自治系统(AS),而每个节点就相当于自治系统的边界网关。各节点之间通过BGP协议交换路由信息并生成路由规则。但并非所有的网络环境都能支持BGP,而且BGP路由模型要求所有节点位于同一个二层网络中,所以Calico还支持基于IPIP和VXLAN的Overlay网络模型。
另外,类似于Flannel的 VXALN后端启用Directrouting时的网络模型,Calico也支持混合使用路由和Overlay网络模型,BGP路由模型用于二层网络的高性能通信,IPIP或VXLAN用于跨二层网络节点间Pod报文的转发,如下图所示:
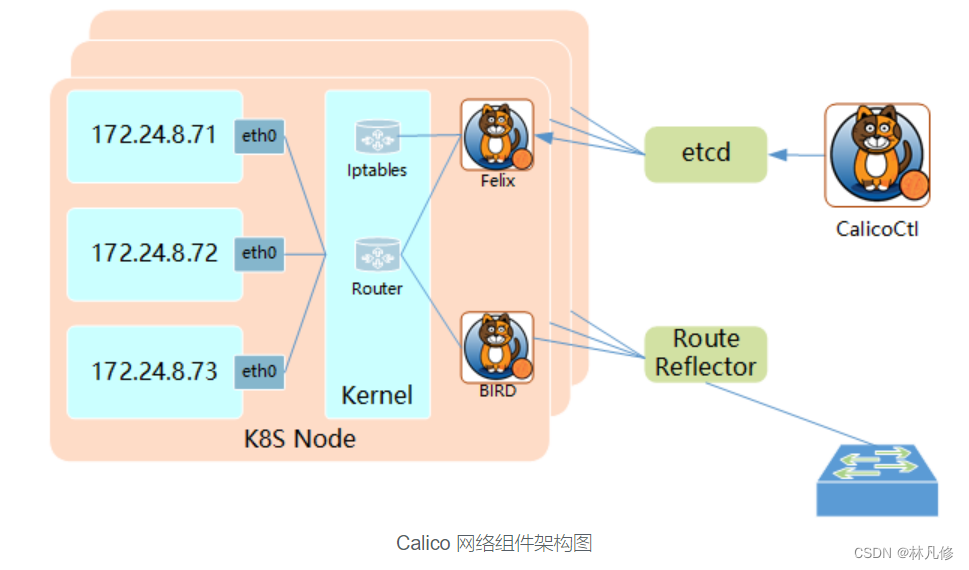
如上图所示,Calico的组件主要有Felix、etcd存储系统、BIRD和BGP路由反射器等,各组件的作用如下:
另外,Calico可以将关键配置抽象为资源类型,并允许用户按需自定义资源对象已完成系统配置,这些资源对象保存在Datastore中,Datastore可以是独立的etcd,也可以是k8s集群使用的etcd。Calico专有资源类型有十几种,包括IPPool(IP地址池)、NetworkPolicy(网络策略)、BGPConfiguration(BGP配置参数)等。类似于Kubernetes API资源的定义,这些资源的配置格式同样以JSON使用apiVersion、kind、metadata和spec等一级字段进行定义,并能够使用calicoctl客户端工具进行管理,也支持由kubelet借助CRD进行这类资源的管理。
在k8s集群上实际部署时,Calico分为calico-node和calico-kube-controllers两个组件,它们通过Datastore读取与自身相关的资源定义完成配置
从官网下载部署文件:
https://raw.githubusercontent.com/projectcalico/calico/v3.24.5/manifests/calico.yaml
curl https://raw.githubusercontent.com/projectcalico/calico/v3.24.5/manifests/calico.yaml -O
修改部署文件以适配k8s集群环境
首先修改部署文件中CALICO_IPV4POOL_CIDR变量的值,将其设置为初始k8s化集群时设定的pod-cidr,例如:
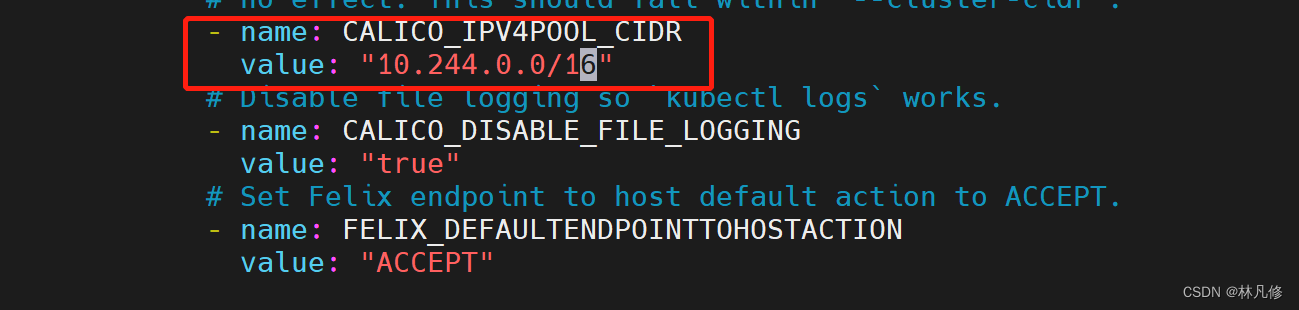
然后修改CALICO_IPV4POOL_BLOCK_SIZE变量的值,指定Calico为节点分配地址段的掩码长度,默认26
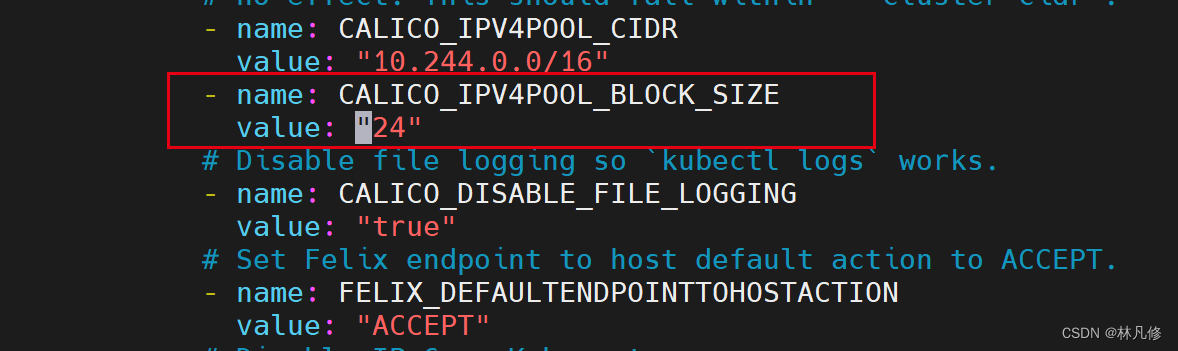
Calico的部署文件默认使用的是IPIP 隧道模式,这里就保持默认,不再进行修改。如果要使用纯BGP路由模式或者混合模式可以修改变量CALICO_IPV4POOL_IPIP的值,可用值如下:
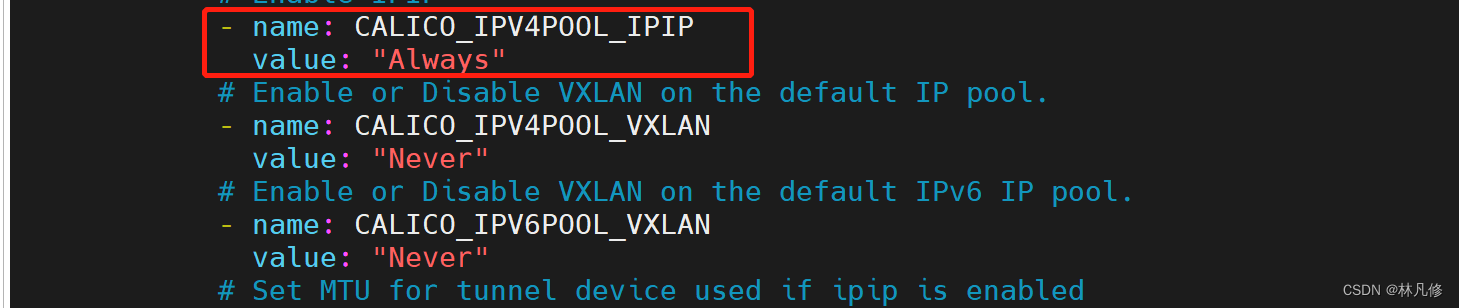
如果想要使用VXLAN隧道网络,而不是IPIP隧道网络,可以修改变量CALICO_IPV4POOL_VXLAN的值,可用值和逻辑与变量CALICO_IPV4POOL_IPIP一致。
更多变量的配置和介绍可以参考官网介绍:https://projectcalico.docs.tigera.io/reference/node/configuration
将部署文件应用到集群之上,等待Calico相关Pod成功运行且无报错就表示Calico部署成功。
kubectl apply -f calico.yaml

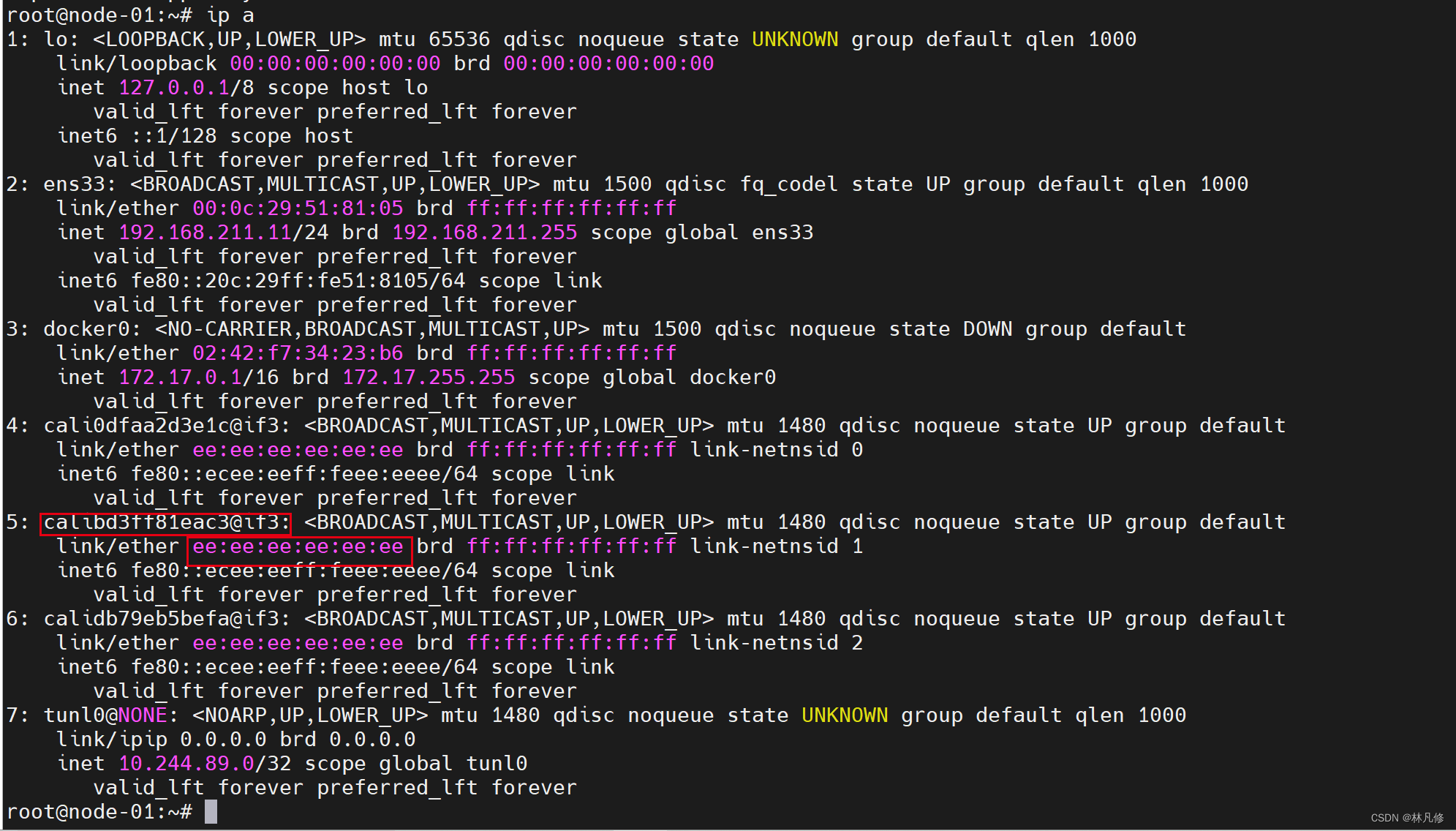
工作在IPIP模式的Calico会在每个节点创建一个tunl0接口作为隧道出入口设备来封装IPIP隧道报文。Calico会为每个Pod资源创建一对veth设备,其中一端作为Pod的网络接口,另一端(名为calixxx)留在宿主机的网络名称空间,它不使用虚拟网桥。如下图所示:
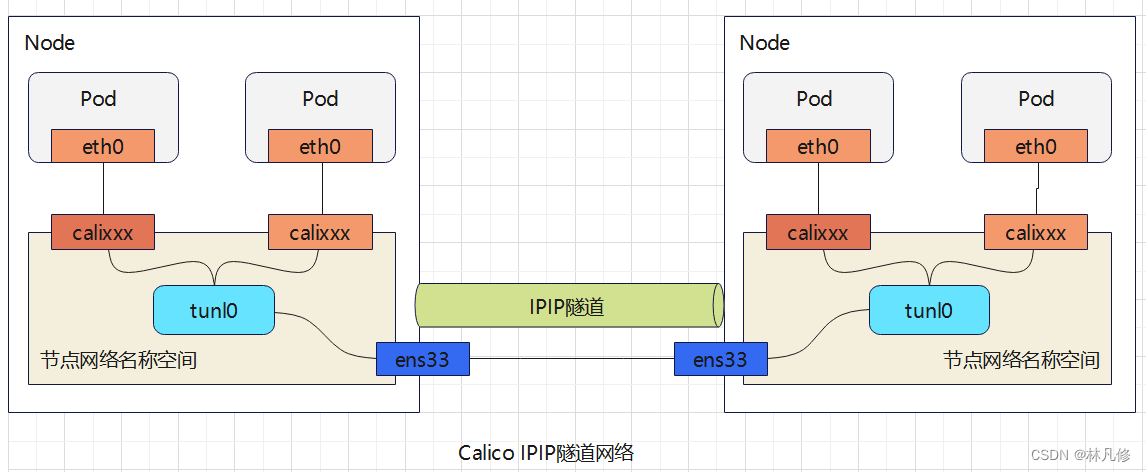
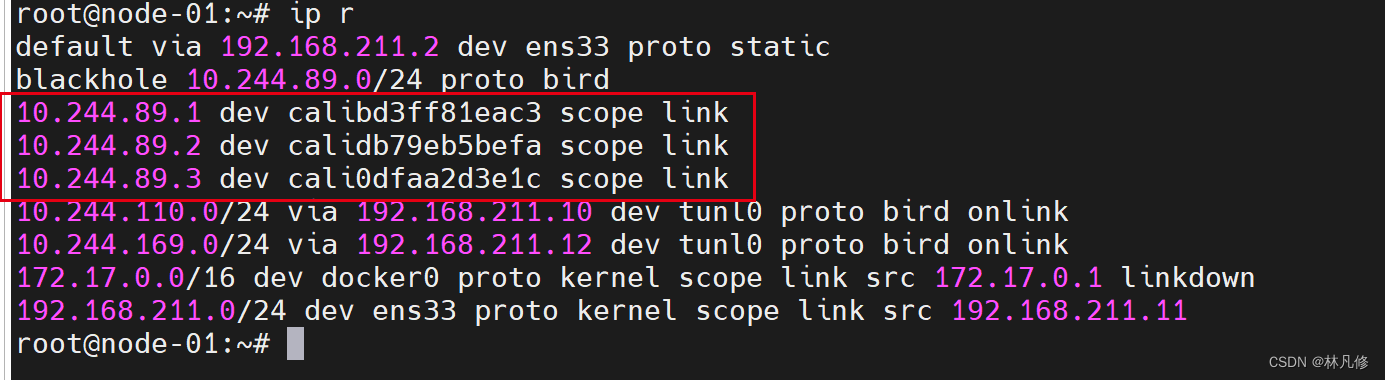
IPIP隧道网络也是依赖BGP来维护节点的路由信息。部署完成后,Calico会通过BGP协议在每个节点上生成到达其它节点Pod子网的路由信息。例如下面node-01上的路由信息,它们是由各节点上的BIRD以点对点的方式向网络中的其它节点进行通告并学习其它节点的通告而生成。
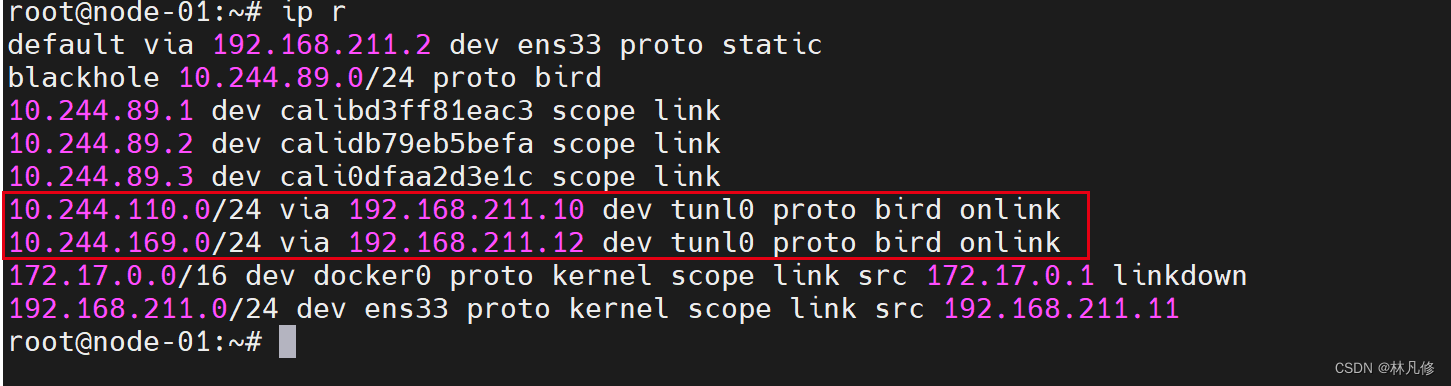
对于每个Pod,Calico都会在节点上为其生成一个专用路由条目,用于确保以Pod IP为目标的报文可以通过节点上的calixxx接口送达,这是因为Calico没有像Flannel一样使用虚拟网桥进行报文转发导致的。相关路由条目如下所示:
Pod通信流程分析
集群中node-02上运行一个nginx-pod(10.244.89.5),在node-01上的client-pod(10.244.169.3)上请求nginx-pod,其过程大致如下:
client-pod发送请求,根据Pod中的默认路由将报文送到主机上对应的calixxx接口,此时
src-ip:10.244.89.5 dst-ip:10.244.169.3
src-mac:b2:65:39:08:87:b0 dst-mac:ee:ee:ee:ee:ee:ee
在calixxx接口抓包如下:
此时发现一个问题,我们在client-pod内查看路由,发现默认路由是169.254.1.1,如下图所示。但是169.254.1.1这个地址是不存在的,这是什么情况?

根据网络常识,当数据包目的地址不是本机时,会根据路由表查询网关,查询到网关后发送ARP请求查询网关MAC,然后修改数据的的目标MAC,所以无论这个地址是不是存在,只要ARP请求可以获取它的MAC即可。
所以,在Pod内查看一下169.254.1.1对应的MAC,如下图:

169.254.1.1对应的MAC是ee:ee:ee:ee:ee:ee,这是主机上calixxx接口的MAC,但这也不符合逻辑,主机上的calixxx接口没有这个地址,为什么ARP获取到的MAC是它的MAC?
这其实是因为calixxx接口启用了网卡的ARP代理功能,如下图:

代理 ARP 是 ARP 协议的一个变种,当 ARP 请求目标跨网段时,网关设备收到此 ARP 请求,会用自己的 MAC 地址返回给请求者,这便是代理 ARP(Proxy ARP)。所以,Pod内发送的ARP请求到达calixxx接口时,calixxx接口直接返回了自己的MAC。
数据报文根据主机路由表,将报文转给tunl0接口进行IPIP封装
tunl0接口抓包如下:

此时应该是把外层的MAC头部给去掉了,然后进行IPIP封装
封装好的IPIP数据报文通过主机接口ens33发出 ,此时
inner-src-ip: 10.224.89.5 inner-dst-ip:10.224.169.3
outer-src-ip:192.168.211.11 outer-dst-ip:192.168.211.12
src-mac:00:0c:29:51:81:05 dst-mac:00:0c:29:99:52:7b

node-02收到报文后进行解封装,然后发送给ngix-pod
关于Calico其它模式的配置和使用,可以参考官网:https://projectcalico.docs.tigera.io/about/about-calico
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
我对最新版本的Rails有疑问。我创建了一个新应用程序(railsnewMyProject),但我没有脚本/生成,只有脚本/rails,当我输入ruby./script/railsgeneratepluginmy_plugin"Couldnotfindgeneratorplugin.".你知道如何生成插件模板吗?没有这个命令可以创建插件吗?PS:我正在使用Rails3.2.1和ruby1.8.7[universal-darwin11.0] 最佳答案 随着Rails3.2.0的发布,插件生成器已经被移除。查看变更日志here.现在
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
您认为可以作为插件很好地存在于您的Rails应用程序中必须实现的哪些行为?您过去曾搜索过哪些插件功能但找不到?哪些现有的Rails插件可以改进或扩展,如何改进或扩展? 最佳答案 我希望在管理界面中看到一个引擎插件,它提供了应用程序中所有模型的仪表板摘要,以及可配置的事件图表。 关于ruby-on-rails-您希望看到哪些Rails插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questio
我们正在使用Vagrant进行部署,我们最终希望将此集群部署在Rackspace上。vagrant-rackspace插件是一个自然的选择,但它有一些错误,这些错误未包含在最新的0.1.1版本中(notablythatvagrantprovisiondoesn'twork)。我已经在我的personalfork中解决了这个问题通过合并其他人的工作来对存储库进行改造。是否可以从github安装vagrant插件?显而易见的事情没有奏效:[unix]$vagrantplugininstallvagrant-rackspace--plugin-sourcehttps://github.com
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案
我在这方面尝试了很多URL,在我遇到这个特定的之前,它们似乎都很好:require'rubygems'require'nokogiri'require'open-uri'doc=Nokogiri::HTML(open("http://www.moxyst.com/fashion/men-clothing/underwear.html"))putsdoc这是结果:/Users/macbookair/.rvm/rubies/ruby-2.0.0-p481/lib/ruby/2.0.0/open-uri.rb:353:in`open_http':404NotFound(OpenURI::HT
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
(本文是网络的宏观的概念铺垫)目录计算机网络背景网络发展认识"协议"网络协议初识协议分层OSI七层模型TCP/IP五层(或四层)模型报头以太网碰撞路由器IP地址和MAC地址IP地址与MAC地址总结IP地址MAC地址计算机网络背景网络发展 是最开始先有的计算机,计算机后来因为多项技术的水平升高,逐渐的计算机变的小型化、高效化。后来因为计算机其本身的计算能力比较的快速:独立模式:计算机之间相互独立。 如:有三个人,每个人做的不同的事物,但是是需要协作的完成。 而这三个人所做的事是需要进行协作的,然而刚开始因为每一台计算机之间都是互相独立的。所以前面的人处理完了就需要将数据