目录
本文详细记录了函数grouping sets使用时遇到的坑,全文代码基于Hive和Presto实现。
首先建立商品销售表:
CREATE TABLE temp.goods_sale_info(
`province` string comment '省份',
`city` string comment '城市',
`goodsid` string comment '商品编号',
`goodsname` string comment '商品名称',
`sales_qty` decimal(38,5) comment '销量',
`sales_amt` decimal(38,5) comment '销售额'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
insert into table temp.goods_sale_info
values ('江西省','南昌市','1000','可口可乐','10','40')
,('福建省','福州市','1000','可口可乐','200','1000')
,('福建省','厦门市','1000','可口可乐','300','1500')
,('福建省','厦门市','1200','百事可乐','200','1000')
,('福建省','厦门市','2000','伊利安慕希','300','21000');
select * from temp.goods_sale_info
再建立一个商品信息表:
CREATE TABLE temp.goods_info(
`goodsid` string comment '商品编号',
`goodsname` string comment '商品名称',
`catgory_id` string comment '商品种类编号',
`catgory_name` string comment '商品种类'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
insert into table temp.goods_info
values ('1000','可口可乐','11','饮料')
,('1200','百事可乐','11','饮料')
,('2000','伊利安慕希','12','乳制品')
select * from temp.goods_info
根据不同字段分组聚合实现各个维度的销量和销售额
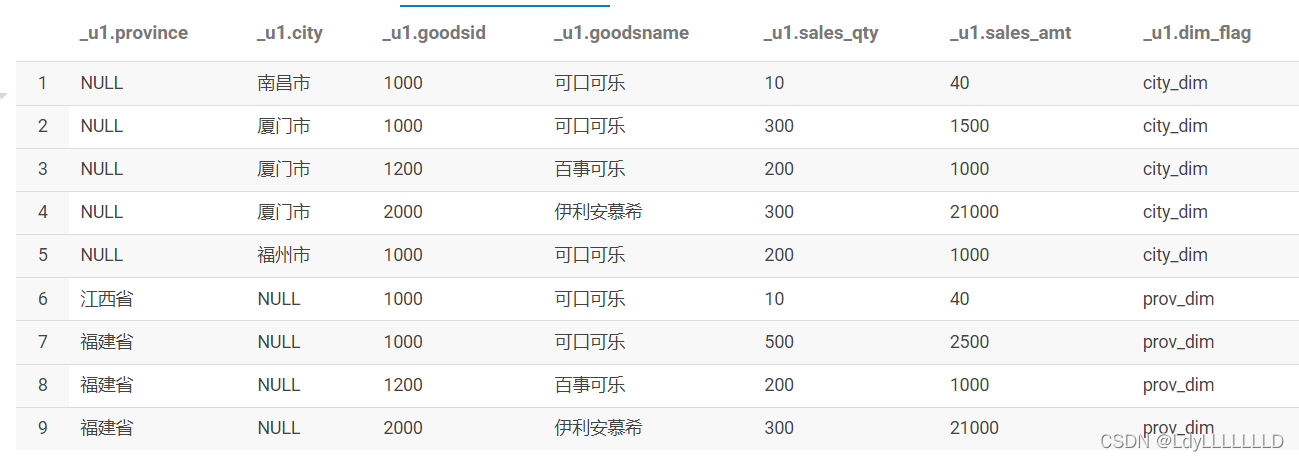
要实现城市’'city’维度聚合求商品销量、销售额以及从省份’province’维度聚合求商品销量、销售额,并放入一个表中,一般可以采用下面两种方法:
-- 方法1:分开聚合
select province
,NULL as city
,goodsid
,goodsname
,sum(sales_qty) as sales_qty
,sum(sales_amt) as sales_amt
,'prov_dim' dim_flag
from temp.goods_sale_info
group by province,goodsid,goodsname
union all
select NULL as province
,city
,goodsid
,goodsname
,sum(sales_qty) as sales_qty
,sum(sales_amt) as sales_amt
,'city_dim' dim_flag
from temp.goods_sale_info
group by city,goodsid,goodsname
运行结果:
-- 方法2:with cube高级别聚合
create table temp.goods_sales_info_cube as -- 要生成表才可以进行下一步筛选,起表别名后嵌套筛选不出来
select province
,city
,goodsid
,goodsname
,sum(sales_qty) as sales_qty
,sum(sales_amt) as sales_amt
,grouping__id --,可写可不写
from temp.goods_sale_info
group by
province
,city
,goodsid
,goodsname with cube
-- rollup 是以最左侧指标为主进行组合聚合,是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合。更换province和city的前后会出来不同结果
-- rollup是cube的一种特殊情况,cube对所有的维度进行聚合,会出现city,province和province,city的结果
-- 对生成的结果进行筛选,即可得到与方法1同样的结果
select *
from temp.goods_sales_info_cube
where grouping__id in ('13','14')
-- 不想生成grouping__id字段的话可以用下面条件判断
-- where (province is null and city is not null and goodsid is not null and goodsname is not null)
-- or (province is not null and city is null and goodsid is not null and goodsname is not null)
运行结果:

相较于with rollup 和with cube,grouping sets可以实现分组字段的自由组合,当分组字段变多,想要按需分组时候用grouping sets更方便。
对于多个维度聚合问题,grouping sets不用像cube方式将分组字段排列组合列出全部维度的结果,能够实现更灵活的组合。
select province
,city
,goodsid
,goodsname
,sum(sales_qty) as sales_qty
,sum(sales_amt) as sales_amt
,GROUPING__ID
from temp.goods_sale_info
group by province
,city
,goodsid
,goodsname
grouping sets(
(), -- 1、全国销量、销售额
(goodsid,goodsname), -- 2、各商品的全国销量、销售额
(province,goodsid,goodsname), -- 3、各省各商品的销量、销售额
(province,goodsid), -- 4、各省各商品的销量、销售额
(city) -- 5、各城市销量、销售额
)
运行结果:
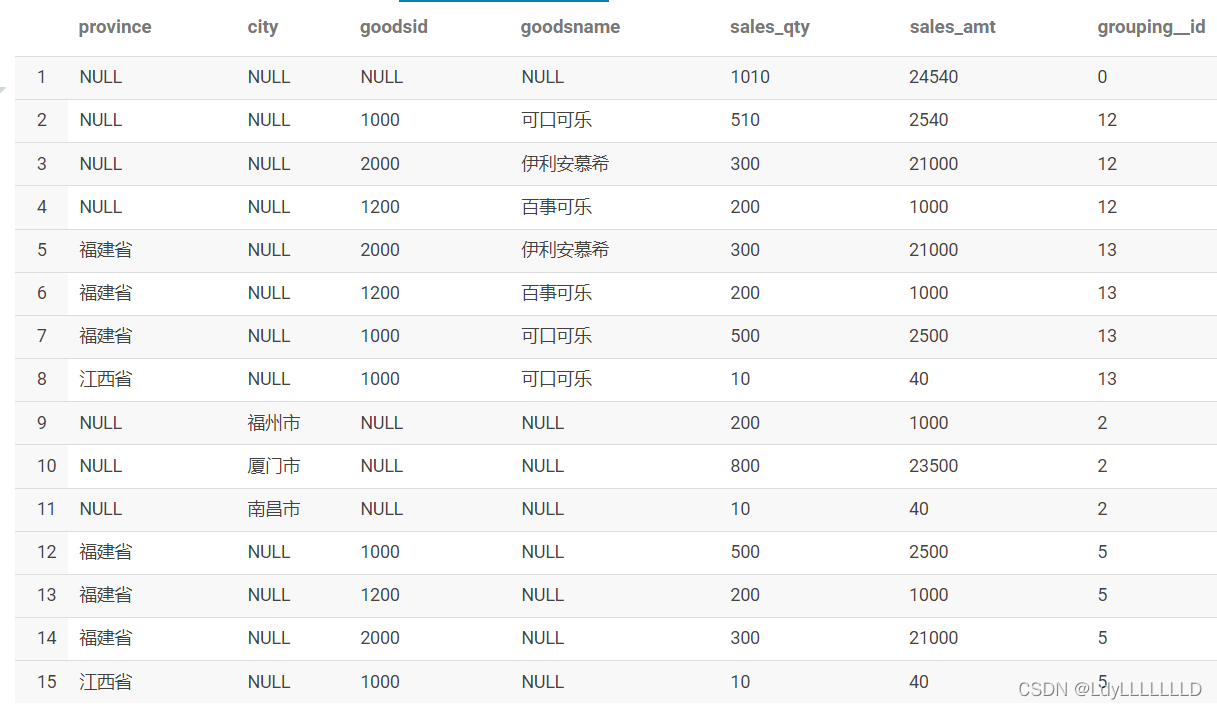
函数及运行结果讲解:
1、group by后面放的字段表示要分组聚合的全部字段
2、grouping sets 后面放的是 group by 后面各种字段的组合,根据实际需求进行组合,组合字段用小括号括起来(上面代码中的第2、3、4组),也可以是单一字段(上面代码中sets里面的第5组)
3、在求取全国的成交量的时候其实是不需要分组聚合的,但是为了使用 grouping sets,所以在求取全国成交量的时候用 group by null(上面代码中sets里面的第1组)
4、sets中第3组和第4组的区别在于有没有写goodsname,没有写goodsname的第4组生成的结果中goodsname列为空值
在具有表联结语句中grouping sets函数使用有个踩坑点,初次使用很可能都报错找不到原因。。总结一下就是:
表联结的结果出来之后再用grouping sets,分组字段组合sets里面用表别名会报错。
报错语句见下:
-- 报错语句
select t1.province
,t1.city
,t2.catgory_id
,t2.catgory_name
,t1.goodsid
,t1.goodsname
,sum(t1.sales_qty) as sales_qty
,sum(t1.sales_amt) as sales_amt
,GROUPING__ID
from temp.goods_sale_info t1
left join
temp.goods_info t2
on t1.goodsid=t2.goodsid
group by
t1.province
,t1.city
,t2.catgory_id
,t2.catgory_name
,t1.goodsid
,t1.goodsname
grouping sets(
(t1.province,t2.catgory_id,t2.catgory_name)
)
正确语句见下:
-- 正确语句
select province
,city
,catgory_id
,catgory_name
,goodsid
,goodsname
,sum(sales_qty) as sales_qty
,sum(sales_amt) as sales_amt
,GROUPING__ID
from
(
select t1.province
,t1.city
,t2.catgory_id
,t2.catgory_name
,t1.goodsid
,t1.goodsname
,sales_qty
,sales_amt
from temp.goods_sale_info t1
left join
temp.goods_info t2
on t1.goodsid=t2.goodsid
) t --在表t的基础上使用grouping sets函数
group by
province
,city
,catgory_id
,catgory_name
,goodsid
,goodsname
grouping sets(
(province,catgory_id,catgory_name)
--这里仅有3个字段,但select中列有不在sets中的非分组字段city、goodsid、goodsname,hive不报错,presto会报错
)
运行结果:

1、select子句中的GROUPING__ID是两个下划线
2、执行语句后GROUPING__ID的结果是数字,如果sets中有5种组合,GROUPING__ID会生成5个不等的数字,具体哪个数字对应哪个维度,需要根据生成的表进行测试判断,或者根据下面2.4节的方法用二进制去计算确定,用于自定义划分维度
3、GROUPING__ID的数字只要不改变表以及查询条件,每次运行都是这些数字
方法描述:
grouping sets 中的每一种粒度,都对应唯一的 grouping__id 值,其计算公式与 group by 的顺序、当前粒度的字段有关。
具体计算方法如下:
1、字段排序
将字段按照group by后的顺序 进行排序,例如是3个字段
2、字段赋值
根据grouping sets的每个set中的字段,用0或1进行赋值,例如group by后跟了3个字段结果就会给出一个有3个数字的二进制数。
赋值规则为 对于每个字段,如果该字段有值则赋给0,空值则给1。出现在当前粒度中,则给0,没出现则给1
3、转化十进制
上面赋值后就形成了一个二进制数,然后将二进制转为10进制就是grouping__id的值
下面为了不进行数据测试,直接根据grouping__id的值来判断grouping__id对应的是哪个维度,在select语句中可以按照如下方式判断:
4、判断维度
按照group by字段顺序求 数字2 的幂次方,紧挨着group by的字段为最高次方,依次递减,然后对grouping__id和 相应层级的幂次方 用位运算 ”&与“ 来判断维度
举个例子:
select province
,city
,goods_id
,if(grouping__id & cast(pow(2,2) as int) =0,'province','') as dim
,sum(sales_amt)
from tmp.table1
group by
province
,city
,goods_id
grouping sets(
(province,city)
,(province)
)
第一步:按顺序,group by 后面是province,city,goods_id,
第二步:以sets中的province为例,得到的二进制数是 011
第三步:转化为十进制,011 为 1*20+1*21+0 =3
第四步:根据province,city,goods_id的顺序,分别为 2的平方、2的1次方、2的0次方
在select中想要判断出province维度,即可用 2的平方 去做位运算, 2的平方对应的二进制为 100
对比
0 1 1
1 0 0
其位运算结果为0
则该grouping__id 对应的是province维度
tips:
跟hive的版本有关,有的版本使用下面的规则:
1、字段排序:将 group by 后面的字段 倒序 排列
2、字段赋值:对于每个字段,如果该字段出现在了当前粒度中,则该字段位置赋值为1,否则为0。
3、转化十进制:将这个二进制数转为十进制,即为当前粒度对应的 grouping__id
用法:
1、函数grouping要与group by、grouping sets配合使用
2、函数grouping()中列出sets中所有分组涉及的字段,运行后grouing()列生成结果为二进制转化来的十进制数字
-- 比如
select column1,column2,column3,
grouping(column1,column2,column3)
group by
grouping sets(
(column1),
(column2,column3)
)
-- 如果分组中包含相应的列,则将位设置为0,否则将其设置为1
-- 第一组 中 三个字段的 为 0 1 1
-- 第二组 中 三个字段的 为 1 0 0
-- grouping函数的值即为011和100对应的十进制数字
参考链接:presto grouping操作
3、group by后面只跟grouping sets(),不加select中的单一字段,否则函数grouping sets无作用
-- 如果group by写上单一字段
select province
,city
,catgory_id
,catgory_name
,goodsid
,goodsname
,sum(sales_qty) as sales_qty
,sum(sales_amt) as sales_amt
,grouping(province,city,catgory_id,catgory_name,goodsid,goodsname)
from
(
select t1.province
,t1.city
,t2.catgory_id
,t2.catgory_name
,t1.goodsid
,t1.goodsname
,sales_qty
,sales_amt
from temp.goods_sale_info t1
left join
temp.goods_info t2
on t1.goodsid=t2.goodsid
) t --也是要在表t的基础上使用grouping sets函数
group by
province
,city
,catgory_id
,catgory_name
,goodsid
,goodsname
,grouping sets( --这里记得加上逗号,
(province,catgory_id,catgory_name),
(province,catgory_id,catgory_name,goodsid,goodsname),
(province,city),
(province)
)
运行结果:
表t结果有5条记录,grouping sets中有4种组合。按照上面语句执行,结果记录数为 5×4=20条记录,同理1种组合结果为5×1,2种组合为5×2,3种组合为5×3

4、不用的分组字段不要在select子句中写出
-- 与hive不同,如果不出现在grouping sets中的字段,select子句写上会报错
-- 比如sets中不涉及city、goodsid、goodsname,select子句中写出来报错
select province
-- ,city
,catgory_id
,catgory_name
-- ,goodsid
-- ,goodsname
,sum(sales_qty) as sales_qty
,sum(sales_amt) as sales_amt
,grouping(province,catgory_id,catgory_name)
from
(
select t1.province
,t1.city
,t2.catgory_id
,t2.catgory_name
,t1.goodsid
,t1.goodsname
,sales_qty
,sales_amt
from temp.goods_sale_info t1
left join
temp.goods_info t2
on t1.goodsid=t2.goodsid
) t
group by
grouping sets(
(province,catgory_id,catgory_name)
)
5、函数grouping中要将grouping sets所有分组组合用到的字段取并集列出
select province
,city
,catgory_id
,catgory_name
,goodsid
,goodsname
,sum(sales_qty) as sales_qty
,sum(sales_amt) as sales_amt
,grouping(province,city,catgory_id,catgory_name,goodsid,goodsname)
-- grouping里面一定要把sets中用到的字段写全,不然生成的数字会缺
-- 比如下面sets中有3种组合,如果grouping()种缺少字段,数字会不是3个
from
(
select t1.province
,t1.city
,t2.catgory_id
,t2.catgory_name
,t1.goodsid
,t1.goodsname
,sales_qty
,sales_amt
from temp.goods_sale_info t1
left join
temp.goods_info t2
on t1.goodsid=t2.goodsid
) t --也是要在表t的基础上使用grouping sets函数
group by
grouping sets(
(province,catgory_id,catgory_name),
(province,catgory_id,catgory_name,goodsid,goodsname),
(province,city)
)
综上可见,可以对比出presto与hive在grouping sets函数使用上的区别:
1、Hive中select子句中用GROUPING__ID,GROUPING__ID不是函数;Presto的select子句中grouping是一个函数,要采用grouping(column_1,column_2,…),列出分组涉及到的所有字段。不过两者运行后的结果都是数字,可以用于后面的维度测试
2、Hive的group by子句中要列出单一字段,然后加上grouping sets,并且grouping sets 前面不加逗号“,”;Presto的group by子句中仅有grouping sets
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我正在尝试用ruby中的gsub函数替换字符串中的某些单词,但有时效果很好,在某些情况下会出现此错误?这种格式有什么问题吗NoMethodError(undefinedmethod`gsub!'fornil:NilClass):模型.rbclassTest"replacethisID1",WAY=>"replacethisID2andID3",DELTA=>"replacethisID4"}end另一个模型.rbclassCheck 最佳答案 啊,我找到了!gsub!是一个非常奇怪的方法。首先,它替换了字符串,所以它实际上修改了
我有一些代码在几个不同的位置之一运行:作为具有调试输出的命令行工具,作为不接受任何输出的更大程序的一部分,以及在Rails环境中。有时我需要根据代码的位置对代码进行细微的更改,我意识到以下样式似乎可行:print"Testingnestedfunctionsdefined\n"CLI=trueifCLIdeftest_printprint"CommandLineVersion\n"endelsedeftest_printprint"ReleaseVersion\n"endendtest_print()这导致:TestingnestedfunctionsdefinedCommandLin
如何在Ruby中按名称传递函数?(我使用Ruby才几个小时,所以我还在想办法。)nums=[1,2,3,4]#Thisworks,butismoreverbosethanI'dlikenums.eachdo|i|putsiend#InJS,Icouldjustdosomethinglike:#nums.forEach(console.log)#InF#,itwouldbesomethinglike:#List.iternums(printf"%A")#InRuby,IwishIcoulddosomethinglike:nums.eachputs在Ruby中能不能做到类似的简洁?我可以只
说在前面这部分我本来是合为一篇来写的,因为目的是一样的,都是通过独立按键来控制LED闪灭本质上是起到开关的作用,即调用函数和中断函数。但是写一篇太累了,我还是决定分为两篇写,这篇是调用函数篇。在本篇中你主要看到这些东西!!!1.调用函数的方法(主要讲语法和格式)2.独立按键如何控制LED亮灭3.程序中的一些细节(软件消抖等)1.调用函数的方法思路还是比较清晰地,就是通过按下按键来控制LED闪灭,即每按下一次,LED取反一次。重要的是,把按键与LED联系在一起。我打算用K1来作为开关,看了一下开发板原理图,K1连接的是单片机的P31口,当按下K1时,P31是与GND相连的,也就是说,当我按下去时
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我需要一个通过输入字符串进行计算的方法,像这样function="(a/b)*100"a=25b=50function.something>>50有什么方法吗? 最佳答案 您可以使用instance_eval:function="(a/b)*100"a=25.0b=50instance_evalfunction#=>50.0请注意,使用eval本质上是不安全的,尤其是当您使用外部输入时,因为它可能包含注入(inject)的恶意代码。另请注意,a设置为25.0而不是25,因为如果它是整数a/b将导致0(整数)。
您认为可以作为插件很好地存在于您的Rails应用程序中必须实现的哪些行为?您过去曾搜索过哪些插件功能但找不到?哪些现有的Rails插件可以改进或扩展,如何改进或扩展? 最佳答案 我希望在管理界面中看到一个引擎插件,它提供了应用程序中所有模型的仪表板摘要,以及可配置的事件图表。 关于ruby-on-rails-您希望看到哪些Rails插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questio
我需要从json记录中获取一些值并像下面这样提取curr_json_doc['title']['genre'].map{|s|s['name']}.join(',')但对于某些记录,curr_json_doc['title']['genre']可以为空。所以我想对map和join()使用try函数。我试过如下curr_json_doc['title']['genre'].try(:map,{|s|s['name']}).try(:join,(','))但是没用。 最佳答案 你没有正确传递block。block被传递给参数括号外的方法