Android 音视频编解码(一) – MediaCodec 初探
Android 音视频编解码(二) – MediaCodec 解码(同步和异步)
前面学习了 MediaCodec 的基本原理,以及如何解码,在学习MediaCodec 编码之前,先来学习视频是如何编码的,以及最常用的 H264。
这一章偏文字理论,但非常重要,希望沉下心来慢慢看。
说到视频,第一印象就是占内存,我们知道视频是由一连串图像组成的,假设我们现在有一个视频,1080p(1920x1080) ,帧率是25帧,时长是2个小时,如果不进行压缩的话,它的大小为 1920x1080x25x2x60x60x1.5≈260.7G 。如果我们不对视频进行压缩的话,任何存储设备都存储不了几部电影,更别说在线电影了,带宽根本撑不住。
前面说到,视频是一帧帧的图像,因此编码也是对图像的编码,而图像一般是 RGB,即红蓝绿三个分量来组合成所有颜色。但是 RGB 对编码不太友好,因此通常会使用 YUV 的图像格式来进行编码,Y 表示亮度,UV表示色彩空间。人眼对亮度信息敏感,对色度信息稍弱,因此我们对图像进行不同的编码。具体YUV与RGB的信息,可以查看Android OpenGL ES 学习(十一) –渲染YUV视频以及视频抖音特效
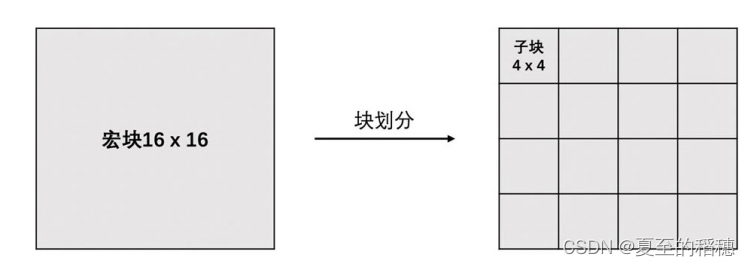
对于每一帧图像,又可以划分成一个个块来编码,不同编码类型对块的解释不通,但基本相同,如 H264 中图像块被叫做宏块,宏块的大小一般为 16x16(H264),32x32(H265,VP9)等。
图像一般具备数据冗余的,因此我们可以根据此特性去做一些操作,减少图像的数据量,比如 Bitmap 压缩,我们可以修改它的缩放因此,适配空间大小,达到压缩空间省内存的效果,视频同样如此,去除冗余的方式有:
视频编码就是通过上述4中冗余来达到视频压缩的目的。更多视频压缩信息,可以参考极客学院-视频怎么编码的
而 H264 就是针对以上冗余信息进行算法编程,达到视频压缩的。
视频编码标准其实有很多,而大名鼎鼎的就是 H264 了,可以说是最常用,最普遍的视频编码格式。其实除了H264,还有H265,H264和H265都是国际标准化组织(ISO)和国际电信联盟(ITU)开发的编码标准,而VP8、VP9 和 AV1是谷歌开发的编码标准,H264 和 H265 是需要专利费的,所以VP8、VP9 和 AV1(都是免费)也是谷歌为了对抗他们高昂专利费而开发出来的。
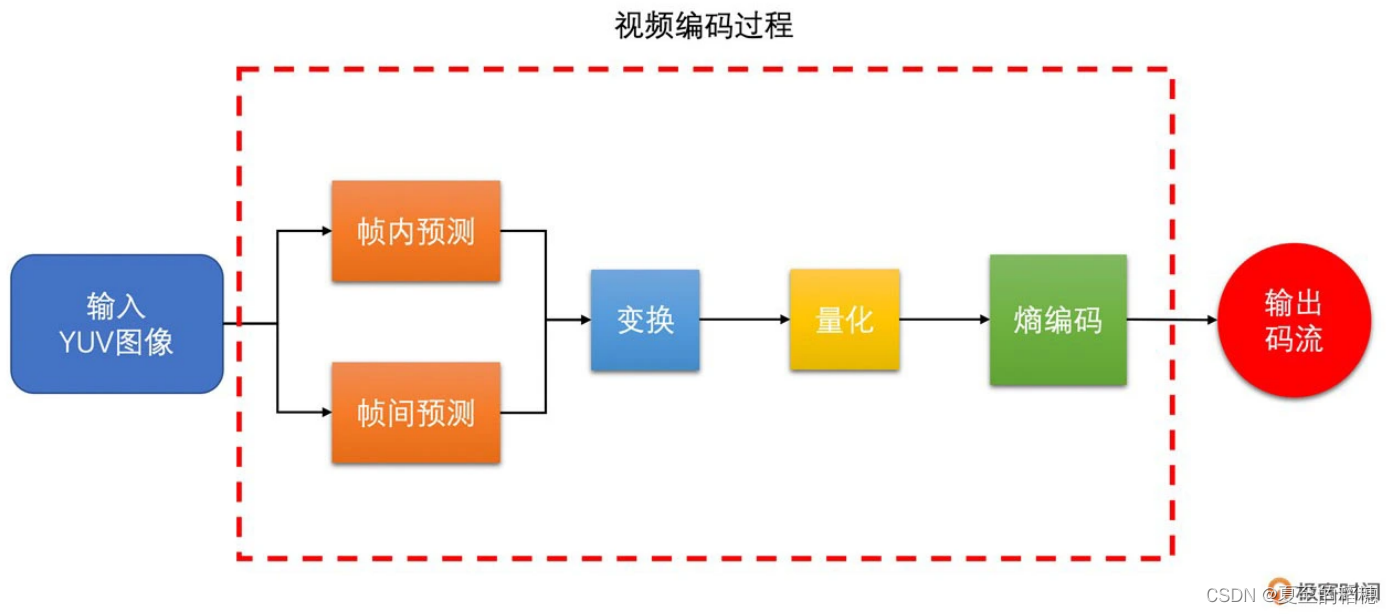
上面讲到了视频编码的原理,这里我们通过H264来了解视频编码中的码流结构,以及H264 是如何解决4中冗余信息的。它的主要步骤为:
前面说到,帧内预测是为了解决空间冗余问题,我们知道,一幅图像中相邻像素的亮度和色度信息是比较接近的,并且亮度和色度信息也是逐渐变化的,不太会出现突变。也就是说,图像具有空间相关性,帧内预测就是按照这个特点来进行的。
比如这张蓝色,它相邻的像素的亮度和色彩就是相似。

所以帧内预测就是利用已经编码后的相邻像素的值,来预测待编码的像素值,从而达到减少空间冗余的目的。
你可能会奇怪,已经编码过的像素,不是变成码流了吗,怎么还能去预测待编码的像素的。其实这个已经编码的像素是会重建成重建像素,用做之后待编码快的参考像素的。
不同块大小的帧内预测模式
这里不打算深入讲,因为要深入讲的话,得重新开一章才行,这里我们简单了解一下即可。
前面说到,视频编码是以块为单位的。在H264的标准里面,块可以分为宏块和子块,宏块的大小是 16x16 (YUV 4:2:0 ,Y 为16x16,UV 为 8x8),在帧内预测中,图像除了相似的地方,还有更细节的部分,如蓝色天空的一朵云,因此,Y 宏块还可以分成16个 4x4 的子块
Y 与 UV 的预测是分开进行的,因此,我们可以总结三个点:
所以,我们在实际帧内预测的时候就会分为:4 x 4 Y块的预测、16 x 16 Y块的预
测、8 x 8 UV块的预测.
实际上,4x4的字块中,帧内预测的模式最多,共有8个,其中有8个方向模式和一种DC模式,且方向模式指的是预测是有方向角度的。这里涉及到具体的编码算法,就不展开,若感兴趣,可参考极客学院-帧内预测
这里也不深入,主要连接P帧,B 帧的概念即可
前面说到,时间冗余是指相邻两帧画面相似的地方比较多,前后两帧图像变化很小,比如帧率30,1秒内有30张图像,如果是连续变化,两帧的图像其实变化往往很小,这就是相关性,帧间预测,就是利用这个特点来进行算法编码的。即:
通过在已经编码的帧里面找到一个块来预测等待编码块的像素,从而达到减少时间冗余的目的。
注意这里和帧内预测的区别:
这里以 H264 的标准来讲讲 P 帧的帧间预测过程,当然也是了解个大概,更详细的,参考极客学院 - 帧间预测
其实阵间预测也是通过块作为参考的,我们会在已经编码的帧里面找到一个块来作为预测块,这个已经编码的帧称之为参考帧。
那问题来了,前面说到帧间预测是图像与图像之间的参考,如果两张图像一模一样,还好理解一点,如果是有变化的呢?比如下面这张图:
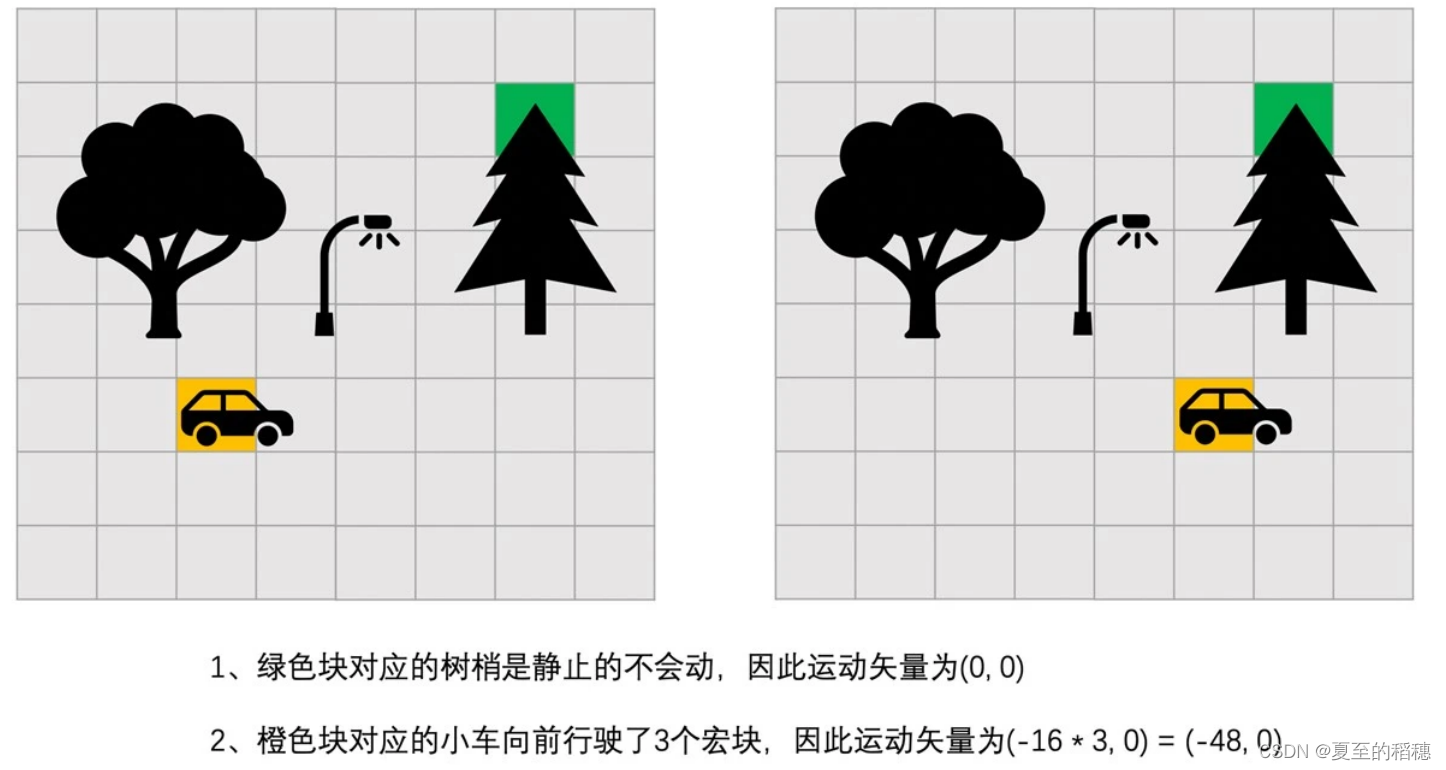
可以看到,树木是不变的,但是汽车移动了,这里是怎么计算的?
从编码的角度来看,汽车是不变的,变的是运动轨迹,因此,为了表示这种变化,可以使用运动矢量来表示编码帧中编码块和参考帧中,预测块之间的位置的差值。
比如说上面两幅图像中,小车从前一幅图像中的(32,80)的坐标位置,变化到当前图像
(80,80)的位置,向前行驶了 48 个像素。很明显,如果我们选用(32,80)这个块作
为当前(80,80)这个编码块的预测块的话,是不是就可以得到全为 0 像素的残差块了?
这是因为小车本身是没有变化的,变化的只是小车的位置。
而这里的难点,在于如何找到这个最佳的参考帧,这里就涉及到运动算法。你可能会箱单,既然都分成块了,那逐行对比即可,即全局搜索,好处就是啥都能对比到,但是缺点就是一帧算下来,耗时过长,因此还需要更快速的算法。这里就不细讲,参考极客学院 - 帧间预测
通过前面的知识,已经知道 ,通过帧内编码可以去除空间冗余,通过帧间编码可以去除时间冗余,而为了分离图像块的高频和低频信息从而去除视觉冗余,我们需要做 DCT 变换和量化。
其实DCT 变换,就是离散余弦变化,它可以将你扛到的图像转到成数据,并能很好的去除相关性。
经过 DCT 变化之后,低频信息会集中出现在左上角,高频信息则分散到其他地方,而人又对高频信息不敏感,因此图像在经过 DCT 变化后,再去除一些高频信息,就可以达到压缩的目的。
而高频信息幅度值比较小,因此还可以使用量化的方式,即除法操作,将高频信息幅度变小,达到压缩的目的。
更多细节,参考极客学院-变化量化
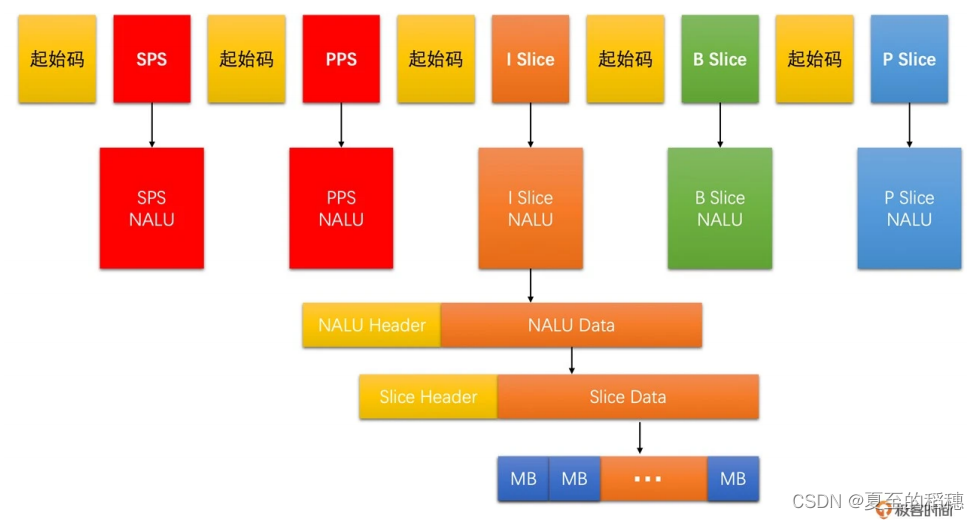
前面学习了视频编码的原理,现在来看H264,估计会简单很多。先来看看结构:
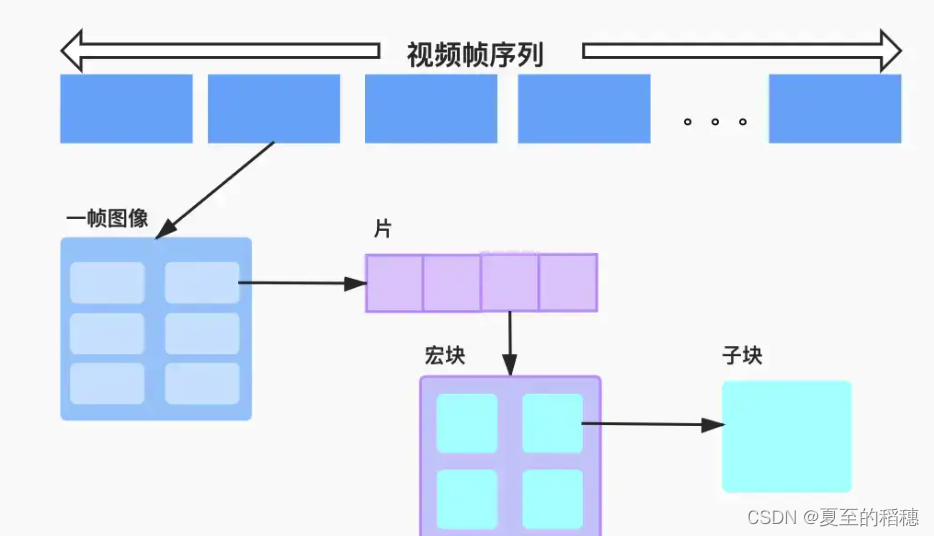
在上面的结构中,一个视频编码后的数据叫做帧,一帧由1个片 (slice)或多个片组成,一个片 又可以分成多个宏块 (MB),一个宏块又可以由多个子块组成。而宏块是H264的基本单位,前面也说到,编码基本是基于块去做参考的。
可能平时你也接触过,H264的帧类型,可以分为 I帧,P帧,和B帧。前面的视频编码原理讲到,为了减少空间冗余和时间冗余,有涉及到帧内预测和帧间预测。
再回顾一下,帧内预测,是参考自身的宏块,帧间预测是不同帧之间的参考,即:
因此,我们可以得出两者之间的关系:
| 帧类型 | 预测方式 | 参考帧 | 优点 | 缺点 | |
|---|---|---|---|---|---|
| I帧 | 帧内编码帧 | 只帧内预测 | 无 | 能独立编码 | 压缩率小 |
| P帧 | 前向编码帧 | 可以进行帧内预测和帧内预测 | 参考前面的I帧或P帧 | 压缩率比I帧高 | 必需参考正确的帧才能正确解码 |
| B帧 | 双向编码帧 | 可以进行帧内预测和帧内预测 | 参考前面或者后面已经编码的I帧或者P帧 | 压缩率最高 | 需要缓存帧,参考后面的帧,延时高 |
可以看到,如果编解码中,如果前面一个帧出现了错误,那么P帧和B帧肯定也会出现错误,虽然B帧也可以参考后面的帧,但一般很少用到B帧,比如只有P帧,错误就会一直传递,为了避免这种情况,就有一种特殊的I帧,叫 IDR 帧,也叫立即刷新帧。
在H264的标砖中,IDR 后的帧不再参考前面的帧,这样如果一帧编码错误后,如果此时有IDR帧过来,后面的帧就只会参考这个IDR帧,就截断了错误,后面就可以正常编解码了。
所以,一般都会使用 IDR帧,而不是普通I帧。
从一个 IDR 帧开始到下一个 IDR 帧的前一帧为止,这里面包含的 IDR 帧、普通 I 帧、P 帧和 B 帧,我们称为一个 GOP(图像组)。

所以,一个GOP的大小,是由IDR的间隔决定的,这个间隔,也叫做 关键帧间隔,关键帧越大,则IDR相关越远,GOP越大,反之亦然。
当然GOP不是越大越好,也不是越小越好,比如直播场景,由于网络等因素,你可能GOP小一些比较好,而局域网投屏,网络基本稳定,所以GOP可以设置大一些。
前面也说到一帧图像可以划分成一个或多个 Slice,而一个 Slice 包含多个宏块,且一个宏块又可以划分成多个不同尺寸的子块。这里我们一层层去剥开它。
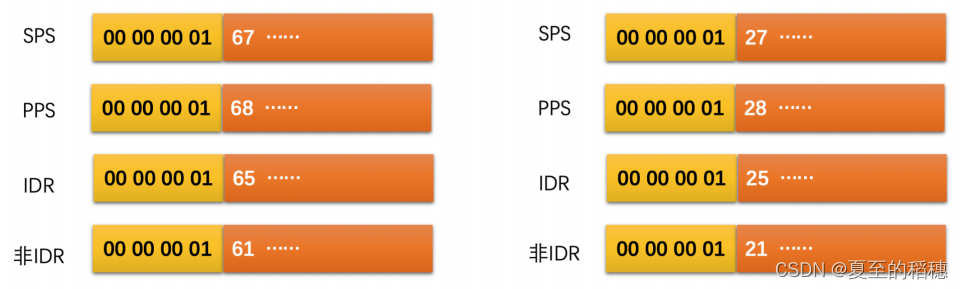
H264 有两种格式,一种是Annexb,另一种是MP4,相同是他们都有起始码,而它们的不同是:
因此,我们在解析H264文件时,要注意头部信息的起始码。
在H264码流中,有两个很重要的信息,即sps和pps:
如果一段码流中,缺失了这两个部分,之后的I帧,P帧,B帧都无办法解码。
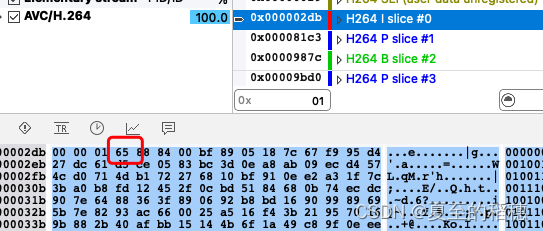
现在我们知道了,H264 的码流中, SPS、PPS、I 帧、P帧和 B 帧。由于帧又可以划分成一个或多个 Slice。因此,帧在码流中实际上是以 Slice 的形式呈现的。
所以,H264 的码流主要是由 SPS、PPS、I Slice、P Slice和B Slice 组成
的。如下图所示:

那如何在码流中区分这些数据呢?
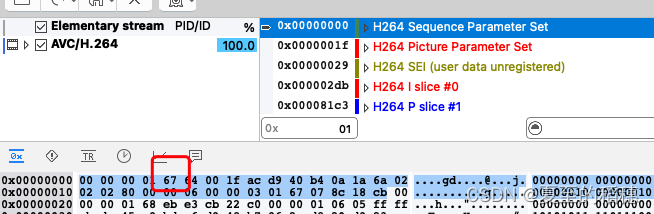
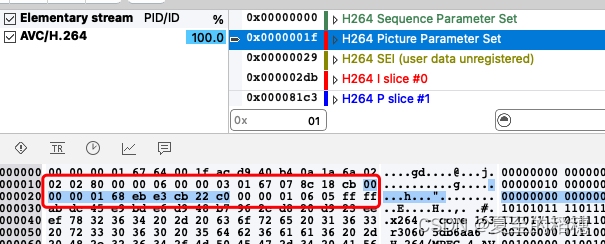
为了解决这个问题,H264设计了NALU (网络抽象层单元),sps 是一个 NALU,pps也是一个 NALU单元,每一个片(Slice) 也是一个 NALU 。
它的结构组成是:


我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
我正在尝试在Ruby中复制Convert.ToBase64String()行为。这是我的C#代码:varsha1=newSHA1CryptoServiceProvider();varpasswordBytes=Encoding.UTF8.GetBytes("password");varpasswordHash=sha1.ComputeHash(passwordBytes);returnConvert.ToBase64String(passwordHash);//returns"W6ph5Mm5Pz8GgiULbPgzG37mj9g="当我在Ruby中尝试同样的事情时,我得到了相同sha
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
最近因为项目需要,需要将Android手机系统自带的某个系统软件反编译并更改里面某个资源,并重新打包,签名生成新的自定义的apk,下面我来介绍一下我的实现过程。APK修改,分为以下几步:反编译解包,修改,重打包,修改签名等步骤。安卓apk修改准备工作1.系统配置好JavaJDK环境变量2.需要root权限的手机(针对系统自带apk,其他软件免root)3.Auto-Sign签名工具4.apktool工具安卓apk修改开始反编译本文拿Android系统里面的Settings.apk做demo,具体如何将apk获取出来在此就不过多介绍了,直接进入主题:按键win+R输入cmd,打开命令窗口,并将路
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
查看Ruby代码,它具有以下proc_arity:staticVALUEproc_arity(VALUEself){intarity=rb_proc_arity(self);returnINT2FIX(arity);}更多的是C编码风格问题,但为什么staticVALUE在单独的一行而不是像这样的:staticVALUEproc_arity(VALUEself) 最佳答案 它来自UNIX世界,因为它有助于轻松grep函数的定义:$grep-n'^proc_arity'*.c或使用vim:/^proc_arity
我创建了一个由于“在运行时执行的单例元类定义”而无法编码的对象(这段代码的描述是否正确?)。这是通过以下代码执行的:#defineclassXthatmyusesingletonclassmetaprogrammingfeatures#throughcallofmethod:break_marshalling!classXdefbreak_marshalling!meta_class=class我该怎么做才能使对象编码正确?是否可以从对象instance_of_x的classX中“移除”单例组件?我真的需要一个建议,因为我们的一些对象需要通过Marshal.dump序列化机制进行缓存。