Wenet框架基于PyTorch实现,因此wenet多机多卡训练依赖于PyTorch分布式训练的实现。
下面代码展示了如何基于PyTorch进行分布式训练:
def ddp_demo(rank, world_size, accum_grad=4):
assert dist.is_gloo_available(), "Gloo is not available!"
print(f"world_size: {world_size}, rank: {rank}, is_gloo_available: {dist.is_gloo_available()}")
# 1. 初始化进程组
dist.init_process_group("gloo", world_size=world_size, rank=rank)
model = nn.Sequential(nn.Linear(10, 100), nn.ReLU(), nn.Linear(100, 20))
# 2. 模型转化成ddp模型
ddp_model = DistributedDataParallel(model)
criterion = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=1e-3)
dataset = TensorDataset(torch.randn(1000, 10))
# 3. 数据分布式并行(内部会根据rank采样)
sampler = DistributedSampler(dataset=dataset, num_replicas=world_size, shuffle=True)
dataloader = DataLoader(dataset=dataset, batch_size=24, sampler=sampler, collate_fn=transform)
for epoch in range(1):
for step, batch in enumerate(dataloader):
output = ddp_model(batch)
label = torch.rand_like(output)
if step % accum_grad == 0:
# 同步参数
context = contextlib.nullcontext
else:
# 4. 梯度累计,不同步参数
context = ddp_model.no_sync
with context():
time.sleep(random.random())
loss = criterion(output, label)
loss.backward()
if step % accum_grad == 0:
optimizer.step()
optimizer.zero_grad()
print(f"epoch: {epoch}, step: {step}, rank: {rank} update parameters.")
# 5. 销毁进程组上下文数据(一些全局变量)
dist.destroy_process_group()
本地环境没有Nvidia显卡,用
gloo后端替代nccl。
源代码参考:https://gist.github.com/hotbaby/15950bbb43d052cd835b0f18c997f67c
模型转换成分布式训练的步骤:
dist.init_process_group;DistributedDataParallel(model);world_size 份,根据rank采样DistributedSampler(dataset=dataset, num_replicas=world_size, shuffle=True);dist.destroy_process_group()。GPU机器列表:
| 节点名称 | IP地址 | GPU数量 |
|---|---|---|
| node1 | 10.10.23.9 | 8 |
| node2 | 10.10.23.10 | 8 |
以aishell数据集为例,说明Wenet框架中文ASR模型在GPU机器上的训练过程:
环境初始化和数据准备
环境初始化参考Wenet官方文档:https://github.com/wenet-e2e/wenet#installationtraining-and-developing
将aishell数据集解压后,分别拷贝node1和node2两台机器的/data/aishell/目录。
配置训练脚本配置
node1训练脚本配置:
wenet/examples/aishell/s0/run.sh
export CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7"
data=/data/aishell/
num_nodes=2
node_rank=0
init_method="tcp://${node1_ip}:23456"
dist_backend="nccl"
node2训练脚本配置:
wenet/examples/aishell/s0/run.sh
export CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7"
num_nodes=2
node_rank=1
init_method="tcp://${node1_ip}:23456"
dist_backend="nccl"
运行训练脚本
分别在node1和node2上后台运行run.sh训练脚本。
# export NCCL_SOCKET_IFNAME=ens1f0
nohup bash run.sh > train.log 2>&1 &
ens1f0为网卡接口名字,如果没有配置,可能会导致多机网络通信问题。
| GPU配置 | 每个Epoch的训练时间(秒) | 速度提升 |
|---|---|---|
| 单机多卡(4) | 407.17 | |
| 单机多卡(8) | 204.36 | 相比单机多卡(4)提升99.24% |
| 多机多卡(8) | 221.75 | 相比单机多卡(8)慢了7.84% |
| 多机多卡(16) | 121.7 | 相比单机多卡(8)提升了67.92% |
与上述DDP Demo类似,Wenet调用PyTorch相关接口实现分布式训练。
wenet/bin/train.py
def main():
...
if distributed:
logging.info('training on multiple gpus, this gpu {}'.format(args.gpu))
dist.init_process_group(args.dist_backend,
init_method=args.init_method,
world_size=args.world_size,
rank=args.rank)
...
Wenet源代码链接:https://github.com/wenet-e2e/wenet/blob/main/wenet/bin/train.py#L141
def main():
...
if distributed:
assert (torch.cuda.is_available())
# cuda model is required for nn.parallel.DistributedDataParallel
model.cuda()
model = torch.nn.parallel.DistributedDataParallel(
model, find_unused_parameters=True)
...
Wenet源代码链接:https://github.com/wenet-e2e/wenet/blob/main/wenet/bin/train.py#L232
wenet/dataset/dataset.py
class DistributedSampler:
...
def sample(self, data):
""" Sample data according to rank/world_size/num_workers
Args:
data(List): input data list
Returns:
List: data list after sample
"""
data = list(range(len(data)))
# TODO(Binbin Zhang): fix this
# We can not handle uneven data for CV on DDP, so we don't
# sample data by rank, that means every GPU gets the same
# and all the CV data
if self.partition:
if self.shuffle:
random.Random(self.epoch).shuffle(data)
data = data[self.rank::self.world_size]
# num_workers参数与world_size相等,按world_size进行切片。
data = data[self.worker_id::self.num_workers]
return data
...
Wenet源代码链接:https://github.com/wenet-e2e/wenet/blob/main/wenet/dataset/dataset.py#L79
wenet/utils/executor.py
class Executor:
def train(...):
with model_context():
for batch_idx, batch in enumerate(data_loader):
if is_distributed and batch_idx % accum_grad != 0:
# 梯度累计,不同步参数
context = model.no_sync
# Used for single gpu training and DDP gradient synchronization
# processes.
else:
# 同步参数
context = nullcontext
with context():
# autocast context
# The more details about amp can be found in
# https://pytorch.org/docs/stable/notes/amp_examples.html
with torch.cuda.amp.autocast(scaler is not None):
loss_dict = model(feats, feats_lengths, target,
target_lengths)
loss = loss_dict['loss'] / accum_grad
if use_amp:
scaler.scale(loss).backward()
else:
loss.backward()
Wenet源代码链接:https://github.com/wenet-e2e/wenet/blob/main/wenet/utils/executor.py#L67
destroy_process_group()方法,因为训练进程退出后,process_group相关全局变量和上下文会自然销毁,所以不会影响训练过程。多机多卡(16卡)相关对于单机多卡(4卡)开发集loss收敛速度变慢?
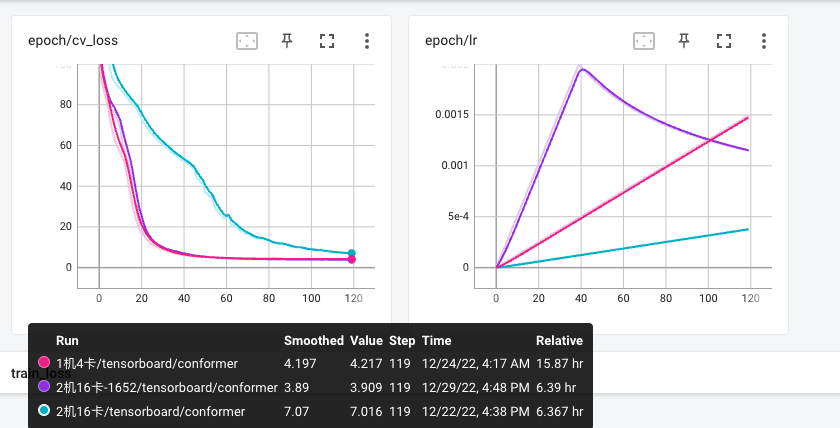
调整wenet/examples/aishell/s0/conf/train_conformer.yaml的warmup_steps参数可以解决此问题。
optim_conf:
lr: 0.002
scheduler: warmuplr # pytorch v1.1.0+ required
scheduler_conf:
warmup_steps: 1562
如何调整梯度累计的间隔?
调整wenet/examples/aishell/s0/conf/train_conformer.yaml的accum_grad参数。
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我有一个多机vagrant设置,其中包含一些我需要更改执行顺序的block。由于vagrant顺序是从外到内,最嵌套的block最后执行。我需要一种方法来使供应block更加嵌套,以便它们最后执行。我尝试添加mach.vm.define但这些block没有执行,我不明白为什么。正常执行,顺序错误Vagrant.require_version">=1.6.0"VAGRANTFILE_API_VERSION="2"require'yaml'machines=YAML.load_file('vagrant.yaml')Vagrant.configure(VAGRANTFILE_API_VER
在神经网络方面,我完全是个初学者。我整天都在与ruby-fann和ai4r搏斗,不幸的是我没有任何东西可以展示,所以我想我会来到StackOverflow并询问这里的知识渊博的人。我有一组样本——每天都有一个数据点,但它们不符合我能够找出的任何明确模式(我尝试了几次回归)。不过,我认为看看是否有任何方法可以仅从日期预测future的数据会很好,而且我认为神经网络将是生成希望表达这种关系的函数的好方法.日期是DateTime对象,数据点是十进制数,例如7.68。我一直在将DateTime对象转换为float,然后除以10,000,000,000得到一个介于0和1之间的数字,我一直在将
我有一个启动DRb服务的脚本,然后生成处理程序对象并通过DRb.thread.join等待。我希望脚本一直运行直到被明确杀死,所以我添加了trap"INT"doDRb.stop_serviceend在Ruby1.8下成功停止DRb服务并退出,但在1.9下似乎死锁(在OSX10.6.7上)。对该进程进行采样显示在semaphore_wait_signal_trap中有几个线程在旋转。我假设我在调用stop_service时做错了什么,但我不确定是什么。谁能给我任何关于如何正确处理它的指示? 最佳答案 好的,我想我已经找到了解决方案。如
我正在尝试训练一个前馈网络来使用Ruby库AI4R执行异或运算。然而,当我在训练后评估XOR时。我没有得到正确的输出。有没有人以前使用过这个库并得到它来学习异或运算。我使用了两个输入神经元,一个隐藏层中的三个神经元,一个输出层,正如我看到的预计算XOR前馈神经网络就像这样。require"rubygems"require"ai4r"#Createthenetworkwith:#2inputs#1hiddenlayerwith3neurons#1outputsnet=Ai4r::NeuralNetwork::Backpropagation.new([2,3,1])example=[[0,
功能需求:主机使用一个串口,与两个从机进行双向通信,主机向从机发送数据,从机能够返回数据,由于结构限制,主机与从机之间只有3根线(电源、地、数据线),并且从机上没有设物理的电源开关,需要通过与主机连接的数据线来控制开机,总结如下:1、数据线只有1根2、能够双向通信3、主机能够控制从机开机4、主机可以单独向1个从机发数据,也可以同时向两个从机发送数据根据需求,设计出如下电路:工作原理分析:VCC_24V_IN、GND、LINE_L(LINE_R)三根线接线连接到从机,电源开启电路是从机内部的电源控制。开机的逻辑:*主机先上电,LINE_L因为主机的R1上拉而有高电平,使Q6导通,Q5的G极电压被
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
1.深度优先搜索(DFS)深度优先遍历主要思路是从图中一个未访问的顶点V开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成。例题P1605迷宫题目描述给定一个N×MN\timesMN×M方格的迷宫,迷宫里有TTT处障碍,障碍处不可通过。在迷宫中移动有上下左右四种方式,每次只能移动一个方格。数据保证起点上没有障碍。给定起点坐标和终点坐标,每个方格最多经过一次,问有多少种从起点坐标到终点坐标的方案。输入格式第一行为三个正整数N,M,TN,M,TN,M,T,分别表示迷宫的长宽和障碍总数。第二行为四个正整数SX,S
BigData/CloudComputing:基于阿里云技术产品的人工智能与大数据/云计算/分布式引擎的综合应用案例目录来理解技术交互流程目录一、云计算网站建设:部署与发布网站建设:简单动态网站搭建云服务器管理维护云数据库管理与数据迁移云存储:对象存储管理与安全超大流量网站的负载均衡二、大数据MOOC网站日志分析搭建企业级数据分析平台基于LBS的热点店铺搜索基于机器学习PAI实现精细化营销基于机器学习的客户流失预警分析使用DataV制作实时销售数据可视化大屏使用MaxCompute进行数据质量核查使用Quick BI制作图形化报表使用时间序列分解模型预测商品销量三、云安全云平台使用安全云上服务
我不太确定如何表达这一点,所以我只是举个例子。如果我写:some_method(["a","b"],3)我希望它返回某种形式的[{"a"=>0,"b"=>3},{"a"=>1,"b"=>2},{"a"=>2,"b"=>1},{"a"=>3,"b"=>0}]如果我传入some_method(%w(abc),2)期望的返回值应该是[{"a"=>2,"b"=>0,"c"=>0},{"a"=>1,"b"=>1,"c"=>0},{"a"=>1,"b"=>0,"c"=>1},{"a"=>0,"b"=>2,"c"=>0},{"a"=>0,"b"=>1,"c"=>1},{"a"=>0,"b"=>0,"