
表单 gearbox00 为齿轮箱正常工况下采集到的振动信号;表单 gearbox10 为故障状态 1 下采集到的振动信号;表单 gearbox20 为故障状态 2 下采集到的故障信号;表单 gearbox30 为故障 状态 3 下采集到的故障信号;表单 gearbox40 为故障状态 4 下采集到的振动信号。
1、对齿轮箱各个状态下的振动数据进行分析,研究正常和不同故障状态下 振动数据的变化规律及差异,并给出刻画这些差异的关键特征。
这题每个状态有四个指标,即对每个状态的各指标首先做图观察,看看每个状态下的数据变化趋势,明天我简单做做给出部分图和代码,不过用spss或者Excel也是一样可以的。
至于差异的关键特征,对数据进行特征分析即可。代码也简单,主要就是看写论文吧。
2、建立齿轮箱的故障检测模型,对其是否处于故障状态进行检测,并对模型的性能进行评价。
根据第一问提取的数据特征通过计算故障强度系数再进行后续计算,见下文
《普通公路隧道机电设施故障检测方法研究》
用小波分析法检测故障,见下文
《基于向量自回归模型和小波分析法的列车 充电机电流传感器故障检测方法》
3、建立齿轮箱的故障诊断模型,对其处于何种故障状态进行判断,并对模型的性能进行评价。
根据前一问的结果先检测哪些是故障,后用一种基于树形卷积神经网络模型诊断是哪种故障。见下文
《铁路信号联锁故障诊断模型构建及仿真》
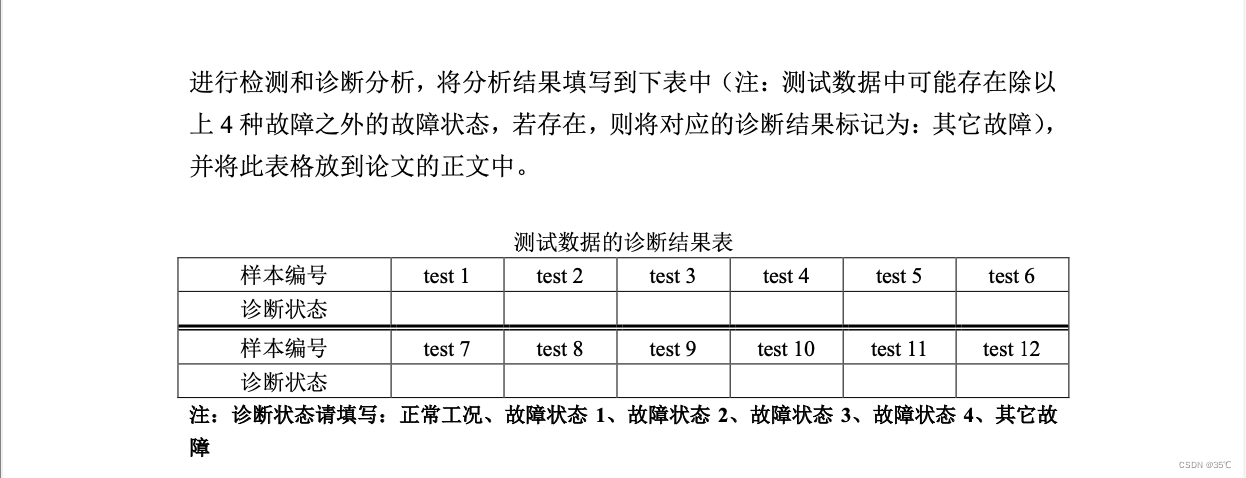
4、结合所建立的故障检测和诊断模型对附件 2 中另行采集的 12 组测试数据进行检测和诊断分析,将分析结果填写到下表中(注:测试数据中可能存在除以 上 4 种故障之外的故障状态,若存在,则将对应的诊断结果标记为:其它故障), 并将此表格放到论文的正文中
第四问直接运用前两问的模型即可。
明天继续更新,今天时间有点仓促,只能大概提供这一点点。明天我会进行修改和补充,大家有问题评论或私信即可,明天我的课还是比较多的。所以应该周末才会给出详细的思路和部分代码。
一样的,对于数据题我们首先要做的是数据预处理,接下来再进行下面的操作。
关于问题一:
可以做每组数据的散点图,我这个就给出一张例图。Excel和SPSS都可以做的,SPSS做的估计会更好看一点。Excel好好调参也可以很好看。
做这种图的,第一自己观察看看有没有什么显著差异,第二写论文。这个也算是震动信号数据的一种分析,论文写写就行。
后面的计算有比较多的方法
1、通过计算方差,筛选特征。计算方法参考下文
数据筛选特征方法-方差法_gao_vip的博客-CSDN博客_方差选择法 特征筛选
2、计算特征重要性,取重要性高的那类作为特征。
3、SVD(奇异值分解),这个方法比较好的。大家可以去看看下面这个论文,这一问能搞定。
《SVD曲率谱降噪和快速谱峭度的滚动轴承微弱故障特征提取》
常用数据特征提取,时域特征、频域特征、小波特征提取汇总;特征提取;有效matlab代码_入间同学的博客-CSDN博客_小波熵特征提取
4、小波分析特征提取
%装入变换放大器输入输出数据
%bf_150ms.dat为正常系统输出信号
%bf_160ms.dat为故障系统输出信号
load bf_150ms.dat;
load bf_160ms.dat;
s1=bf_150ms(1:1000);%s1为正常信号
s2=bf_160ms(1:1000);%s2为故障信号
%画出正常信号与故障信号的原始波形
tittle(“原始信号’);
Ylabel('s1');
subplot(922); plot(s2);
title('故障信号');
Ylabel('s2');
%============================================
%用dbl小波包对正常信号s1进行三层分解
[t,d]=wpdec(sl,3,'db','shannon');
%plontree(t)%画小波包树结构的图形
%下面对正常信号第三层各系数进行重构
%s130是指信号sl的[3,0]结点的重构系数;其他依次类推
sl30=wprcoef(t,d,[3,0]);
s13l=wprcoef(t,d,[3,1]);
s132=wprcoef(t,d,[3,2]);
sl33=wprcoef(t,d,[3,3]);
sl34=wprcoef(t,d,[3,4]);
s135=wprcoef(t,d,[3,5]);
s136=wprcoef(t,d,[3,6]);
s137=wprcoef(t,d,[3,7]);
%画出至构系数的波形
subplot(9,2,3); plot(s130);
Ylabel('S130');
subpolt(9,2,5); plot(s131);
Ylabel('S13l');
subplot(9,2,7); plot(s132);
Ylabel('S132');
subplot(9,2,9); plot(s133);
Ylabel('S133');
subplot(9,2,11);plot(s134);
Ylabel('S134');
subplot(9,2,13);plot(s135);
Ylabel('S135');
subplot(9,2,15);plot(s136);
Ylabel('S136');
subplot(9,2,17);plot(s137);
Ylabel('S137');
%--------------------------------------
%计算正常信号各重构系数的方差
%s10是指s130的方差,其他依此类推
s10=norm(sl30);
sll=norm(s131);
s12=norm(sl32);
s13=norm(sl33);
sl4=norm(s134);
s15=norm(s135);
s16=norm(sl36);
s17=norm(sl37);
%向量ssl是针对信号s1构造的向量
disp=('正常信号的输出向量')
ssl=[sl0,s11,sl2,sl3,s14,s15,sl6,s17]
%===========================
%用db1小波包对故障信号s2进行三层分解
[t,d]=wpdec(s2,3,'db1','shannon');
%plottree(t)%画小波包树结构的图形
%s230是指信号S2的[3,0]结点的重构系数,其他以此类推
s230=wprcoef(t,d,[3,0]);
s231=wprcoef(t,d,[3,1]);
s232=wprcoef(t,d,[3,2]);
s233=wprcoef(t,d,[3,3]);
s234=wprcoef(t,d,[3,4]);
s235=wprcoef(t,d,[3,5]);
s236=wprcoef(t,d,[3,6]);
s237=wprcoef(t,d,[3,7]);
%画出重构系数的波形
subplot(9,2,4);plot(s230);
Ylabel('S230');
subplot(9,2,6);plot(s231);
Ylabel('S231');
subplot(9,2,8);plot(s232);
Ylabel('S232');
subplot(9,2,10);plot(s233);
Ylabel('S233');
subplot(9,2,12);plot(s234);
Ylabel('S234');
subplot(9,2,14);plot(s235);
Ylabel('S235');
subplot(9,2,16);plot(s236);
Ylabel('S236');
subplot(9,2,18);plot(s237);
Ylabel('S237');
%----------------------------------------------------------
%计算故障信号各重构系数的方差
%s20是指s230的方差,其他依次类推
s20=norm(s230);
s21=norm(s231);
s22=norm(s232);
s23=norm(s233);
s24=norm(s234);
s25=norm(s235);
s26=norm(s236);
s27=norm(s237);
%向量ss2是针对信号S1构造的向量
disp('故障信号')来源于:轴承故障诊断小波分析.7z_小波轴承故障-专业指导其他资源-CSDN下载
这问的方法实在太多了,代码也有很全的,重点就是写论文上。
关于问题二:
1、PCA故障检测
clc;clear;
%% 1.导入数据
%产生训练数据
num_sample=100;
a=10*randn(num_sample,1);
x1=a+randn(num_sample,1);
x2=1*sin(a)+randn(num_sample,1);
x3=5*cos(5*a)+randn(num_sample,1);
x4=0.8*x2+0.1*x3+randn(num_sample,1);
xx_train=[x1,x2,x3,x4];
% 产生测试数据
a=10*randn(num_sample,1);
x1=a+randn(num_sample,1);
x2=1*sin(a)+randn(num_sample,1);
x3=5*cos(5*a)+randn(num_sample,1);
x4=0.8*x2+0.1*x3+randn(num_sample,1);
xx_test=[x1,x2,x3,x4];
xx_test(51:100,2)=xx_test(51:100,2)+15*ones(50,1);
%% 2.数据处理
Xtrain=xx_train;
Xtest=xx_test;
X_mean=mean(Xtrain);
X_std=std(Xtrain);
[X_row, X_col]=size(Xtrain);
Xtrain=(Xtrain-repmat(X_mean,X_row,1))./repmat(X_std,X_row,1); %标准化处理
%% 3.PCA降维
SXtrain = cov(Xtrain);%求协方差矩阵
[T,lm]=eig(SXtrain);%求特征值及特征向量,特征值排列顺序为从小到大
D=flipud(diag(lm));%将特征值从大到小排列
% 确定降维后的数量
num=1;
while sum(D(1:num))/sum(D)<0.85
num = num+1;
end
P = T(:,X_col-num+1:X_col); %取对应的向量
P_=fliplr(P); %特征向量由大到小排列
%% 4.计算T2和Q的限值
%求置信度为99%时的T2统计控制限,T=k*(n^2-1)/n(n-k)*F(k,n-k)
%其中k对应num,n对应X_row
T2UCL1=num*(X_row-1)*(X_row+1)*finv(0.99,num,X_row - num)/(X_row*(X_row - num));%求置信度为99%时的T2统计控制限
%求置信度为99%的Q统计控制限
for i = 1:3
th(i) = sum((D(num+1:X_col)).^i);
end
h0 = 1 - 2*th(1)*th(3)/(3*th(2)^2);
ca = norminv(0.99,0,1);
QU = th(1)*(h0*ca*sqrt(2*th(2))/th(1) + 1 + th(2)*h0*(h0 - 1)/th(1)^2)^(1/h0); %置信度为99%的Q统计控制限
%% 5.模型测试
n = size(Xtest,1);
Xtest=(Xtest-repmat(X_mean,n,1))./repmat(X_std,n,1);%标准化处理
%求T2统计量,Q统计量
[r,y] = size(P*P');
I = eye(r,y);
T2 = zeros(n,1);
Q = zeros(n,1);
lm_=fliplr(flipud(lm));
%T2的计算公式Xtest.T*P_*inv(S)*P_*Xtest
for i = 1:n
T2(i)=Xtest(i,:)*P_*inv(lm_(1:num,1:num))*P_'*Xtest(i,:)';
Q(i) = Xtest(i,:)*(I - P*P')*Xtest(i,:)';
end
%% 6.绘制T2和SPE图
figure('Name','PCA');
subplot(2,1,1);
plot(1:i,T2(1:i),'k');
hold on;
plot(i:n,T2(i:n),'k');
title('统计量变化图');
xlabel('采样数');
ylabel('T2');
hold on;
line([0,n],[T2UCL1,T2UCL1],'LineStyle','--','Color','r');
subplot(2,1,2);
plot(1:i,Q(1:i),'k');
hold on;
plot(i:n,Q(i:n),'k');
title('统计量变化图');
xlabel('采样数');
ylabel('SPE');
hold on;
line([0,n],[QU,QU],'LineStyle','--','Color','r');
%% 7.绘制贡献图
%7.1.确定造成失控状态的得分
S = Xtest(51,:)*P(:,1:num);
r = [ ];
for i = 1:num
if S(i)^2/lm_(i) > T2UCL1/num
r = cat(2,r,i);
end
end
%7.2.计算每个变量相对于上述失控得分的贡献
cont = zeros(length(r),X_col);
for i = length(r)
for j = 1:X_col
cont(i,j) = abs(S(i)/D(i)*P(j,i)*Xtest(51,j));
end
end
%7.3.计算每个变量的总贡献
CONTJ = zeros(X_col,1);
for j = 1:X_col
CONTJ(j) = sum(cont(:,j));
end
%7.4.计算每个变量对Q的贡献
e = Xtest(51,:)*(I - P*P');%选取第60个样本来检测哪个变量出现问题。
contq = e.^2;
%5. 绘制贡献图
figure
subplot(2,1,1);
bar(contq,'g');
xlabel('变量号');
ylabel('SPE贡献率 %');
hold on;
subplot(2,1,2);
bar(CONTJ,'r');
xlabel('变量号');
ylabel('T^2贡献率 %');来源于:基于PCA的故障诊断方法(matlab)_汤宪宇的博客-CSDN博客_pca 故障诊断
不懂的转原文看,花个时间学学。
2、《普通公路隧道机电设施故障检测方法研究》中的方法
这个方法就是计算,看懂这篇论文就行。
3、小波分析
这个方法也看论文学习,找找代码。
代码需要下载使用小波进行信号中的特征检测:使用小波进行特征检测的MATLAB代码和相关文件-matlab开发_-互联网文档类资源-CSDN下载
基于小波分析的故障检测与诊断硕士论文-基于小波分析的故障检测与诊断.rar_-互联网文档类资源-CSDN下载
两篇都有,我也没下过,但看标题来说。第一个是代码,第二个是论文。
至于性能评价
无非就是那几个指标,准确率、召回率等等。
%样本标记为0和1,num为选取前n个特征的数据用于分类
%需要安装好SVM
function [sens,spec,F1,pre,rec,acc] = SEERES(train,trainclass,test,testclass,num)
acc = zeros(num,1);
sens = zeros(num,1);
spec = zeros(num,1);
F1 = zeros(num,1);
pre = zeros(num,1);
rec = zeros(num,1);
FeatureNumber = zeros(num,1);
[len,b]=size(testclass);
for n=1:num
label = trainclass;
data = train(:,1:n);
testlabel = testclass;
testdata = test(:,1:n);
model=svmtrain(label,data,'-s 0 -t 0 -b 1');%默认C-SVC类型,0 线性 2 RBF,-b会输出概率
[predictlabel,accuracy,Scores]=svmpredict(testlabel,testdata,model,'-b 1');
acc(n,1) = accuracy(1,1);
FeatureNumber(n,1) = n;
tp = 0;
fn = 0;
fp = 0;
tn = 0;
for y = 1:len
if predictlabel(y,1)==1 && testclass(y,1)==1
tp=tp+1;
elseif predictlabel(y,1)==1 && testclass(y,1)==0
fp=fp+1;
elseif predictlabel(y,1)==0 && testclass(y,1)==1
fn=fn+1;
elseif predictlabel(y,1)==0 && testclass(y,1)==0
tn=tn+1;
end
end
sens(n,1) = tp/(tp+fn);
spec(n,1) = tn/(tn+fp);
pre(n,1) = tp/(tp+fp);
rec(n,1) = sens(n,1);
F1(n,1) = 2*(pre(n,1)*rec(n,1))/(pre(n,1)+rec(n,1));
end来源于:查准率、召回率、敏感性、特异性和F1-score的计算及Matlab实现_黑山白雪m的博客-CSDN博客_召回率和敏感性
关于问题三:
1、LSTM故障诊断
基于LSTM的故障诊断_旧日之歌的博客-CSDN博客_故障检测lstm
看看上面的这个博文。
2、小波分析与神经网络
这个方法的代码在CSDN里需要下载,但是这个很成熟了,而且已经有人用这个方法做过诊断齿轮箱的故障。大家可以去看看下面这篇论文。
《基于小波降噪和BP神经网络的风力发电机组齿轮箱故障诊断研究》
就是代码比较难找,但方法应该是比较好的。
3、深度学习故障诊断算法
这个方法python厉害,擅长编程的可以考虑,用的是残差收缩网络。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Sat Dec 28 23:24:05 2019
Implemented using TensorFlow 1.0.1 and Keras 2.2.1
M. Zhao, S. Zhong, X. Fu, et al., Deep Residual Shrinkage Networks for Fault Diagnosis,
IEEE Transactions on Industrial Informatics, 2019, DOI: 10.1109/TII.2019.2943898
@author: super_9527
"""
from __future__ import print_function
import keras
import numpy as np
from keras.datasets import mnist
from keras.layers import Dense, Conv2D, BatchNormalization, Activation
from keras.layers import AveragePooling2D, Input, GlobalAveragePooling2D
from keras.optimizers import Adam
from keras.regularizers import l2
from keras import backend as K
from keras.models import Model
from keras.layers.core import Lambda
K.set_learning_phase(1)
# Input image dimensions
img_rows, img_cols = 28, 28
# The data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
# Noised data
x_train = x_train.astype('float32') / 255. + 0.5*np.random.random([x_train.shape[0], img_rows, img_cols, 1])
x_test = x_test.astype('float32') / 255. + 0.5*np.random.random([x_test.shape[0], img_rows, img_cols, 1])
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
def abs_backend(inputs):
return K.abs(inputs)
def expand_dim_backend(inputs):
return K.expand_dims(K.expand_dims(inputs,1),1)
def sign_backend(inputs):
return K.sign(inputs)
def pad_backend(inputs, in_channels, out_channels):
pad_dim = (out_channels - in_channels)//2
inputs = K.expand_dims(inputs,-1)
inputs = K.spatial_3d_padding(inputs, ((0,0),(0,0),(pad_dim,pad_dim)), 'channels_last')
return K.squeeze(inputs, -1)
# Residual Shrinakge Block
def residual_shrinkage_block(incoming, nb_blocks, out_channels, downsample=False,
downsample_strides=2):
residual = incoming
in_channels = incoming.get_shape().as_list()[-1]
for i in range(nb_blocks):
identity = residual
if not downsample:
downsample_strides = 1
residual = BatchNormalization()(residual)
residual = Activation('relu')(residual)
residual = Conv2D(out_channels, 3, strides=(downsample_strides, downsample_strides),
padding='same', kernel_initializer='he_normal',
kernel_regularizer=l2(1e-4))(residual)
residual = BatchNormalization()(residual)
residual = Activation('relu')(residual)
residual = Conv2D(out_channels, 3, padding='same', kernel_initializer='he_normal',
kernel_regularizer=l2(1e-4))(residual)
# Calculate global means
residual_abs = Lambda(abs_backend)(residual)
abs_mean = GlobalAveragePooling2D()(residual_abs)
# Calculate scaling coefficients
scales = Dense(out_channels, activation=None, kernel_initializer='he_normal',
kernel_regularizer=l2(1e-4))(abs_mean)
scales = BatchNormalization()(scales)
scales = Activation('relu')(scales)
scales = Dense(out_channels, activation='sigmoid', kernel_regularizer=l2(1e-4))(scales)
scales = Lambda(expand_dim_backend)(scales)
# Calculate thresholds
thres = keras.layers.multiply([abs_mean, scales])
# Soft thresholding
sub = keras.layers.subtract([residual_abs, thres])
zeros = keras.layers.subtract([sub, sub])
n_sub = keras.layers.maximum([sub, zeros])
residual = keras.layers.multiply([Lambda(sign_backend)(residual), n_sub])
# Downsampling using the pooL-size of (1, 1)
if downsample_strides > 1:
identity = AveragePooling2D(pool_size=(1,1), strides=(2,2))(identity)
# Zero_padding to match channels
if in_channels != out_channels:
identity = Lambda(pad_backend, arguments={'in_channels':in_channels,'out_channels':out_channels})(identity)
residual = keras.layers.add([residual, identity])
return residual
# define and train a model
inputs = Input(shape=input_shape)
net = Conv2D(8, 3, padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(inputs)
net = residual_shrinkage_block(net, 1, 8, downsample=True)
net = BatchNormalization()(net)
net = Activation('relu')(net)
net = GlobalAveragePooling2D()(net)
outputs = Dense(10, activation='softmax', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(net)
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=100, epochs=5, verbose=1, validation_data=(x_test, y_test))
# get results
K.set_learning_phase(0)
DRSN_train_score = model.evaluate(x_train, y_train, batch_size=100, verbose=0)
print('Train loss:', DRSN_train_score[0])
print('Train accuracy:', DRSN_train_score[1])
DRSN_test_score = model.evaluate(x_test, y_test, batch_size=100, verbose=0)
print('Test loss:', DRSN_test_score[0])
print('Test accuracy:', DRSN_test_score[1])来源于:深度学习故障诊断算法:残差收缩网络_weixin_47174159的博客-CSDN博客_故障诊断算法
性能评价借鉴前一问的。
关于第四问:
直接运用前面的模型就行,注意论文写好点。
LSTM故障诊断matlab代码:
其中第一个用于读取并划分原始数据
第二个用于完成划分训练集测试集,特征提取+分类等工作
// 本函数Input为
// interval - 数据划分长度,默认为6400,即每6400个数据点划为一个样本
// ind_column - 通道,默认为2,即选取第二个通道
// Output为
// label1 label2, ..., label8,分别为划分好的8种故障类型的样本
%
function [label1 label2 label3 label4 label5 label6 label7 label8]= read_data_1800_High( interval, ind_column )
if nargin <2
ind_column=2; //如果传递的实参小于2个,默认ind_column为2
end
if nargin <1
interval=6400; //默认interval=6400
end
file_rul='E:\Datasets\PHM data challenge\2009 PHM Society Conference Data Challenge-gear box\spur_30hz_High\';
// 以下为获取file_rul路径下.mat格式的所有文件
file_folder=fullfile(file_rul);
dir_output=dir(fullfile(file_folder,'*.mat'));
file_name={dir_output.name}';
num_file=max(size(file_name)); //num_file为文件数,本例中num_file=8,8个文件,分别存储齿轮箱的8种故障数据
for i=1:num_file
file=[file_rul,file_name{i}];
load(file);
[filepath, name, ext]=fileparts(file);
raw=eval(name);
// 每6400个点划分为一个样本
n=1;
left_index=1+(n-1)*interval;
right_index=n*interval;
while right_index<=size(raw,1)
temp=raw(left_index : right_index, ind_column);
// eval函数构造label1, label2,...等变量名
eval(['label' num2str(i) '(:,n)=temp;']);
n=n+1;
left_index=1+(n-1)*interval;
right_index=n*interval;
end
end
end
// 读取数据,label1为一个6400*83的数组,83为每种故障类型所得到的样本数
[label1, label2, label3, label4, label5, label6, label7, label8]=read_data_1800_High();
num_categories=8;
// 由于matlab中LSTM建模需要,用num2cell函数将label1转为cell型,label_x_cell为一个1×83的cell型数组,每个cell存储6400个数据点
label1_x_cell=num2cell(label1,1);
label2_x_cell=num2cell(label2,1);
label3_x_cell=num2cell(label3,1);
label4_x_cell=num2cell(label4,1);
label5_x_cell=num2cell(label5,1);
label6_x_cell=num2cell(label6,1);
label7_x_cell=num2cell(label7,1);
label8_x_cell=num2cell(label8,1);
num_1=length(label1_x_cell);
num_2=length(label2_x_cell);
num_3=length(label3_x_cell);
num_4=length(label4_x_cell);
num_5=length(label5_x_cell);
num_6=length(label6_x_cell);
num_7=length(label7_x_cell);
num_8=length(label8_x_cell);
// 创建用于存储每种故障类型的标签的数据结构,由于matlab中lstm建模需要,也需要cell型数据。例如,label1_y为一个83×1的cell型数组,目前其值为空
label1_y=cell(num_1,1);
label2_y=cell(num_2,1);
label3_y=cell(num_3,1);
label4_y=cell(num_4,1);
label5_y=cell(num_5,1);
label6_y=cell(num_6,1);
label7_y=cell(num_7,1);
label8_y=cell(num_8,1);
// 创建故障类型的标签,用1,2,3,...,8表示8种故障标签,给对应标签赋值。
for i=1:num_1; label1_y{i}='1'; end
for i=1:num_2; label2_y{i}='2'; end
for i=1:num_3; label3_y{i}='3'; end
for i=1:num_4; label4_y{i}='4'; end
for i=1:num_5; label5_y{i}='5'; end
for i=1:num_6; label6_y{i}='6'; end
for i=1:num_7; label7_y{i}='7'; end
for i=1:num_8; label8_y{i}='8'; end
// 用dividerand函数将每种故障类型的数据随机划分为4:1的比例,分别用作训练和测试
[trainInd_label1,~,testInd_label1]=dividerand(num_1,0.8,0,0.2);
[trainInd_label2,~,testInd_label2]=dividerand(num_2,0.8,0,0.2);
[trainInd_label3,~,testInd_label3]=dividerand(num_3,0.8,0,0.2);
[trainInd_label4,~,testInd_label4]=dividerand(num_4,0.8,0,0.2);
[trainInd_label5,~,testInd_label5]=dividerand(num_5,0.8,0,0.2);
[trainInd_label6,~,testInd_label6]=dividerand(num_6,0.8,0,0.2);
[trainInd_label7,~,testInd_label7]=dividerand(num_7,0.8,0,0.2);
[trainInd_label8,~,testInd_label8]=dividerand(num_8,0.8,0,0.2);
// 构建每种故障类型的训练数据
xTrain_label1=label1_x_cell(trainInd_label1);
yTrain_label1=label1_y(trainInd_label1);
xTrain_label2=label2_x_cell(trainInd_label2);
yTrain_label2=label2_y(trainInd_label2);
xTrain_label3=label3_x_cell(trainInd_label3);
yTrain_label3=label3_y(trainInd_label3);
xTrain_label4=label4_x_cell(trainInd_label4);
yTrain_label4=label4_y(trainInd_label4);
xTrain_label5=label5_x_cell(trainInd_label5);
yTrain_label5=label5_y(trainInd_label5);
xTrain_label6=label6_x_cell(trainInd_label6);
yTrain_label6=label6_y(trainInd_label6);
xTrain_label7=label7_x_cell(trainInd_label7);
yTrain_label7=label7_y(trainInd_label7);
xTrain_label8=label8_x_cell(trainInd_label8);
yTrain_label8=label8_y(trainInd_label8);
// 构建每种故障类型的测试数据
xTest_label1=label1_x_cell(testInd_label1);
yTest_label1=label1_y(testInd_label1);
xTest_label2=label2_x_cell(testInd_label2);
yTest_label2=label2_y(testInd_label2);
xTest_label3=label3_x_cell(testInd_label3);
yTest_label3=label3_y(testInd_label3);
xTest_label4=label4_x_cell(testInd_label4);
yTest_label4=label4_y(testInd_label4);
xTest_label5=label5_x_cell(testInd_label5);
yTest_label5=label5_y(testInd_label5);
xTest_label6=label6_x_cell(testInd_label6);
yTest_label6=label6_y(testInd_label6);
xTest_label7=label7_x_cell(testInd_label7);
yTest_label7=label7_y(testInd_label7);
xTest_label8=label8_x_cell(testInd_label8);
yTest_label8=label8_y(testInd_label8);
// 将每种故障类型的数据整合,构建完整的训练集和测试集
xTrain=[xTrain_label1 xTrain_label2 xTrain_label3 xTrain_label4 xTrain_label5 xTrain_label6 xTrain_label7 xTrain_label8];
yTrain=[yTrain_label1; yTrain_label2; yTrain_label3; yTrain_label4; yTrain_label5; yTrain_label6; yTrain_label7; yTrain_label8];
num_train=size(xTrain,2);
xTest=[xTest_label1 xTest_label2 xTest_label3 xTest_label4 xTest_label5 xTest_label6 xTest_label7 xTest_label8];
yTest=[yTest_label1; yTest_label2; yTest_label3; yTest_label4; yTest_label5; yTest_label6; yTest_label7; yTest_label8];
num_test=size(xTest,2);
//================================================================================
//以下分别对每个样本,提取三种特征:1.瞬时频率,2.瞬时谱熵,3.小波包能量,
//上述三种特征后面会被送入分类器中进行分类,实验结果表明,将小波包能量作为特征,
//能够取得最高的分类精度
// 提取瞬时频率:用matlab的pspectrum对每个样本进行谱分解,再用instfreq函数计算瞬时频率
FreqResolu=25;
TimeResolu=0.12;
// the output of pspectrum 'p' contains an estimate of the short-term, time-localized power spectrum of x.
// In this case, p is of size Nf × Nt, where Nf is the length of f and Nt is the length of t.
[p,f,t]=cellfun(@(x) pspectrum(x,fs,'TimeResolution',TimeResolu,'spectrogram'),xTrain,'UniformOutput', false);
instfreqTrain=cellfun(@(x,y,z) instfreq(x,y,z)', p,f,t,'UniformOutput',false);
[p,f,t]=cellfun(@(x) pspectrum(x,fs,'TimeResolution',TimeResolu,'spectrogram'),xTest,'UniformOutput', false);
instfreqTest=cellfun(@(x,y,z) instfreq(x,y,z)', p,f,t,'UniformOutput',false);
// 提取瞬时谱熵:用matlab的pspectrum对每个样本进行谱分解,再用pentropy函数计算瞬时频率
[p,f,t]=cellfun(@(x) pspectrum(x,fs,'TimeResolution',TimeResolu,'spectrogram'),xTrain,'UniformOutput', false);
pentropyTrain=cellfun(@(x,y,z) pentropy(x,y,z)', p,f,t,'UniformOutput',false);
[p,f,t]=cellfun(@(x) pspectrum(x,fs,'TimeResolution',TimeResolu,'spectrogram'),xTest,'UniformOutput', false);
pentropyTest=cellfun(@(x,y,z) pentropy(x,y,z)', p,f,t,'UniformOutput',false);
// 提取小波包能量
// num_level=5表示进行小波包五层分解,共获得2^5=32个值组成的特征向量。
num_level=5;
index=0:1:2^num_level-1;
// wpdec为小波包分解函数
treeTrain=cellfun(@(x) wpdec(x,num_level,'dmey'), xTrain, 'UniformOutput', false);
treeTest=cellfun(@(x) wpdec(x,num_level,'dmey'), xTest, 'UniformOutput', false);
for i=1:num_train
for j=1:length(index)
// wprcoef为小波系数重构函数
reconstr_coef=wprcoef(treeTrain{i},[num_level,index(j)]);
// 计算能量
energy(j)=sum(reconstr_coef.^2);
end
energyTrain_doule(i,:)=energy;
end
energyTrain=num2cell(energyTrain_doule,2);
energyTrain=energyTrain';
for i=1:num_test
for j=1:length(index)
reconstr_coef=wprcoef(treeTest{i},[num_level,index(j)]);
energy(j)=sum(reconstr_coef.^2);
end
energyTest_double(i,:)=energy;
end
energyTest=num2cell(energyTest_double,2);
energyTest=energyTest';
// ===============组装用于送入分类器的特征序列====================
// 下面的语句仅用了小波包能量作为输入特征
xTrainFeature=cellfun(@(x)[x], energyTrain', 'UniformOutput',false);
xTestFeature=cellfun(@(x)[x], energyTest', 'UniformOutput',false);
// 如果想用 瞬时谱熵和小波包能量三种特征作为输入,如下
// xTrainFeature=cellfun(@(x,y,z)[x;y;z],energyTrain',instfreqTrain', pentropyTrain', 'UniformOutput',false);
// xTestFeature=cellfun(@(x,y,z)[x;y;z], energyTest',instfreqTest',pentropyTest', 'UniformOutput',false);
// ============================数据标准化================================
XV=[xTrainFeature{:}];
mu=mean(XV,2);
sg=std(XV,[],2);
xTrainFeatureSD=xTrainFeature;
xTrainFeatureSD=cellfun(@(x)(x-mu)./sg, xTrainFeatureSD,'UniformOutput',false);
xTestFeatureSD=xTestFeature;
xTestFeatureSD=cellfun(@(x)(x-mu)./sg,xTestFeatureSD,'UniformOutput',false);
// =========================设计LSTM网络=================================
yTrain_categorical=categorical(yTrain);
numClasses=numel(categories(yTrain_categorical));
yTest_categorical=categorical(yTest);
sequenceInput=size(xTrainFeatureSD{1},1); // 如果选了3种特征作为数据,这里改为"3"
// 创建用于sequence-to-label分类的LSTM步骤如下:
// 1. 创建sequence input layer
// 2. 创建若干个LSTM layer
// 3. 创建一个fully connected layer
// 4. 创建一个softmax layer
// 5. 创建一个classification outputlayer
// 注意将sequence input layer的size设置为所包含的特征类别数,本例中,1或2或3,取决于你用了几种特征。fully connected layer的参数为分类数,本例中为8.
layers = [ ...
sequenceInputLayer(sequenceInput)
lstmLayer(256,'OutputMode','last')
fullyConnectedLayer(numClasses)
softmaxLayer
classificationLayer
];
maxEpochs=600;
miniBatchSize=32;
// 如果不想展示训练过程,
options = trainingOptions('adam', ...
'ExecutionEnvironment', 'gpu',...
'SequenceLength', 'longest',...
'MaxEpochs',maxEpochs, ...
'MiniBatchSize', miniBatchSize, ...
'InitialLearnRate', 0.001, ...
'GradientThreshold', 1, ...
'plots','training-progress', ...
'Verbose',true);
// ======================训练网络=========================
net2 = trainNetwork(xTrainFeatureSD,yTrain_categorical,layers,options);
// ======================测试网路==========================
testPred2 = classify(net2,xTestFeatureSD);
// 打印混淆矩阵
plotconfusion(yTest_categorical',testPred2','Testing Accuracy')来源于:信号特征提取+LSTM实现齿轮减速箱故障诊断-matlab代码_Eva215665的博客-CSDN博客_lstm故障诊断
这篇论文是齿轮故障诊断的,仔细看!!!
小波分析神经网络的需要下载matlab程序源码及报告word版--基于小波包分析和神经网络的滚动轴承故障诊断_MATLAB轴承SVM故障诊断CSDN-Matlab代码类资源-CSDN下载
这个题来说,比较好的方法就是机器学习直接做就行,数据也不难处理。数维杯有很多人反映数据不好处理,这个题没有这个烦恼。
就看谁做的精确度更高吧,论文好好写就行。
后续有问题我会修改或者补充。
大家有问题可以在评论区或者私信。
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
ruby中有这样的东西吗?send(+,1,2)我想让这段代码看起来不那么冗余ifop=="+"returnarg1+arg2elsifop=="-"returnarg1-arg2elsifop=="*"returnarg1*arg2elsifop=="/"returnarg1/arg2 最佳答案 是的,只需像这样使用send(或者更好的是public_send):arg1.public_send(op,arg2)这是可行的,因为Ruby中的大多数运算符(包括+、-、*、/、andmore)只需调用方法。所以1+2与1.+(2)相同
3月26日,映宇宙(HK:03700,即“映客”)发布截至2022年12月31日的2022年度业绩财务报告。财报显示,映宇宙2022年的总营收为63.19亿元,较2021年同期的91.76亿元下降31.1%。2022年,映宇宙的经营亏损为4698.7万元,2021年同期则为净利润4.57亿元;期内亏损(净亏损)为1.68亿元,2021年同期的净利润为4.33亿元;非国际财务报告准则经调整净利润为3.88亿元,2021年同期为4.82亿元,同比下降19.6%。 映宇宙在财报中表示,收入减少主要是由于行业竞争加剧,该集团对旗下产品采取更为谨慎的运营策略以应对市场变化。不过,映宇宙的毛利率则有所提升
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
情况:我正在编写一个程序来求解素数。我需要解决4x^2+y^2=n的问题,其中n是一个已知变量。是的,必须是Ruby。我愿意在这个项目上花费大量时间。我最好自己编写方程式的求解算法,并将其作为该项目的一部分。我真正喜欢的是:如果任何人都可以向我提供指南、网站的链接,或者关于与求解代数方程特别相关的形式算法的构造的歧义消除,或者向我提供似乎你是读者它会帮助我完成任务。请不要建议我使用其他语言。如果您在回答之前接受我真的非常想这样做,我将不胜感激。该项目没有范围或时间限制,也不以营利为目的。这是为了我自己的教育。注意:我并不直接反对为Ruby实现和使用现存的数学库/模块/其他东西,但我更喜
我发现许多Rails应用程序主要针对企业、社交网络类型的Web应用程序。我看到有人将Ruby与一些出色的OOPS语言(如Java和C#)进行了比较,但我确实发现很难获得一些数学密集型应用程序。非常感谢任何知识渊博的输入(指向示例程序的链接等),其中轻松显示了语言的用法,就像快速启动或显示该语言如何用于各种数学问题一样。 最佳答案 不幸的是,Ruby并没有在数学和科学计算领域涉足太多。目前,有一个名为SciRuby的pre-alpha库它试图为Ruby带来更多面向数学的功能。他们正试图构建一个NumPy/SciPy等价物。SciRub
link有两个组件:componenta_id和componentb_id。为此,在Link模型文件中我有:belongs_to:componenta,class_name:"Component"belongs_to:componentb,class_name:"Component"validates:componenta_id,presence:truevalidates:componentb_id,presence:truevalidates:componenta_id,uniqueness:{scope::componentb_id}validates:componentb_id
三大公有云厂商,香港地区主机测评一、ping时延比对(厦门电信本地测试):Ping时延测试腾讯云阿里云华为云延迟率最低时延44ms,最高72ms,平均46ms47.242段:最低时延59ms,最高204ms,平均107ms最低时延45ms,最高93ms,平均47ms丢包率丢包率小有的ip段丢包率较大每个段都会有概率丢包阿里云:47.242段:最低时延59ms,最高204ms,平均107ms,有的ip段丢包率较大8.210段:最低时延64ms,最高232ms,平均119ms,丢包率较好腾讯云:最低时延44ms,最高72ms,平均46ms,丢包率小华为云:最低时延45ms,最高93ms,平均47m
“架设一个亿级高并发系统,是多数程序员、架构师的工作目标。许多的技术从业人员甚至有时会降薪去寻找这样的机会。但并不是所有人都有机会主导,甚至参与这样一个系统。今天我们用12306火车票购票这样一个业务场景来做DDD领域建模。”开篇要实现软件设计、软件开发在一个统一的思想、统一的节奏下进行,就应该有一个轻量级的框架对开发过程与代码编写做一定的约束。虽然DDD是一个软件开发的方法,而不是具体的技术或框架,但拥有一个轻量级的框架仍然是必要的,为了开发一个支持DDD的框架,首先需要理解DDD的基本概念和核心的组件。一.什么是领域驱动设计(DDD)首先要知道DDD是一种开发理念,核心是维护一个反应领域概
如何用IDEA2022创建并初始化一个SpringBoot项目?目录如何用IDEA2022创建并初始化一个SpringBoot项目?0. 环境说明1. 创建SpringBoot项目 2.编写初始化代码0. 环境说明IDEA2022.3.1JDK1.8SpringBoot1. 创建SpringBoot项目 打开IDEA,选择NewProject创建项目。 填写项目名称、项目构建方式、jdk版本,按需要修改项目文件路径等信息。 选择springboot版本以及需要的包,此处只选择了springweb。 此处需特别注意,若你使用的是jdk1