情景:女友买的学习视频将在一个月后到期(到期后下载在本地也无法看),让我帮忙把视频下载下来,之前抓过m3u8文件下载过视频切片合成后是一个完整视频,以为这次的任务非常简单~
然鹅,查看一下app信息,已经被加固处理(伪加固)
已经加固了,暂时不考虑脱壳编译
于是开始抓包,我的安卓手机没有root,在抓取某课app时由于 检测到代理导致某课app里面没网络,之前在玩安卓逆向的时候偶然发现
部分APP可以放在容器中,通过抓取容器获得运行APP的抓包数据
也就是用把 xx 安装在 VirtualXposed 里面,黄鸟抓取VirtualXposed
VirtualXposed链接:点我
注意:这个方法只适用部分app,有的安装后会闪退
抓包部分截图:

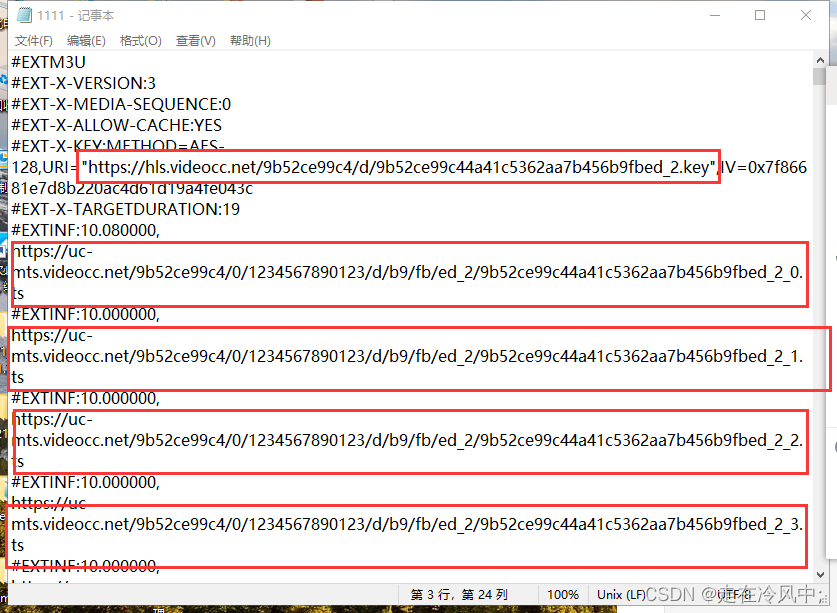
上面是抓到的m3u8信息,根据之前的到这一步应该是成功了,密钥和视频切片ts文件应该就可以合成完整视频
但是访问红色部分的key却是显示404,视频切片能下载但是无法解密
看到了一篇关于key被访问了一次就删除的博客,不得不让我猜想,是不是app客户端访问后拿下密钥文件,在app前端将下载的资源文件进行解析然后播放,既然访问了一次,我拿到的抓包数据也就是已经被访问过的了,在这里我已经将app的缓存目录看了下,乱码很多不知道密钥文件放在哪里,所以我将整个流程用python写下来了
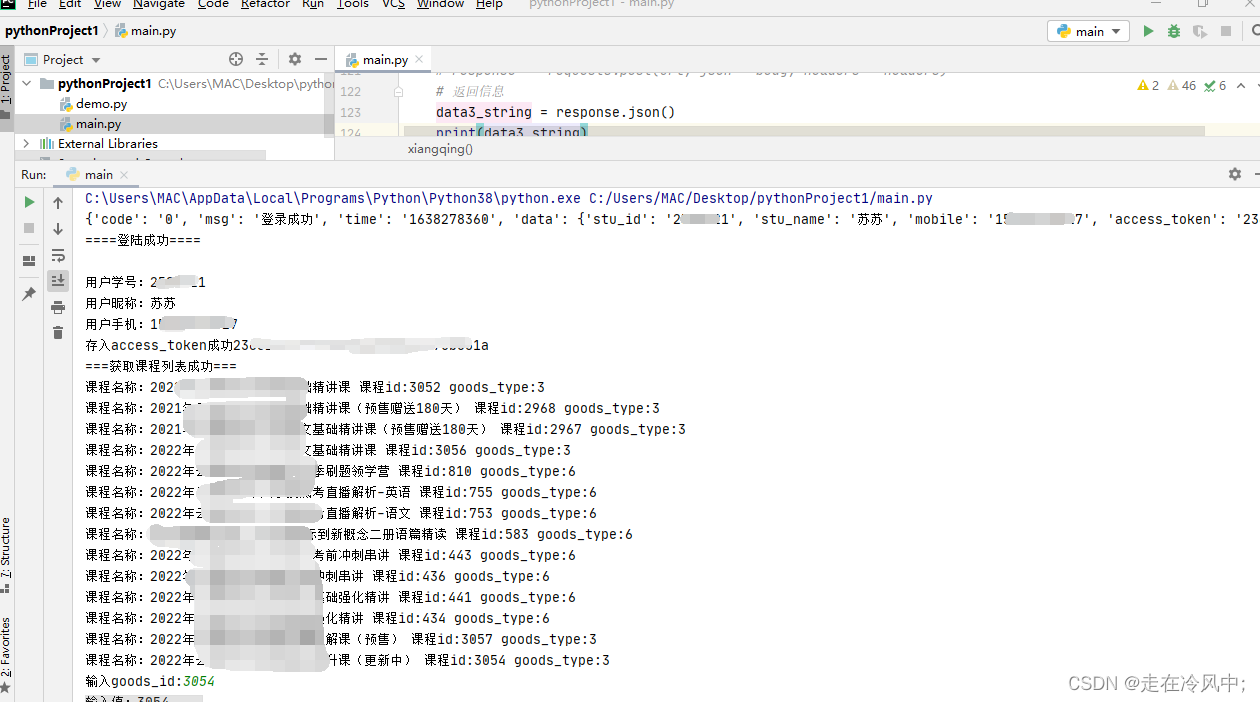
现在写到 登录->获取用户信息及token->获取所有课程->某个课程课程->视频id 编码
今晚就到这里,明天再看,目前发现拿到m3u8的链接由
https://api/userid/x/video_id.m3u8
x位置不确定,后面的did不用携带也可以
真实地址:https://hls.videocc.net/9b52ce99c4/d/9b52ce99c4df4d856f4b770a2e8112ad_2.m3u8?did=1638152451432X1376979
明天会上代码以及接口,如果对于我的个人见解有更好的意见、看法,或者新思路请评论一起交流,以上
import requests
import json
#爬取库课网课付费视频
#本人因为女友购买的付费视频即将到期,想将其下载下来,留作备份 慢慢看
def login(uuid,password):
host = "https://new6api.kuke99.com/user/login"
#
params = {
"password":password,
"mobile":'MTU5NjkxMTA5Mjc='
}
header = {
"clientType": "3",
'version': '6.2.13',
"Referer": "https://m.kuke99.com",
"UUID": uuid,
"Content-Type": "application/x-www-form-urlencoded;charset=UTF-8",
"deviceType": "V1814T",
"osVersion": "9",
"Content-Length": "78",
"Host": "new6api.kuke99.com",
"Connection": "Keep-Alive",
"Accept-Encoding": "gzip",
"User-Agent": "okhttp/4.9.1"
}
cookies = {
# "acw_tc": acw_tc
}
response = requests.post(host, data=params,headers=header)
# 也可以直接将data字段换成json字段,2.4.3版本之后支持
# response = requests.post(url, json = body, headers = headers)
# 返回信息
data_string=response.json()
print(data_string)
if(data_string['code']=='0'):
print("====登陆成功====\n")
print("用户学号:" + data_string['data']['stu_id'])
print("用户昵称:"+data_string['data']['stu_name'])
print("用户手机:" + data_string['data']['mobile'])
global access_token
access_token=data_string['data']['access_token']
print("存入access_token成功"+access_token)
return access_token
else:
print("!!!!!登录失败!!!!!!")
def refresh(uid,accessTok):
url = "https://new6api.kuke99.com/learning/learning_list"
#
params = {
"subject_id": '0',
"cate_id": '0'
}
header = {
"accessToken": accessTok,
"clientType": "3",
'version': '6.2.13',
"Referer": "https://m.kuke99.com",
"UUID": uid,
"Content-Type": "application/x-www-form-urlencoded",
"deviceType": "V1814T",
"osVersion": "9",
"Content-Length": "22",
"Host": "new6api.kuke99.com",
"Connection": "Keep-Alive",
"Accept-Encoding": "gzip",
"User-Agent": "okhttp/4.9.1"
}
cookies = {
# "acw_tc": acw_tc
}
response = requests.post(url, data=params, headers=header)
# 也可以直接将data字段换成json字段,2.4.3版本之后支持
# response = requests.post(url, json = body, headers = headers)
# 返回信息
data2_string = response.json()
# print(data2_string)
if(data2_string['code']=='0'):
print("===获取课程列表成功===")
for keys in data2_string['data']['general']:
print("课程名称:"+keys['goods_title']+" 课程id:"+keys['goods_id']+" goods_type:"+keys['goods_type'])
else:
print("获取列表失败请重新登录,建议查看password uuid 正确性")
def xiangqing(g_id,g_type,access_oken,uuid):
url = "https://new6api.kuke99.com/goods_collation/detail"
#
params = {
"goods_id": g_id,
"goods_type": g_type,
"ac_type":''
}
header = {
"accessToken": access_oken,
"clientType": "3",
'version': '6.2.13',
"Referer": "https://m.kuke99.com",
"UUID": uuid,
"Content-Type": "application/x-www-form-urlencoded",
"deviceType": "V1814T",
"osVersion": "9",
"Content-Length": "22",
"Host": "new6api.kuke99.com",
"Connection": "Keep-Alive",
"Accept-Encoding": "gzip",
"User-Agent": "okhttp/4.9.1"
}
cookies = {
# "acw_tc": acw_tc
}
response = requests.post(url, data=params, headers=header)
# 也可以直接将data字段换成json字段,2.4.3版本之后支持
# response = requests.post(url, json = body, headers = headers)
# 返回信息
data3_string = response.json()
print(data3_string)
#视频详情页面
def get_m3u8(video_id,access_oken,uuid):
host = "https://hls.videocc.net/9b52ce99c4/f/"+video_id+".m3u8?did=1638275844261X1898885"
print(host)
params = {
}
headers = {
"accessToken": access_oken,
"clientType": "3",
'version': '6.2.13',
"Referer": "https://m.kuke99.com",
"UUID": uuid,
"Content-Type": "application/x-www-form-urlencoded",
"deviceType": "V1814T",
"osVersion": "9",
"Content-Length": "25",
"Host": "hls.videocc.net",
"Connection": "Keep-Alive",
"Accept-Encoding": "gzip",
"User-Agent": "polyv-android-sdk2.15.3-20210520 Dalvik/2.1.0 (Linux; U; Android 9; V1814T Build/PKQ1.180819.001)"
}
cookies = {
}
r = requests.get(host, data=params)
data3_string = r.json()
print(data3_string)
def download(g_id,g_type,access_oken,uuid):
url = "https://new6api.kuke99.com/download/node_list"
#
params = {
"goods_id": g_id,
"goods_type": g_type,
}
header = {
"accessToken": access_oken,
"clientType": "3",
'version': '6.2.13',
"Referer": "https://m.kuke99.com",
"UUID": uuid,
"Content-Type": "application/x-www-form-urlencoded",
"deviceType": "V1814T",
"osVersion": "9",
"Content-Length": "25",
"Host": "new6api.kuke99.com",
"Connection": "Keep-Alive",
"Accept-Encoding": "gzip",
"User-Agent": "okhttp/4.9.1"
}
cookies = {
# "acw_tc": acw_tc
}
response = requests.post(url, data=params, headers=header)
# 也可以直接将data字段换成json字段,2.4.3版本之后支持
# response = requests.post(url, json = body, headers = headers)
# 返回信息
data3_string = response.json()
# print(data3_string)
print(data3_string['code'])
if(data3_string['code']=='0'):
for keys in data3_string['data']:
print("选中的可下载的vdieo id:"+keys['video_id'])
else:
print("获取下载信息失败")
#视频下载页面信息
if __name__ == '__main__':
UUID=''#用户识别uid
password=""#密码
login(UUID,password)#登录账号密码获取token
# print(access_token)
refresh(UUID,access_token)#读取购买所有课程信息(学习列表)
#用户手动输入数据
goods_id = input("输入goods_id:")
print('输入值:' + goods_id)
goods_type = input("goods_type:")
print('输入值:' + goods_type)
# xiangqing(goods_id,goods_type,access_token,UUID)#视频详情
download(goods_id, goods_type, access_token, UUID) # 得到下载列表
video_id = input("输入video_id:")
print('输入值:' + video_id)
get_m3u8(video_id,access_token,UUID)#获得m3u8链接
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
我需要尝试一些AES片段。我有一些密文c和一个keyk。密文已使用AES-CBC加密,并在前面加上IV。不存在填充,纯文本的长度是16的倍数。所以我这样做:aes=OpenSSL::Cipher::Cipher.new("AES-128-CCB")aes.decryptaes.key=kaes.iv=c[0..15]aes.update(c[16..63])+aes.final它工作得很好。现在我需要手动执行CBC模式,所以我需要单个block的“普通”AES解密。我正在尝试这个:aes=OpenSSL::Cipher::Cipher.new("AES-128-ECB")aes.dec
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
-if!request.path_info.include?'A'%{:id=>'A'}"Text"-else"Text"“文本”写了两次。我怎样才能只写一次并同时检查path_info是否包含“A”? 最佳答案 有两种方法可以做到这一点。使用部分,或使用content_forblock:如果“文本”较长,或者是一个重要的子树,您可以将其提取到一个部分。这会使您的代码变干一点。在给出的示例中,这似乎有点矫枉过正。在这种情况下更好的方法是使用content_forblock,如下所示:-if!request.path_info.inc
我正在尝试对某些帖子的评论使用简单的身份验证。用户使用即时ID和密码输入评论我使用“bcrypt”gem将密码存储在数据库中。在comments_controller.rb中像这样@comment=Comment.new(comment_params)bcrypted_pwd=BCrypt::Password.create(@comment.user_pwd)@comment.user_pwd=bcrypted_pwd当用户想要删除他们的评论时,我使用data-confirm-modalgem来确认数据在这部分,我必须解密用户输入的密码以与数据库中的加密密码进行比较我怎样才能解密密码,
