小梅哥的这个ZYNQ开发板上的DDR3位于PS侧,PL侧想要使用DDR3作为缓存的话,得通过HP接口来与PS侧的DDR3控制进行通信。

本次实验在小梅哥OV5640工程的基础上,通过修改VDMA的S2MM端的模块而来的。
将VMDA的帧缓存区设为1,关闭帧同步的功能后,其实和DMA差不多。
这里列出的为自己写的IP核。小梅哥的工程里还用到了其它的自定义的IP核,这里就不列出了。
该模块调用了之前写的串口8位接收模块,详情可点击查看。
此外,本模块还调用16位宽、深度为1024的带数据计数的普通FIFO核
该模块主要的思想就是将接收到的两个8位的数据拼接位1个16位的数据并存入FIFO中,
当存入的数据达到LINE_LENGTH(800)的时候,在收到从接口的准备信号时一次性写入VMDA中,再通过VMDA将数据写到DDR3中。
此外该模块在应用的时候要封装成带AXI4_Stream 接口的IP核,具体封装过程可网上找教程。
`timescale 1ns / 1ps
//////////////////////////////////////////////////////////////////////////////////
// Company: GDUT
// Engineer: Lclone
//
// Create Date: 2023/02/07 20:38:34
// Design Name:
// Module Name: Img_Rx
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//////////////////////////////////////////////////////////////////////////////////
module Img_Rx
# (parameter RX_BAUD = 115200,
parameter CLK_FQC = 50_000_000,
parameter LINE_LENGTH = 800)
(
input Uart_Rx,
//---------------------------
input m_clk,
input m_axis_aresetn,
output [15:0] m_axis_tdata,
output reg m_axis_tlast,
input m_axis_tready,
output reg m_axis_tvalid
);
wire [7:0] Uart_Data;
wire Rx_done;
reg Rx_done_r;
reg Rx_done_cnt;
reg [15:0] Uart_Data_16;
wire [9:0] fifo_data_count;
reg [9:0] out_data_count;
reg m_axis_tvalid_r;
always @(posedge m_clk) Rx_done_r <= Rx_done;
always @(posedge m_clk) m_axis_tvalid <= m_axis_tvalid_r;
always @(posedge m_clk or negedge m_axis_aresetn) begin
if(m_axis_aresetn == 0)
Uart_Data_16 <= 0;
else if(Rx_done == 1)
Uart_Data_16 <= {Uart_Data_16[7:0],Uart_Data};
end
always @(posedge m_clk or negedge m_axis_aresetn) begin
if(m_axis_aresetn == 0)
Rx_done_cnt <= 0;
else if(Rx_done == 1)
Rx_done_cnt <= Rx_done_cnt + 1'b1;
else
Rx_done_cnt <= Rx_done_cnt;
end
always @(posedge m_clk or negedge m_axis_aresetn) begin
if(m_axis_aresetn == 0)
m_axis_tvalid_r <= 0;
else if(m_axis_tready == 1 & fifo_data_count >= LINE_LENGTH)
m_axis_tvalid_r <= 1'b1;
else if(fifo_data_count <= 1)
m_axis_tvalid_r <= 0;
else
m_axis_tvalid_r <= m_axis_tvalid_r;
end
always @(posedge m_clk or negedge m_axis_aresetn) begin
if(m_axis_aresetn == 0)
out_data_count <= 0;
else if(out_data_count == LINE_LENGTH - 1)
out_data_count <= 0;
else if(m_axis_tvalid_r & m_axis_tready)
out_data_count <= out_data_count + 1'b1;
else
out_data_count <= out_data_count;
end
always @(posedge m_clk or negedge m_axis_aresetn) begin
if(m_axis_aresetn == 0)
m_axis_tlast <= 0;
else if(out_data_count == LINE_LENGTH - 1)
m_axis_tlast <= 1;
else
m_axis_tlast <= 0;
end
uart_byte_rx
# (
.RX_BAUD (RX_BAUD),
.CLK_FQC (CLK_FQC))
uart_byte_rx_inst
(
.Clk (m_clk),
.Rst_n (m_axis_aresetn),
.Uart_rx (Uart_Rx),
.Data (Uart_Data),
.Rx_done (Rx_done)
);
fifo_generator_0 fifo_generator_0_inst (
.clk(m_clk), // input wire clk
.srst(~m_axis_aresetn), // input wire srst
.din(Uart_Data_16), // input wire [15 : 0] din
.wr_en(~Rx_done_cnt & Rx_done_r), // input wire wr_en
.rd_en(m_axis_tvalid_r & m_axis_tready), // input wire rd_en
.dout(m_axis_tdata), // output wire [15 : 0] dout
.full(), // output wire full
.empty(), // output wire empty
.data_count(fifo_data_count) // output wire [9 : 0] data_count
);
endmodule
`timescale 1ns / 1ps
module rx_img_test();
reg clk_50m;
initial clk_50m <= 1;
always #10 clk_50m <= ~clk_50m;
reg rst_n;
initial begin
rst_n <= 0;
#200
rst_n <= 1;
end
wire [15:0] m_axis_tdata;
wire m_axis_tlast;
wire m_axis_tready;
wire m_axis_tvalid;
wire [15:0] out_axis_tdata;
wire out_axis_tlast;
wire out_axis_tready;
wire out_axis_tvalid;
reg Uart_Rx;
reg [ 7:0] Uart_Data;
Img_Rx #(
.RX_BAUD(2_000_000),
.CLK_FQC(100_000_000),
.LINE_LENGTH(16)
)
Img_Rx_inst (
.Uart_Rx(Uart_Rx), // input wire Uart_Rx
.m_clk(clk_50m), // input wire m_clk
.m_axis_aresetn(rst_n), // input wire m_axis_aresetn
.m_axis_tdata(m_axis_tdata), // output wire [15 : 0] m_axis_tdata
.m_axis_tlast(m_axis_tlast), // output wire m_axis_tlast
.m_axis_tready(m_axis_tready), // input wire m_axis_tready
.m_axis_tvalid(m_axis_tvalid) // output wire m_axis_tvalid
);
axis_data_fifo_0 axis_data_fifo_0_inst (
.s_axis_aresetn(rst_n), // input wire s_axis_aresetn
.s_axis_aclk(clk_50m), // input wire s_axis_aclk
.s_axis_tvalid(m_axis_tvalid), // input wire s_axis_tvalid
.s_axis_tready(m_axis_tready), // output wire s_axis_tready
.s_axis_tdata(m_axis_tdata), // input wire [15 : 0] s_axis_tdata
.s_axis_tlast(m_axis_tlast), // input wire s_axis_tlast
.m_axis_tvalid(out_axis_tvalid), // output wire m_axis_tvalid
.m_axis_tready(out_axis_tready), // input wire m_axis_tready
.m_axis_tdata(out_axis_tdata), // output wire [15 : 0] m_axis_tdata
.m_axis_tlast(out_axis_tlast) // output wire m_axis_tlast
);
initial begin
Uart_Rx <= 1;
Uart_Data <= 0;
#200
repeat (256) begin
data_deliver(Uart_Data);
Uart_Data = Uart_Data + 1;
end
$stop;
end
task data_deliver;
input [7:0] test_data;
begin
Uart_Rx <= 1'b0;
#1000
Uart_Rx <= test_data[0];
#1000
Uart_Rx <= test_data[1];
#1000
Uart_Rx <= test_data[2];
#1000
Uart_Rx <= test_data[3];
#1000
Uart_Rx <= test_data[4];
#1000
Uart_Rx <= test_data[5];
#1000
Uart_Rx <= test_data[6];
#1000
Uart_Rx <= test_data[7];
#1000
Uart_Rx <= 1'b1;
#1000;
end
endtask
assign out_axis_tready = 1;
endmodule
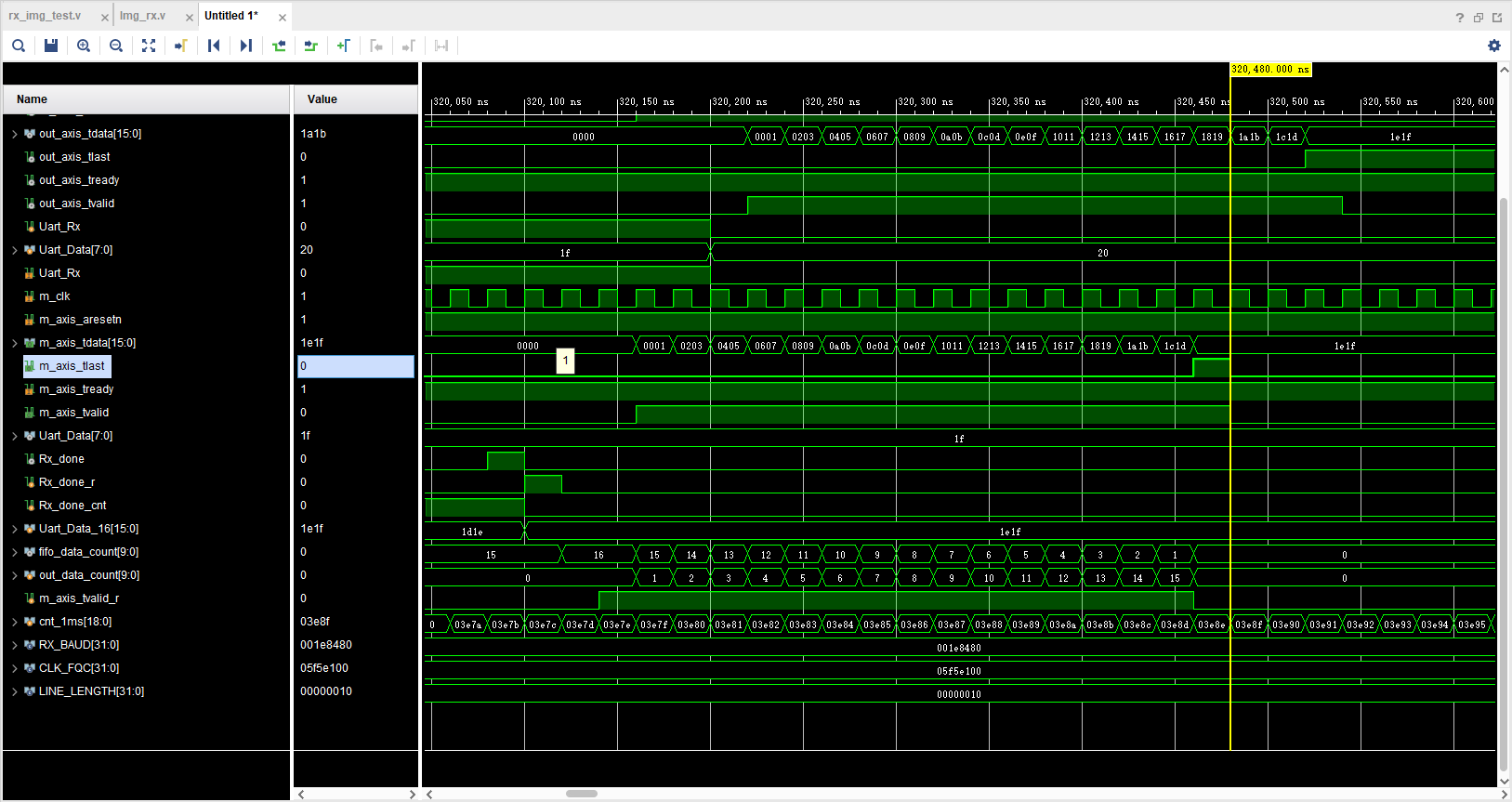
可见该模块能够正确地将16个两字节的数据正确的输出,并在最后一个数据的位置基于一个tlast信号。
打开小梅哥的ACZ7020的OV5640_LCD工程,然后将红框部分的模块删除,加入自定义的串口接收图像数据模块。
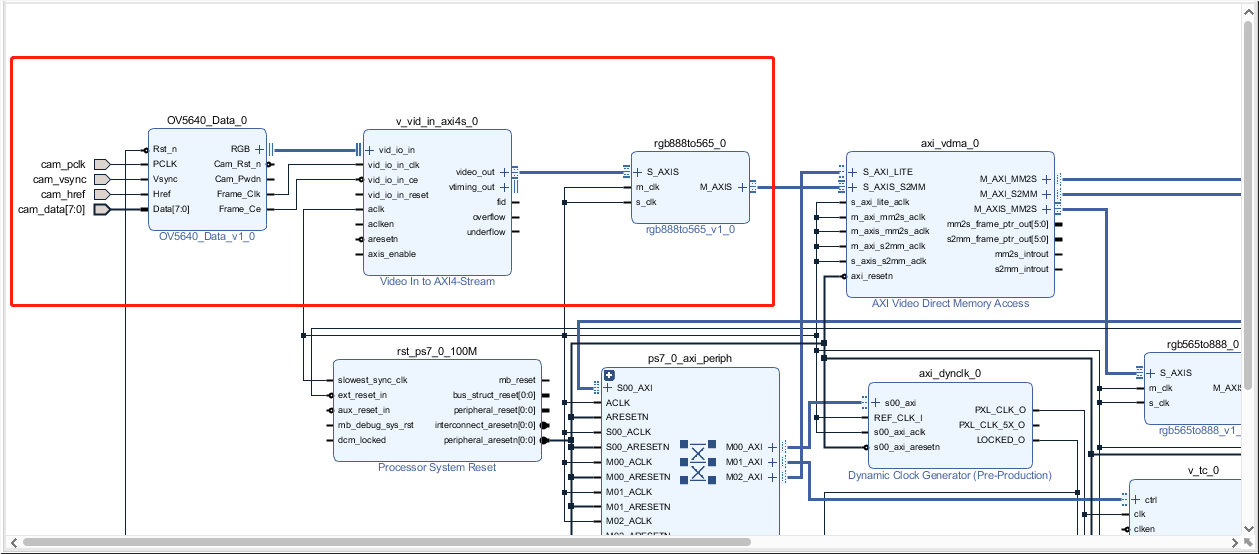
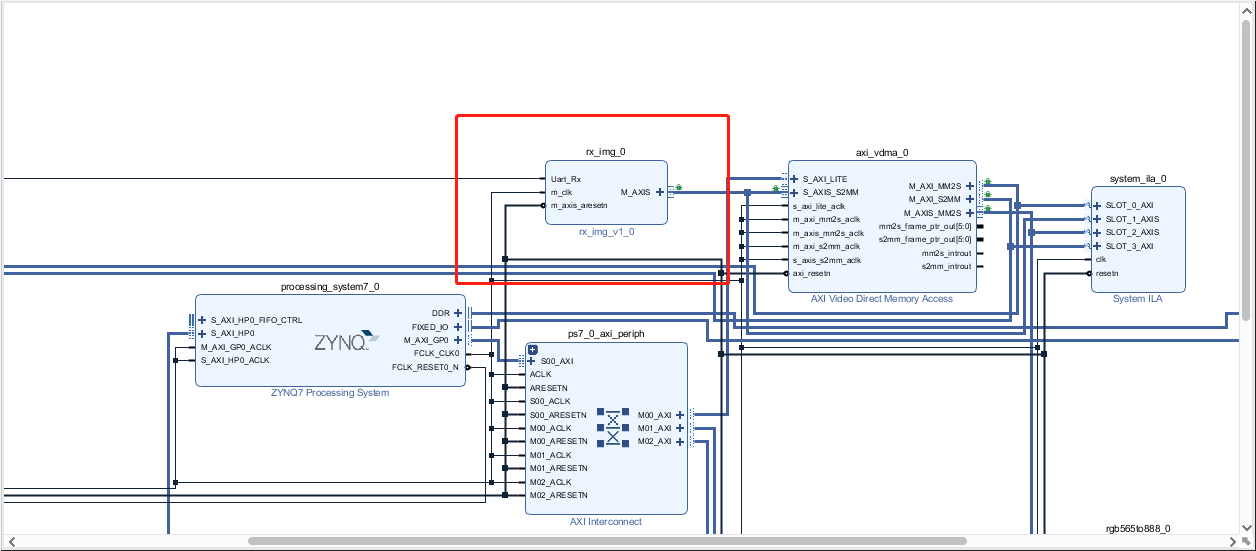
并修改下列IP核的参数
将频率修改为如下:
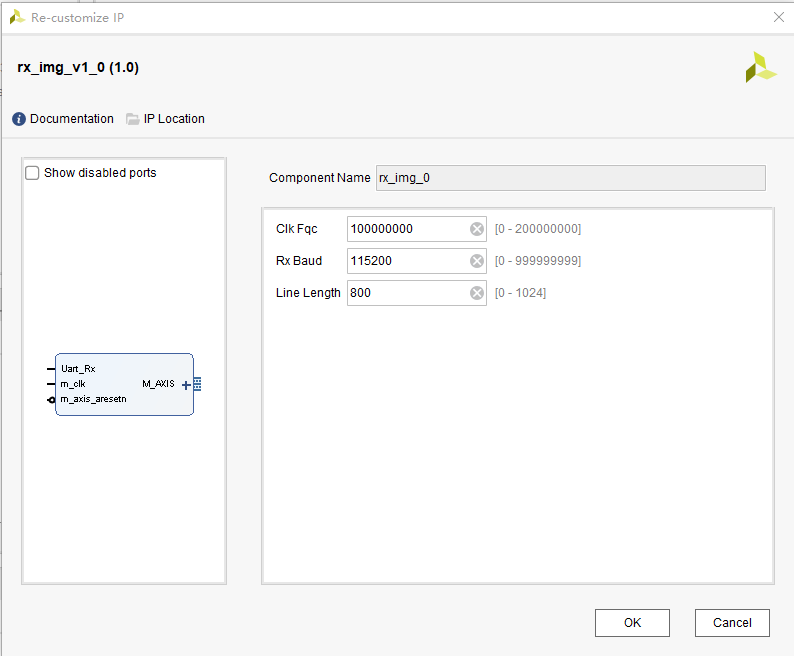
将帧缓存区设为1
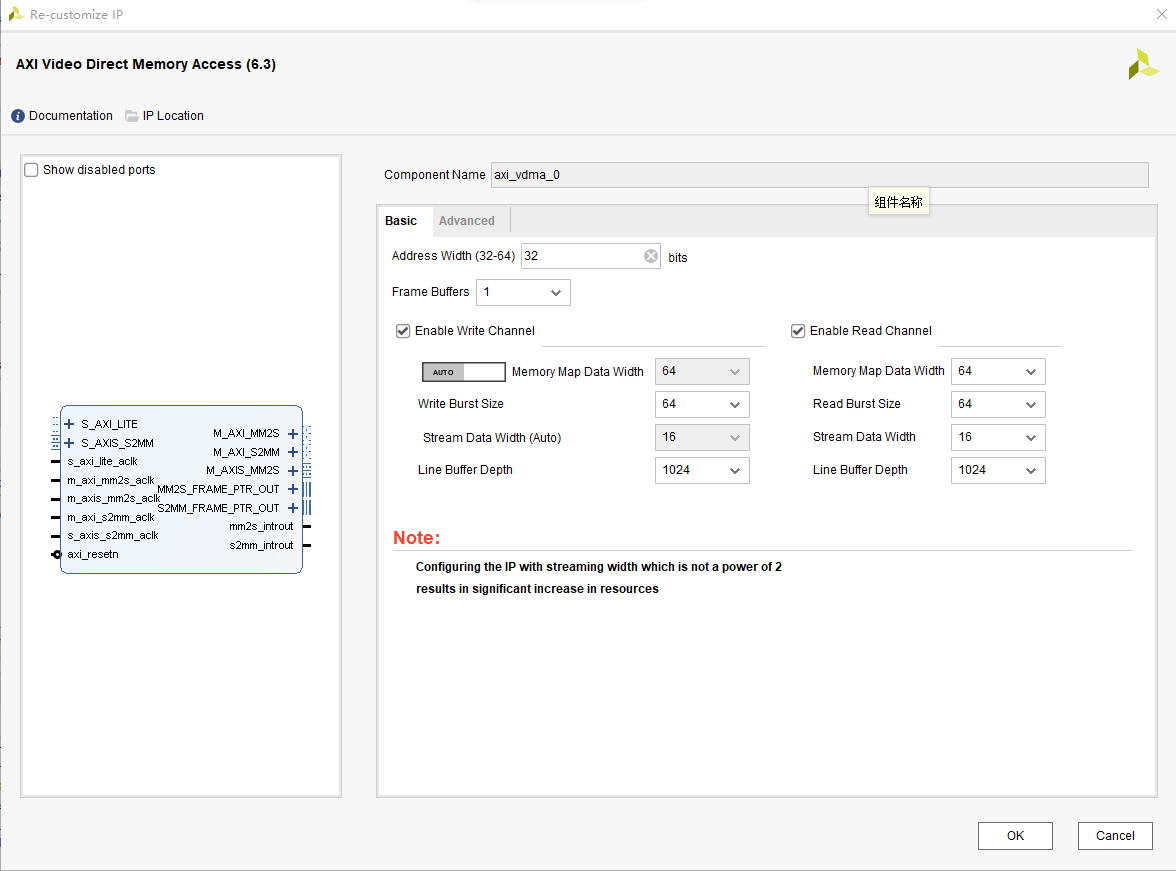
Fsync Options选择None,关掉帧同步功能
在约束文件中,加入串口的管脚约束

在SDK中,将OV5640的初始化函数删除,将PS_IIC和OV5640库删除
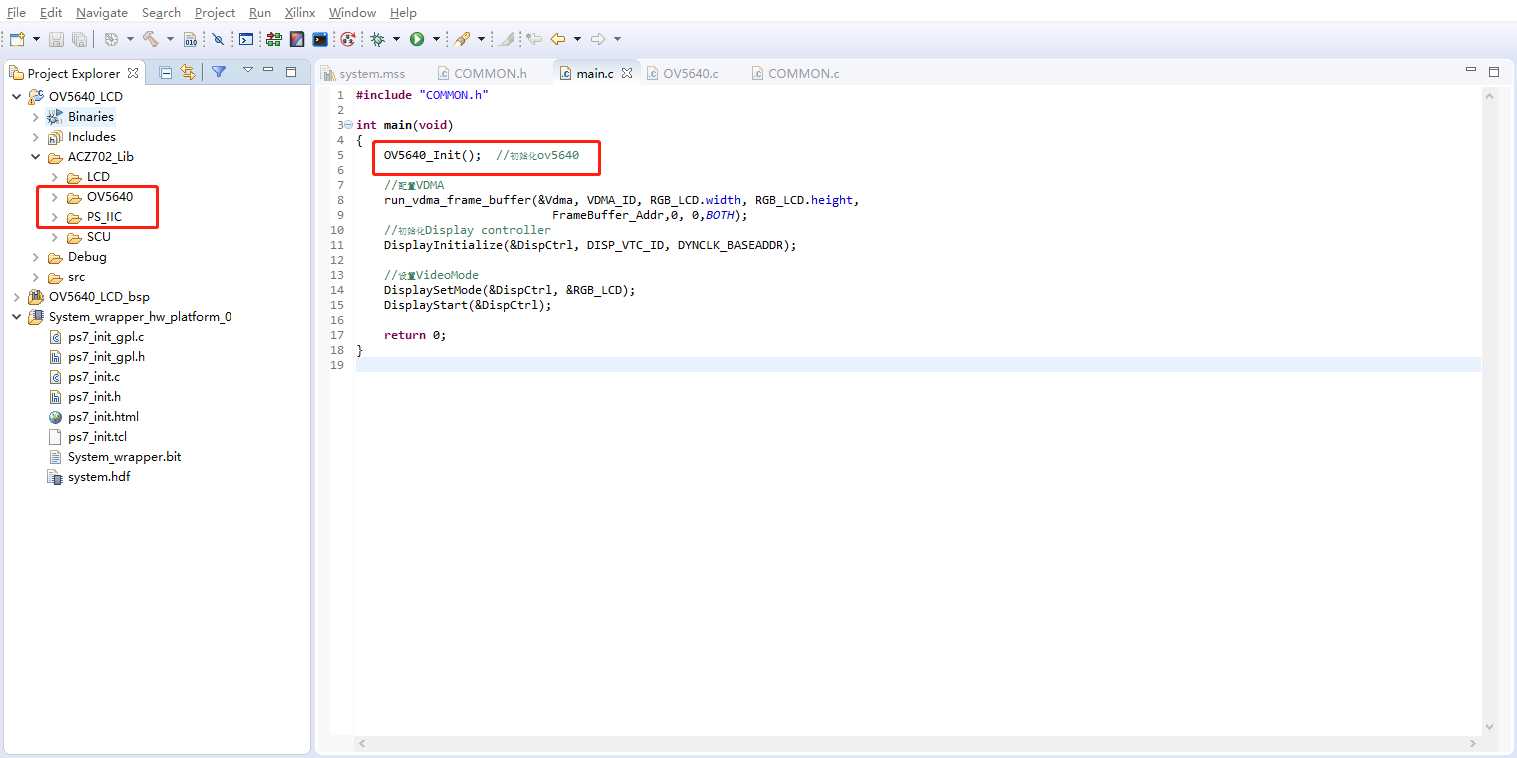
同时也将PS_IIC和OV5640库的路径删除掉

然后就可以下载程序到开发板上了
将程序下载进开发板,然后打开img2lcd软件,读取一个800*480大小的BMP文件,并按如下设置:
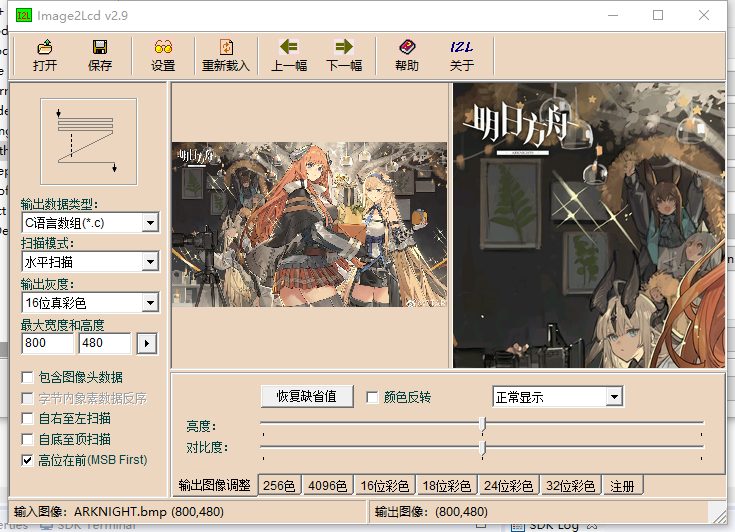
然后在输出的文件中进行修改
删除首行
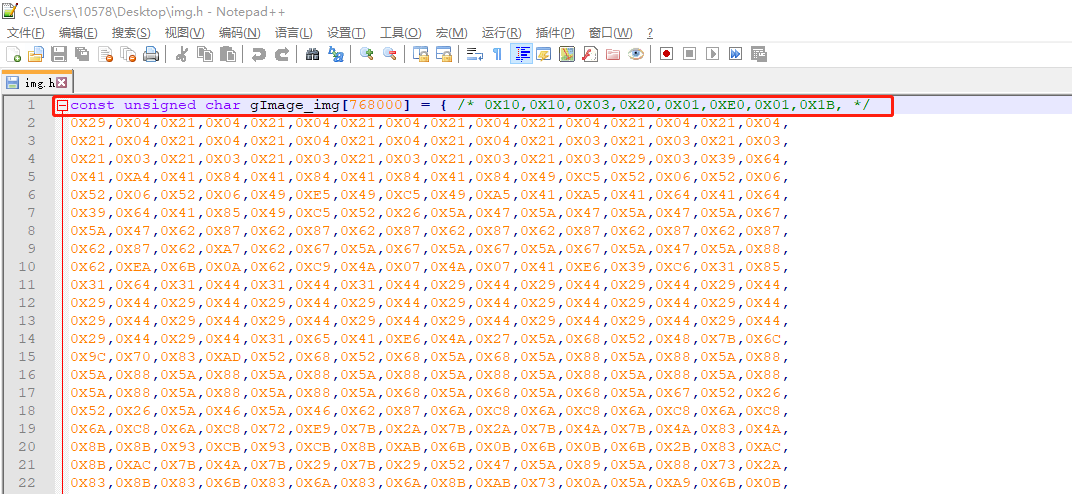
删除末尾符号

使用软件的查找替换功能,将所有的0X删掉,并将","换为空格符,然后使用行操作里面的行合并去除掉每一行末尾的回车符。最后就得到传输的图像数据:

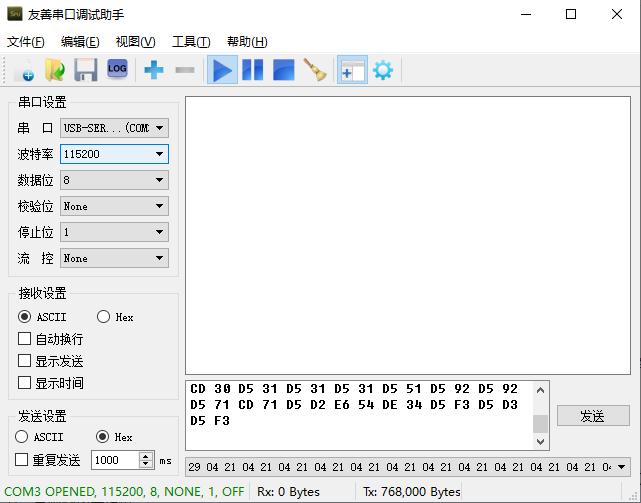
打开友善串口调试助手,将图像数据复制进去,打开串口端口,设置好波特率,然后发送,确保TX发送了768000个字节,否则图像会错位;确保底下绿色的字显示的波特率为115200,否则数据无法正确传输。
传输数据后,发现图像能够正确显示在LCD上
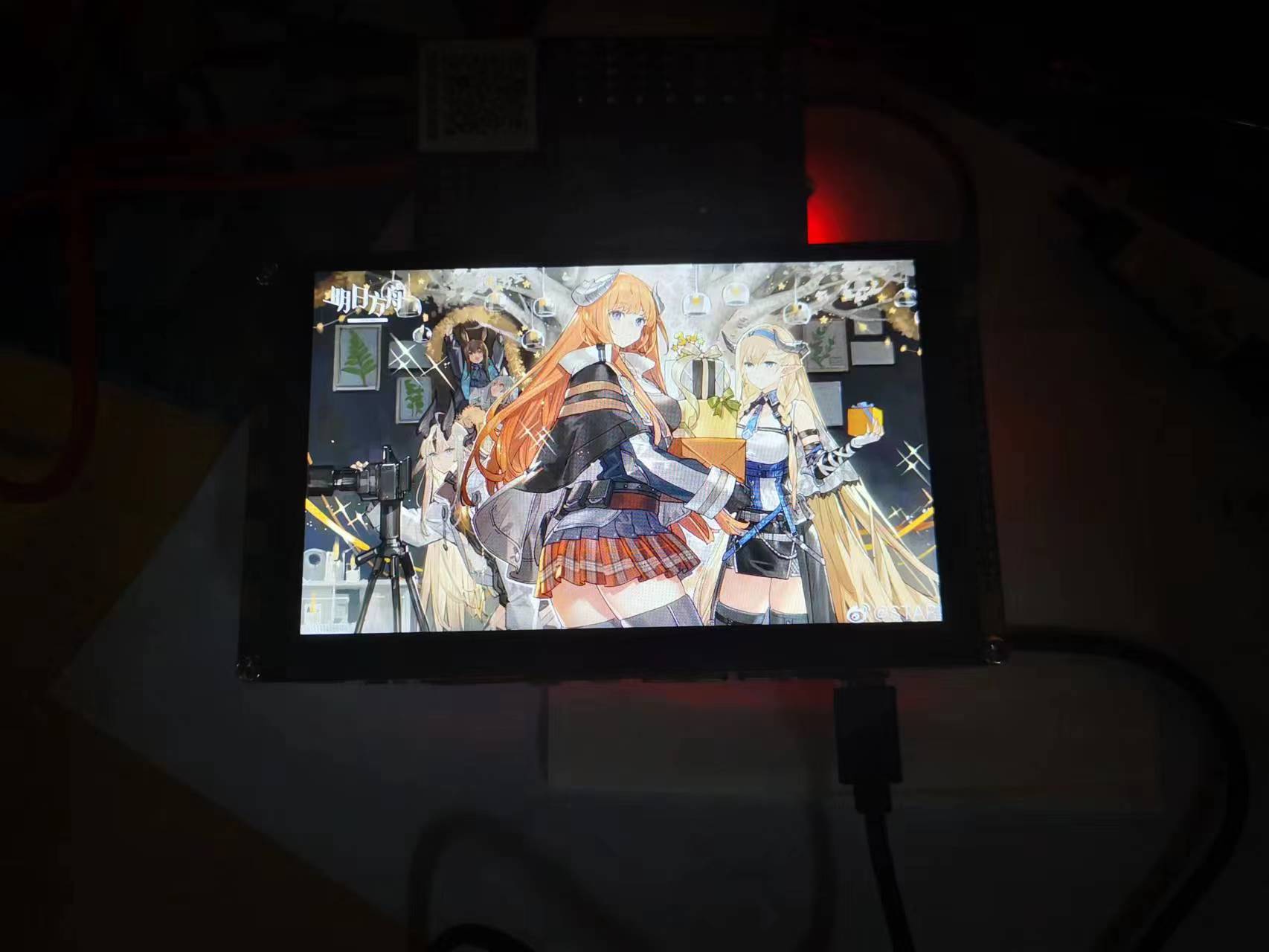
实验成功。
本随笔还有许多小细节没有给出,如果遇到问题,可以评论询问。
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
文章目录1.开发板选择*用到的资源2.串口通信(个人理解)3.代码分析(注释比较详细)1.主函数2.串口1配置3.串口2配置以及中断函数4.注意问题5.源码链接1.开发板选择我用的是STM32F103RCT6的板子,不过代码大概在F103系列的板子上都可以运行,我试过在野火103的霸道板上也可以,主要看一下串口对应的引脚一不一样就行了,不一样的就更改一下。*用到的资源keil5软件这里用到了两个串口资源,采集数据一个,串口通信一个,板子对应引脚如下:串口1,TX:PA9,RX:PA10串口2,TX:PA2,RX:PA32.串口通信(个人理解)我就从串口采集传感器数据这个过程说一下我自己的理解,
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源
我正在根据Rakefile中的现有测试文件动态生成测试任务。假设您有各种以模式命名的单元测试文件test_.rb.所以我正在做的是创建一个以“测试”命名空间内的文件名命名的任务。使用下面的代码,我可以用raketest:调用所有测试require'rake/testtask'task:default=>'test:all'namespace:testdodesc"Runalltests"Rake::TestTask.new(:all)do|t|t.test_files=FileList['test_*.rb']endFileList['test_*.rb'].eachdo|task|n
我想要像“嘿那里”这样的东西变成,例如,#316583。我希望将任意长度的字符串“归结”为十六进制颜色。我不知道从哪里开始。我在想,每个字符串的MD5散列都是不同的-但如何将该散列转换为十六进制颜色数字? 最佳答案 你可以只取几位前几位:require'digest/md5'color=Digest::MD5.hexdigest('Mytext')[0..5] 关于ruby-如何使用Ruby基于字母数字字符串生成颜色?,我们在StackOverflow上找到一个类似的问题:
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
我正在尝试整个BDD方法并想测试AMQP基于Vanilla的方面Ruby我正在写的应用程序。选择Minitest后作为与其他名副其实的蔬菜框架不同的平衡功能和表现力的测试框架,我着手编写此规范:#File./test/specs/services/my_service_spec.rb#Requirementsfortestrunningandconfigurationrequire"minitest/autorun"require"./test/specs/spec_helper"#Externalrequires#MinitestSpecsforEventMachinerequire
我分1,000个批处理从服务器获取大约20,000个数据集。每个数据集都是一个JSON对象。坚持这会产生大约350MB的未压缩明文。我的内存限制为1GB。因此,我以追加模式将每1,000个JSON对象作为一个数组写入到一个原始JSON文件中。结果是一个包含20个需要聚合的JSON数组的文件。无论如何我都需要触摸它们,因为我想添加元数据。一般RubyYajlParser使这成为可能:raw_file=File.new(path_to_raw_file,'r')json_file=File.new(path_to_json_file,'w')datasets=[]parser=Yajl::