 从GAN切换到扩散模型的架构转变也引出了一个问题:能否通过扩大GAN模型的规模,比如说在 LAION 这样的大型数据集中进一步提升性能吗?最近,针对增加StyleGAN架构容量会导致不稳定的问题,来自浦项科技大学(韩国)、卡内基梅隆大学和Adobe研究院的研究人员提出了一种全新的生成对抗网络架构GigaGAN,打破了模型的规模限制,展示了 GAN 仍然可以胜任文本到图像合成模型。
从GAN切换到扩散模型的架构转变也引出了一个问题:能否通过扩大GAN模型的规模,比如说在 LAION 这样的大型数据集中进一步提升性能吗?最近,针对增加StyleGAN架构容量会导致不稳定的问题,来自浦项科技大学(韩国)、卡内基梅隆大学和Adobe研究院的研究人员提出了一种全新的生成对抗网络架构GigaGAN,打破了模型的规模限制,展示了 GAN 仍然可以胜任文本到图像合成模型。 论文链接:https://arxiv.org/abs/2303.05511项目链接:https://mingukkang.github.io/GigaGAN/GigaGAN有三大优势。1. 它在推理时速度更快,相比同量级参数的Stable Diffusion-v1.5,在512分辨率的生成速度从2.9秒缩短到0.13秒。
论文链接:https://arxiv.org/abs/2303.05511项目链接:https://mingukkang.github.io/GigaGAN/GigaGAN有三大优势。1. 它在推理时速度更快,相比同量级参数的Stable Diffusion-v1.5,在512分辨率的生成速度从2.9秒缩短到0.13秒。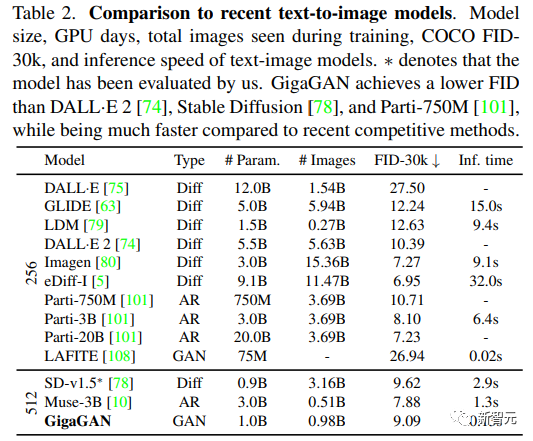 2. 可以合成高分辨率的图像,例如,在3.66秒内合成1600万像素的图像。
2. 可以合成高分辨率的图像,例如,在3.66秒内合成1600万像素的图像。 3. 支持各种潜空间编辑应用程序,如潜插值、样式混合和向量算术操作等。
3. 支持各种潜空间编辑应用程序,如潜插值、样式混合和向量算术操作等。
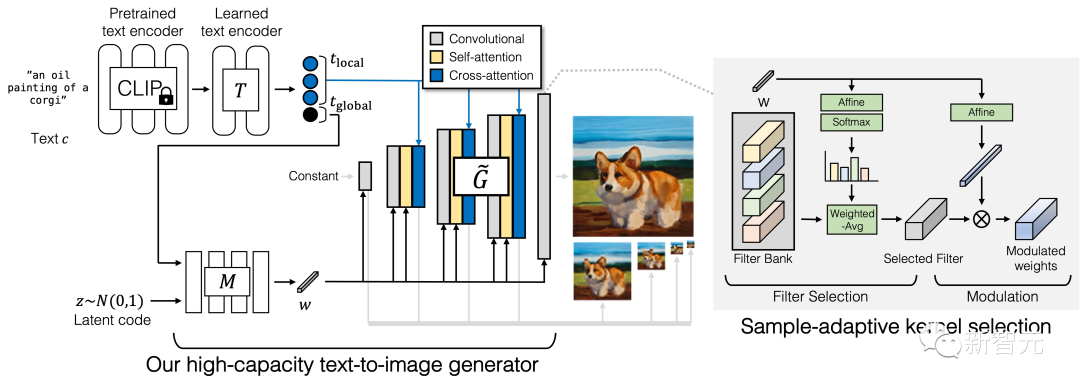 GigaGAN的生成器由文本编码分支(text encoding branch)、样式映射网络(style mapping network)、多尺度综合网络(multi-scale synthesis network)组成,并辅以稳定注意力(stable attention)和自适应核选择(adaptive kernel selection)。在文本编码分支中,首先使用一个预先训练好的 CLIP 模型和一个学习的注意层 T 来提取文本嵌入,然后将嵌入过程传递给样式映射网络 M,生成与 StyleGAN 类似的样式向量 w
GigaGAN的生成器由文本编码分支(text encoding branch)、样式映射网络(style mapping network)、多尺度综合网络(multi-scale synthesis network)组成,并辅以稳定注意力(stable attention)和自适应核选择(adaptive kernel selection)。在文本编码分支中,首先使用一个预先训练好的 CLIP 模型和一个学习的注意层 T 来提取文本嵌入,然后将嵌入过程传递给样式映射网络 M,生成与 StyleGAN 类似的样式向量 w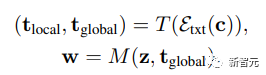 合成网络采用样式编码作为modulation,以文本嵌入作为注意力来生成image pyramid,在此基础上,引入样本自适应核选择算法,实现了基于输入文本条件的卷积核自适应选择。
合成网络采用样式编码作为modulation,以文本嵌入作为注意力来生成image pyramid,在此基础上,引入样本自适应核选择算法,实现了基于输入文本条件的卷积核自适应选择。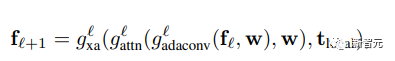 判别器
判别器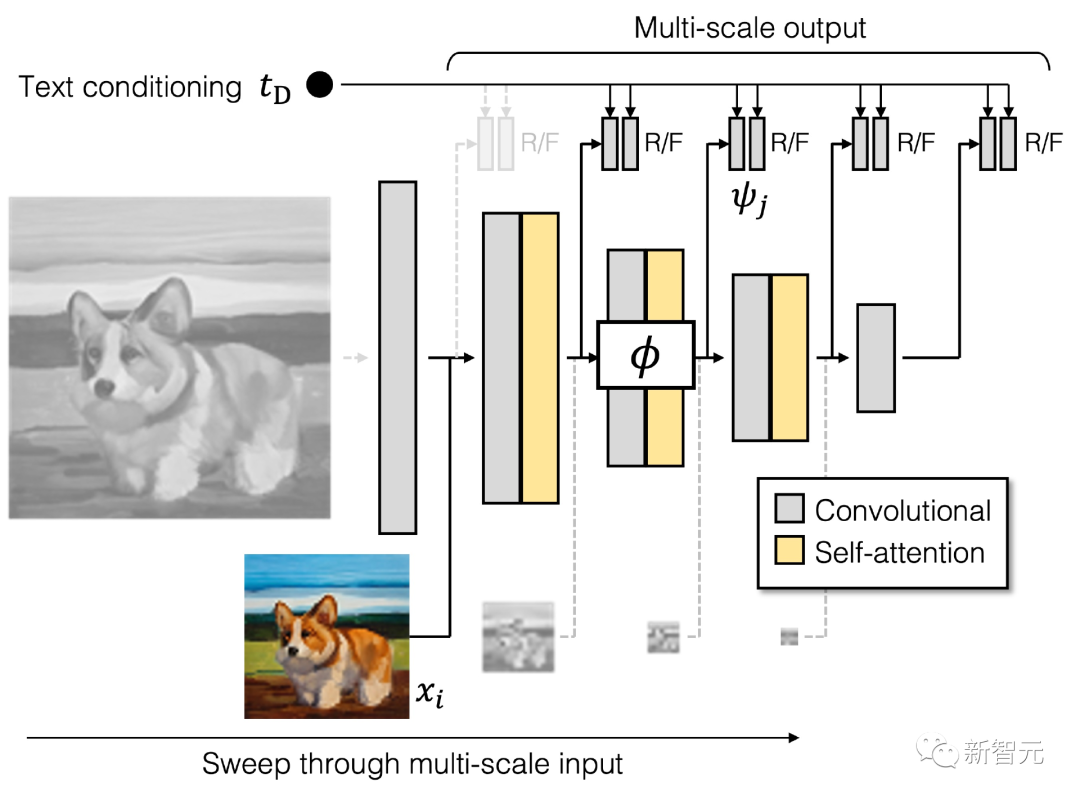 与生成器类似,GigaGAN的判别器由两个分支组成,分别用于处理图像和文本条件。文本分支处理类似于生成器的文本分支;图像分支接收一个image pyramid作为输入并对每个图像尺度进行独立的预测。
与生成器类似,GigaGAN的判别器由两个分支组成,分别用于处理图像和文本条件。文本分支处理类似于生成器的文本分支;图像分支接收一个image pyramid作为输入并对每个图像尺度进行独立的预测。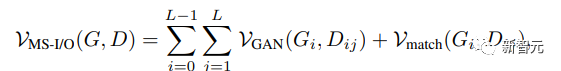 公式中引入了多个额外的损失函数以促进快速收敛。
公式中引入了多个额外的损失函数以促进快速收敛。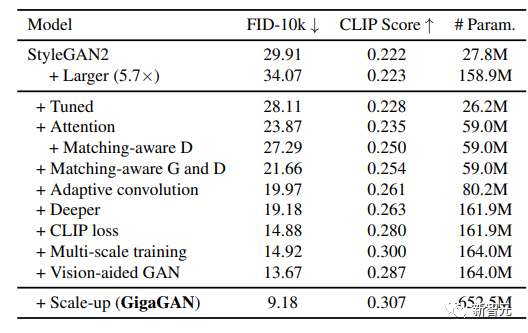 2. 文本-图像合成结果表明,GigaGAN表现出与稳定扩散(SD-v1.5)相当的FID,同时生成的结果比扩散或自回归模型快数百倍;
2. 文本-图像合成结果表明,GigaGAN表现出与稳定扩散(SD-v1.5)相当的FID,同时生成的结果比扩散或自回归模型快数百倍;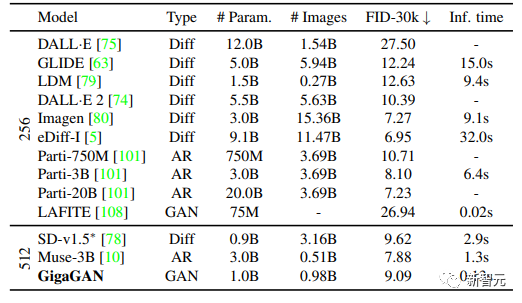 3. 将GigaGAN与基于蒸馏的扩散模型进行对比,显示GigaGAN可以比基于蒸馏的扩散模型更快地合成更高质量的图像;
3. 将GigaGAN与基于蒸馏的扩散模型进行对比,显示GigaGAN可以比基于蒸馏的扩散模型更快地合成更高质量的图像;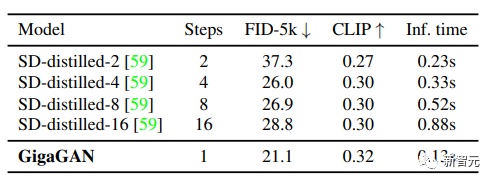 4. 验证了GigaGAN的上采样器在有条件和无条件的超分辨率任务中比其他上采样器的优势;
4. 验证了GigaGAN的上采样器在有条件和无条件的超分辨率任务中比其他上采样器的优势;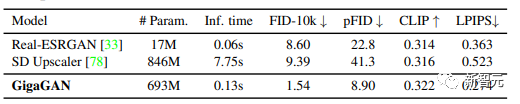 5. 结果表明大规模GANs仍然享有GANs的连续和分解潜伏空间的操作,实现了新的图像编辑模式。
5. 结果表明大规模GANs仍然享有GANs的连续和分解潜伏空间的操作,实现了新的图像编辑模式。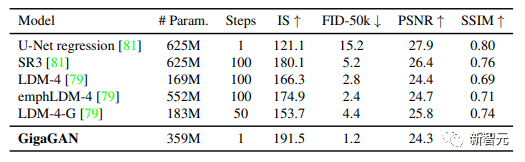 经过调参,研究人员在大规模的数据集,如LAION2B-en上实现了稳定和可扩展的十亿参数GAN(GigaGAN)的训练。
经过调参,研究人员在大规模的数据集,如LAION2B-en上实现了稳定和可扩展的十亿参数GAN(GigaGAN)的训练。 并且该方法采用了多阶段的方法,首先在64×64下生成,然后上采样到512×512,这两个网络是模块化的,而且足够强大,能够以即插即用的方式使用。结果表明,尽管在训练时从未见过扩散模型的图像,但基于文本条件的GAN上采样网络可以作为基础扩散模型(如DALL-E 2)的高效、高质量的上采样器。
并且该方法采用了多阶段的方法,首先在64×64下生成,然后上采样到512×512,这两个网络是模块化的,而且足够强大,能够以即插即用的方式使用。结果表明,尽管在训练时从未见过扩散模型的图像,但基于文本条件的GAN上采样网络可以作为基础扩散模型(如DALL-E 2)的高效、高质量的上采样器。 这些成果加在一起,使得GigaGAN远远超过了以前的GAN模型,比StyleGAN2大36倍,比StyleGAN-XL和XMC-GAN大6倍。
这些成果加在一起,使得GigaGAN远远超过了以前的GAN模型,比StyleGAN2大36倍,比StyleGAN-XL和XMC-GAN大6倍。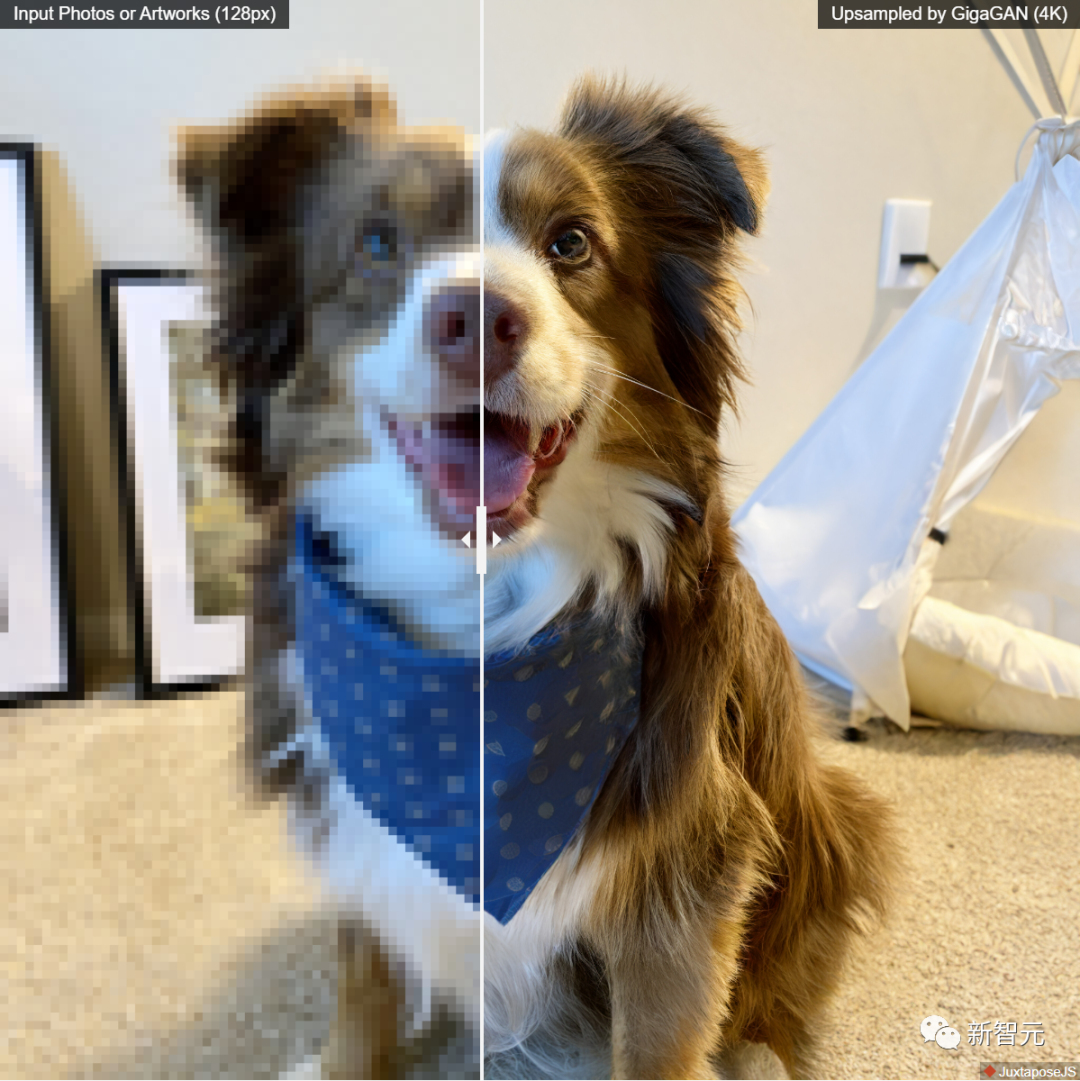 虽然GiGAN的10亿参数量仍然低于最近发布的最大合成模型,如Imagen(3B)、DALL-E 2(5.5B)和Parti(20B),但目前还没有观察到关于模型大小的质量饱和度。GigaGAN在COCO2014数据集上实现了9.09的zero-shot FID,低于DALL-E 2、Parti-750M和Stable Diffusion的FID
虽然GiGAN的10亿参数量仍然低于最近发布的最大合成模型,如Imagen(3B)、DALL-E 2(5.5B)和Parti(20B),但目前还没有观察到关于模型大小的质量饱和度。GigaGAN在COCO2014数据集上实现了9.09的zero-shot FID,低于DALL-E 2、Parti-750M和Stable Diffusion的FID 解耦提示混合(Disentangled prompt mixing)GigaGAN 保留了一个分离的潜空间,使得能够将一个样本的粗样式与另一个样本的精细样式结合起来,并且GigaGAN 可以通过文本提示直接控制样式。
解耦提示混合(Disentangled prompt mixing)GigaGAN 保留了一个分离的潜空间,使得能够将一个样本的粗样式与另一个样本的精细样式结合起来,并且GigaGAN 可以通过文本提示直接控制样式。 粗到精风格交换(Coarse-to-fine sytle swapping)基于 GAN 的模型架构保留了一个分离的潜在空间,使得能够将一个样本的粗样式与另一个样本的精样式混合在一起。
粗到精风格交换(Coarse-to-fine sytle swapping)基于 GAN 的模型架构保留了一个分离的潜在空间,使得能够将一个样本的粗样式与另一个样本的精样式混合在一起。 参考资料:https://mingukkang.github.io/GigaGAN/
参考资料:https://mingukkang.github.io/GigaGAN/ 需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
提供3种Ubuntu系统安装微信的方法,在Ubuntu20.04上验证都ok。1.WineHQ7.0安装微信:ubuntu20.04安装最新版微信--可以支持微信最新版,但是适配的不是特别好;比如WeChartOCR.exe报错。2.原生微信安装:linux系统下的微信安装(ubuntu20.04)--微信适配的最好,反应最快,但是微信版本只到2.1.1,版本太老,很多功能都没有。3.深度deepin-wine6安装微信:ubuntu20.04+系统deepin-wine6安装新版微信--综合比较好,当前个人使用此种方法1个月,微信版本3.4;没什么大问题,尚可。一、WineHQ7.0安装微信
序言AI绘图已经火了有一段时间了,国外各种AI绘图,AI视频剪辑等已经被玩坏了。StableDiffusionInfinity免费开源的StableDiffusion已经能扩画了,StableDiffusionInfinity是其子功能,下面可以来看看这个开源项目。github克隆项目(使用镜像)如果有vpn的或者能上谷歌的同学直接上github上搜索该项目,如果没有的话,找到github镜像。镜像链接:gitclone.comvsCode打开项目该项目是python写的,可以使用vscode打开查看,vscode安装参考:RunningVisualStudioCodeonmacOS项目基本信
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。在我在网上找到的每个基准测试中,Ruby似乎都很慢,比Java慢得多。Ruby的人只是说这无关紧要。您能举个例子说明RubyonRails(以及Ruby本身)的速度真的无关紧要吗?
我正在尝试从使用RubyonRails的散列创建http参数,我尝试使用URI.encode_www_form(params),但这没有正确生成参数。下面是我的哈希值params['Name'.to_sym]='NiaKun'params['AddressLine1'.to_sym]='AddressOne'params['City'.to_sym]='CityName'这个方法把空格转成+,我要的是把空格转成%20我收到"Name=Nia+Kun&AddressLine1=Address+One&City=City+Name"但我需要将此空格转换为%20
我有这段代码:date_counter=Time.mktime(2011,01,01,00,00,00,"+05:00")@weeks=Array.new(date_counter..Time.now).step(1.week)do|week|logger.debug"WEEK:"+week.inspect@weeks从技术上讲,代码有效,输出:SatJan0100:00:00-05002011SatJan0800:00:00-05002011SatJan1500:00:00-05002011etc.但是执行时间完全是垃圾!每周计算大约需要四秒钟。我在这段代码中是否遗漏了一些奇怪的低效
我想知道NokogiriXPath或CSS解析是否可以更快地处理HTML文件。速度有何不同? 最佳答案 Nokogiri没有XPath或CSS解析。它将XML/HTML解析为单个DOM,然后您可以使用CSS或XPath语法进行查询。CSS选择器在要求libxml2执行查询之前在内部转换为XPath。因此(对于完全相同的选择器)XPath版本会快一点点,因为CSS不需要先转换成XPath。但是,您的问题没有通用答案;这取决于您选择的是什么,以及您的XPath是什么样的。很有可能,您不会编写与Nokogiri创建的相同的XPath。例如
过程和lambdadiffer关于方法范围和return关键字的效果。我对它们之间的性能差异很感兴趣。我写了一个测试,如下所示:deftime(&block)start=Time.nowblock.callp"thattook#{Time.now-start}"enddeftest(proc)time{(0..10000000).each{|n|proc.call(n)}}enddeftest_block(&block)time{(0..10000000).each{|n|block.call(n)}}enddefmethod_testtime{(1..10000000).each{|
每5分钟(例如)ping20个网站的列表以了解该网站是否响应HTTP202的最佳方法是什么?最简单的想法是将20个URLS保存在数据库中,然后运行数据库并对每个URL执行ping操作。但是,当一个人不回答时会发生什么?之后的人会怎样?此外,是否有更好但更简单的解决方案?恐怕该列表会增长到20000个网站,然后没有足够的时间在我需要ping的5分钟内全部ping通它们。基本上,我是在描述PingDom、UptimeRobot等的工作原理。我正在使用node.js和RubyonRails构建这个系统。我也倾向于使用MongoDB来保存所有ping和监控结果的历史记录。建议?非常感谢!
我正在使用RubyonRails3.2.2、FactoryGirl3.1.0、FactoryGirlRails3.1.0、Rspec2.9.0和RspecRails2.9.0。为了测试我的应用程序,我必须在数据库中创建大量记录(大约5000条),但是该操作非常慢(创建记录需要10多分钟)。我这样进行:before(:each)do5000.timesdoFactoryGirl.create(:article,)endend如何改进我的规范代码以加快速度?注意:可能速度较慢是由在每个文章创建过程前后运行的(5)个文章回调引起的,但我可以跳过这些(因为我唯一需要测试的是文章和不是关联的模型